 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupling Contact for Fine-Grained Motion Style Transfer
Sep 09, 2024Motion style transfer changes the style of a motion while retaining its content and is useful in computer animations and games. Contact is an essential component of motion style transfer that should be controlled explicitly in order to express the style vividly while enhancing motion naturalness and quality. However, it is unknown how to decouple and control contact to achieve fine-grained control in motion style transfer. In this paper, we present a novel style transfer method for fine-grained control over contacts while achieving both motion naturalness and spatial-temporal variations of style. Based on our empirical evidence, we propose controlling contact indirectly through the hip velocity, which can be further decomposed into the trajectory and contact timing, respectively. To this end, we propose a new model that explicitly models the correlations between motions and trajectory/contact timing/style, allowing us to decouple and control each separately. Our approach is built around a motion manifold, where hip controls can be easily integrated into a Transformer-based decoder. It is versatile in that it can generate motions directly as well as be used as post-processing for existing methods to improve quality and contact controllability. In addition, we propose a new metric that measures a correlation pattern of motions based on our empirical evidence, aligning well with human perception in terms of motion naturalness. Based on extensive evaluation, our method outperforms existing methods in terms of style expressivity and motion quality.
DreamMat: High-quality PBR Material Generation with Geometry- and Light-aware Diffusion Models
May 27, 20242D diffusion model, which often contains unwanted baked-in shading effects and results in unrealistic rendering effects in the downstream applications. Generating Physically Based Rendering (PBR) materials instead of just RGB textures would be a promising solution. However, directly distilling the PBR material parameters from 2D diffusion models still suffers from incorrect material decomposition, such as baked-in shading effects in albedo. We introduce DreamMat, an innovative approach to resolve the aforementioned problem, to generate high-quality PBR materials from text descriptions. We find out that the main reason for the incorrect material distillation is that large-scale 2D diffusion models are only trained to generate final shading colors, resulting in insufficient constraints on material decomposition during distillation. To tackle this problem, we first finetune a new light-aware 2D diffusion model to condition on a given lighting environment and generate the shading results on this specific lighting condition. Then, by applying the same environment lights in the material distillation, DreamMat can generate high-quality PBR materials that are not only consistent with the given geometry but also free from any baked-in shading effects in albedo. Extensive experiments demonstrate that the materials produced through our methods exhibit greater visual appeal to users and achieve significantly superior rendering quality compared to baseline methods, which are preferable for downstream tasks such as game and film production.
A Locality-based Neural Solver for Optical Motion Capture
Sep 04, 2023We present a novel locality-based learning method for cleaning and solving optical motion capture data. Given noisy marker data, we propose a new heterogeneous graph neural network which treats markers and joints as different types of nodes, and uses graph convolution operations to extract the local features of markers and joints and transform them to clean motions. To deal with anomaly markers (e.g. occluded or with big tracking errors), the key insight is that a marker's motion shows strong correlations with the motions of its immediate neighboring markers but less so with other markers, a.k.a. locality, which enables us to efficiently fill missing markers (e.g. due to occlusion). Additionally, we also identify marker outliers due to tracking errors by investigating their acceleration profiles. Finally, we propose a training regime based on representation learning and data augmentation, by training the model on data with masking. The masking schemes aim to mimic the occluded and noisy markers often observed in the real data. Finally, we show that our method achieves high accuracy on multiple metrics across various datasets. Extensive comparison shows our method outperforms state-of-the-art methods in terms of prediction accuracy of occluded marker position error by approximately 20%, which leads to a further error reduction on the reconstructed joint rotations and positions by 30%. The code and data for this paper are available at https://github.com/non-void/LocalMoCap.
RSMT: Real-time Stylized Motion Transition for Characters
Jun 21, 2023



Styled online in-between motion generation has important application scenarios in computer animation and games. Its core challenge lies in the need to satisfy four critical requirements simultaneously: generation speed, motion quality, style diversity, and synthesis controllability. While the first two challenges demand a delicate balance between simple fast models and learning capacity for generation quality, the latter two are rarely investigated together in existing methods, which largely focus on either control without style or uncontrolled stylized motions. To this end, we propose a Real-time Stylized Motion Transition method (RSMT) to achieve all aforementioned goals. Our method consists of two critical, independent components: a general motion manifold model and a style motion sampler. The former acts as a high-quality motion source and the latter synthesizes styled motions on the fly under control signals. Since both components can be trained separately on different datasets, our method provides great flexibility, requires less data, and generalizes well when no/few samples are available for unseen styles. Through exhaustive evaluation, our method proves to be fast, high-quality, versatile, and controllable. The code and data are available at {https://github.com/yuyujunjun/RSMT-Realtime-Stylized-Motion-Transition.}
CTSN: Predicting Cloth Deformation for Skeleton-based Characters with a Two-stream Skinning Network
May 30, 2023



We present a novel learning method to predict the cloth deformation for skeleton-based characters with a two-stream network. The characters processed in our approach are not limited to humans, and can be other skeletal-based representations of non-human targets such as fish or pets. We use a novel network architecture which consists of skeleton-based and mesh-based residual networks to learn the coarse and wrinkle features as the overall residual from the template cloth mesh. Our network is used to predict the deformation for loose or tight-fitting clothing or dresses. We ensure that the memory footprint of our network is low, and thereby result in reduced storage and computational requirements. In practice, our prediction for a single cloth mesh for the skeleton-based character takes about 7 milliseconds on an NVIDIA GeForce RTX 3090 GPU. Compared with prior methods, our network can generate fine deformation results with details and wrinkles.
Real-time Controllable Motion Transition for Characters
May 05, 2022

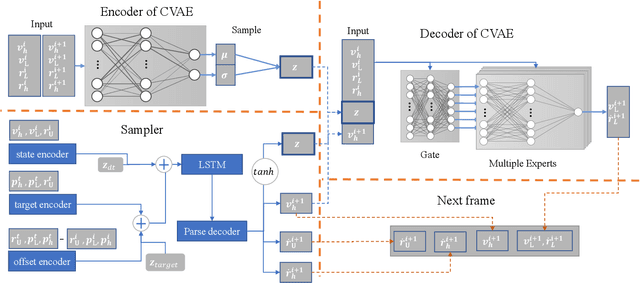
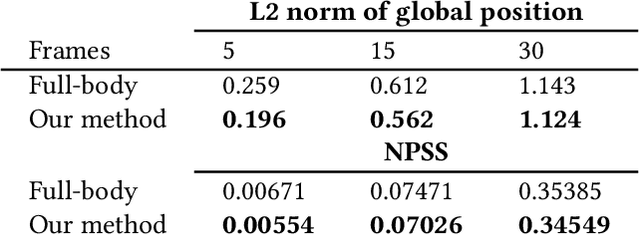
Real-time in-between motion generation is universally required in games and highly desirable in existing animation pipelines. Its core challenge lies in the need to satisfy three critical conditions simultaneously: quality, controllability and speed, which renders any methods that need offline computation (or post-processing) or cannot incorporate (often unpredictable) user control undesirable. To this end, we propose a new real-time transition method to address the aforementioned challenges. Our approach consists of two key components: motion manifold and conditional transitioning. The former learns the important low-level motion features and their dynamics; while the latter synthesizes transitions conditioned on a target frame and the desired transition duration. We first learn a motion manifold that explicitly models the intrinsic transition stochasticity in human motions via a multi-modal mapping mechanism. Then, during generation, we design a transition model which is essentially a sampling strategy to sample from the learned manifold, based on the target frame and the aimed transition duration. We validate our method on different datasets in tasks where no post-processing or offline computation is allowed. Through exhaustive evaluation and comparison, we show that our method is able to generate high-quality motions measured under multiple metrics. Our method is also robust under various target frames (with extreme cases).