 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonolingual Recognizers Fusion for Code-switching Speech Recognition
Nov 02, 2022The bi-encoder structure has been intensively investigated in code-switching (CS) automatic speech recognition (ASR). However, most existing methods require the structures of two monolingual ASR models (MAMs) should be the same and only use the encoder of MAMs. This leads to the problem that pre-trained MAMs cannot be timely and fully used for CS ASR. In this paper, we propose a monolingual recognizers fusion method for CS ASR. It has two stages: the speech awareness (SA) stage and the language fusion (LF) stage. In the SA stage, acoustic features are mapped to two language-specific predictions by two independent MAMs. To keep the MAMs focused on their own language, we further extend the language-aware training strategy for the MAMs. In the LF stage, the BELM fuses two language-specific predictions to get the final prediction. Moreover, we propose a text simulation strategy to simplify the training process of the BELM and reduce reliance on CS data. Experiments on a Mandarin-English corpus show the efficiency of the proposed method. The mix error rate is significantly reduced on the test set after using open-source pre-trained MAMs.
Joint Learning of Deep Texture and High-Frequency Features for Computer-Generated Image Detection
Sep 07, 2022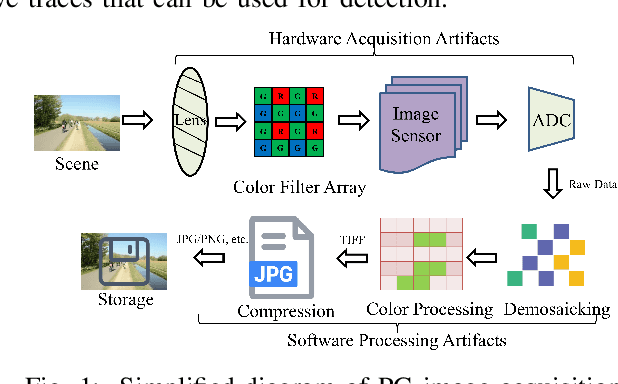
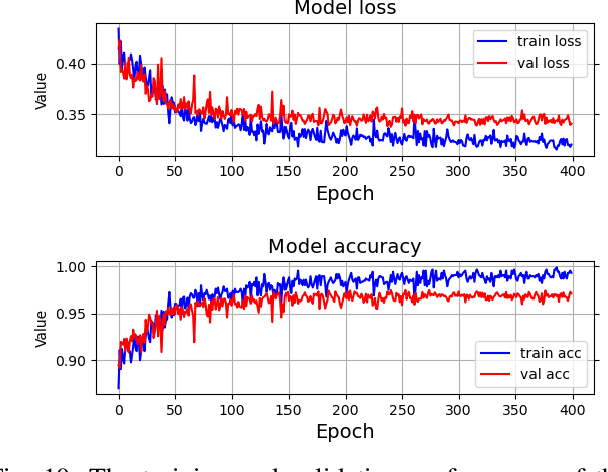

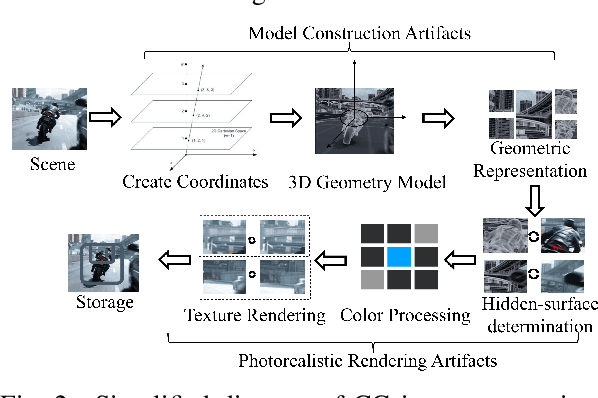
Distinguishing between computer-generated (CG) and natural photographic (PG) images is of great importance to verify the authenticity and originality of digital images. However, the recent cutting-edge generation methods enable high qualities of synthesis in CG images, which makes this challenging task even trickier. To address this issue, a joint learning strategy with deep texture and high-frequency features for CG image detection is proposed. We first formulate and deeply analyze the different acquisition processes of CG and PG images. Based on the finding that multiple different modules in image acquisition will lead to different sensitivity inconsistencies to the convolutional neural network (CNN)-based rendering in images, we propose a deep texture rendering module for texture difference enhancement and discriminative texture representation. Specifically, the semantic segmentation map is generated to guide the affine transformation operation, which is used to recover the texture in different regions of the input image. Then, the combination of the original image and the high-frequency components of the original and rendered images are fed into a multi-branch neural network equipped with attention mechanisms, which refines intermediate features and facilitates trace exploration in spatial and channel dimensions respectively. Extensive experiments on two public datasets and a newly constructed dataset with more realistic and diverse images show that the proposed approach outperforms existing methods in the field by a clear margin. Besides, results also demonstrate the detection robustness and generalization ability of the proposed approach to postprocessing operations and generative adversarial network (GAN) generated images.
SATformer: Transformers for SAT Solving
Sep 02, 2022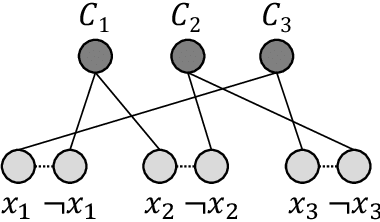

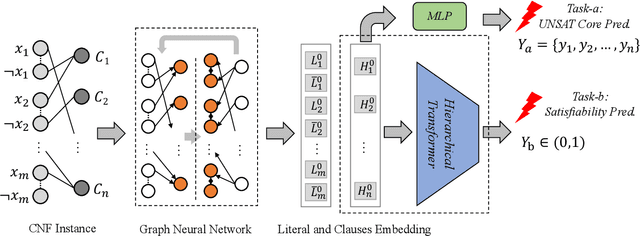
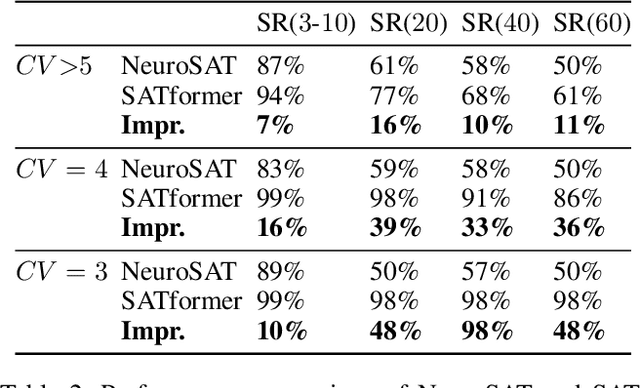
In this paper, we propose SATformer, a novel Transformer-based solution for Boolean satisfiability (SAT) solving. Different from existing learning-based SAT solvers that learn at the problem instance level, SATformer learns the minimum unsatisfiable cores (MUC) of unsatisfiable problem instances, which provide rich information for the causality of such problems. Specifically, we apply a graph neural network (GNN) to obtain the embeddings of the clauses in the conjunctive normal format (CNF). A hierarchical Transformer architecture is applied on the clause embeddings to capture the relationships among clauses, and the self-attention weight is learned to be high when those clauses forming UNSAT cores are attended together, and set to be low otherwise. By doing so, SATformer effectively learns the correlations among clauses for SAT prediction. Experimental results show that SATformer is more powerful than existing end-to-end learning-based SAT solvers.
Out-of-Distribution Detection with Semantic Mismatch under Masking
Jul 31, 2022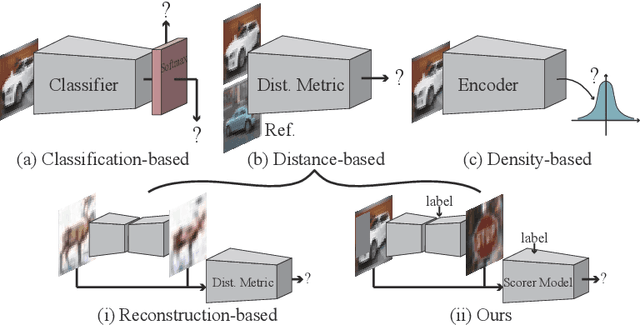
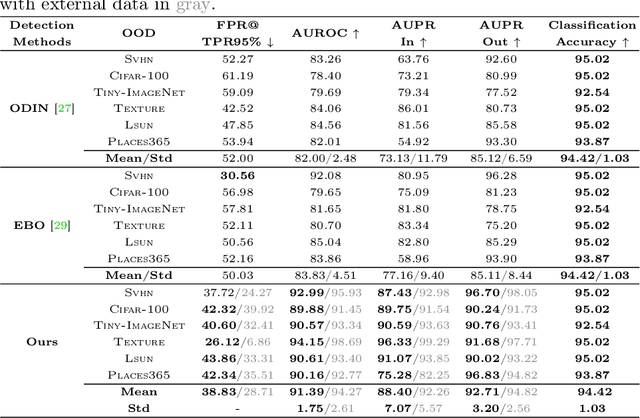
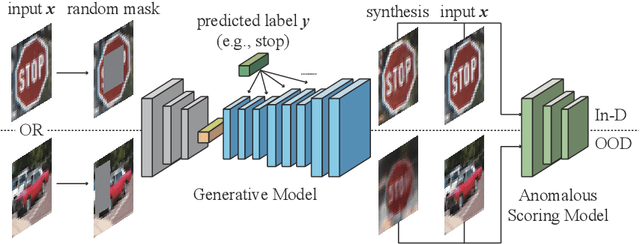
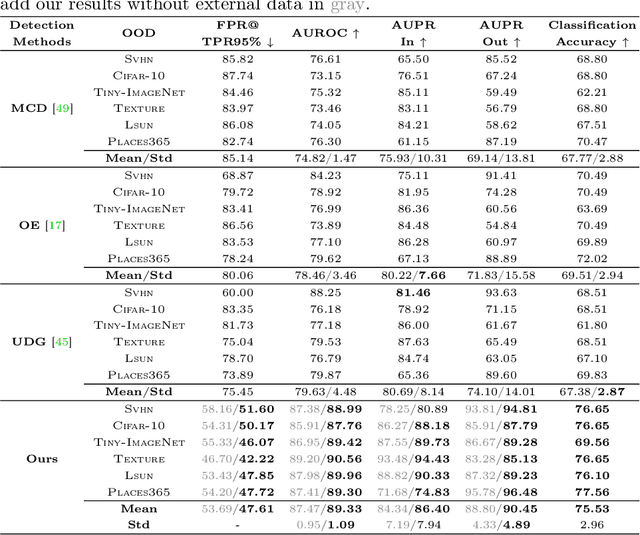
This paper proposes a novel out-of-distribution (OOD) detection framework named MoodCat for image classifiers. MoodCat masks a random portion of the input image and uses a generative model to synthesize the masked image to a new image conditioned on the classification result. It then calculates the semantic difference between the original image and the synthesized one for OOD detection. Compared to existing solutions, MoodCat naturally learns the semantic information of the in-distribution data with the proposed mask and conditional synthesis strategy, which is critical to identifying OODs. Experimental results demonstrate that MoodCat outperforms state-of-the-art OOD detection solutions by a large margin.
Language-specific Characteristic Assistance for Code-switching Speech Recognition
Jul 05, 2022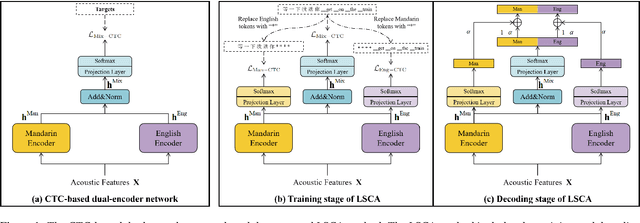
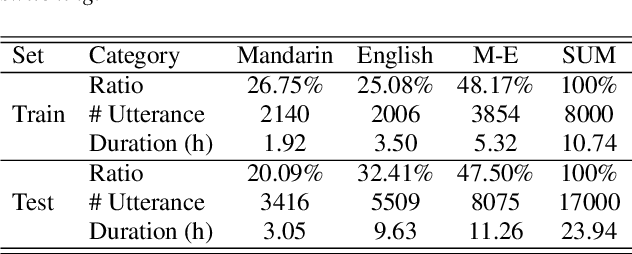

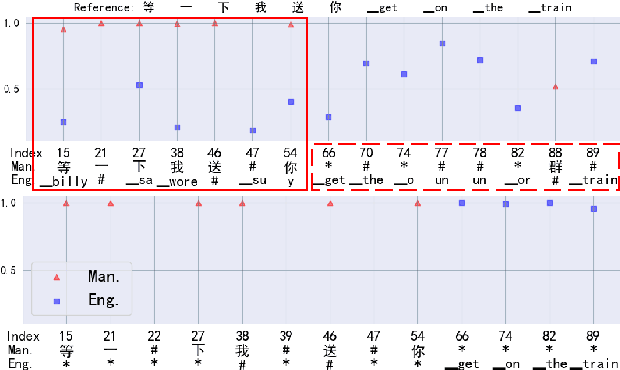
Dual-encoder structure successfully utilizes two language-specific encoders (LSEs) for code-switching speech recognition. Because LSEs are initialized by two pre-trained language-specific models (LSMs), the dual-encoder structure can exploit sufficient monolingual data and capture the individual language attributes. However, existing methods have no language constraints on LSEs and underutilize language-specific knowledge of LSMs. In this paper, we propose a language-specific characteristic assistance (LSCA) method to mitigate the above problems. Specifically, during training, we introduce two language-specific losses as language constraints and generate corresponding language-specific targets for them. During decoding, we take the decoding abilities of LSMs into account by combining the output probabilities of two LSMs and the mixture model to obtain the final predictions. Experiments show that either the training or decoding method of LSCA can improve the model's performance. Furthermore, the best result can obtain up to 15.4% relative error reduction on the code-switching test set by combining the training and decoding methods of LSCA. Moreover, the system can process code-switching speech recognition tasks well without extra shared parameters or even retraining based on two pre-trained LSMs by using our method.
DeepTPI: Test Point Insertion with Deep Reinforcement Learning
Jun 07, 2022
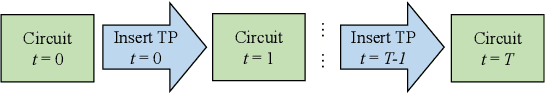
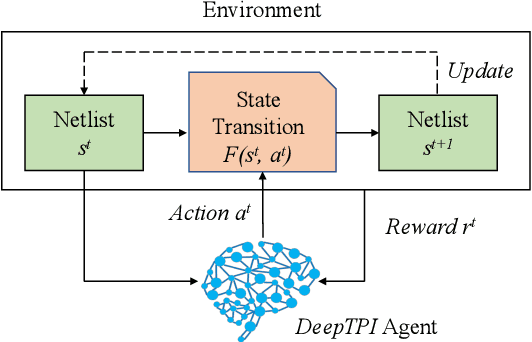
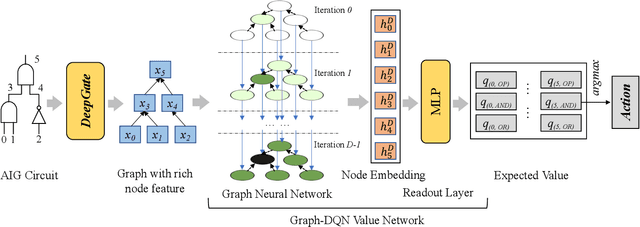
Test point insertion (TPI) is a widely used technique for testability enhancement, especially for logic built-in self-test (LBIST) due to its relatively low fault coverage. In this paper, we propose a novel TPI approach based on deep reinforcement learning (DRL), named DeepTPI. Unlike previous learning-based solutions that formulate the TPI task as a supervised-learning problem, we train a novel DRL agent, instantiated as the combination of a graph neural network (GNN) and a Deep Q-Learning network (DQN), to maximize the test coverage improvement. Specifically, we model circuits as directed graphs and design a graph-based value network to estimate the action values for inserting different test points. The policy of the DRL agent is defined as selecting the action with the maximum value. Moreover, we apply the general node embeddings from a pre-trained model to enhance node features, and propose a dedicated testability-aware attention mechanism for the value network. Experimental results on circuits with various scales show that DeepTPI significantly improves test coverage compared to the commercial DFT tool. The code of this work is available at https://github.com/cure-lab/DeepTPI.
Are Transformers Effective for Time Series Forecasting?
Jun 01, 2022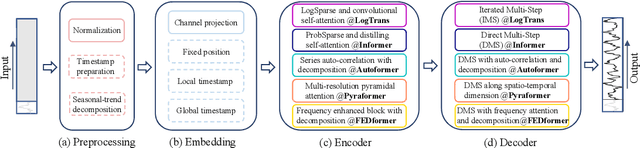

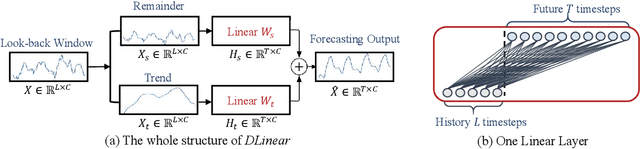
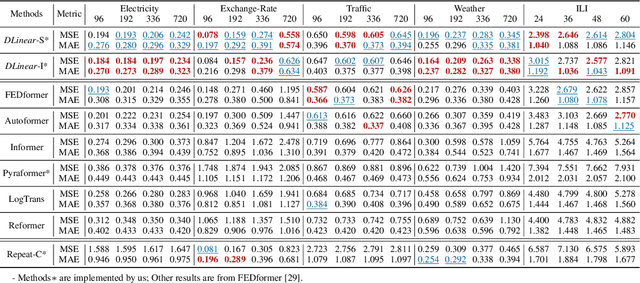
Recently, there has been a surge of Transformer-based solutions for the time series forecasting (TSF) task, especially for the challenging long-term TSF problem. Transformer architecture relies on self-attention mechanisms to effectively extract the semantic correlations between paired elements in a long sequence, which is permutation-invariant and anti-ordering to some extent. However, in time series modeling, we are to extract the temporal relations among an ordering set of continuous points. Consequently, whether Transformer-based techniques are the right solutions for long-term time series forecasting is an interesting problem to investigate, despite the performance improvements shown in these studies. In this work, we question the validity of Transformer-based TSF solutions. In their experiments, the compared (non-Transformer) baselines are mainly autoregressive forecasting solutions, which usually have a poor long-term prediction capability due to inevitable error accumulation effects. In contrast, we use an embarrassingly simple architecture named DLinear that conducts direct multi-step (DMS) forecasting for comparison. DLinear decomposes the time series into a trend and a remainder series and employs two one-layer linear networks to model these two series for the forecasting task. Surprisingly, it outperforms existing complex Transformer-based models in most cases by a large margin. Therefore, we conclude that the relatively higher long-term forecasting accuracy of Transformer-based TSF solutions shown in existing works has little to do with the temporal relation extraction capabilities of the Transformer architecture. Instead, it is mainly due to the non-autoregressive DMS forecasting strategy used in them. We hope this study also advocates revisiting the validity of Transformer-based solutions for other time series analysis tasks (e.g., anomaly detection) in the future.
DeepSAT: An EDA-Driven Learning Framework for SAT
May 27, 2022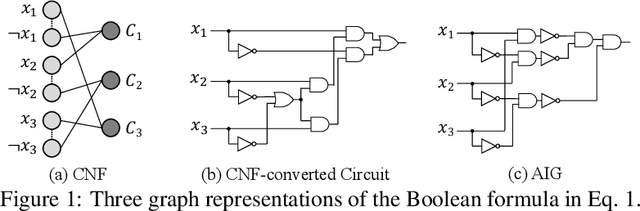
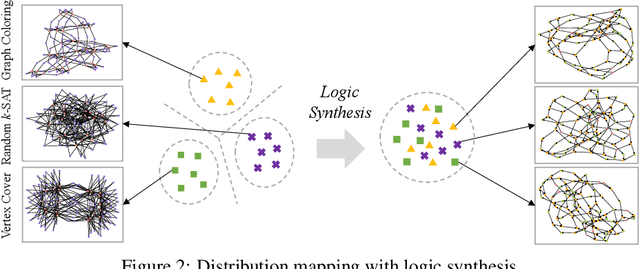
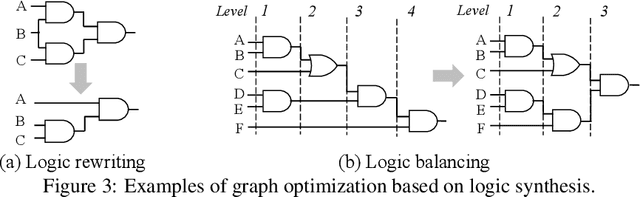
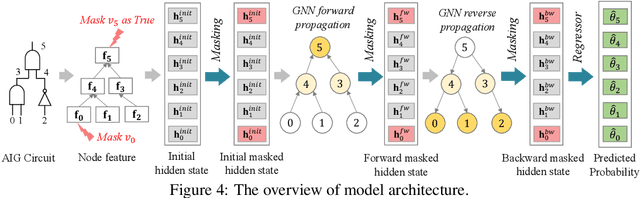
We present DeepSAT, a novel end-to-end learning framework for the Boolean satisfiability (SAT) problem. Unlike existing solutions trained on random SAT instances with relatively weak supervisions, we propose applying the knowledge of the well-developed electronic design automation (EDA) field for SAT solving. Specifically, we first resort to advanced logic synthesis algorithms to pre-process SAT instances into optimized and-inverter graphs (AIGs). By doing so, our training and test sets have a unified distribution, thus the learned model can generalize well to test sets of various sources of SAT instances. Next, we regard the distribution of SAT solutions being a product of conditional Bernoulli distributions. Based on this observation, we approximate the SAT solving procedure with a conditional generative model, leveraging a directed acyclic graph neural network with two polarity prototypes for conditional SAT modeling. To effectively train the generative model, with the help of logic simulation tools, we obtain the probabilities of nodes in the AIG being logic '1' as rich supervision. We conduct extensive experiments on various SAT instances. DeepSAT achieves significant accuracy improvements over state-of-the-art learning-based SAT solutions, especially when generalized to SAT instances that are large or with diverse distributions.
DeciWatch: A Simple Baseline for 10x Efficient 2D and 3D Pose Estimation
Mar 16, 2022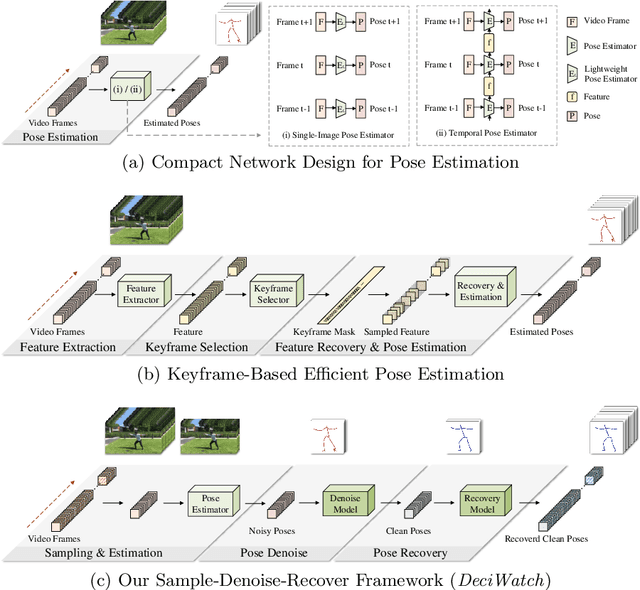
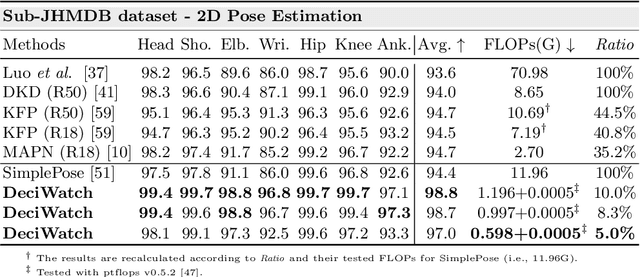
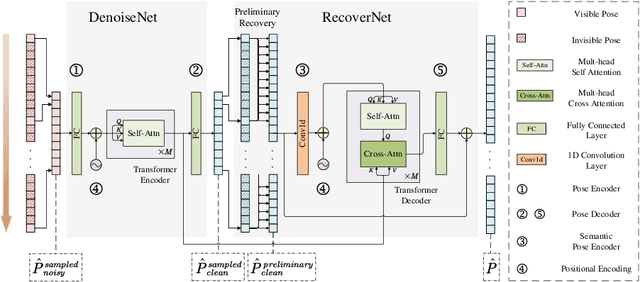
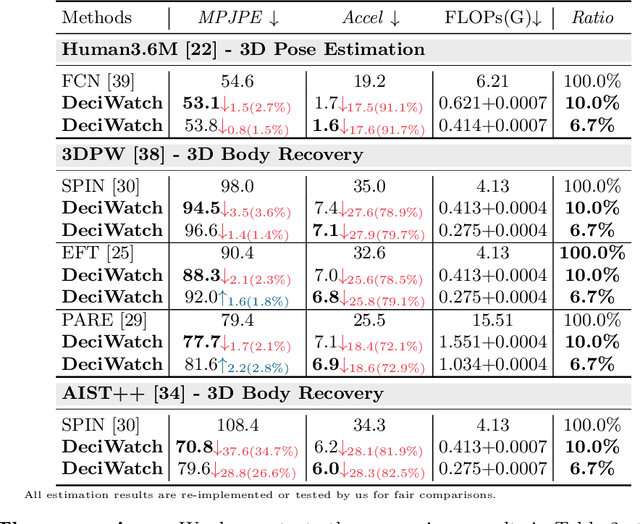
This paper proposes a simple baseline framework for video-based 2D/3D human pose estimation that can achieve 10 times efficiency improvement over existing works without any performance degradation, named DeciWatch. Unlike current solutions that estimate each frame in a video, DeciWatch introduces a simple yet effective sample-denoise-recover framework that only watches sparsely sampled frames, taking advantage of the continuity of human motions and the lightweight pose representation. Specifically, DeciWatch uniformly samples less than 10% video frames for detailed estimation, denoises the estimated 2D/3D poses with an efficient Transformer architecture, and then accurately recovers the rest of the frames using another Transformer-based network. Comprehensive experimental results on three video-based human pose estimation and body mesh recovery tasks with four datasets validate the efficiency and effectiveness of DeciWatch.
What You See is Not What the Network Infers: Detecting Adversarial Examples Based on Semantic Contradiction
Jan 24, 2022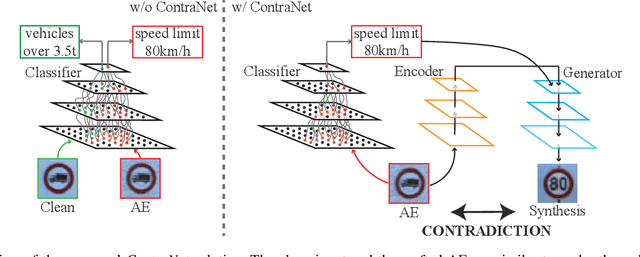

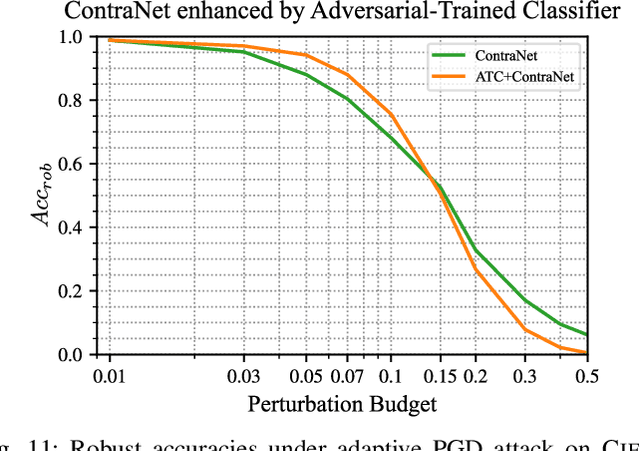

Adversarial examples (AEs) pose severe threats to the applications of deep neural networks (DNNs) to safety-critical domains, e.g., autonomous driving. While there has been a vast body of AE defense solutions, to the best of our knowledge, they all suffer from some weaknesses, e.g., defending against only a subset of AEs or causing a relatively high accuracy loss for legitimate inputs. Moreover, most existing solutions cannot defend against adaptive attacks, wherein attackers are knowledgeable about the defense mechanisms and craft AEs accordingly. In this paper, we propose a novel AE detection framework based on the very nature of AEs, i.e., their semantic information is inconsistent with the discriminative features extracted by the target DNN model. To be specific, the proposed solution, namely ContraNet, models such contradiction by first taking both the input and the inference result to a generator to obtain a synthetic output and then comparing it against the original input. For legitimate inputs that are correctly inferred, the synthetic output tries to reconstruct the input. On the contrary, for AEs, instead of reconstructing the input, the synthetic output would be created to conform to the wrong label whenever possible. Consequently, by measuring the distance between the input and the synthetic output with metric learning, we can differentiate AEs from legitimate inputs. We perform comprehensive evaluations under various AE attack scenarios, and experimental results show that ContraNet outperforms existing solutions by a large margin, especially under adaptive attacks. Moreover, our analysis shows that successful AEs that can bypass ContraNet tend to have much-weakened adversarial semantics. We have also shown that ContraNet can be easily combined with adversarial training techniques to achieve further improved AE defense capabilities.