 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Re-Train, More Gain: Upgrading Backbones with Diffusion Model for Few-Shot Segmentation
Jul 23, 2024



Few-Shot Segmentation (FSS) aims to segment novel classes using only a few annotated images. Despite considerable process under pixel-wise support annotation, current FSS methods still face three issues: the inflexibility of backbone upgrade without re-training, the inability to uniformly handle various types of annotations (e.g., scribble, bounding box, mask and text), and the difficulty in accommodating different annotation quantity. To address these issues simultaneously, we propose DiffUp, a novel FSS method that conceptualizes the FSS task as a conditional generative problem using a diffusion process. For the first issue, we introduce a backbone-agnostic feature transformation module that converts different segmentation cues into unified coarse priors, facilitating seamless backbone upgrade without re-training. For the second issue, due to the varying granularity of transformed priors from diverse annotation types, we conceptualize these multi-granular transformed priors as analogous to noisy intermediates at different steps of a diffusion model. This is implemented via a self-conditioned modulation block coupled with a dual-level quality modulation branch. For the third issue, we incorporates an uncertainty-aware information fusion module that harmonizing the variability across zero-shot, one-shot and many-shot scenarios. Evaluated through rigorous benchmarks, DiffUp significantly outperforms existing FSS models in terms of flexibility and accuracy.
On the Adversarial Robustness of Learning-based Image Compression Against Rate-Distortion Attacks
May 13, 2024



Despite demonstrating superior rate-distortion (RD) performance, learning-based image compression (LIC) algorithms have been found to be vulnerable to malicious perturbations in recent studies. Adversarial samples in these studies are designed to attack only one dimension of either bitrate or distortion, targeting a submodel with a specific compression ratio. However, adversaries in real-world scenarios are neither confined to singular dimensional attacks nor always have control over compression ratios. This variability highlights the inadequacy of existing research in comprehensively assessing the adversarial robustness of LIC algorithms in practical applications. To tackle this issue, this paper presents two joint rate-distortion attack paradigms at both submodel and algorithm levels, i.e., Specific-ratio Rate-Distortion Attack (SRDA) and Agnostic-ratio Rate-Distortion Attack (ARDA). Additionally, a suite of multi-granularity assessment tools is introduced to evaluate the attack results from various perspectives. On this basis, extensive experiments on eight prominent LIC algorithms are conducted to offer a thorough analysis of their inherent vulnerabilities. Furthermore, we explore the efficacy of two defense techniques in improving the performance under joint rate-distortion attacks. The findings from these experiments can provide a valuable reference for the development of compression algorithms with enhanced adversarial robustness.
A Deep Learning Method for Beat-Level Risk Analysis and Interpretation of Atrial Fibrillation Patients during Sinus Rhythm
Mar 18, 2024



Atrial Fibrillation (AF) is a common cardiac arrhythmia. Many AF patients experience complications such as stroke and other cardiovascular issues. Early detection of AF is crucial. Existing algorithms can only distinguish ``AF rhythm in AF patients'' from ``sinus rhythm in normal individuals'' . However, AF patients do not always exhibit AF rhythm, posing a challenge for diagnosis when the AF rhythm is absent. To address this, this paper proposes a novel artificial intelligence (AI) algorithm to distinguish ``sinus rhythm in AF patients'' and ``sinus rhythm in normal individuals'' in beat-level. We introduce beat-level risk interpreters, trend risk interpreters, addressing the interpretability issues of deep learning models and the difficulty in explaining AF risk trends. Additionally, the beat-level information fusion decision is presented to enhance model accuracy. The experimental results demonstrate that the average AUC for single beats used as testing data from CPSC 2021 dataset is 0.7314. By employing 150 beats for information fusion decision algorithm, the average AUC can reach 0.7591. Compared to previous segment-level algorithms, we utilized beats as input, reducing data dimensionality and making the model more lightweight, facilitating deployment on portable medical devices. Furthermore, we draw new and interesting findings through average beat analysis and subgroup analysis, considering varying risk levels.
Learning with Noisy Low-Cost MOS for Image Quality Assessment via Dual-Bias Calibration
Nov 27, 2023



Learning based image quality assessment (IQA) models have obtained impressive performance with the help of reliable subjective quality labels, where mean opinion score (MOS) is the most popular choice. However, in view of the subjective bias of individual annotators, the labor-abundant MOS (LA-MOS) typically requires a large collection of opinion scores from multiple annotators for each image, which significantly increases the learning cost. In this paper, we aim to learn robust IQA models from low-cost MOS (LC-MOS), which only requires very few opinion scores or even a single opinion score for each image. More specifically, we consider the LC-MOS as the noisy observation of LA-MOS and enforce the IQA model learned from LC-MOS to approach the unbiased estimation of LA-MOS. In this way, we represent the subjective bias between LC-MOS and LA-MOS, and the model bias between IQA predictions learned from LC-MOS and LA-MOS (i.e., dual-bias) as two latent variables with unknown parameters. By means of the expectation-maximization based alternating optimization, we can jointly estimate the parameters of the dual-bias, which suppresses the misleading of LC-MOS via a gated dual-bias calibration (GDBC) module. To the best of our knowledge, this is the first exploration of robust IQA model learning from noisy low-cost labels. Theoretical analysis and extensive experiments on four popular IQA datasets show that the proposed method is robust toward different bias rates and annotation numbers and significantly outperforms the other learning based IQA models when only LC-MOS is available. Furthermore, we also achieve comparable performance with respect to the other models learned with LA-MOS.
Cross-modal Cognitive Consensus guided Audio-Visual Segmentation
Oct 10, 2023



Audio-Visual Segmentation (AVS) aims to extract the sounding object from a video frame, which is represented by a pixel-wise segmentation mask. The pioneering work conducts this task through dense feature-level audio-visual interaction, which ignores the dimension gap between different modalities. More specifically, the audio clip could only provide a \textit{Global} semantic label in each sequence, but the video frame covers multiple semantic objects across different \textit{Local} regions. In this paper, we propose a Cross-modal Cognitive Consensus guided Network (C3N) to align the audio-visual semantics from the global dimension and progressively inject them into the local regions via an attention mechanism. Firstly, a Cross-modal Cognitive Consensus Inference Module (C3IM) is developed to extract a unified-modal label by integrating audio/visual classification confidence and similarities of modality-specific label embeddings. Then, we feed the unified-modal label back to the visual backbone as the explicit semantic-level guidance via a Cognitive Consensus guided Attention Module (CCAM), which highlights the local features corresponding to the interested object. Extensive experiments on the Single Sound Source Segmentation (S4) setting and Multiple Sound Source Segmentation (MS3) setting of the AVSBench dataset demonstrate the effectiveness of the proposed method, which achieves state-of-the-art performance.
Towards Continual Egocentric Activity Recognition: A Multi-modal Egocentric Activity Dataset for Continual Learning
Jan 26, 2023



With the rapid development of wearable cameras, a massive collection of egocentric video for first-person visual perception becomes available. Using egocentric videos to predict first-person activity faces many challenges, including limited field of view, occlusions, and unstable motions. Observing that sensor data from wearable devices facilitates human activity recognition, multi-modal activity recognition is attracting increasing attention. However, the deficiency of related dataset hinders the development of multi-modal deep learning for egocentric activity recognition. Nowadays, deep learning in real world has led to a focus on continual learning that often suffers from catastrophic forgetting. But the catastrophic forgetting problem for egocentric activity recognition, especially in the context of multiple modalities, remains unexplored due to unavailability of dataset. In order to assist this research, we present a multi-modal egocentric activity dataset for continual learning named UESTC-MMEA-CL, which is collected by self-developed glasses integrating a first-person camera and wearable sensors. It contains synchronized data of videos, accelerometers, and gyroscopes, for 32 types of daily activities, performed by 10 participants. Its class types and scale are compared with other publicly available datasets. The statistical analysis of the sensor data is given to show the auxiliary effects for different behaviors. And results of egocentric activity recognition are reported when using separately, and jointly, three modalities: RGB, acceleration, and gyroscope, on a base network architecture. To explore the catastrophic forgetting in continual learning tasks, four baseline methods are extensively evaluated with different multi-modal combinations. We hope the UESTC-MMEA-CL can promote future studies on continual learning for first-person activity recognition in wearable applications.
Forgetting to Remember: A Scalable Incremental Learning Framework for Cross-Task Blind Image Quality Assessment
Sep 15, 2022

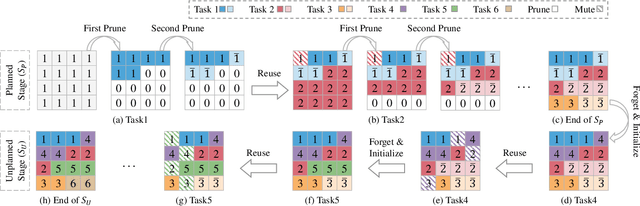
Recent years have witnessed the great success of blind image quality assessment (BIQA) in various task-specific scenarios, which present invariable distortion types and evaluation criteria. However, due to the rigid structure and learning framework, they cannot apply to the cross-task BIQA scenario, where the distortion types and evaluation criteria keep changing in practical applications. This paper proposes a scalable incremental learning framework (SILF) that could sequentially conduct BIQA across multiple evaluation tasks with limited memory capacity. More specifically, we develop a dynamic parameter isolation strategy to sequentially update the task-specific parameter subsets, which are non-overlapped with each other. Each parameter subset is temporarily settled to Remember one evaluation preference toward its corresponding task, and the previously settled parameter subsets can be adaptively reused in the following BIQA to achieve better performance based on the task relevance. To suppress the unrestrained expansion of memory capacity in sequential tasks learning, we develop a scalable memory unit by gradually and selectively pruning unimportant neurons from previously settled parameter subsets, which enable us to Forget part of previous experiences and free the limited memory capacity for adapting to the emerging new tasks. Extensive experiments on eleven IQA datasets demonstrate that our proposed method significantly outperforms the other state-of-the-art methods in cross-task BIQA.
RefCrowd: Grounding the Target in Crowd with Referring Expressions
Jun 16, 2022
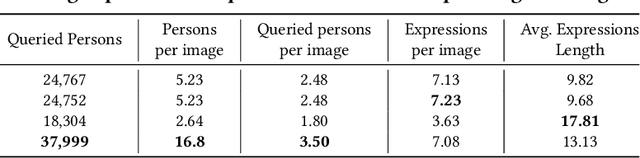

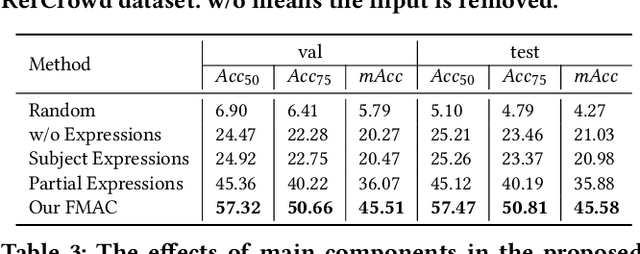
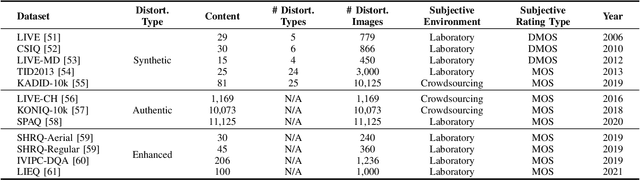
Crowd understanding has aroused the widespread interest in vision domain due to its important practical significance. Unfortunately, there is no effort to explore crowd understanding in multi-modal domain that bridges natural language and computer vision. Referring expression comprehension (REF) is such a representative multi-modal task. Current REF studies focus more on grounding the target object from multiple distinctive categories in general scenarios. It is difficult to applied to complex real-world crowd understanding. To fill this gap, we propose a new challenging dataset, called RefCrowd, which towards looking for the target person in crowd with referring expressions. It not only requires to sufficiently mine the natural language information, but also requires to carefully focus on subtle differences between the target and a crowd of persons with similar appearance, so as to realize the fine-grained mapping from language to vision. Furthermore, we propose a Fine-grained Multi-modal Attribute Contrastive Network (FMAC) to deal with REF in crowd understanding. It first decomposes the intricate visual and language features into attribute-aware multi-modal features, and then captures discriminative but robustness fine-grained attribute features to effectively distinguish these subtle differences between similar persons. The proposed method outperforms existing state-of-the-art (SoTA) methods on our RefCrowd dataset and existing REF datasets. In addition, we implement an end-to-end REF toolbox for the deeper research in multi-modal domain. Our dataset and code can be available at: \url{https://qiuheqian.github.io/datasets/refcrowd/}.
Non-Homogeneous Haze Removal via Artificial Scene Prior and Bidimensional Graph Reasoning
Apr 05, 2021
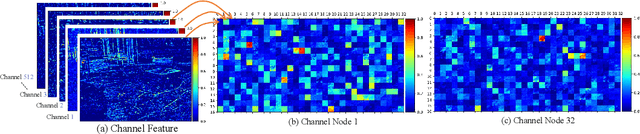
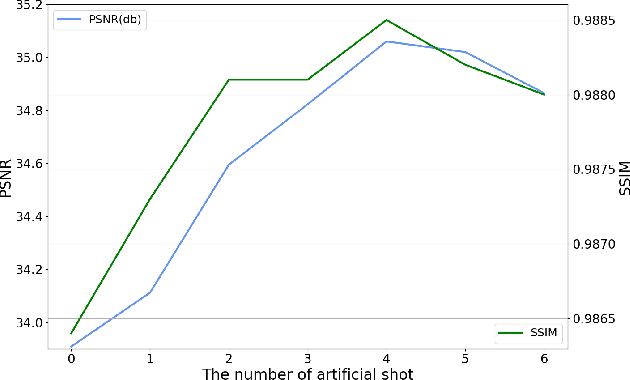
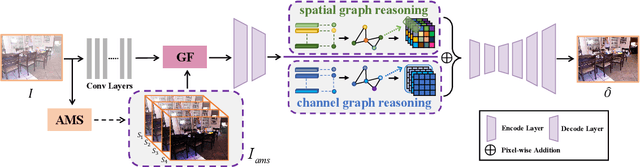
Due to the lack of natural scene and haze prior information, it is greatly challenging to completely remove the haze from single image without distorting its visual content. Fortunately, the real-world haze usually presents non-homogeneous distribution, which provides us with many valuable clues in partial well-preserved regions. In this paper, we propose a Non-Homogeneous Haze Removal Network (NHRN) via artificial scene prior and bidimensional graph reasoning. Firstly, we employ the gamma correction iteratively to simulate artificial multiple shots under different exposure conditions, whose haze degrees are different and enrich the underlying scene prior. Secondly, beyond utilizing the local neighboring relationship, we build a bidimensional graph reasoning module to conduct non-local filtering in the spatial and channel dimensions of feature maps, which models their long-range dependency and propagates the natural scene prior between the well-preserved nodes and the nodes contaminated by haze. We evaluate our method on different benchmark datasets. The results demonstrate that our method achieves superior performance over many state-of-the-art algorithms for both the single image dehazing and hazy image understanding tasks.
BA^2M: A Batch Aware Attention Module for Image Classification
Mar 28, 2021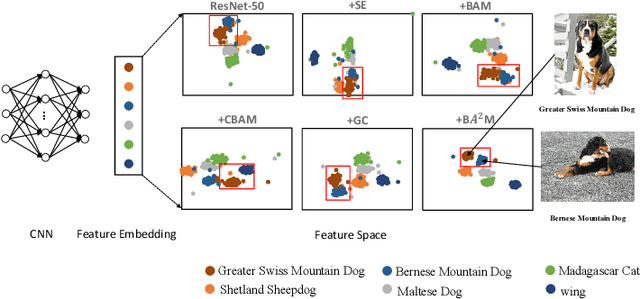
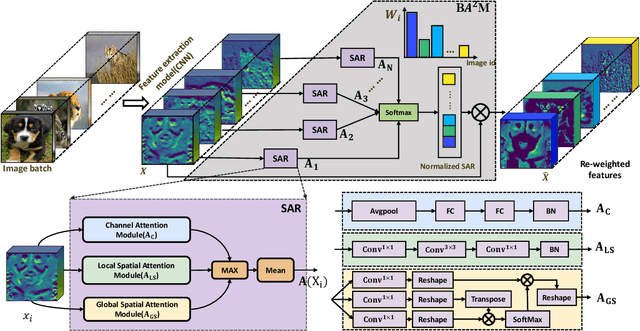
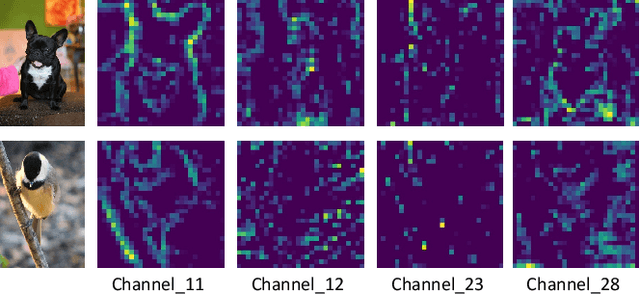
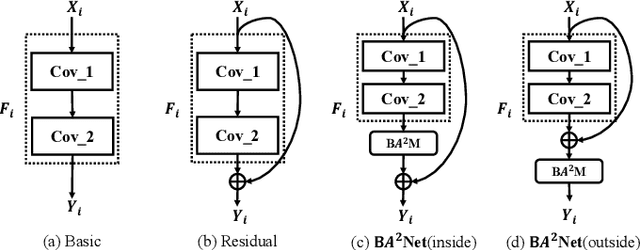
The attention mechanisms have been employed in Convolutional Neural Network (CNN) to enhance the feature representation. However, existing attention mechanisms only concentrate on refining the features inside each sample and neglect the discrimination between different samples. In this paper, we propose a batch aware attention module (BA2M) for feature enrichment from a distinctive perspective. More specifically, we first get the sample-wise attention representation (SAR) by fusing the channel, local spatial and global spatial attention maps within each sample. Then, we feed the SARs of the whole batch to a normalization function to get the weights for each sample. The weights serve to distinguish the features' importance between samples in a training batch with different complexity of content. The BA2M could be embedded into different parts of CNN and optimized with the network in an end-to-end manner. The design of BA2M is lightweight with few extra parameters and calculations. We validate BA2M through extensive experiments on CIFAR-100 and ImageNet-1K for the image recognition task. The results show that BA2M can boost the performance of various network architectures and outperforms many classical attention methods. Besides, BA2M exceeds traditional methods of re-weighting samples based on the loss value.