 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRectified Flow: A Marginal Preserving Approach to Optimal Transport
Sep 29, 2022We present a flow-based approach to the optimal transport (OT) problem between two continuous distributions $\pi_0,\pi_1$ on $\mathbb{R}^d$, of minimizing a transport cost $\mathbb{E}[c(X_1-X_0)]$ in the set of couplings $(X_0,X_1)$ whose marginal distributions on $X_0,X_1$ equals $\pi_0,\pi_1$, respectively, where $c$ is a cost function. Our method iteratively constructs a sequence of neural ordinary differentiable equations (ODE), each learned by solving a simple unconstrained regression problem, which monotonically reduce the transport cost while automatically preserving the marginal constraints. This yields a monotonic interior approach that traverses inside the set of valid couplings to decrease the transport cost, which distinguishes itself from most existing approaches that enforce the coupling constraints from the outside. The main idea of the method draws from rectified flow, a recent approach that simultaneously decreases the whole family of transport costs induced by convex functions $c$ (and is hence multi-objective in nature), but is not tailored to minimize a specific transport cost. Our method is a single-object variant of rectified flow that guarantees to solve the OT problem for a fixed, user-specified convex cost function $c$.
Improving Molecular Pretraining with Complementary Featurizations
Sep 29, 2022
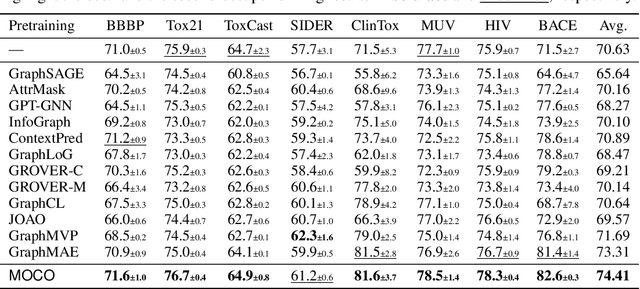
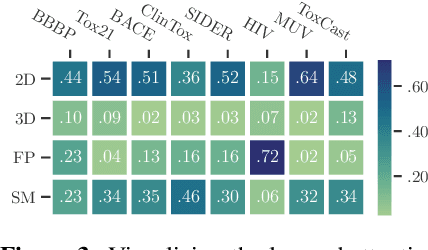
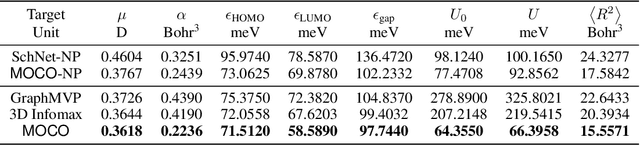
Molecular pretraining, which learns molecular representations over massive unlabeled data, has become a prominent paradigm to solve a variety of tasks in computational chemistry and drug discovery. Recently, prosperous progress has been made in molecular pretraining with different molecular featurizations, including 1D SMILES strings, 2D graphs, and 3D geometries. However, the role of molecular featurizations with their corresponding neural architectures in molecular pretraining remains largely unexamined. In this paper, through two case studies -- chirality classification and aromatic ring counting -- we first demonstrate that different featurization techniques convey chemical information differently. In light of this observation, we propose a simple and effective MOlecular pretraining framework with COmplementary featurizations (MOCO). MOCO comprehensively leverages multiple featurizations that complement each other and outperforms existing state-of-the-art models that solely relies on one or two featurizations on a wide range of molecular property prediction tasks.
BOME! Bilevel Optimization Made Easy: A Simple First-Order Approach
Sep 19, 2022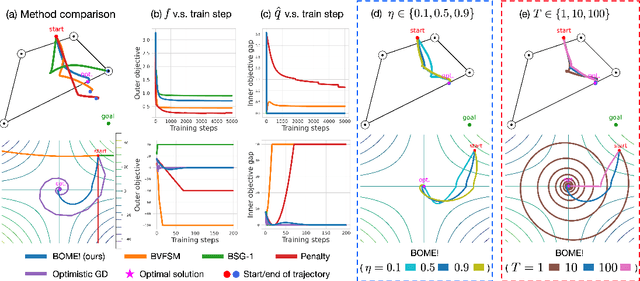
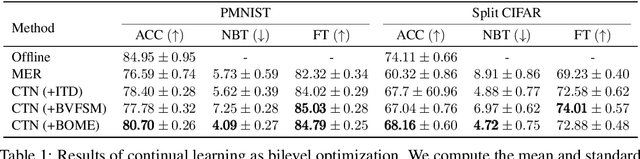
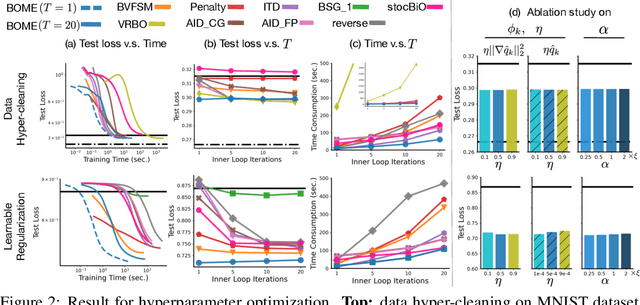
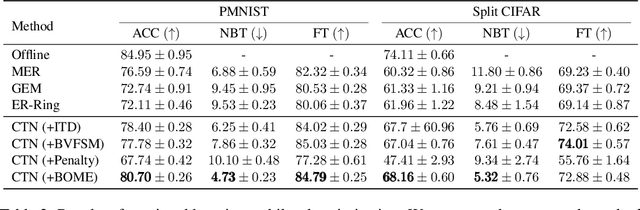
Bilevel optimization (BO) is useful for solving a variety of important machine learning problems including but not limited to hyperparameter optimization, meta-learning, continual learning, and reinforcement learning. Conventional BO methods need to differentiate through the low-level optimization process with implicit differentiation, which requires expensive calculations related to the Hessian matrix. There has been a recent quest for first-order methods for BO, but the methods proposed to date tend to be complicated and impractical for large-scale deep learning applications. In this work, we propose a simple first-order BO algorithm that depends only on first-order gradient information, requires no implicit differentiation, and is practical and efficient for large-scale non-convex functions in deep learning. We provide non-asymptotic convergence analysis of the proposed method to stationary points for non-convex objectives and present empirical results that show its superior practical performance.
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Sep 07, 2022
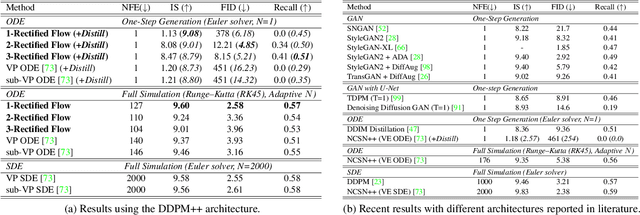


We present rectified flow, a surprisingly simple approach to learning (neural) ordinary differential equation (ODE) models to transport between two empirically observed distributions \pi_0 and \pi_1, hence providing a unified solution to generative modeling and domain transfer, among various other tasks involving distribution transport. The idea of rectified flow is to learn the ODE to follow the straight paths connecting the points drawn from \pi_0 and \pi_1 as much as possible. This is achieved by solving a straightforward nonlinear least squares optimization problem, which can be easily scaled to large models without introducing extra parameters beyond standard supervised learning. The straight paths are special and preferred because they are the shortest paths between two points, and can be simulated exactly without time discretization and hence yield computationally efficient models. We show that the procedure of learning a rectified flow from data, called rectification, turns an arbitrary coupling of \pi_0 and \pi_1 to a new deterministic coupling with provably non-increasing convex transport costs. In addition, recursively applying rectification allows us to obtain a sequence of flows with increasingly straight paths, which can be simulated accurately with coarse time discretization in the inference phase. In empirical studies, we show that rectified flow performs superbly on image generation, image-to-image translation, and domain adaptation. In particular, on image generation and translation, our method yields nearly straight flows that give high quality results even with a single Euler discretization step.
Factor Graph Accelerator for LiDAR-Inertial Odometry
Sep 06, 2022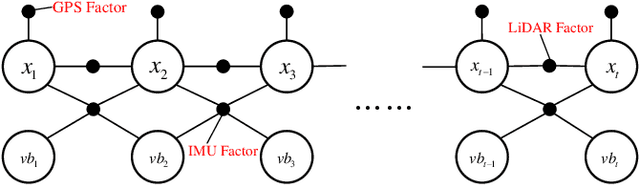
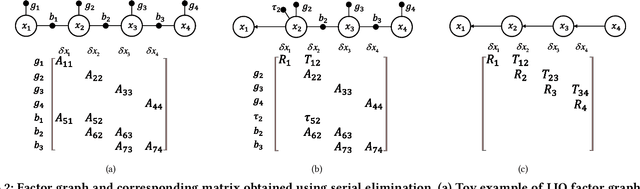
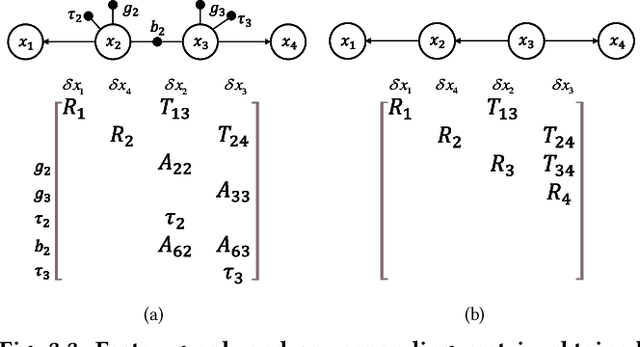

Factor graph is a graph representing the factorization of a probability distribution function, and has been utilized in many autonomous machine computing tasks, such as localization, tracking, planning and control etc. We are developing an architecture with the goal of using factor graph as a common abstraction for most, if not, all autonomous machine computing tasks. If successful, the architecture would provide a very simple interface of mapping autonomous machine functions to the underlying compute hardware. As a first step of such an attempt, this paper presents our most recent work of developing a factor graph accelerator for LiDAR-Inertial Odometry (LIO), an essential task in many autonomous machines, such as autonomous vehicles and mobile robots. By modeling LIO as a factor graph, the proposed accelerator not only supports multi-sensor fusion such as LiDAR, inertial measurement unit (IMU), GPS, etc., but solves the global optimization problem of robot navigation in batch or incremental modes. Our evaluation demonstrates that the proposed design significantly improves the real-time performance and energy efficiency of autonomous machine navigation systems. The initial success suggests the potential of generalizing the factor graph architecture as a common abstraction for autonomous machine computing, including tracking, planning, and control etc.
Deep Stable Representation Learning on Electronic Health Records
Sep 03, 2022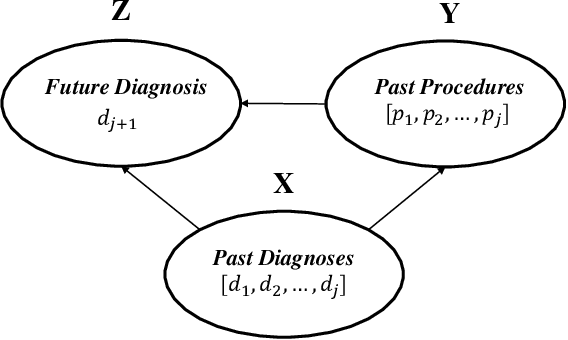
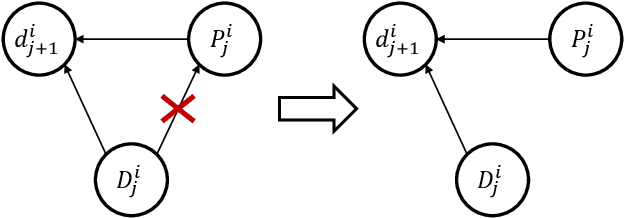
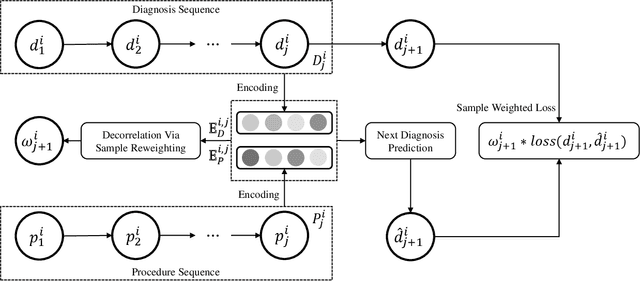
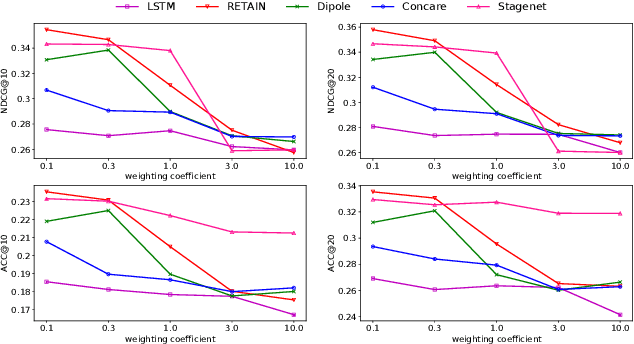
Deep learning models have achieved promising disease prediction performance of the Electronic Health Records (EHR) of patients. However, most models developed under the I.I.D. hypothesis fail to consider the agnostic distribution shifts, diminishing the generalization ability of deep learning models to Out-Of-Distribution (OOD) data. In this setting, spurious statistical correlations that may change in different environments will be exploited, which can cause sub-optimal performances of deep learning models. The unstable correlation between procedures and diagnoses existed in the training distribution can cause spurious correlation between historical EHR and future diagnosis. To address this problem, we propose to use a causal representation learning method called Causal Healthcare Embedding (CHE). CHE aims at eliminating the spurious statistical relationship by removing the dependencies between diagnoses and procedures. We introduce the Hilbert-Schmidt Independence Criterion (HSIC) to measure the degree of independence between the embedded diagnosis and procedure features. Based on causal view analyses, we perform the sample weighting technique to get rid of such spurious relationship for the stable learning of EHR across different environments. Moreover, our proposed CHE method can be used as a flexible plug-and-play module that can enhance existing deep learning models on EHR. Extensive experiments on two public datasets and five state-of-the-art baselines unequivocally show that CHE can improve the prediction accuracy of deep learning models on out-of-distribution data by a large margin. In addition, the interpretability study shows that CHE could successfully leverage causal structures to reflect a more reasonable contribution of historical records for predictions.
First Hitting Diffusion Models
Sep 02, 2022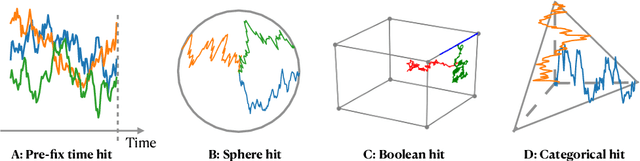
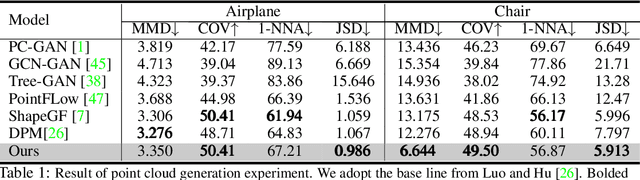
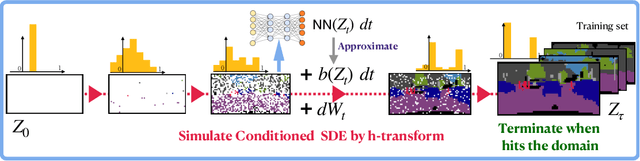
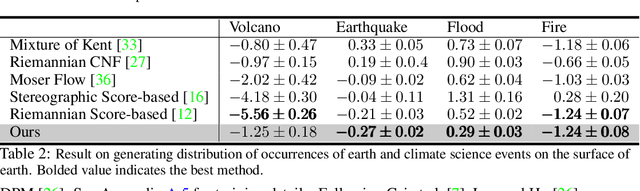
We propose a family of First Hitting Diffusion Models (FHDM), deep generative models that generate data with a diffusion process that terminates at a random first hitting time. This yields an extension of the standard fixed-time diffusion models that terminate at a pre-specified deterministic time. Although standard diffusion models are designed for continuous unconstrained data, FHDM is naturally designed to learn distributions on continuous as well as a range of discrete and structure domains. Moreover, FHDM enables instance-dependent terminate time and accelerates the diffusion process to sample higher quality data with fewer diffusion steps. Technically, we train FHDM by maximum likelihood estimation on diffusion trajectories augmented from observed data with conditional first hitting processes (i.e., bridge) derived based on Doob's $h$-transform, deviating from the commonly used time-reversal mechanism. We apply FHDM to generate data in various domains such as point cloud (general continuous distribution), climate and geographical events on earth (continuous distribution on the sphere), unweighted graphs (distribution of binary matrices), and segmentation maps of 2D images (high-dimensional categorical distribution). We observe considerable improvement compared with the state-of-the-art approaches in both quality and speed.
Future Gradient Descent for Adapting the Temporal Shifting Data Distribution in Online Recommendation Systems
Sep 02, 2022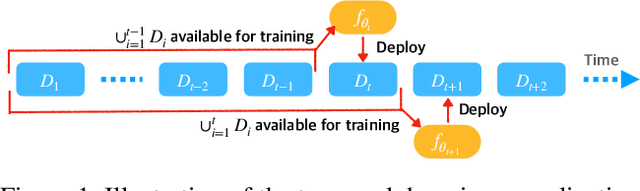
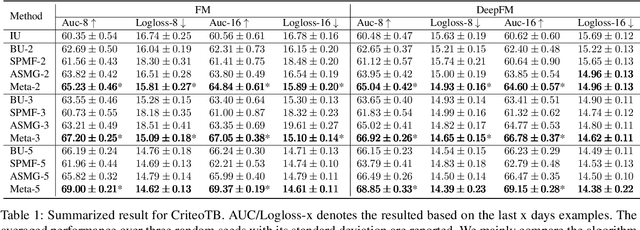
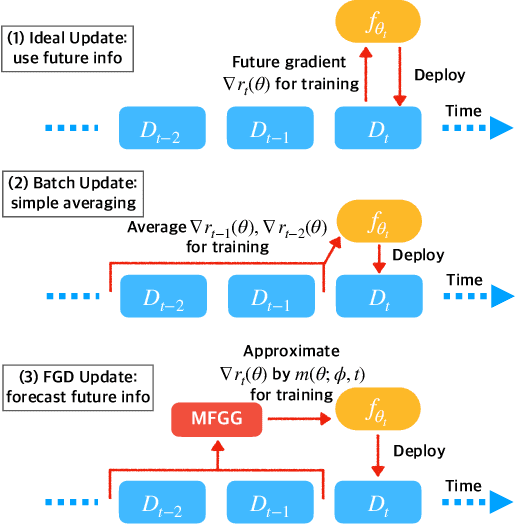
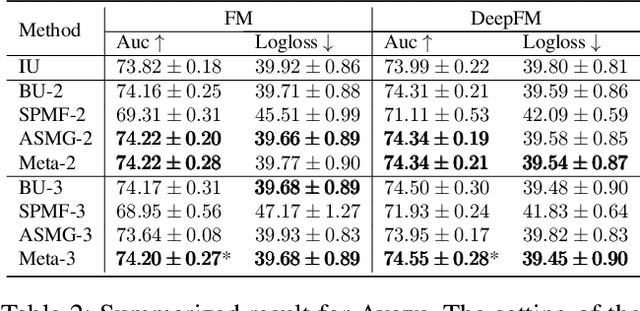
One of the key challenges of learning an online recommendation model is the temporal domain shift, which causes the mismatch between the training and testing data distribution and hence domain generalization error. To overcome, we propose to learn a meta future gradient generator that forecasts the gradient information of the future data distribution for training so that the recommendation model can be trained as if we were able to look ahead at the future of its deployment. Compared with Batch Update, a widely used paradigm, our theory suggests that the proposed algorithm achieves smaller temporal domain generalization error measured by a gradient variation term in a local regret. We demonstrate the empirical advantage by comparing with various representative baselines.
Diffusion-based Molecule Generation with Informative Prior Bridges
Sep 02, 2022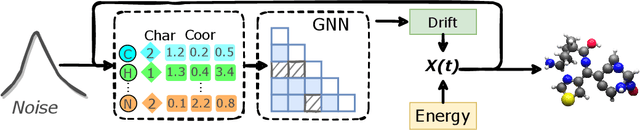
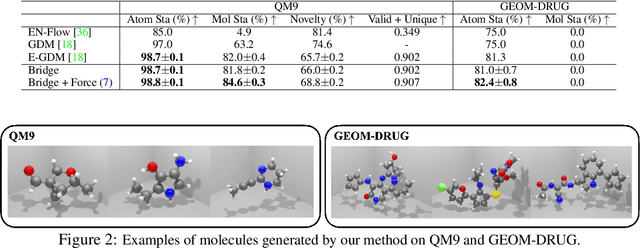


AI-based molecule generation provides a promising approach to a large area of biomedical sciences and engineering, such as antibody design, hydrolase engineering, or vaccine development. Because the molecules are governed by physical laws, a key challenge is to incorporate prior information into the training procedure to generate high-quality and realistic molecules. We propose a simple and novel approach to steer the training of diffusion-based generative models with physical and statistics prior information. This is achieved by constructing physically informed diffusion bridges, stochastic processes that guarantee to yield a given observation at the fixed terminal time. We develop a Lyapunov function based method to construct and determine bridges, and propose a number of proposals of informative prior bridges for both high-quality molecule generation and uniformity-promoted 3D point cloud generation. With comprehensive experiments, we show that our method provides a powerful approach to the 3D generation task, yielding molecule structures with better quality and stability scores and more uniformly distributed point clouds of high qualities.
Let us Build Bridges: Understanding and Extending Diffusion Generative Models
Aug 31, 2022
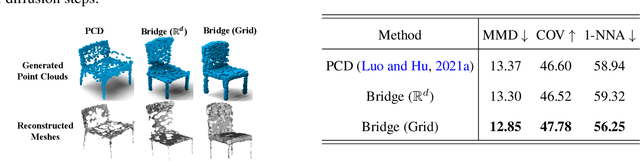
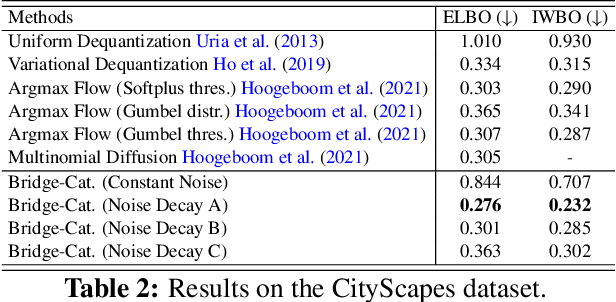
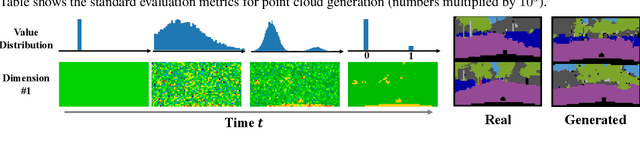
Diffusion-based generative models have achieved promising results recently, but raise an array of open questions in terms of conceptual understanding, theoretical analysis, algorithm improvement and extensions to discrete, structured, non-Euclidean domains. This work tries to re-exam the overall framework, in order to gain better theoretical understandings and develop algorithmic extensions for data from arbitrary domains. By viewing diffusion models as latent variable models with unobserved diffusion trajectories and applying maximum likelihood estimation (MLE) with latent trajectories imputed from an auxiliary distribution, we show that both the model construction and the imputation of latent trajectories amount to constructing diffusion bridge processes that achieve deterministic values and constraints at end point, for which we provide a systematic study and a suit of tools. Leveraging our framework, we present 1) a first theoretical error analysis for learning diffusion generation models, and 2) a simple and unified approach to learning on data from different discrete and constrained domains. Experiments show that our methods perform superbly on generating images, semantic segments and 3D point clouds.