 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialSim: A Real-Time Simulator for Evaluating Long-Term Dialogue Understanding of Conversational Agents
Jun 19, 2024



Recent advancements in Large Language Models (LLMs) have significantly enhanced the capabilities of conversational agents, making them applicable to various fields (e.g., education). Despite their progress, the evaluation of the agents often overlooks the complexities of real-world conversations, such as real-time interactions, multi-party dialogues, and extended contextual dependencies. To bridge this gap, we introduce DialSim, a real-time dialogue simulator. In this simulator, an agent is assigned the role of a character from popular TV shows, requiring it to respond to spontaneous questions using past dialogue information and to distinguish between known and unknown information. Key features of DialSim include evaluating the agent's ability to respond within a reasonable time limit, handling long-term multi-party dialogues, and managing adversarial settings (e.g., swap character names) to challenge the agent's reliance on pre-trained knowledge. We utilized this simulator to evaluate the latest conversational agents and analyze their limitations. Our experiments highlight both the strengths and weaknesses of these agents, providing valuable insights for future improvements in the field of conversational AI. DialSim is available at https://github.com/jiho283/Simulator.
EHRSQL: A Practical Text-to-SQL Benchmark for Electronic Health Records
Jan 16, 2023



We present a new text-to-SQL dataset for electronic health records (EHRs). The utterances were collected from 222 hospital staff, including physicians, nurses, insurance review and health records teams, and more. To construct the QA dataset on structured EHR data, we conducted a poll at a university hospital and templatized the responses to create seed questions. Then, we manually linked them to two open-source EHR databases, MIMIC-III and eICU, and included them with various time expressions and held-out unanswerable questions in the dataset, which were all collected from the poll. Our dataset poses a unique set of challenges: the model needs to 1) generate SQL queries that reflect a wide range of needs in the hospital, including simple retrieval and complex operations such as calculating survival rate, 2) understand various time expressions to answer time-sensitive questions in healthcare, and 3) distinguish whether a given question is answerable or unanswerable based on the prediction confidence. We believe our dataset, EHRSQL, could serve as a practical benchmark to develop and assess QA models on structured EHR data and take one step further towards bridging the gap between text-to-SQL research and its real-life deployment in healthcare. EHRSQL is available at https://github.com/glee4810/EHRSQL.
Towards the Practical Utility of Federated Learning in the Medical Domain
Jul 14, 2022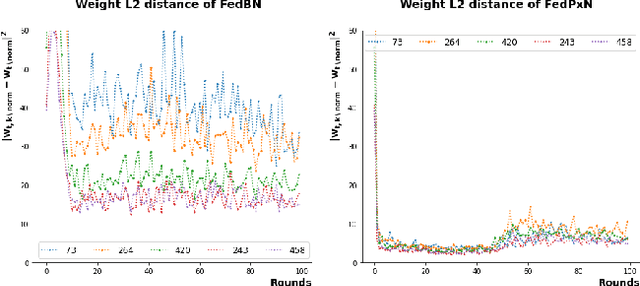
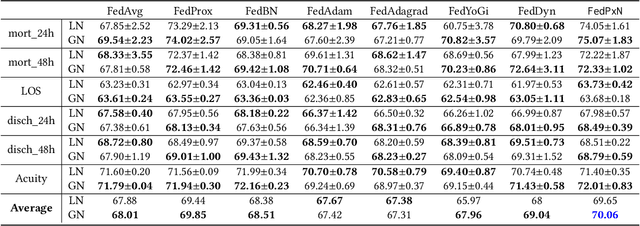
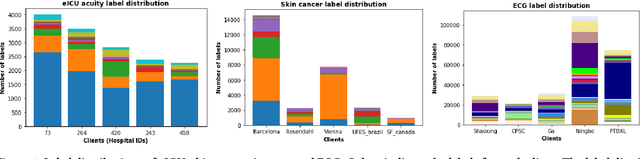
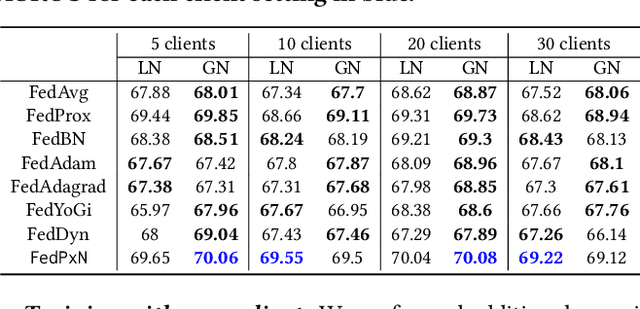
Federated learning (FL) is an active area of research. One of the most suitable areas for adopting FL is the medical domain, where patient privacy must be respected. Previous research, however, does not fully consider who will most likely use FL in the medical domain. It is not the hospitals who are eager to adopt FL, but the service providers such as IT companies who want to develop machine learning models with real patient records. Moreover, service providers would prefer to focus on maximizing the performance of the models at the lowest cost possible. In this work, we propose empirical benchmarks of FL methods considering both performance and monetary cost with three real-world datasets: electronic health records, skin cancer images, and electrocardiogram datasets. We also propose Federated learning with Proximal regularization eXcept local Normalization (FedPxN), which, using a simple combination of FedProx and FedBN, outperforms all other FL algorithms while consuming only slightly more power than the most power efficient method.