 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatterhorn: Efficient Analog Sparse Spiking Transformer Architecture with Masked Time-To-First-Spike Encoding
Jan 30, 2026Spiking neural networks (SNNs) have emerged as a promising candidate for energy-efficient LLM inference. However, current energy evaluations for SNNs primarily focus on counting accumulate operations, and fail to account for real-world hardware costs such as data movement, which can consume nearly 80% of the total energy. In this paper, we propose Matterhorn, a spiking transformer that integrates a novel masked time-to-first-spike (M-TTFS) encoding method to reduce spike movement and a memristive synapse unit (MSU) to eliminate weight access overhead. M-TTFS employs a masking strategy that reassigns the zero-energy silent state (a spike train of all 0s) to the most frequent membrane potential rather than the lowest. This aligns the coding scheme with the data distribution, minimizing spike movement energy without information loss. We further propose a `dead zone' strategy that maximizes sparsity by mapping all values within a given range to the silent state. At the hardware level, the MSU utilizes compute-in-memory (CIM) technology to perform analog integration directly within memory, effectively removing weight access costs. On the GLUE benchmark, Matterhorn establishes a new state-of-the-art, surpassing existing SNNs by 1.42% in average accuracy while delivering a 2.31 times improvement in energy efficiency.
The Quick Red Fox gets the best Data Driven Classroom Interviews: A manual for an interview app and its associated methodology
Nov 17, 2025



Data Driven Classroom Interviews (DDCIs) are an interviewing technique that is facilitated by recent technological developments in the learning analytics community. DDCIs are short, targeted interviews that allow researchers to contextualize students' interactions with a digital learning environment (e.g., intelligent tutoring systems or educational games) while minimizing the amount of time that the researcher interrupts that learning experience, and focusing researcher time on the events they most want to focus on DDCIs are facilitated by a research tool called the Quick Red Fox (QRF)--an open-source server-client Android app that optimizes researcher time by directing interviewers to users that have just displayed an interesting behavior (previously defined by the research team). QRF integrates with existing student modeling technologies (e.g., behavior-sensing, affect-sensing, detection of self-regulated learning) to alert researchers to key moments in a learner's experience. This manual documents the tech while providing training on the processes involved in developing triggers and interview techniques; it also suggests methods of analyses.
Human-Inspired Audio-Visual Speech Recognition: Spike Activity, Cueing Interaction and Causal Processing
Aug 29, 2024



Humans naturally perform audiovisual speech recognition (AVSR), enhancing the accuracy and robustness by integrating auditory and visual information. Spiking neural networks (SNNs), which mimic the brain's information-processing mechanisms, are well-suited for emulating the human capability of AVSR. Despite their potential, research on SNNs for AVSR is scarce, with most existing audio-visual multimodal methods focused on object or digit recognition. These models simply integrate features from both modalities, neglecting their unique characteristics and interactions. Additionally, they often rely on future information for current processing, which increases recognition latency and limits real-time applicability. Inspired by human speech perception, this paper proposes a novel human-inspired SNN named HI-AVSNN for AVSR, incorporating three key characteristics: cueing interaction, causal processing and spike activity. For cueing interaction, we propose a visual-cued auditory attention module (VCA2M) that leverages visual cues to guide attention to auditory features. We achieve causal processing by aligning the SNN's temporal dimension with that of visual and auditory features and applying temporal masking to utilize only past and current information. To implement spike activity, in addition to using SNNs, we leverage the event camera to capture lip movement as spikes, mimicking the human retina and providing efficient visual data. We evaluate HI-AVSNN on an audiovisual speech recognition dataset combining the DVS-Lip dataset with its corresponding audio samples. Experimental results demonstrate the superiority of our proposed fusion method, outperforming existing audio-visual SNN fusion methods and achieving a 2.27% improvement in accuracy over the only existing SNN-based AVSR method.
ED-sKWS: Early-Decision Spiking Neural Networks for Rapid,and Energy-Efficient Keyword Spotting
Jun 14, 2024Keyword Spotting (KWS) is essential in edge computing requiring rapid and energy-efficient responses. Spiking Neural Networks (SNNs) are well-suited for KWS for their efficiency and temporal capacity for speech. To further reduce the latency and energy consumption, this study introduces ED-sKWS, an SNN-based KWS model with an early-decision mechanism that can stop speech processing and output the result before the end of speech utterance. Furthermore, we introduce a Cumulative Temporal (CT) loss that can enhance prediction accuracy at both the intermediate and final timesteps. To evaluate early-decision performance, we present the SC-100 dataset including 100 speech commands with beginning and end timestamp annotation. Experiments on the Google Speech Commands v2 and our SC-100 datasets show that ED-sKWS maintains competitive accuracy with 61% timesteps and 52% energy consumption compared to SNN models without early-decision mechanism, ensuring rapid response and energy efficiency.
sVAD: A Robust, Low-Power, and Light-Weight Voice Activity Detection with Spiking Neural Networks
Mar 09, 2024Speech applications are expected to be low-power and robust under noisy conditions. An effective Voice Activity Detection (VAD) front-end lowers the computational need. Spiking Neural Networks (SNNs) are known to be biologically plausible and power-efficient. However, SNN-based VADs have yet to achieve noise robustness and often require large models for high performance. This paper introduces a novel SNN-based VAD model, referred to as sVAD, which features an auditory encoder with an SNN-based attention mechanism. Particularly, it provides effective auditory feature representation through SincNet and 1D convolution, and improves noise robustness with attention mechanisms. The classifier utilizes Spiking Recurrent Neural Networks (sRNN) to exploit temporal speech information. Experimental results demonstrate that our sVAD achieves remarkable noise robustness and meanwhile maintains low power consumption and a small footprint, making it a promising solution for real-world VAD applications.
LitE-SNN: Designing Lightweight and Efficient Spiking Neural Network through Spatial-Temporal Compressive Network Search and Joint Optimization
Jan 26, 2024Spiking Neural Networks (SNNs) mimic the information-processing mechanisms of the human brain and are highly energy-efficient, making them well-suited for low-power edge devices. However, the pursuit of accuracy in current studies leads to large, long-timestep SNNs, conflicting with the resource constraints of these devices. In order to design lightweight and efficient SNNs, we propose a new approach named LitESNN that incorporates both spatial and temporal compression into the automated network design process. Spatially, we present a novel Compressive Convolution block (CompConv) to expand the search space to support pruning and mixed-precision quantization while utilizing the shared weights and pruning mask to reduce the computation. Temporally, we are the first to propose a compressive timestep search to identify the optimal number of timesteps under specific computation cost constraints. Finally, we formulate a joint optimization to simultaneously learn the architecture parameters and spatial-temporal compression strategies to achieve high performance while minimizing memory and computation costs. Experimental results on CIFAR10, CIFAR100, and Google Speech Command datasets demonstrate our proposed LitESNNs can achieve competitive or even higher accuracy with remarkably smaller model sizes and fewer computation costs. Furthermore, we validate the effectiveness of our LitESNN on the trade-off between accuracy and resource cost and show the superiority of our joint optimization. Additionally, we conduct energy analysis to further confirm the energy efficiency of LitESNN
Multi-Level Firing with Spiking DS-ResNet: Enabling Better and Deeper Directly-Trained Spiking Neural Networks
Oct 12, 2022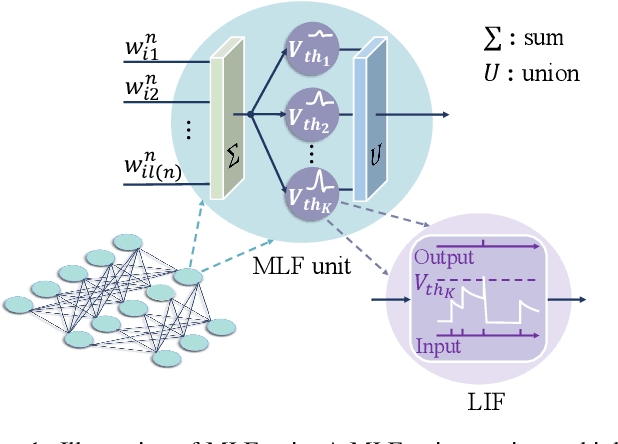
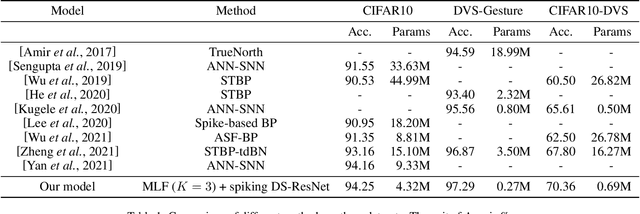
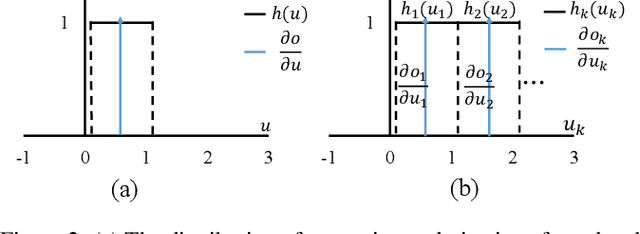

Spiking neural networks (SNNs) are bio-inspired neural networks with asynchronous discrete and sparse characteristics, which have increasingly manifested their superiority in low energy consumption. Recent research is devoted to utilizing spatio-temporal information to directly train SNNs by backpropagation. However, the binary and non-differentiable properties of spike activities force directly trained SNNs to suffer from serious gradient vanishing and network degradation, which greatly limits the performance of directly trained SNNs and prevents them from going deeper. In this paper, we propose a multi-level firing (MLF) method based on the existing spatio-temporal back propagation (STBP) method, and spiking dormant-suppressed residual network (spiking DS-ResNet). MLF enables more efficient gradient propagation and the incremental expression ability of the neurons. Spiking DS-ResNet can efficiently perform identity mapping of discrete spikes, as well as provide a more suitable connection for gradient propagation in deep SNNs. With the proposed method, our model achieves superior performances on a non-neuromorphic dataset and two neuromorphic datasets with much fewer trainable parameters and demonstrates the great ability to combat the gradient vanishing and degradation problem in deep SNNs.
TinyLight: Adaptive Traffic Signal Control on Devices with Extremely Limited Resources
May 01, 2022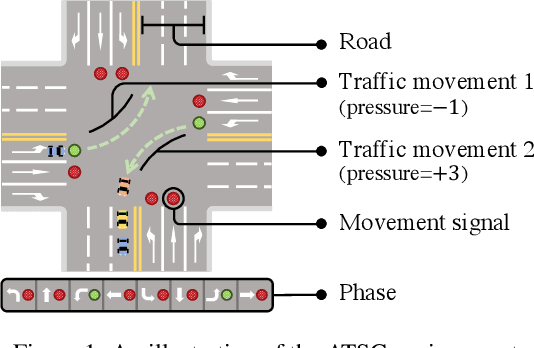
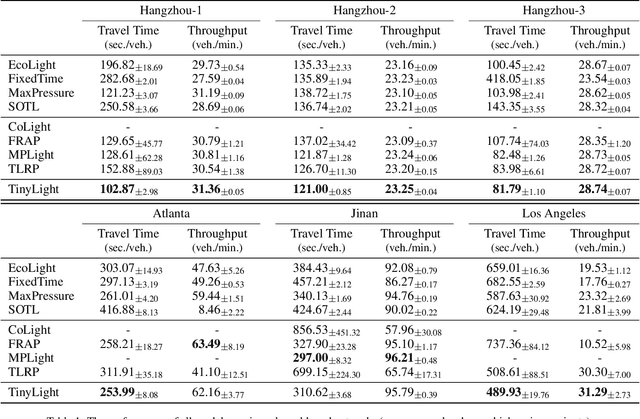
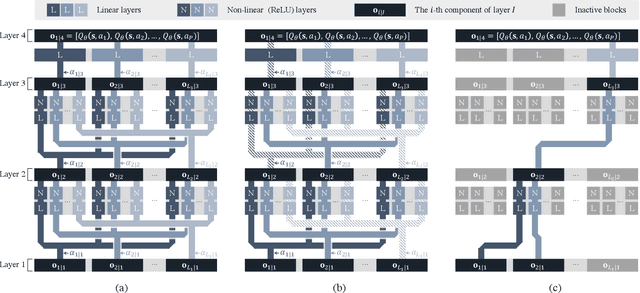

Recent advances in deep reinforcement learning (DRL) have largely promoted the performance of adaptive traffic signal control (ATSC). Nevertheless, regarding the implementation, most works are cumbersome in terms of storage and computation. This hinders their deployment on scenarios where resources are limited. In this work, we propose TinyLight, the first DRL-based ATSC model that is designed for devices with extremely limited resources. TinyLight first constructs a super-graph to associate a rich set of candidate features with a group of light-weighted network blocks. Then, to diminish the model's resource consumption, we ablate edges in the super-graph automatically with a novel entropy-minimized objective function. This enables TinyLight to work on a standalone microcontroller with merely 2KB RAM and 32KB ROM. We evaluate TinyLight on multiple road networks with real-world traffic demands. Experiments show that even with extremely limited resources, TinyLight still achieves competitive performance. The source code and appendix of this work can be found at \url{https://bit.ly/38hH8t8}.
Effective AER Object Classification Using Segmented Probability-Maximization Learning in Spiking Neural Networks
Feb 14, 2020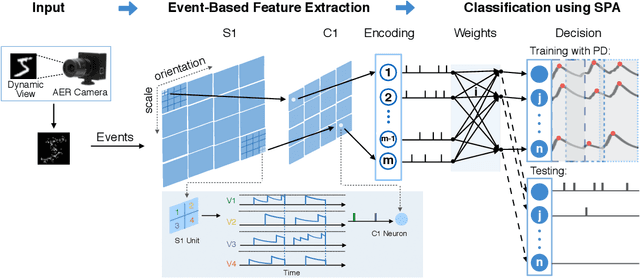

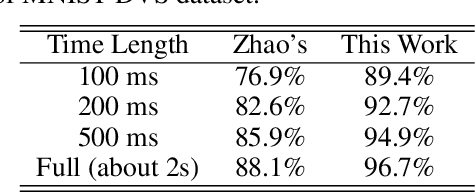

Address event representation (AER) cameras have recently attracted more attention due to the advantages of high temporal resolution and low power consumption, compared with traditional frame-based cameras. Since AER cameras record the visual input as asynchronous discrete events, they are inherently suitable to coordinate with the spiking neural network (SNN), which is biologically plausible and energy-efficient on neuromorphic hardware. However, using SNN to perform the AER object classification is still challenging, due to the lack of effective learning algorithms for this new representation. To tackle this issue, we propose an AER object classification model using a novel segmented probability-maximization (SPA) learning algorithm. Technically, 1) the SPA learning algorithm iteratively maximizes the probability of the classes that samples belong to, in order to improve the reliability of neuron responses and effectiveness of learning; 2) a peak detection (PD) mechanism is introduced in SPA to locate informative time points segment by segment, based on which information within the whole event stream can be fully utilized by the learning. Extensive experimental results show that, compared to state-of-the-art methods, not only our model is more effective, but also it requires less information to reach a certain level of accuracy.
Unsupervised AER Object Recognition Based on Multiscale Spatio-Temporal Features and Spiking Neurons
Nov 19, 2019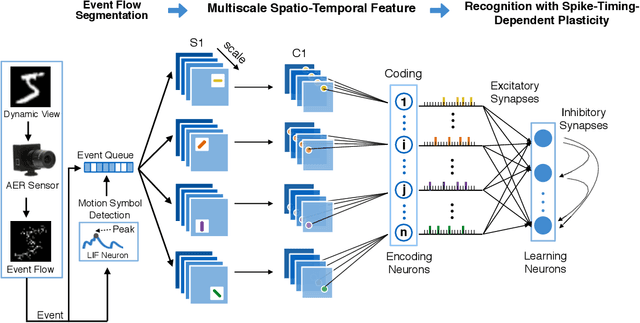
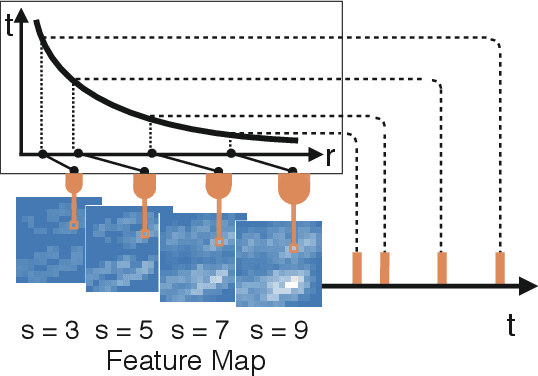
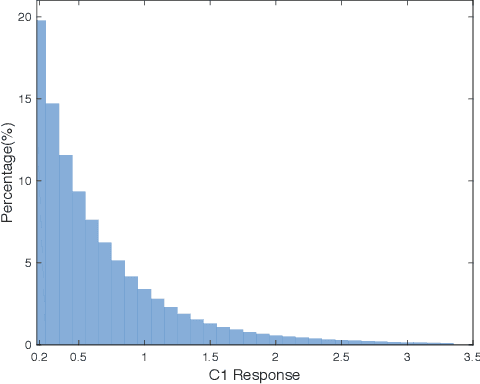
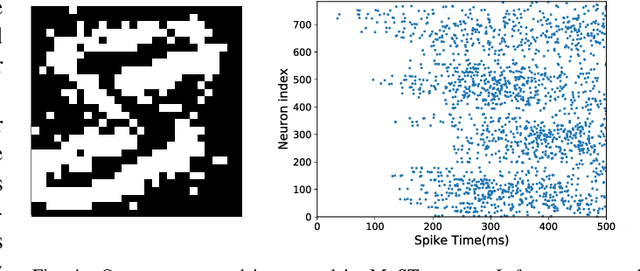
This paper proposes an unsupervised address event representation (AER) object recognition approach. The proposed approach consists of a novel multiscale spatio-temporal feature (MuST) representation of input AER events and a spiking neural network (SNN) using spike-timing-dependent plasticity (STDP) for object recognition with MuST. MuST extracts the features contained in both the spatial and temporal information of AER event flow, and meanwhile forms an informative and compact feature spike representation. We show not only how MuST exploits spikes to convey information more effectively, but also how it benefits the recognition using SNN. The recognition process is performed in an unsupervised manner, which does not need to specify the desired status of every single neuron of SNN, and thus can be flexibly applied in real-world recognition tasks. The experiments are performed on five AER datasets including a new one named GESTURE-DVS. Extensive experimental results show the effectiveness and advantages of this proposed approach.