 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOLMo: Accelerating the Science of Language Models
Feb 07, 2024



Language models (LMs) have become ubiquitous in both NLP research and in commercial product offerings. As their commercial importance has surged, the most powerful models have become closed off, gated behind proprietary interfaces, with important details of their training data, architectures, and development undisclosed. Given the importance of these details in scientifically studying these models, including their biases and potential risks, we believe it is essential for the research community to have access to powerful, truly open LMs. To this end, this technical report details the first release of OLMo, a state-of-the-art, truly Open Language Model and its framework to build and study the science of language modeling. Unlike most prior efforts that have only released model weights and inference code, we release OLMo and the whole framework, including training data and training and evaluation code. We hope this release will empower and strengthen the open research community and inspire a new wave of innovation.
Camels in a Changing Climate: Enhancing LM Adaptation with Tulu 2
Nov 20, 2023Since the release of T\"ULU [Wang et al., 2023b], open resources for instruction tuning have developed quickly, from better base models to new finetuning techniques. We test and incorporate a number of these advances into T\"ULU, resulting in T\"ULU 2, a suite of improved T\"ULU models for advancing the understanding and best practices of adapting pretrained language models to downstream tasks and user preferences. Concretely, we release: (1) T\"ULU-V2-mix, an improved collection of high-quality instruction datasets; (2) T\"ULU 2, LLAMA-2 models finetuned on the V2 mixture; (3) T\"ULU 2+DPO, T\"ULU 2 models trained with direct preference optimization (DPO), including the largest DPO-trained model to date (T\"ULU 2+DPO 70B); (4) CODE T\"ULU 2, CODE LLAMA models finetuned on our V2 mix that outperform CODE LLAMA and its instruction-tuned variant, CODE LLAMA-Instruct. Our evaluation from multiple perspectives shows that the T\"ULU 2 suite achieves state-of-the-art performance among open models and matches or exceeds the performance of GPT-3.5-turbo-0301 on several benchmarks. We release all the checkpoints, data, training and evaluation code to facilitate future open efforts on adapting large language models.
Evaluating In-Context Learning of Libraries for Code Generation
Nov 16, 2023Contemporary Large Language Models (LLMs) exhibit a high degree of code generation and comprehension capability. A particularly promising area is their ability to interpret code modules from unfamiliar libraries for solving user-instructed tasks. Recent work has shown that large proprietary LLMs can learn novel library usage in-context from demonstrations. These results raise several open questions: whether demonstrations of library usage is required, whether smaller (and more open) models also possess such capabilities, etc. In this work, we take a broader approach by systematically evaluating a diverse array of LLMs across three scenarios reflecting varying levels of domain specialization to understand their abilities and limitations in generating code based on libraries defined in-context. Our results show that even smaller open-source LLMs like Llama-2 and StarCoder demonstrate an adept understanding of novel code libraries based on specification presented in-context. Our findings further reveal that LLMs exhibit a surprisingly high proficiency in learning novel library modules even when provided with just natural language descriptions or raw code implementations of the functions, which are often cheaper to obtain than demonstrations. Overall, our results pave the way for harnessing LLMs in more adaptable and dynamic coding environments.
TRAM: Bridging Trust Regions and Sharpness Aware Minimization
Oct 05, 2023



By reducing the curvature of the loss surface in the parameter space, Sharpness-aware minimization (SAM) yields widespread robustness improvement under domain transfer. Instead of focusing on parameters, however, this work considers the transferability of representations as the optimization target for out-of-domain generalization in a fine-tuning setup. To encourage the retention of transferable representations, we consider trust region-based fine-tuning methods, which exploit task-specific skills without forgetting task-agnostic representations from pre-training. We unify parameter- and representation-space smoothing approaches by using trust region bounds to inform SAM-style regularizers on both of these optimization surfaces. We propose Trust Region Aware Minimization (TRAM), a fine-tuning algorithm that optimizes for flat minima and smooth, informative representations without forgetting pre-trained structure. We find that TRAM outperforms both sharpness-aware and trust region-based optimization methods on cross-domain language modeling and cross-lingual transfer, where robustness to domain transfer and representation generality are critical for success. TRAM establishes a new standard in training generalizable models with minimal additional computation.
How Far Can Camels Go? Exploring the State of Instruction Tuning on Open Resources
Jun 07, 2023In this work we explore recent advances in instruction-tuning language models on a range of open instruction-following datasets. Despite recent claims that open models can be on par with state-of-the-art proprietary models, these claims are often accompanied by limited evaluation, making it difficult to compare models across the board and determine the utility of various resources. We provide a large set of instruction-tuned models from 6.7B to 65B parameters in size, trained on 12 instruction datasets ranging from manually curated (e.g., OpenAssistant) to synthetic and distilled (e.g., Alpaca) and systematically evaluate them on their factual knowledge, reasoning, multilinguality, coding, and open-ended instruction following abilities through a collection of automatic, model-based, and human-based metrics. We further introduce T\"ulu, our best performing instruction-tuned model suite finetuned on a combination of high-quality open resources. Our experiments show that different instruction-tuning datasets can uncover or enhance specific skills, while no single dataset (or combination) provides the best performance across all evaluations. Interestingly, we find that model and human preference-based evaluations fail to reflect differences in model capabilities exposed by benchmark-based evaluations, suggesting the need for the type of systemic evaluation performed in this work. Our evaluations show that the best model in any given evaluation reaches on average 83% of ChatGPT performance, and 68% of GPT-4 performance, suggesting that further investment in building better base models and instruction-tuning data is required to close the gap. We release our instruction-tuned models, including a fully finetuned 65B T\"ulu, along with our code, data, and evaluation framework at https://github.com/allenai/open-instruct to facilitate future research.
Inference-time Re-ranker Relevance Feedback for Neural Information Retrieval
May 19, 2023



Neural information retrieval often adopts a retrieve-and-rerank framework: a bi-encoder network first retrieves K (e.g., 100) candidates that are then re-ranked using a more powerful cross-encoder model to rank the better candidates higher. The re-ranker generally produces better candidate scores than the retriever, but is limited to seeing only the top K retrieved candidates, thus providing no improvements in retrieval performance as measured by Recall@K. In this work, we leverage the re-ranker to also improve retrieval by providing inference-time relevance feedback to the retriever. Concretely, we update the retriever's query representation for a test instance using a lightweight inference-time distillation of the re-ranker's prediction for that instance. The distillation loss is designed to bring the retriever's candidate scores closer to those of the re-ranker. A second retrieval step is then performed with the updated query vector. We empirically show that our approach, which can serve arbitrary retrieve-and-rerank pipelines, significantly improves retrieval recall in multiple domains, languages, and modalities.
LongEval: Guidelines for Human Evaluation of Faithfulness in Long-form Summarization
Jan 30, 2023



While human evaluation remains best practice for accurately judging the faithfulness of automatically-generated summaries, few solutions exist to address the increased difficulty and workload when evaluating long-form summaries. Through a survey of 162 papers on long-form summarization, we first shed light on current human evaluation practices surrounding long-form summaries. We find that 73% of these papers do not perform any human evaluation on model-generated summaries, while other works face new difficulties that manifest when dealing with long documents (e.g., low inter-annotator agreement). Motivated by our survey, we present LongEval, a set of guidelines for human evaluation of faithfulness in long-form summaries that addresses the following challenges: (1) How can we achieve high inter-annotator agreement on faithfulness scores? (2) How can we minimize annotator workload while maintaining accurate faithfulness scores? and (3) Do humans benefit from automated alignment between summary and source snippets? We deploy LongEval in annotation studies on two long-form summarization datasets in different domains (SQuALITY and PubMed), and we find that switching to a finer granularity of judgment (e.g., clause-level) reduces inter-annotator variance in faithfulness scores (e.g., std-dev from 18.5 to 6.8). We also show that scores from a partial annotation of fine-grained units highly correlates with scores from a full annotation workload (0.89 Kendall's tau using 50% judgments). We release our human judgments, annotation templates, and our software as a Python library for future research.
AGRO: Adversarial Discovery of Error-prone groups for Robust Optimization
Dec 08, 2022Models trained via empirical risk minimization (ERM) are known to rely on spurious correlations between labels and task-independent input features, resulting in poor generalization to distributional shifts. Group distributionally robust optimization (G-DRO) can alleviate this problem by minimizing the worst-case loss over a set of pre-defined groups over training data. G-DRO successfully improves performance of the worst-group, where the correlation does not hold. However, G-DRO assumes that the spurious correlations and associated worst groups are known in advance, making it challenging to apply it to new tasks with potentially multiple unknown spurious correlations. We propose AGRO -- Adversarial Group discovery for Distributionally Robust Optimization -- an end-to-end approach that jointly identifies error-prone groups and improves accuracy on them. AGRO equips G-DRO with an adversarial slicing model to find a group assignment for training examples which maximizes worst-case loss over the discovered groups. On the WILDS benchmark, AGRO results in 8% higher model performance on average on known worst-groups, compared to prior group discovery approaches used with G-DRO. AGRO also improves out-of-distribution performance on SST2, QQP, and MS-COCO -- datasets where potential spurious correlations are as yet uncharacterized. Human evaluation of ARGO groups shows that they contain well-defined, yet previously unstudied spurious correlations that lead to model errors.
Data-Efficient Finetuning Using Cross-Task Nearest Neighbors
Dec 01, 2022



Language models trained on massive prompted multitask datasets like T0 (Sanh et al., 2021) or FLAN (Wei et al., 2021a) can generalize to tasks unseen during training. We show that training on a carefully chosen subset of instances can outperform training on all available data on a variety of datasets. We assume access to a small number (250--1000) of unlabeled target task instances, select their nearest neighbors from a pool of multitask data, and use the retrieved data to train target task-specific models. Our method is more data-efficient than training a single multitask model, while still outperforming it by large margins. We evaluate across a diverse set of tasks not in the multitask pool we retrieve from, including those used to evaluate T0 and additional complex tasks including legal and scientific document QA. We retrieve small subsets of P3 (the collection of prompted datasets from which T0's training data was sampled) and finetune T5 models that outperform the 3-billion parameter variant of T0 (T0-3B) by 3--30% on 12 out of 14 evaluation datasets while using at most 2% of the data used to train T0-3B. These models also provide a better initialization than T0-3B for few-shot finetuning on target-task data, as shown by a 2--23% relative improvement over few-shot finetuned T0-3B models on 8 datasets. Our code is available at https://github.com/allenai/data-efficient-finetuning.
Generating Data to Mitigate Spurious Correlations in Natural Language Inference Datasets
Mar 24, 2022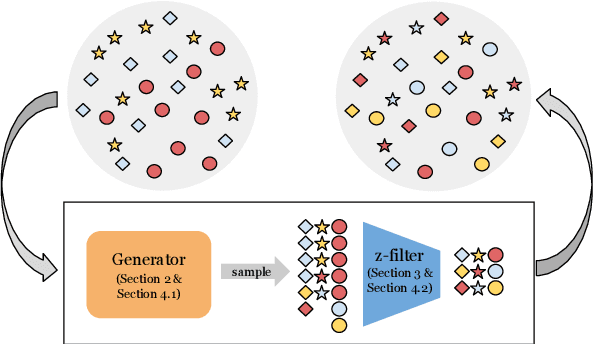
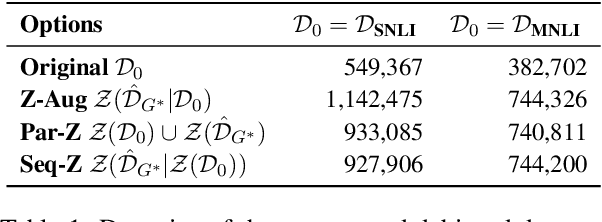
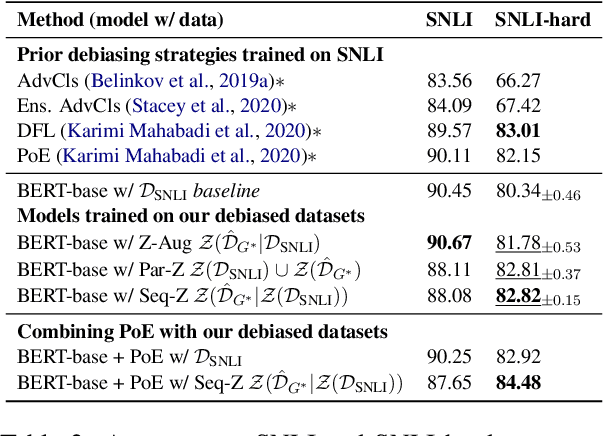
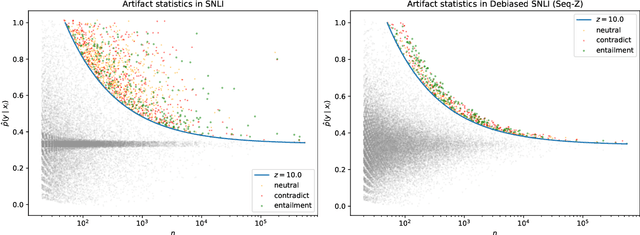
Natural language processing models often exploit spurious correlations between task-independent features and labels in datasets to perform well only within the distributions they are trained on, while not generalising to different task distributions. We propose to tackle this problem by generating a debiased version of a dataset, which can then be used to train a debiased, off-the-shelf model, by simply replacing its training data. Our approach consists of 1) a method for training data generators to generate high-quality, label-consistent data samples; and 2) a filtering mechanism for removing data points that contribute to spurious correlations, measured in terms of z-statistics. We generate debiased versions of the SNLI and MNLI datasets, and we evaluate on a large suite of debiased, out-of-distribution, and adversarial test sets. Results show that models trained on our debiased datasets generalise better than those trained on the original datasets in all settings. On the majority of the datasets, our method outperforms or performs comparably to previous state-of-the-art debiasing strategies, and when combined with an orthogonal technique, product-of-experts, it improves further and outperforms previous best results of SNLI-hard and MNLI-hard.