 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaithful GRPO: Improving Visual Spatial Reasoning in Multimodal Language Models via Constrained Policy Optimization
Apr 09, 2026Multimodal reasoning models (MRMs) trained with reinforcement learning with verifiable rewards (RLVR) show improved accuracy on visual reasoning benchmarks. However, we observe that accuracy gains often come at the cost of reasoning quality: generated Chain-of-Thought (CoT) traces are frequently inconsistent with the final answer and poorly grounded in the visual evidence. We systematically study this phenomenon across seven challenging real-world spatial reasoning benchmarks and find that it affects contemporary MRMs such as ViGoRL-Spatial, TreeVGR as well as our own models trained with standard Group Relative Policy Optimization (GRPO). We characterize CoT reasoning quality along two complementary axes: "logical consistency" (does the CoT entail the final answer?) and "visual grounding" (does each reasoning step accurately describe objects, attributes, and spatial relationships in the image?). To address this, we propose Faithful GRPO (FGRPO), a variant of GRPO that enforces consistency and grounding as constraints via Lagrangian dual ascent. FGRPO incorporates batch-level consistency and grounding constraints into the advantage computation within a group, adaptively adjusting the relative importance of constraints during optimization. We evaluate FGRPO on Qwen2.5-VL-7B and 3B backbones across seven spatial datasets. Our results show that FGRPO substantially improves reasoning quality, reducing the inconsistency rate from 24.5% to 1.7% and improving visual grounding scores by +13%. It also improves final answer accuracy over simple GRPO, demonstrating that faithful reasoning enables better answers.
Efficient Vocabulary-Free Fine-Grained Visual Recognition in the Age of Multimodal LLMs
May 02, 2025Fine-grained Visual Recognition (FGVR) involves distinguishing between visually similar categories, which is inherently challenging due to subtle inter-class differences and the need for large, expert-annotated datasets. In domains like medical imaging, such curated datasets are unavailable due to issues like privacy concerns and high annotation costs. In such scenarios lacking labeled data, an FGVR model cannot rely on a predefined set of training labels, and hence has an unconstrained output space for predictions. We refer to this task as Vocabulary-Free FGVR (VF-FGVR), where a model must predict labels from an unconstrained output space without prior label information. While recent Multimodal Large Language Models (MLLMs) show potential for VF-FGVR, querying these models for each test input is impractical because of high costs and prohibitive inference times. To address these limitations, we introduce \textbf{Nea}rest-Neighbor Label \textbf{R}efinement (NeaR), a novel approach that fine-tunes a downstream CLIP model using labels generated by an MLLM. Our approach constructs a weakly supervised dataset from a small, unlabeled training set, leveraging MLLMs for label generation. NeaR is designed to handle the noise, stochasticity, and open-endedness inherent in labels generated by MLLMs, and establishes a new benchmark for efficient VF-FGVR.
Can Better Text Semantics in Prompt Tuning Improve VLM Generalization?
May 13, 2024Going beyond mere fine-tuning of vision-language models (VLMs), learnable prompt tuning has emerged as a promising, resource-efficient alternative. Despite their potential, effectively learning prompts faces the following challenges: (i) training in a low-shot scenario results in overfitting, limiting adaptability and yielding weaker performance on newer classes or datasets; (ii) prompt-tuning's efficacy heavily relies on the label space, with decreased performance in large class spaces, signaling potential gaps in bridging image and class concepts. In this work, we ask the question if better text semantics can help address these concerns. In particular, we introduce a prompt-tuning method that leverages class descriptions obtained from large language models (LLMs). Our approach constructs part-level description-guided views of both image and text features, which are subsequently aligned to learn more generalizable prompts. Our comprehensive experiments, conducted across 11 benchmark datasets, outperform established methods, demonstrating substantial improvements.
Causal Regularization Using Domain Priors
Nov 24, 2021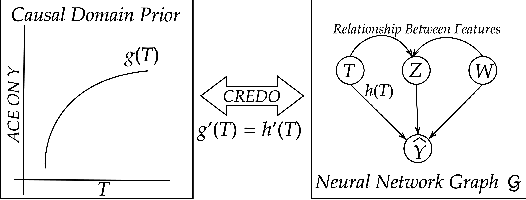
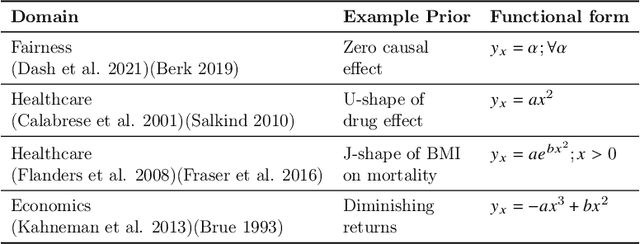
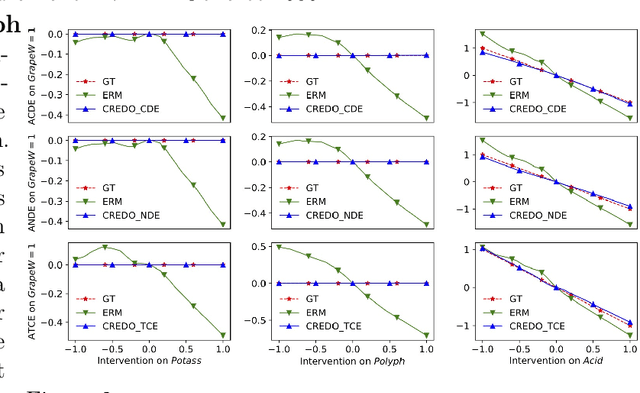
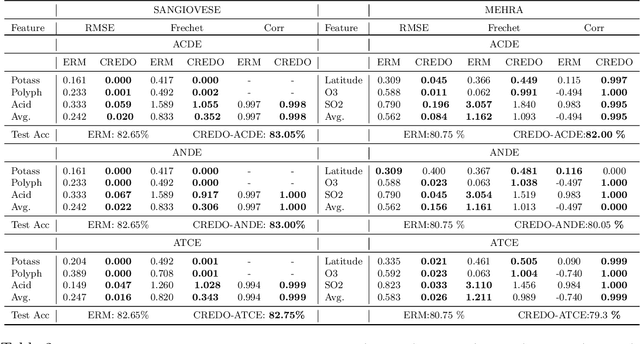
Neural networks leverage both causal and correlation-based relationships in data to learn models that optimize a given performance criterion, such as classification accuracy. This results in learned models that may not necessarily reflect the true causal relationships between input and output. When domain priors of causal relationships are available at the time of training, it is essential that a neural network model maintains these relationships as causal, even as it learns to optimize the performance criterion. We propose a causal regularization method that can incorporate such causal domain priors into the network and which supports both direct and total causal effects. We show that this approach can generalize to various kinds of specifications of causal priors, including monotonicity of causal effect of a given input feature or removing a certain influence for purposes of fairness. Our experiments on eleven benchmark datasets show the usefulness of this approach in regularizing a learned neural network model to maintain desired causal effects. On most datasets, domain-prior consistent models can be obtained without compromising on accuracy.
Instance-wise Causal Feature Selection for Model Interpretation
Apr 26, 2021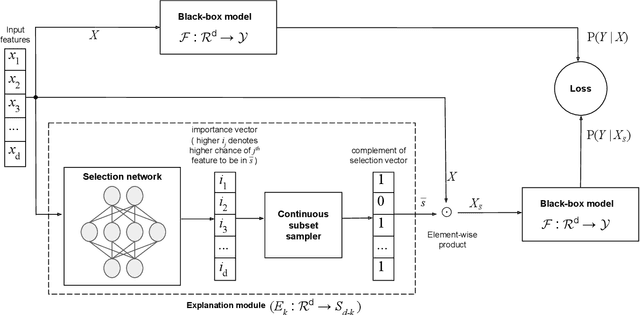
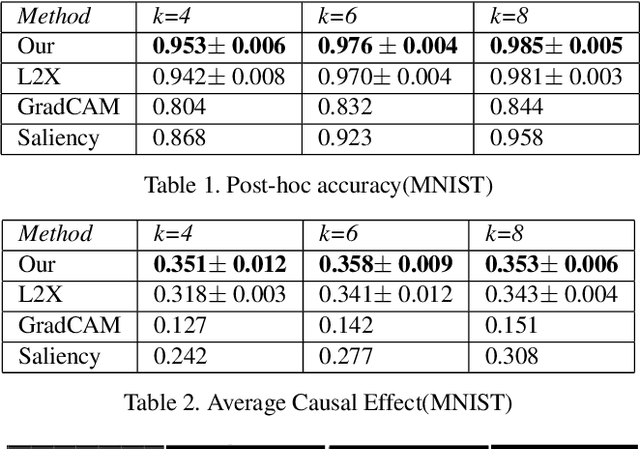
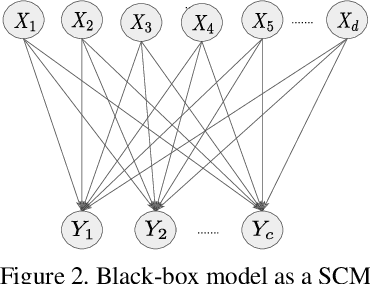
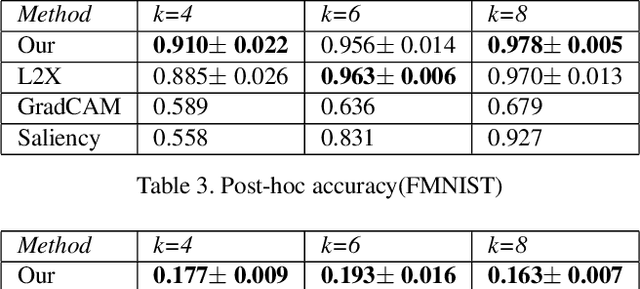
We formulate a causal extension to the recently introduced paradigm of instance-wise feature selection to explain black-box visual classifiers. Our method selects a subset of input features that has the greatest causal effect on the models output. We quantify the causal influence of a subset of features by the Relative Entropy Distance measure. Under certain assumptions this is equivalent to the conditional mutual information between the selected subset and the output variable. The resulting causal selections are sparser and cover salient objects in the scene. We show the efficacy of our approach on multiple vision datasets by measuring the post-hoc accuracy and Average Causal Effect of selected features on the models output.
Beyond VQA: Generating Multi-word Answer and Rationale to Visual Questions
Oct 24, 2020
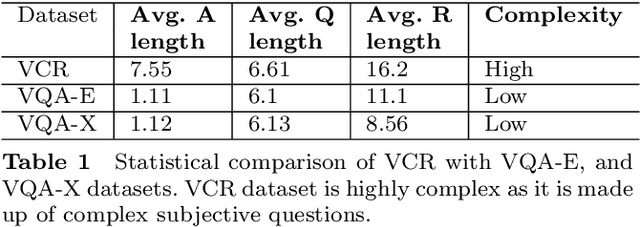

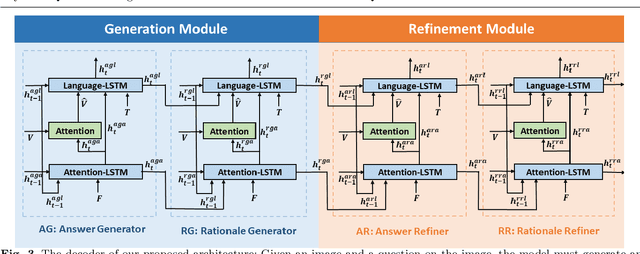
Visual Question Answering is a multi-modal task that aims to measure high-level visual understanding. Contemporary VQA models are restrictive in the sense that answers are obtained via classification over a limited vocabulary (in the case of open-ended VQA), or via classification over a set of multiple-choice-type answers. In this work, we present a completely generative formulation where a multi-word answer is generated for a visual query. To take this a step forward, we introduce a new task: ViQAR (Visual Question Answering and Reasoning), wherein a model must generate the complete answer and a rationale that seeks to justify the generated answer. We propose an end-to-end architecture to solve this task and describe how to evaluate it. We show that our model generates strong answers and rationales through qualitative and quantitative evaluation, as well as through a human Turing Test.