 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralist Foundation Models Are Not Clinical Enough for Hospital Operations
Nov 17, 2025Hospitals and healthcare systems rely on operational decisions that determine patient flow, cost, and quality of care. Despite strong performance on medical knowledge and conversational benchmarks, foundation models trained on general text may lack the specialized knowledge required for these operational decisions. We introduce Lang1, a family of models (100M-7B parameters) pretrained on a specialized corpus blending 80B clinical tokens from NYU Langone Health's EHRs and 627B tokens from the internet. To rigorously evaluate Lang1 in real-world settings, we developed the REalistic Medical Evaluation (ReMedE), a benchmark derived from 668,331 EHR notes that evaluates five critical tasks: 30-day readmission prediction, 30-day mortality prediction, length of stay, comorbidity coding, and predicting insurance claims denial. In zero-shot settings, both general-purpose and specialized models underperform on four of five tasks (36.6%-71.7% AUROC), with mortality prediction being an exception. After finetuning, Lang1-1B outperforms finetuned generalist models up to 70x larger and zero-shot models up to 671x larger, improving AUROC by 3.64%-6.75% and 1.66%-23.66% respectively. We also observed cross-task scaling with joint finetuning on multiple tasks leading to improvement on other tasks. Lang1-1B effectively transfers to out-of-distribution settings, including other clinical tasks and an external health system. Our findings suggest that predictive capabilities for hospital operations require explicit supervised finetuning, and that this finetuning process is made more efficient by in-domain pretraining on EHR. Our findings support the emerging view that specialized LLMs can compete with generalist models in specialized tasks, and show that effective healthcare systems AI requires the combination of in-domain pretraining, supervised finetuning, and real-world evaluation beyond proxy benchmarks.
Agricultural Landscape Understanding At Country-Scale
Nov 08, 2024Agricultural landscapes are quite complex, especially in the Global South where fields are smaller, and agricultural practices are more varied. In this paper we report on our progress in digitizing the agricultural landscape (natural and man-made) in our study region of India. We use high resolution imagery and a UNet style segmentation model to generate the first of its kind national-scale multi-class panoptic segmentation output. Through this work we have been able to identify individual fields across 151.7M hectares, and delineating key features such as water resources and vegetation. We share how this output was validated by our team and externally by downstream users, including some sample use cases that can lead to targeted data driven decision making. We believe this dataset will contribute towards digitizing agriculture by generating the foundational baselayer.
Reweighting Strategy based on Synthetic Data Identification for Sentence Similarity
Aug 30, 2022
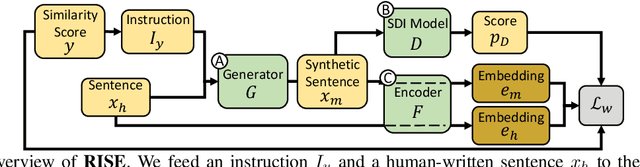

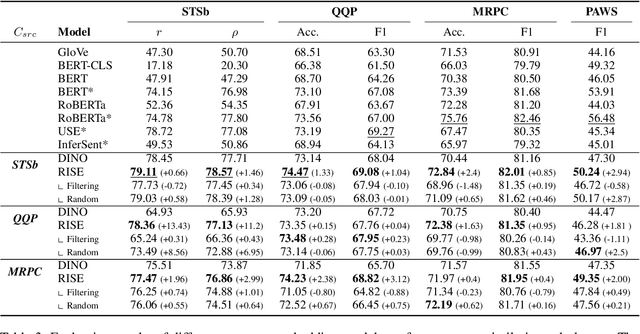
Semantically meaningful sentence embeddings are important for numerous tasks in natural language processing. To obtain such embeddings, recent studies explored the idea of utilizing synthetically generated data from pretrained language models (PLMs) as a training corpus. However, PLMs often generate sentences much different from the ones written by human. We hypothesize that treating all these synthetic examples equally for training deep neural networks can have an adverse effect on learning semantically meaningful embeddings. To analyze this, we first train a classifier that identifies machine-written sentences, and observe that the linguistic features of the sentences identified as written by a machine are significantly different from those of human-written sentences. Based on this, we propose a novel approach that first trains the classifier to measure the importance of each sentence. The distilled information from the classifier is then used to train a reliable sentence embedding model. Through extensive evaluation on four real-world datasets, we demonstrate that our model trained on synthetic data generalizes well and outperforms the existing baselines. Our implementation is publicly available at https://github.com/ddehun/coling2022_reweighting_sts.
Automatic Detection of Noisy Electrocardiogram Signals without Explicit Noise Labels
Aug 08, 2022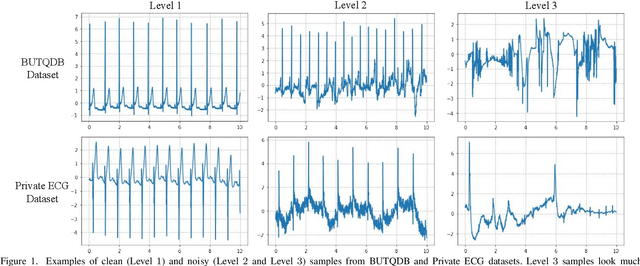
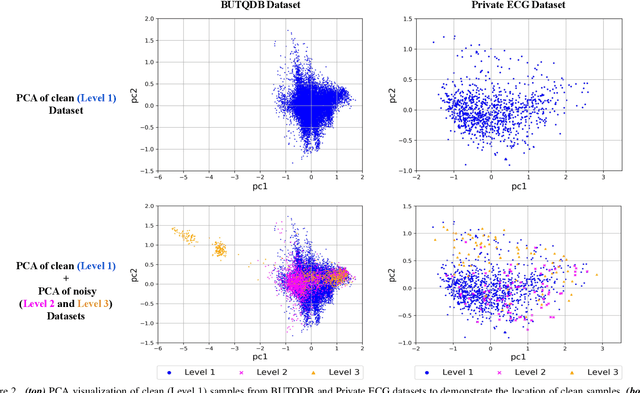
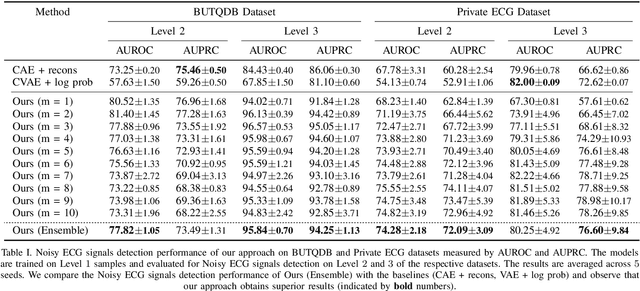
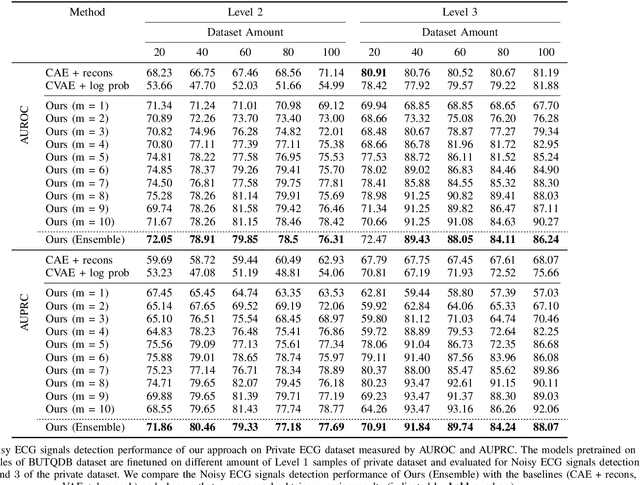
Electrocardiogram (ECG) signals are beneficial in diagnosing cardiovascular diseases, which are one of the leading causes of death. However, they are often contaminated by noise artifacts and affect the automatic and manual diagnosis process. Automatic deep learning-based examination of ECG signals can lead to inaccurate diagnosis, and manual analysis involves rejection of noisy ECG samples by clinicians, which might cost extra time. To address this limitation, we present a two-stage deep learning-based framework to automatically detect the noisy ECG samples. Through extensive experiments and analysis on two different datasets, we observe that the deep learning-based framework can detect slightly and highly noisy ECG samples effectively. We also study the transfer of the model learned on one dataset to another dataset and observe that the framework effectively detects noisy ECG samples.
Task Agnostic and Post-hoc Unseen Distribution Detection
Jul 26, 2022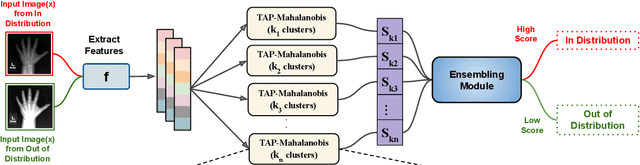
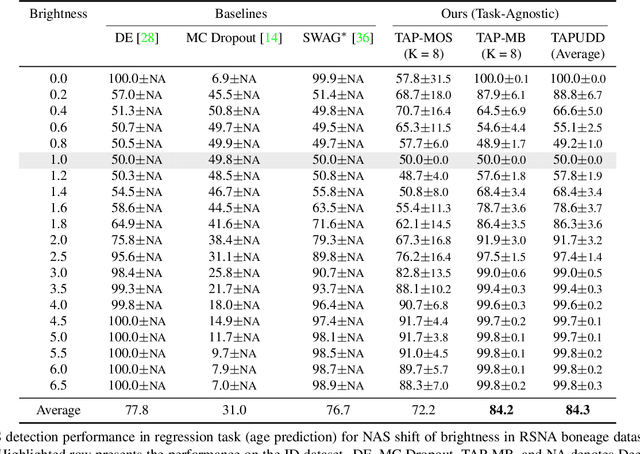
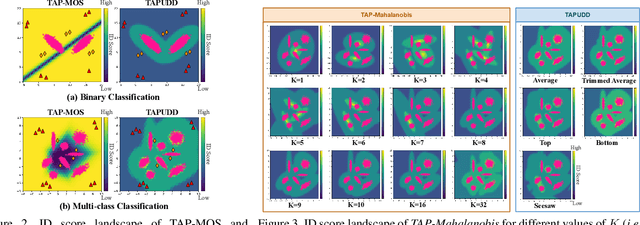
Despite the recent advances in out-of-distribution(OOD) detection, anomaly detection, and uncertainty estimation tasks, there do not exist a task-agnostic and post-hoc approach. To address this limitation, we design a novel clustering-based ensembling method, called Task Agnostic and Post-hoc Unseen Distribution Detection (TAPUDD) that utilizes the features extracted from the model trained on a specific task. Explicitly, it comprises of TAP-Mahalanobis, which clusters the training datasets' features and determines the minimum Mahalanobis distance of the test sample from all clusters. Further, we propose the Ensembling module that aggregates the computation of iterative TAP-Mahalanobis for a different number of clusters to provide reliable and efficient cluster computation. Through extensive experiments on synthetic and real-world datasets, we observe that our approach can detect unseen samples effectively across diverse tasks and performs better or on-par with the existing baselines. To this end, we eliminate the necessity of determining the optimal value of the number of clusters and demonstrate that our method is more viable for large-scale classification tasks.
Towards the Practical Utility of Federated Learning in the Medical Domain
Jul 14, 2022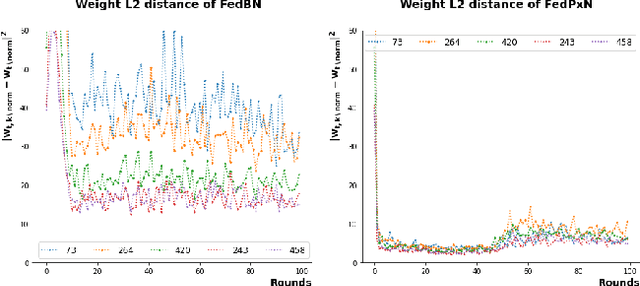
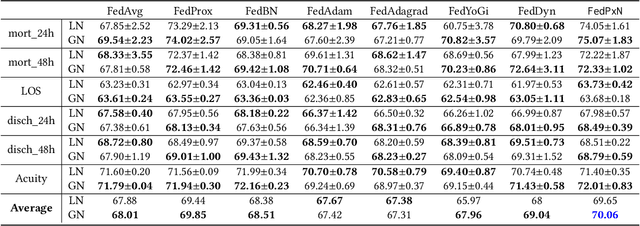
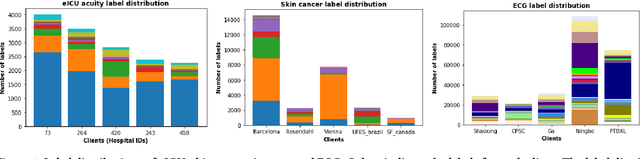
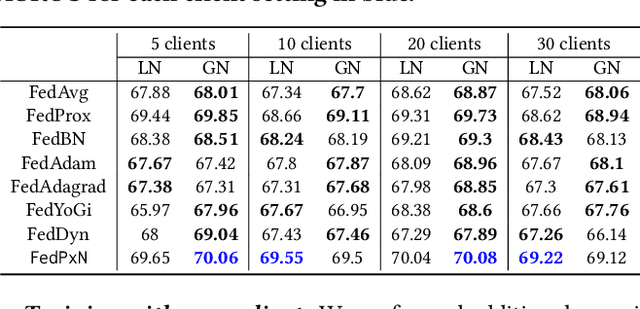
Federated learning (FL) is an active area of research. One of the most suitable areas for adopting FL is the medical domain, where patient privacy must be respected. Previous research, however, does not fully consider who will most likely use FL in the medical domain. It is not the hospitals who are eager to adopt FL, but the service providers such as IT companies who want to develop machine learning models with real patient records. Moreover, service providers would prefer to focus on maximizing the performance of the models at the lowest cost possible. In this work, we propose empirical benchmarks of FL methods considering both performance and monetary cost with three real-world datasets: electronic health records, skin cancer images, and electrocardiogram datasets. We also propose Federated learning with Proximal regularization eXcept local Normalization (FedPxN), which, using a simple combination of FedProx and FedBN, outperforms all other FL algorithms while consuming only slightly more power than the most power efficient method.
ConDor: Self-Supervised Canonicalization of 3D Pose for Partial Shapes
Jan 19, 2022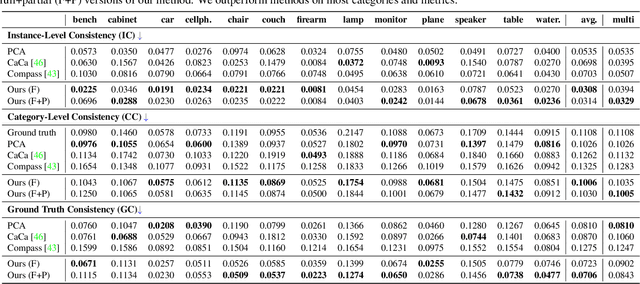
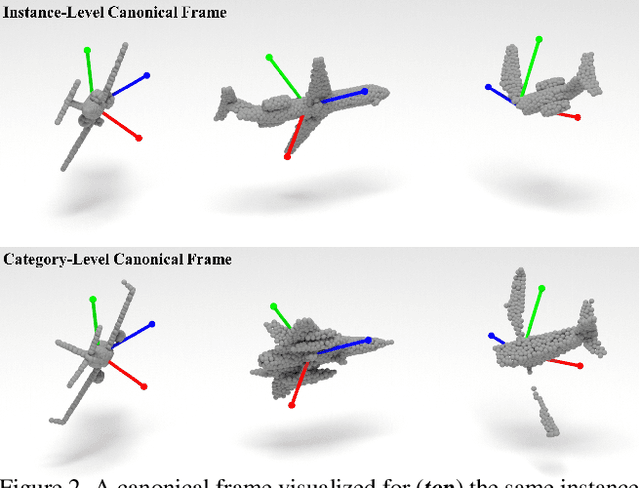
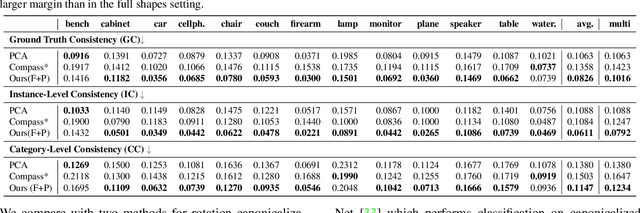
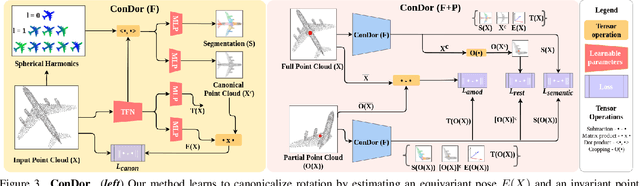
Progress in 3D object understanding has relied on manually canonicalized shape datasets that contain instances with consistent position and orientation (3D pose). This has made it hard to generalize these methods to in-the-wild shapes, eg., from internet model collections or depth sensors. ConDor is a self-supervised method that learns to Canonicalize the 3D orientation and position for full and partial 3D point clouds. We build on top of Tensor Field Networks (TFNs), a class of permutation- and rotation-equivariant, and translation-invariant 3D networks. During inference, our method takes an unseen full or partial 3D point cloud at an arbitrary pose and outputs an equivariant canonical pose. During training, this network uses self-supervision losses to learn the canonical pose from an un-canonicalized collection of full and partial 3D point clouds. ConDor can also learn to consistently co-segment object parts without any supervision. Extensive quantitative results on four new metrics show that our approach outperforms existing methods while enabling new applications such as operation on depth images and annotation transfer.
Natural Attribute-based Shift Detection
Oct 18, 2021

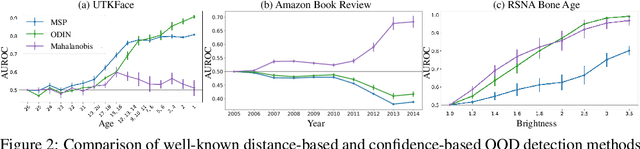

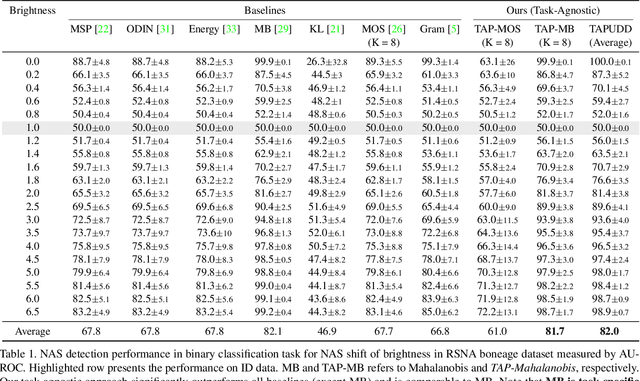
Despite the impressive performance of deep networks in vision, language, and healthcare, unpredictable behaviors on samples from the distribution different than the training distribution cause severe problems in deployment. For better reliability of neural-network-based classifiers, we define a new task, natural attribute-based shift (NAS) detection, to detect the samples shifted from the training distribution by some natural attribute such as age of subjects or brightness of images. Using the natural attributes present in existing datasets, we introduce benchmark datasets in vision, language, and medical for NAS detection. Further, we conduct an extensive evaluation of prior representative out-of-distribution (OOD) detection methods on NAS datasets and observe an inconsistency in their performance. To understand this, we provide an analysis on the relationship between the location of NAS samples in the feature space and the performance of distance- and confidence-based OOD detection methods. Based on the analysis, we split NAS samples into three categories and further suggest a simple modification to the training objective to obtain an improved OOD detection method that is capable of detecting samples from all NAS categories.
Beyond VQA: Generating Multi-word Answer and Rationale to Visual Questions
Oct 24, 2020
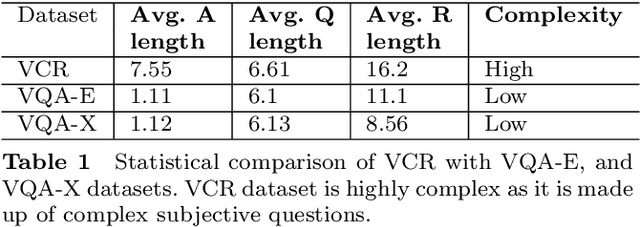

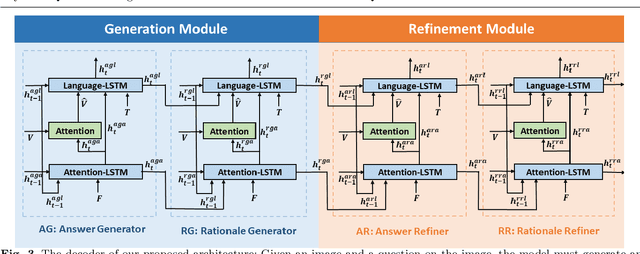
Visual Question Answering is a multi-modal task that aims to measure high-level visual understanding. Contemporary VQA models are restrictive in the sense that answers are obtained via classification over a limited vocabulary (in the case of open-ended VQA), or via classification over a set of multiple-choice-type answers. In this work, we present a completely generative formulation where a multi-word answer is generated for a visual query. To take this a step forward, we introduce a new task: ViQAR (Visual Question Answering and Reasoning), wherein a model must generate the complete answer and a rationale that seeks to justify the generated answer. We propose an end-to-end architecture to solve this task and describe how to evaluate it. We show that our model generates strong answers and rationales through qualitative and quantitative evaluation, as well as through a human Turing Test.
VayuAnukulani: Adaptive Memory Networks for Air Pollution Forecasting
Apr 08, 2019
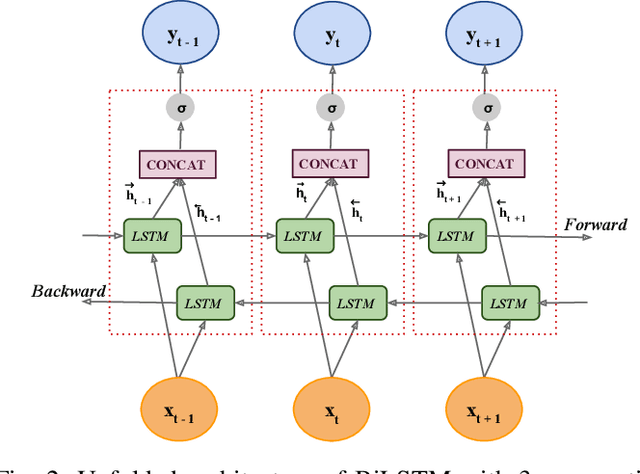
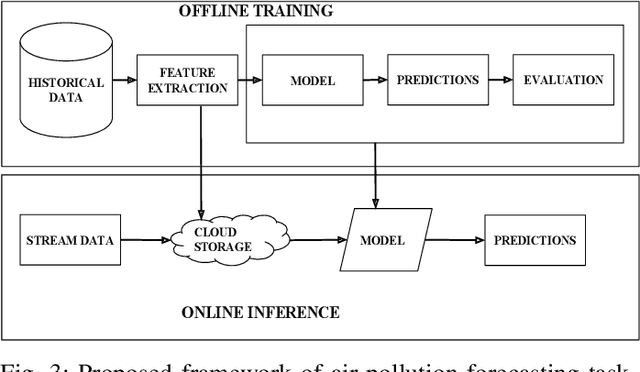
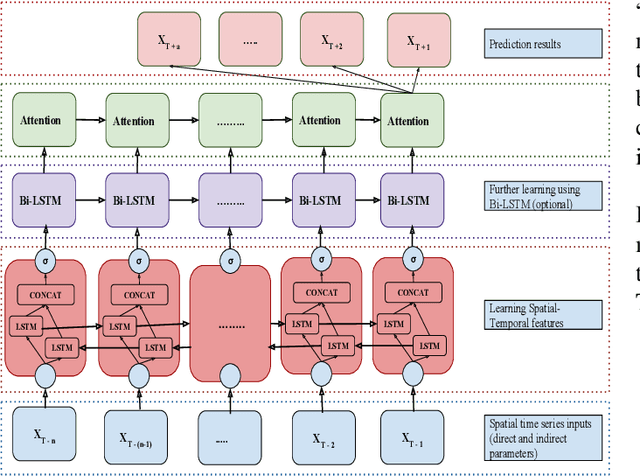
Air pollution is the leading environmental health hazard globally due to various sources which include factory emissions, car exhaust and cooking stoves. As a precautionary measure, air pollution forecast serves as the basis for taking effective pollution control measures, and accurate air pollution forecasting has become an important task. In this paper, we forecast fine-grained ambient air quality information for 5 prominent locations in Delhi based on the historical and real-time ambient air quality and meteorological data reported by Central Pollution Control board. We present VayuAnukulani system, a novel end-to-end solution to predict air quality for next 24 hours by estimating the concentration and level of different air pollutants including nitrogen dioxide ($NO_2$), particulate matter ($PM_{2.5}$ and $PM_{10}$) for Delhi. Extensive experiments on data sources obtained in Delhi demonstrate that the proposed adaptive attention based Bidirectional LSTM Network outperforms several baselines for classification and regression models. The accuracy of the proposed adaptive system is $\sim 15 - 20\%$ better than the same offline trained model. We compare the proposed methodology on several competing baselines, and show that the network outperforms conventional methods by $\sim 3 - 5 \%$.