 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR-4B: Incentivizing General-Purpose Auto-Thinking Capability in MLLMs via Bi-Mode Annealing and Reinforce Learning
Aug 28, 2025



Multimodal Large Language Models (MLLMs) equipped with step-by-step thinking capabilities have demonstrated remarkable performance on complex reasoning problems. However, this thinking process is redundant for simple problems solvable without complex reasoning. To address this inefficiency, we propose R-4B, an auto-thinking MLLM, which can adaptively decide when to think based on problem complexity. The central idea of R-4B is to empower the model with both thinking and non-thinking capabilities using bi-mode annealing, and apply Bi-mode Policy Optimization~(BPO) to improve the model's accuracy in determining whether to activate the thinking process. Specifically, we first train the model on a carefully curated dataset spanning various topics, which contains samples from both thinking and non-thinking modes. Then it undergoes a second phase of training under an improved GRPO framework, where the policy model is forced to generate responses from both modes for each input query. Experimental results show that R-4B achieves state-of-the-art performance across 25 challenging benchmarks. It outperforms Qwen2.5-VL-7B in most tasks and achieves performance comparable to larger models such as Kimi-VL-A3B-Thinking-2506 (16B) on reasoning-intensive benchmarks with lower computational cost.
3DGS-VBench: A Comprehensive Video Quality Evaluation Benchmark for 3DGS Compression
Aug 09, 20253D Gaussian Splatting (3DGS) enables real-time novel view synthesis with high visual fidelity, but its substantial storage requirements hinder practical deployment, prompting state-of-the-art (SOTA) 3DGS methods to incorporate compression modules. However, these 3DGS generative compression techniques introduce unique distortions lacking systematic quality assessment research. To this end, we establish 3DGS-VBench, a large-scale Video Quality Assessment (VQA) Dataset and Benchmark with 660 compressed 3DGS models and video sequences generated from 11 scenes across 6 SOTA 3DGS compression algorithms with systematically designed parameter levels. With annotations from 50 participants, we obtained MOS scores with outlier removal and validated dataset reliability. We benchmark 6 3DGS compression algorithms on storage efficiency and visual quality, and evaluate 15 quality assessment metrics across multiple paradigms. Our work enables specialized VQA model training for 3DGS, serving as a catalyst for compression and quality assessment research. The dataset is available at https://github.com/YukeXing/3DGS-VBench.
Rasterizing Wireless Radiance Field via Deformable 2D Gaussian Splatting
Jun 15, 2025Modeling the wireless radiance field (WRF) is fundamental to modern communication systems, enabling key tasks such as localization, sensing, and channel estimation. Traditional approaches, which rely on empirical formulas or physical simulations, often suffer from limited accuracy or require strong scene priors. Recent neural radiance field (NeRF-based) methods improve reconstruction fidelity through differentiable volumetric rendering, but their reliance on computationally expensive multilayer perceptron (MLP) queries hinders real-time deployment. To overcome these challenges, we introduce Gaussian splatting (GS) to the wireless domain, leveraging its efficiency in modeling optical radiance fields to enable compact and accurate WRF reconstruction. Specifically, we propose SwiftWRF, a deformable 2D Gaussian splatting framework that synthesizes WRF spectra at arbitrary positions under single-sided transceiver mobility. SwiftWRF employs CUDA-accelerated rasterization to render spectra at over 100000 fps and uses a lightweight MLP to model the deformation of 2D Gaussians, effectively capturing mobility-induced WRF variations. In addition to novel spectrum synthesis, the efficacy of SwiftWRF is further underscored in its applications in angle-of-arrival (AoA) and received signal strength indicator (RSSI) prediction. Experiments conducted on both real-world and synthetic indoor scenes demonstrate that SwiftWRF can reconstruct WRF spectra up to 500x faster than existing state-of-the-art methods, while significantly enhancing its signal quality. Code and datasets will be released.
Re-ranking Reasoning Context with Tree Search Makes Large Vision-Language Models Stronger
Jun 09, 2025Recent advancements in Large Vision Language Models (LVLMs) have significantly improved performance in Visual Question Answering (VQA) tasks through multimodal Retrieval-Augmented Generation (RAG). However, existing methods still face challenges, such as the scarcity of knowledge with reasoning examples and erratic responses from retrieved knowledge. To address these issues, in this study, we propose a multimodal RAG framework, termed RCTS, which enhances LVLMs by constructing a Reasoning Context-enriched knowledge base and a Tree Search re-ranking method. Specifically, we introduce a self-consistent evaluation mechanism to enrich the knowledge base with intrinsic reasoning patterns. We further propose a Monte Carlo Tree Search with Heuristic Rewards (MCTS-HR) to prioritize the most relevant examples. This ensures that LVLMs can leverage high-quality contextual reasoning for better and more consistent responses. Extensive experiments demonstrate that our framework achieves state-of-the-art performance on multiple VQA datasets, significantly outperforming In-Context Learning (ICL) and Vanilla-RAG methods. It highlights the effectiveness of our knowledge base and re-ranking method in improving LVLMs. Our code is available at https://github.com/yannqi/RCTS-RAG.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
DPCD: A Quality Assessment Database for Dynamic Point Clouds
May 18, 2025



Recently, the advancements in Virtual/Augmented Reality (VR/AR) have driven the demand for Dynamic Point Clouds (DPC). Unlike static point clouds, DPCs are capable of capturing temporal changes within objects or scenes, offering a more accurate simulation of the real world. While significant progress has been made in the quality assessment research of static point cloud, little study has been done on Dynamic Point Cloud Quality Assessment (DPCQA), which hinders the development of quality-oriented applications, such as interframe compression and transmission in practical scenarios. In this paper, we introduce a large-scale DPCQA database, named DPCD, which includes 15 reference DPCs and 525 distorted DPCs from seven types of lossy compression and noise distortion. By rendering these samples to Processed Video Sequences (PVS), a comprehensive subjective experiment is conducted to obtain Mean Opinion Scores (MOS) from 21 viewers for analysis. The characteristic of contents, impact of various distortions, and accuracy of MOSs are presented to validate the heterogeneity and reliability of the proposed database. Furthermore, we evaluate the performance of several objective metrics on DPCD. The experiment results show that DPCQA is more challenge than that of static point cloud. The DPCD, which serves as a catalyst for new research endeavors on DPCQA, is publicly available at https://huggingface.co/datasets/Olivialyt/DPCD.
On the Eligibility of LLMs for Counterfactual Reasoning: A Decompositional Study
May 17, 2025



Counterfactual reasoning has emerged as a crucial technique for generalizing the reasoning capabilities of large language models (LLMs). By generating and analyzing counterfactual scenarios, researchers can assess the adaptability and reliability of model decision-making. Although prior work has shown that LLMs often struggle with counterfactual reasoning, it remains unclear which factors most significantly impede their performance across different tasks and modalities. In this paper, we propose a decompositional strategy that breaks down the counterfactual generation from causality construction to the reasoning over counterfactual interventions. To support decompositional analysis, we investigate 11 datasets spanning diverse tasks, including natural language understanding, mathematics, programming, and vision-language tasks. Through extensive evaluations, we characterize LLM behavior across each decompositional stage and identify how modality type and intermediate reasoning influence performance. By establishing a structured framework for analyzing counterfactual reasoning, this work contributes to the development of more reliable LLM-based reasoning systems and informs future elicitation strategies.
Textured mesh Quality Assessment using Geometry and Color Field Similarity
May 16, 2025Textured mesh quality assessment (TMQA) is critical for various 3D mesh applications. However, existing TMQA methods often struggle to provide accurate and robust evaluations. Motivated by the effectiveness of fields in representing both 3D geometry and color information, we propose a novel point-based TMQA method called field mesh quality metric (FMQM). FMQM utilizes signed distance fields and a newly proposed color field named nearest surface point color field to realize effective mesh feature description. Four features related to visual perception are extracted from the geometry and color fields: geometry similarity, geometry gradient similarity, space color distribution similarity, and space color gradient similarity. Experimental results on three benchmark datasets demonstrate that FMQM outperforms state-of-the-art (SOTA) TMQA metrics. Furthermore, FMQM exhibits low computational complexity, making it a practical and efficient solution for real-world applications in 3D graphics and visualization. Our code is publicly available at: https://github.com/yyyykf/FMQM.
ADC-GS: Anchor-Driven Deformable and Compressed Gaussian Splatting for Dynamic Scene Reconstruction
May 13, 2025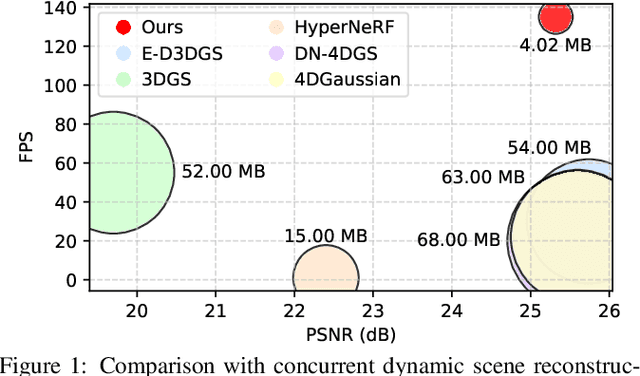
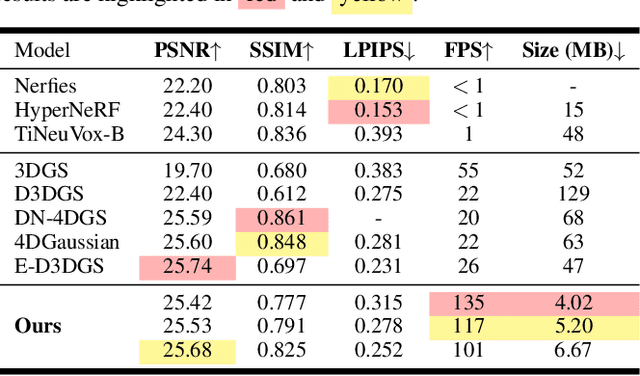
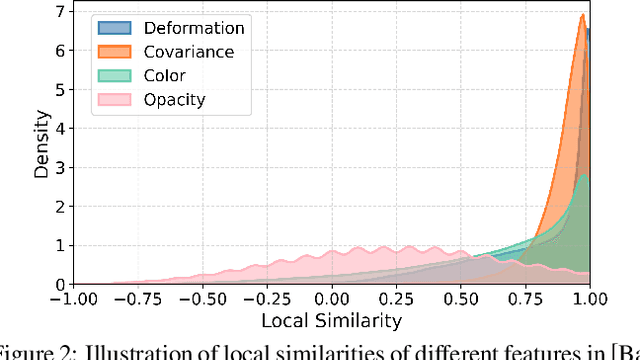

Existing 4D Gaussian Splatting methods rely on per-Gaussian deformation from a canonical space to target frames, which overlooks redundancy among adjacent Gaussian primitives and results in suboptimal performance. To address this limitation, we propose Anchor-Driven Deformable and Compressed Gaussian Splatting (ADC-GS), a compact and efficient representation for dynamic scene reconstruction. Specifically, ADC-GS organizes Gaussian primitives into an anchor-based structure within the canonical space, enhanced by a temporal significance-based anchor refinement strategy. To reduce deformation redundancy, ADC-GS introduces a hierarchical coarse-to-fine pipeline that captures motions at varying granularities. Moreover, a rate-distortion optimization is adopted to achieve an optimal balance between bitrate consumption and representation fidelity. Experimental results demonstrate that ADC-GS outperforms the per-Gaussian deformation approaches in rendering speed by 300%-800% while achieving state-of-the-art storage efficiency without compromising rendering quality. The code is released at https://github.com/H-Huang774/ADC-GS.git.
HybridGS: High-Efficiency Gaussian Splatting Data Compression using Dual-Channel Sparse Representation and Point Cloud Encoder
May 03, 2025



Most existing 3D Gaussian Splatting (3DGS) compression schemes focus on producing compact 3DGS representation via implicit data embedding. They have long coding times and highly customized data format, making it difficult for widespread deployment. This paper presents a new 3DGS compression framework called HybridGS, which takes advantage of both compact generation and standardized point cloud data encoding. HybridGS first generates compact and explicit 3DGS data. A dual-channel sparse representation is introduced to supervise the primitive position and feature bit depth. It then utilizes a canonical point cloud encoder to perform further data compression and form standard output bitstreams. A simple and effective rate control scheme is proposed to pivot the interpretable data compression scheme. At the current stage, HybridGS does not include any modules aimed at improving 3DGS quality during generation. But experiment results show that it still provides comparable reconstruction performance against state-of-the-art methods, with evidently higher encoding and decoding speed. The code is publicly available at https://github.com/Qi-Yangsjtu/HybridGS.