 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVerification of deep probabilistic models
Dec 06, 2018Probabilistic models are a critical part of the modern deep learning toolbox - ranging from generative models (VAEs, GANs), sequence to sequence models used in machine translation and speech processing to models over functional spaces (conditional neural processes, neural processes). Given the size and complexity of these models, safely deploying them in applications requires the development of tools to analyze their behavior rigorously and provide some guarantees that these models are consistent with a list of desirable properties or specifications. For example, a machine translation model should produce semantically equivalent outputs for innocuous changes in the input to the model. A functional regression model that is learning a distribution over monotonic functions should predict a larger value at a larger input. Verification of these properties requires a new framework that goes beyond notions of verification studied in deterministic feedforward networks, since requiring worst-case guarantees in probabilistic models is likely to produce conservative or vacuous results. We propose a novel formulation of verification for deep probabilistic models that take in conditioning inputs and sample latent variables in the course of producing an output: We require that the output of the model satisfies a linear constraint with high probability over the sampling of latent variables and for every choice of conditioning input to the model. We show that rigorous lower bounds on the probability that the constraint is satisfied can be obtained efficiently. Experiments with neural processes show that several properties of interest while modeling functional spaces can be modeled within this framework (monotonicity, convexity) and verified efficiently using our algorithms
Rigorous Agent Evaluation: An Adversarial Approach to Uncover Catastrophic Failures
Dec 04, 2018
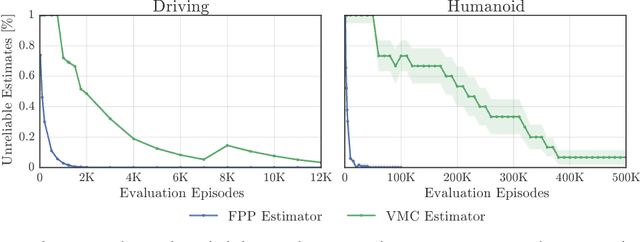
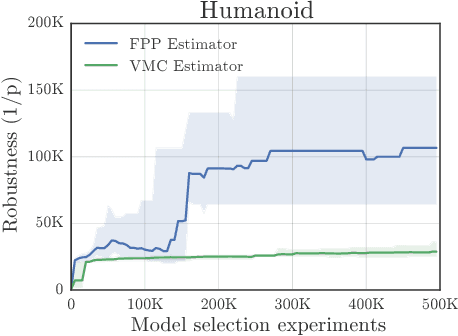

This paper addresses the problem of evaluating learning systems in safety critical domains such as autonomous driving, where failures can have catastrophic consequences. We focus on two problems: searching for scenarios when learned agents fail and assessing their probability of failure. The standard method for agent evaluation in reinforcement learning, Vanilla Monte Carlo, can miss failures entirely, leading to the deployment of unsafe agents. We demonstrate this is an issue for current agents, where even matching the compute used for training is sometimes insufficient for evaluation. To address this shortcoming, we draw upon the rare event probability estimation literature and propose an adversarial evaluation approach. Our approach focuses evaluation on adversarially chosen situations, while still providing unbiased estimates of failure probabilities. The key difficulty is in identifying these adversarial situations -- since failures are rare there is little signal to drive optimization. To solve this we propose a continuation approach that learns failure modes in related but less robust agents. Our approach also allows reuse of data already collected for training the agent. We demonstrate the efficacy of adversarial evaluation on two standard domains: humanoid control and simulated driving. Experimental results show that our methods can find catastrophic failures and estimate failures rates of agents multiple orders of magnitude faster than standard evaluation schemes, in minutes to hours rather than days.
Compositional Imitation Learning: Explaining and executing one task at a time
Dec 04, 2018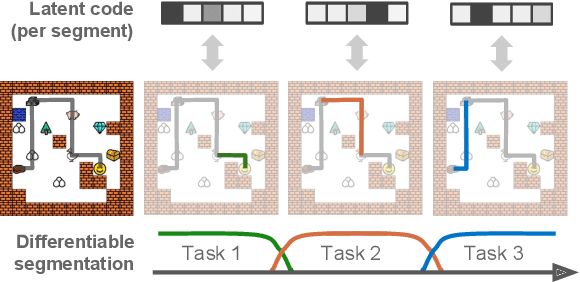
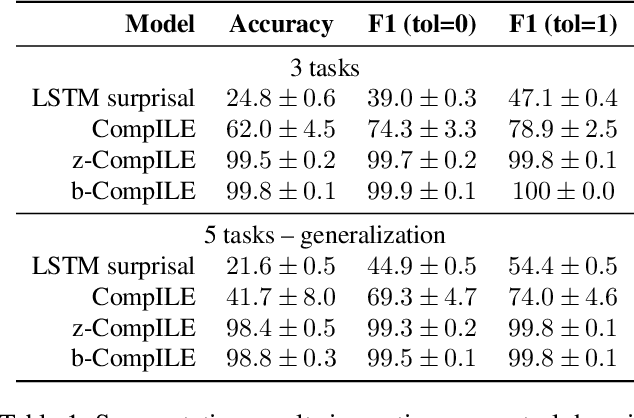
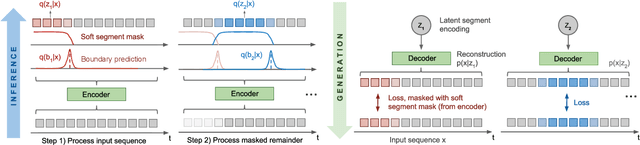
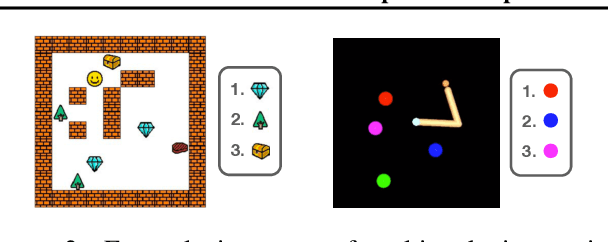
We introduce a framework for Compositional Imitation Learning and Execution (CompILE) of hierarchically-structured behavior. CompILE learns reusable, variable-length segments of behavior from demonstration data using a novel unsupervised, fully-differentiable sequence segmentation module. These learned behaviors can then be re-composed and executed to perform new tasks. At training time, CompILE auto-encodes observed behavior into a sequence of latent codes, each corresponding to a variable-length segment in the input sequence. Once trained, our model generalizes to sequences of longer length and from environment instances not seen during training. We evaluate our model in a challenging 2D multi-task environment and show that CompILE can find correct task boundaries and event encodings in an unsupervised manner without requiring annotated demonstration data. Latent codes and associated behavior policies discovered by CompILE can be used by a hierarchical agent, where the high-level policy selects actions in the latent code space, and the low-level, task-specific policies are simply the learned decoders. We found that our agent could learn given only sparse rewards, where agents without task-specific policies struggle.
Strength in Numbers: Trading-off Robustness and Computation via Adversarially-Trained Ensembles
Nov 22, 2018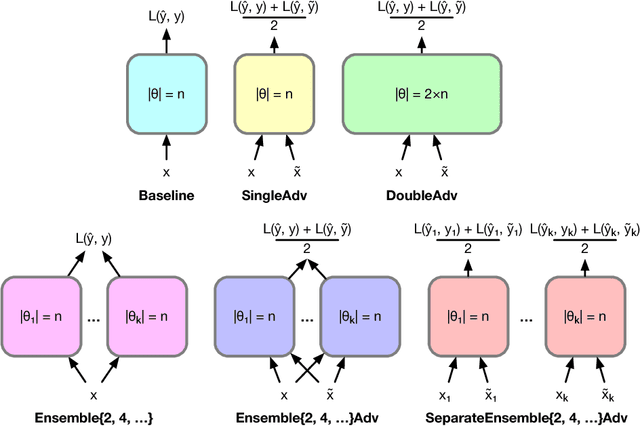
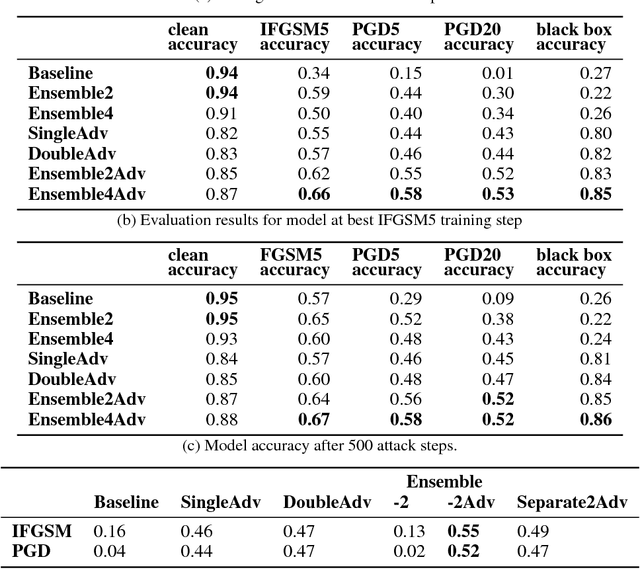
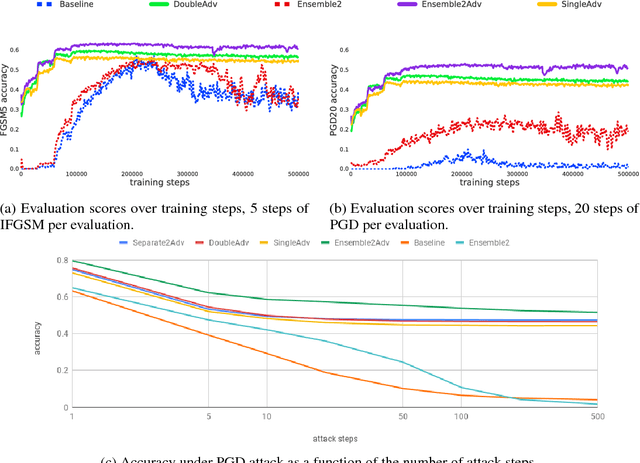
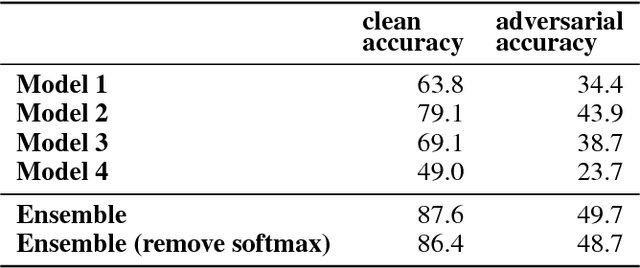
While deep learning has led to remarkable results on a number of challenging problems, researchers have discovered a vulnerability of neural networks in adversarial settings, where small but carefully chosen perturbations to the input can make the models produce extremely inaccurate outputs. This makes these models particularly unsuitable for safety-critical application domains (e.g. self-driving cars) where robustness is extremely important. Recent work has shown that augmenting training with adversarially generated data provides some degree of robustness against test-time attacks. In this paper we investigate how this approach scales as we increase the computational budget given to the defender. We show that increasing the number of parameters in adversarially-trained models increases their robustness, and in particular that ensembling smaller models while adversarially training the entire ensemble as a single model is a more efficient way of spending said budget than simply using a larger single model. Crucially, we show that it is the adversarial training of the ensemble, rather than the ensembling of adversarially trained models, which provides robustness.
On the Effectiveness of Interval Bound Propagation for Training Verifiably Robust Models
Nov 05, 2018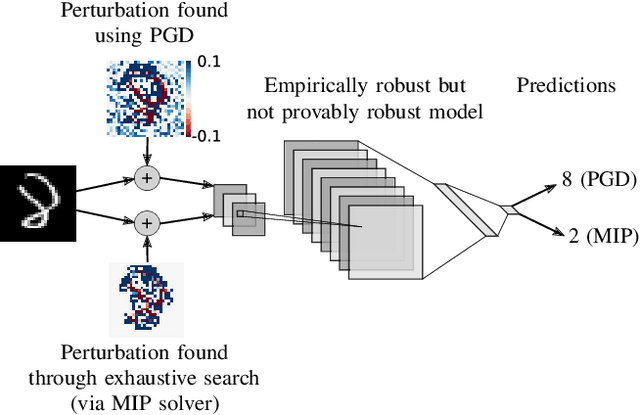

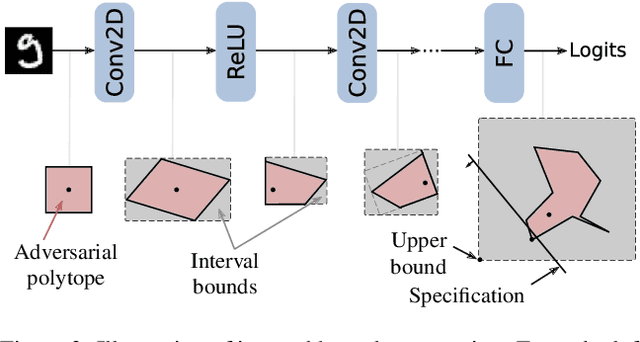

Recent works have shown that it is possible to train models that are verifiably robust to norm-bounded adversarial perturbations. While these recent methods show promise, they remain hard to scale and difficult to tune. This paper investigates how interval bound propagation (IBP) using simple interval arithmetic can be exploited to train verifiably robust neural networks that are surprisingly effective. While IBP itself has been studied in prior work, our contribution is in showing that, with an appropriate loss and careful tuning of hyper-parameters, verified training with IBP leads to a fast and stable learning algorithm. We compare our approach with recent techniques, and train classifiers that improve on the state-of-the-art in single-model adversarial robustness: we reduce the verified error rate from 3.67% to 2.23% on MNIST (with $\ell_\infty$ perturbations of $\epsilon = 0.1$), from 19.32% to 8.05% on MNIST (at $\epsilon = 0.3$), and from 78.22% to 72.91% on CIFAR-10 (at $\epsilon = 8/255$).
Efficient Relaxations for Dense CRFs with Sparse Higher Order Potentials
Oct 26, 2018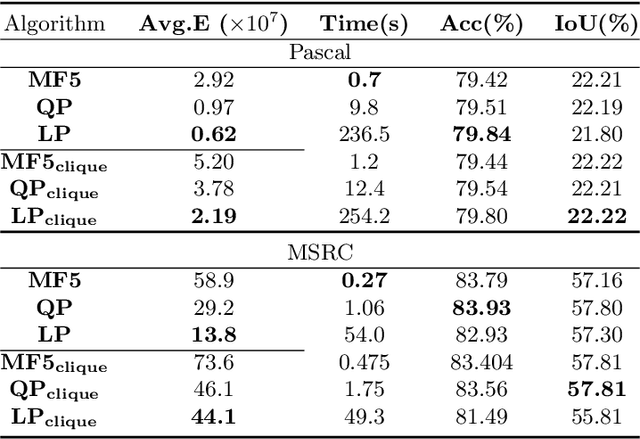
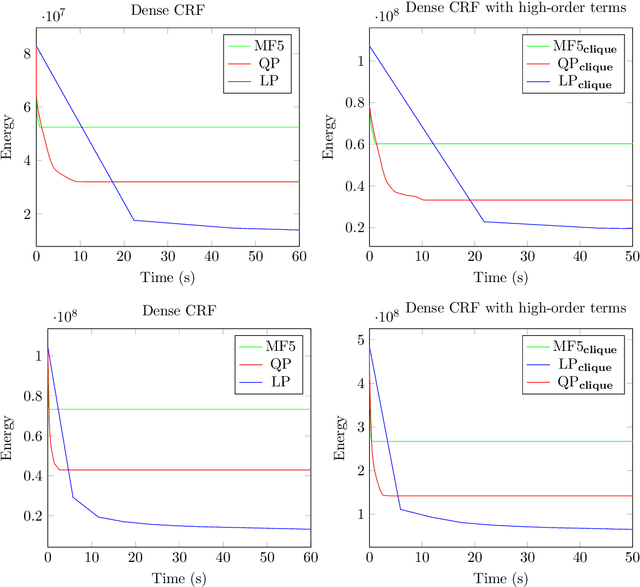
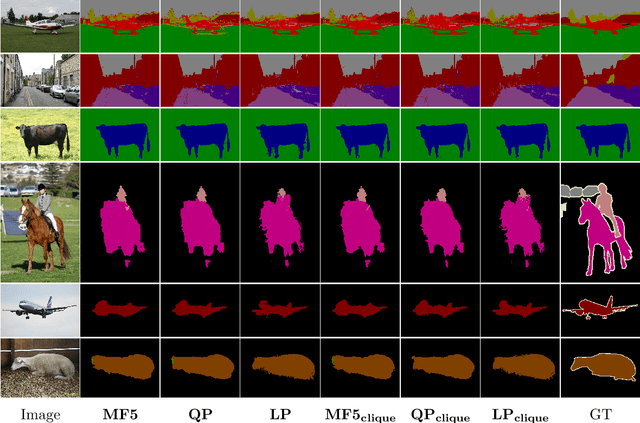
Dense conditional random fields (CRFs) have become a popular framework for modelling several problems in computer vision such as stereo correspondence and multi-class semantic segmentation. By modelling long-range interactions, dense CRFs provide a labelling that captures finer detail than their sparse counterparts. Currently, the state-of-the-art algorithm performs mean-field inference using a filter-based method but fails to provide a strong theoretical guarantee on the quality of the solution. A question naturally arises as to whether it is possible to obtain a maximum a posteriori (MAP) estimate of a dense CRF using a principled method. Within this paper, we show that this is indeed possible. We will show that, by using a filter-based method, continuous relaxations of the MAP problem can be optimised efficiently using state-of-the-art algorithms. Specifically, we will solve a quadratic programming (QP) relaxation using the Frank-Wolfe algorithm and a linear programming (LP) relaxation by developing a proximal minimisation framework. By exploiting labelling consistency in the higher-order potentials and utilising the filter-based method, we are able to formulate the above algorithms such that each iteration has a complexity linear in the number of classes and random variables. The presented algorithms can be applied to any labelling problem using a dense CRF with sparse higher-order potentials. In this paper, we use semantic segmentation as an example application as it demonstrates the ability of the algorithm to scale to dense CRFs with large dimensions. We perform experiments on the Pascal dataset to indicate that the presented algorithms are able to attain lower energies than the mean-field inference method.
Relational inductive biases, deep learning, and graph networks
Oct 17, 2018
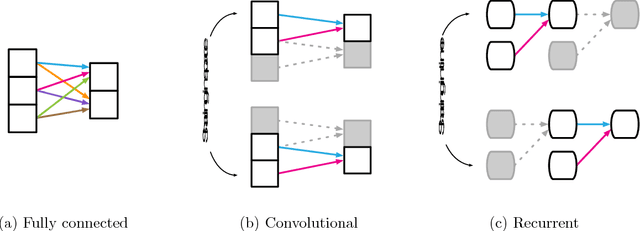
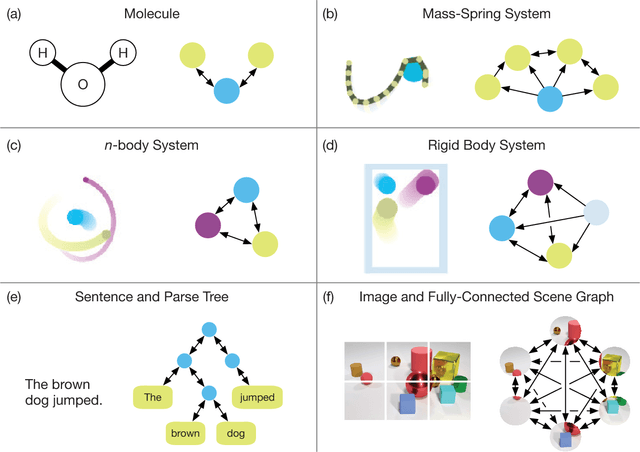
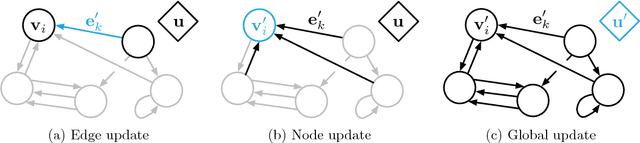
Artificial intelligence (AI) has undergone a renaissance recently, making major progress in key domains such as vision, language, control, and decision-making. This has been due, in part, to cheap data and cheap compute resources, which have fit the natural strengths of deep learning. However, many defining characteristics of human intelligence, which developed under much different pressures, remain out of reach for current approaches. In particular, generalizing beyond one's experiences--a hallmark of human intelligence from infancy--remains a formidable challenge for modern AI. The following is part position paper, part review, and part unification. We argue that combinatorial generalization must be a top priority for AI to achieve human-like abilities, and that structured representations and computations are key to realizing this objective. Just as biology uses nature and nurture cooperatively, we reject the false choice between "hand-engineering" and "end-to-end" learning, and instead advocate for an approach which benefits from their complementary strengths. We explore how using relational inductive biases within deep learning architectures can facilitate learning about entities, relations, and rules for composing them. We present a new building block for the AI toolkit with a strong relational inductive bias--the graph network--which generalizes and extends various approaches for neural networks that operate on graphs, and provides a straightforward interface for manipulating structured knowledge and producing structured behaviors. We discuss how graph networks can support relational reasoning and combinatorial generalization, laying the foundation for more sophisticated, interpretable, and flexible patterns of reasoning. As a companion to this paper, we have released an open-source software library for building graph networks, with demonstrations of how to use them in practice.
Learning to Understand Goal Specifications by Modelling Reward
Oct 02, 2018
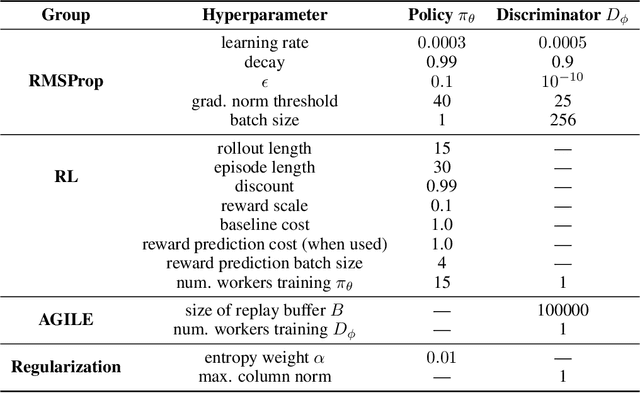
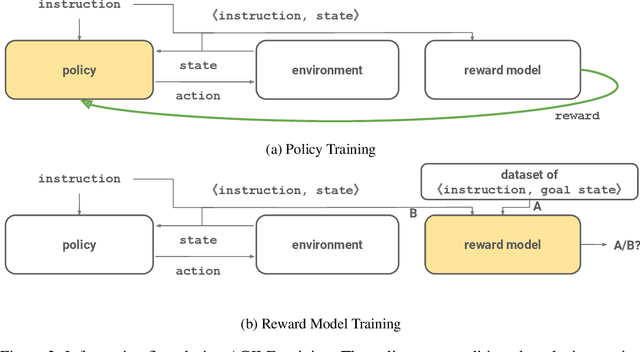
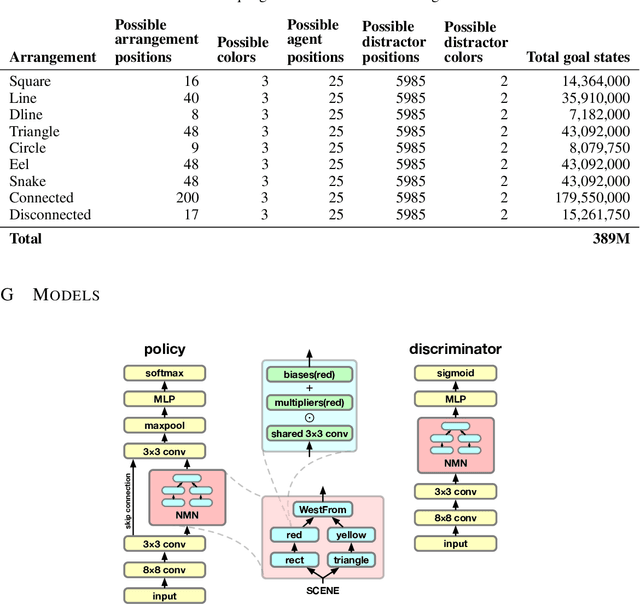
Recent work has shown that deep reinforcement-learning agents can learn to follow language-like instructions from infrequent environment rewards. However, this places on environment designers the onus of designing language-conditional reward functions which may not be easily or tractably implemented as the complexity of the environment and the language scales. To overcome this limitation, we present a framework within which instruction-conditional RL agents are trained using rewards obtained not from the environment, but from reward models which are jointly trained from expert examples. As reward models improve, they learn to accurately reward agents for completing tasks for environment configurations---and for instructions---not present amongst the expert data. This framework effectively separates the representation of what instructions require from how they can be executed. In a simple grid world, it enables an agent to learn a range of commands requiring interaction with blocks and understanding of spatial relations and underspecified abstract arrangements. We further show the method allows our agent to adapt to changes in the environment without requiring new expert examples.
A Dual Approach to Scalable Verification of Deep Networks
Aug 03, 2018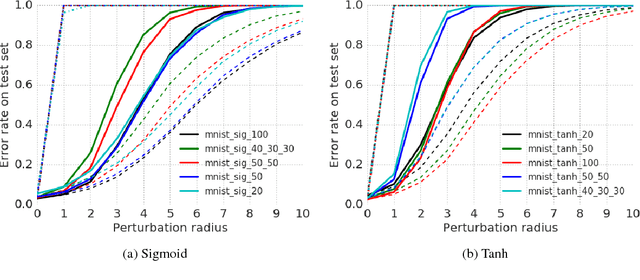
This paper addresses the problem of formally verifying desirable properties of neural networks, i.e., obtaining provable guarantees that neural networks satisfy specifications relating their inputs and outputs (robustness to bounded norm adversarial perturbations, for example). Most previous work on this topic was limited in its applicability by the size of the network, network architecture and the complexity of properties to be verified. In contrast, our framework applies to a general class of activation functions and specifications on neural network inputs and outputs. We formulate verification as an optimization problem (seeking to find the largest violation of the specification) and solve a Lagrangian relaxation of the optimization problem to obtain an upper bound on the worst case violation of the specification being verified. Our approach is anytime i.e. it can be stopped at any time and a valid bound on the maximum violation can be obtained. We develop specialized verification algorithms with provable tightness guarantees under special assumptions and demonstrate the practical significance of our general verification approach on a variety of verification tasks.
Adversarial Risk and the Dangers of Evaluating Against Weak Attacks
Jun 12, 2018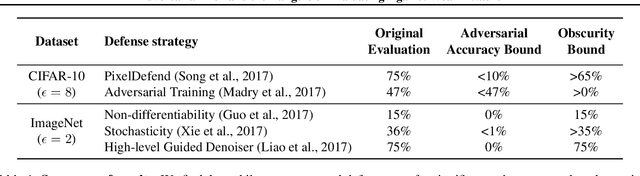
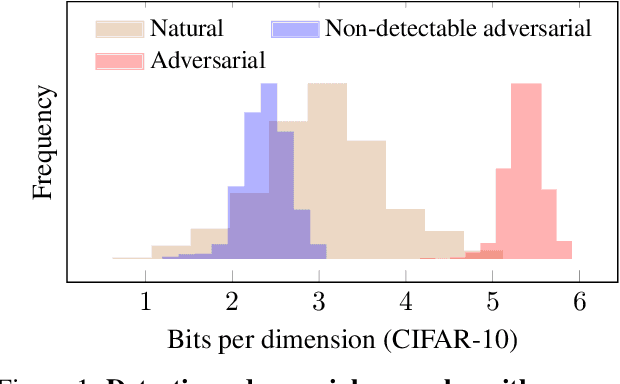
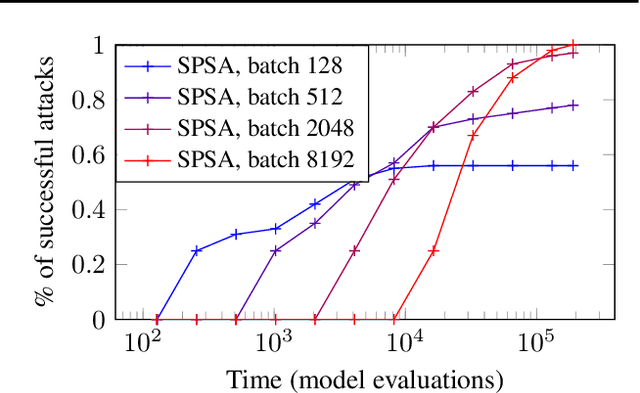
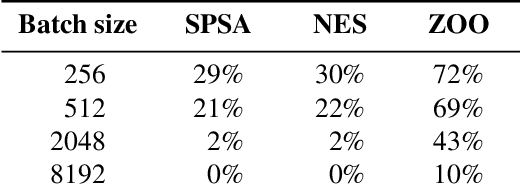
This paper investigates recently proposed approaches for defending against adversarial examples and evaluating adversarial robustness. We motivate 'adversarial risk' as an objective for achieving models robust to worst-case inputs. We then frame commonly used attacks and evaluation metrics as defining a tractable surrogate objective to the true adversarial risk. This suggests that models may optimize this surrogate rather than the true adversarial risk. We formalize this notion as 'obscurity to an adversary,' and develop tools and heuristics for identifying obscured models and designing transparent models. We demonstrate that this is a significant problem in practice by repurposing gradient-free optimization techniques into adversarial attacks, which we use to decrease the accuracy of several recently proposed defenses to near zero. Our hope is that our formulations and results will help researchers to develop more powerful defenses.