 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstablishing Task Scaling Laws via Compute-Efficient Model Ladders
Dec 05, 2024We develop task scaling laws and model ladders to predict the individual task performance of pretrained language models (LMs) in the overtrained setting. Standard power laws for language modeling loss cannot accurately model task performance. Therefore, we leverage a two-step prediction approach: first use model and data size to predict a task-specific loss, and then use this task loss to predict task performance. We train a set of small-scale "ladder" models, collect data points to fit the parameterized functions of the two prediction steps, and make predictions for two target models: a 7B model trained to 4T tokens and a 13B model trained to 5T tokens. Training the ladder models only costs 1% of the compute used for the target models. On four multiple-choice tasks written in ranked classification format, we can predict the accuracy of both target models within 2 points of absolute error. We have higher prediction error on four other tasks (average absolute error 6.9) and find that these are often tasks with higher variance in task metrics. We also find that using less compute to train fewer ladder models tends to deteriorate predictions. Finally, we empirically show that our design choices and the two-step approach lead to superior performance in establishing scaling laws.
Scalable Data Ablation Approximations for Language Models through Modular Training and Merging
Oct 21, 2024



Training data compositions for Large Language Models (LLMs) can significantly affect their downstream performance. However, a thorough data ablation study exploring large sets of candidate data mixtures is typically prohibitively expensive since the full effect is seen only after training the models; this can lead practitioners to settle for sub-optimal data mixtures. We propose an efficient method for approximating data ablations which trains individual models on subsets of a training corpus and reuses them across evaluations of combinations of subsets. In continued pre-training experiments, we find that, given an arbitrary evaluation set, the perplexity score of a single model trained on a candidate set of data is strongly correlated with perplexity scores of parameter averages of models trained on distinct partitions of that data. From this finding, we posit that researchers and practitioners can conduct inexpensive simulations of data ablations by maintaining a pool of models that were each trained on partitions of a large training corpus, and assessing candidate data mixtures by evaluating parameter averages of combinations of these models. This approach allows for substantial improvements in amortized training efficiency -- scaling only linearly with respect to new data -- by enabling reuse of previous training computation, opening new avenues for improving model performance through rigorous, incremental data assessment and mixing.
OLMo: Accelerating the Science of Language Models
Feb 07, 2024



Language models (LMs) have become ubiquitous in both NLP research and in commercial product offerings. As their commercial importance has surged, the most powerful models have become closed off, gated behind proprietary interfaces, with important details of their training data, architectures, and development undisclosed. Given the importance of these details in scientifically studying these models, including their biases and potential risks, we believe it is essential for the research community to have access to powerful, truly open LMs. To this end, this technical report details the first release of OLMo, a state-of-the-art, truly Open Language Model and its framework to build and study the science of language modeling. Unlike most prior efforts that have only released model weights and inference code, we release OLMo and the whole framework, including training data and training and evaluation code. We hope this release will empower and strengthen the open research community and inspire a new wave of innovation.
Dolma: an Open Corpus of Three Trillion Tokens for Language Model Pretraining Research
Jan 31, 2024



Language models have become a critical technology to tackling a wide range of natural language processing tasks, yet many details about how the best-performing language models were developed are not reported. In particular, information about their pretraining corpora is seldom discussed: commercial language models rarely provide any information about their data; even open models rarely release datasets they are trained on, or an exact recipe to reproduce them. As a result, it is challenging to conduct certain threads of language modeling research, such as understanding how training data impacts model capabilities and shapes their limitations. To facilitate open research on language model pretraining, we release Dolma, a three trillion tokens English corpus, built from a diverse mixture of web content, scientific papers, code, public-domain books, social media, and encyclopedic materials. In addition, we open source our data curation toolkit to enable further experimentation and reproduction of our work. In this report, we document Dolma, including its design principles, details about its construction, and a summary of its contents. We interleave this report with analyses and experimental results from training language models on intermediate states of Dolma to share what we have learned about important data curation practices, including the role of content or quality filters, deduplication, and multi-source mixing. Dolma has been used to train OLMo, a state-of-the-art, open language model and framework designed to build and study the science of language modeling.
Paloma: A Benchmark for Evaluating Language Model Fit
Dec 16, 2023Language models (LMs) commonly report perplexity on monolithic data held out from training. Implicitly or explicitly, this data is composed of domains$\unicode{x2013}$varying distributions of language. Rather than assuming perplexity on one distribution extrapolates to others, Perplexity Analysis for Language Model Assessment (Paloma), measures LM fit to 585 text domains, ranging from nytimes.com to r/depression on Reddit. We invite submissions to our benchmark and organize results by comparability based on compliance with guidelines such as removal of benchmark contamination from pretraining. Submissions can also record parameter and training token count to make comparisons of Pareto efficiency for performance as a function of these measures of cost. We populate our benchmark with results from 6 baselines pretrained on popular corpora. In case studies, we demonstrate analyses that are possible with Paloma, such as finding that pretraining without data beyond Common Crawl leads to inconsistent fit to many domains.
Large Language Model Distillation Doesn't Need a Teacher
May 24, 2023



Knowledge distillation trains a smaller student model to match the output distribution of a larger teacher to maximize the end-task performance under computational constraints. However, existing literature on language model distillation primarily focuses on compressing encoder-only models that are then specialized by task-specific supervised finetuning. We need to rethink this setup for more recent large language models with tens to hundreds of billions of parameters. Task-specific finetuning is impractical at this scale, and model performance is often measured using zero/few-shot prompting. Thus, in this work, we advocate for task-agnostic zero-shot evaluated distillation for large language models without access to end-task finetuning data. We propose a teacher-free task-agnostic distillation method, which uses a truncated version of the larger model for initialization, and continues pretraining this model using a language modeling objective. Our teacher-free method shines in a distillation regime where it is infeasible to fit both the student and teacher into the GPU memory. Despite its simplicity, our method can effectively reduce the model size by 50\%, matching or outperforming the vanilla distillation method on perplexity and accuracy on 13 zero-shot end-tasks while being 1.5x computationally efficient.
AAVAE: Augmentation-Augmented Variational Autoencoders
Jul 26, 2021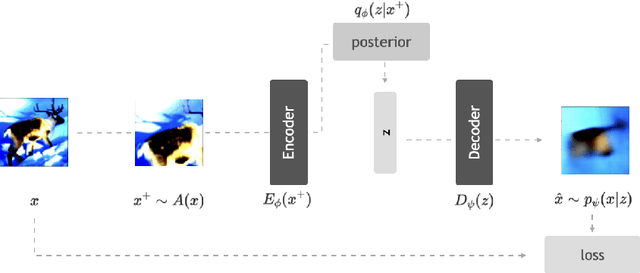
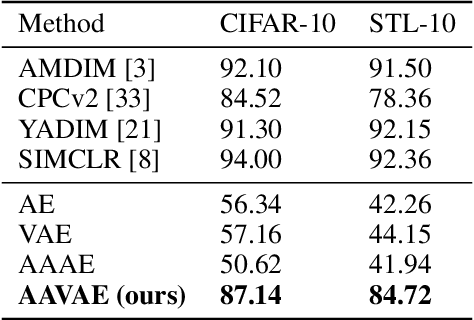
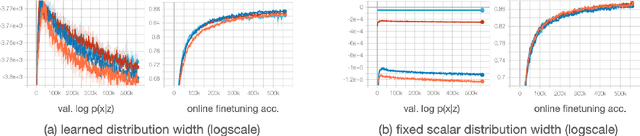
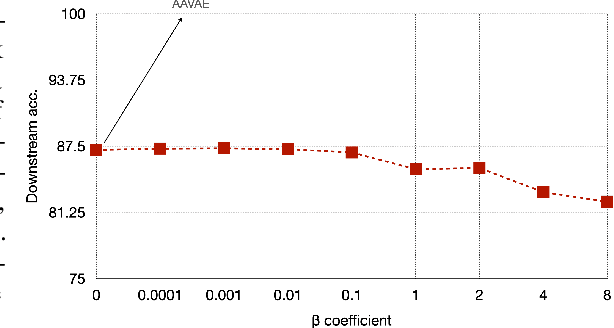
Recent methods for self-supervised learning can be grouped into two paradigms: contrastive and non-contrastive approaches. Their success can largely be attributed to data augmentation pipelines which generate multiple views of a single input that preserve the underlying semantics. In this work, we introduce augmentation-augmented variational autoencoders (AAVAE), a third approach to self-supervised learning based on autoencoding. We derive AAVAE starting from the conventional variational autoencoder (VAE), by replacing the KL divergence regularization, which is agnostic to the input domain, with data augmentations that explicitly encourage the internal representations to encode domain-specific invariances and equivariances. We empirically evaluate the proposed AAVAE on image classification, similar to how recent contrastive and non-contrastive learning algorithms have been evaluated. Our experiments confirm the effectiveness of data augmentation as a replacement for KL divergence regularization. The AAVAE outperforms the VAE by 30% on CIFAR-10 and 40% on STL-10. The results for AAVAE are largely comparable to the state-of-the-art for self-supervised learning.
Disentangling Factors of Variation with Cycle-Consistent Variational Auto-Encoders
Apr 27, 2018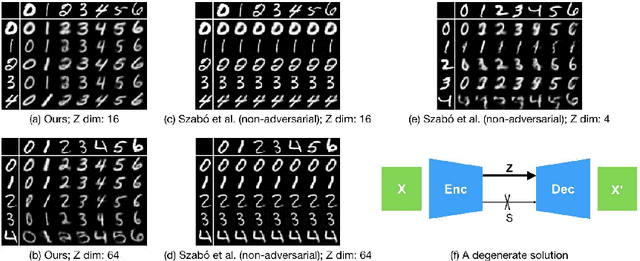
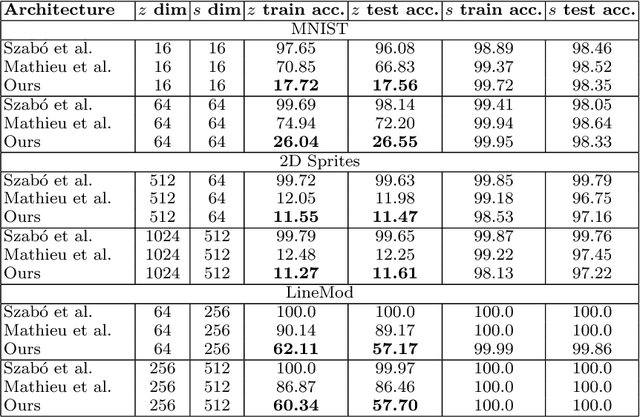
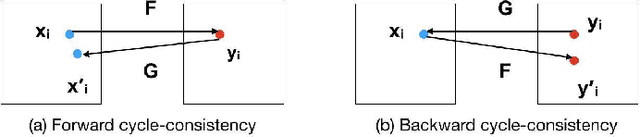
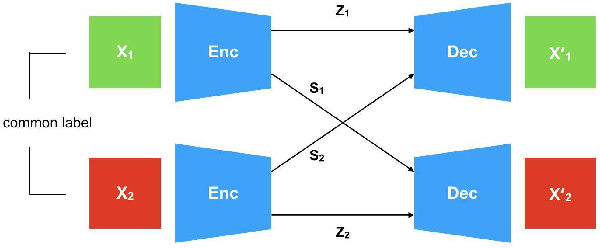
Generative models that learn disentangled representations for different factors of variation in an image can be very useful for targeted data augmentation. By sampling from the disentangled latent subspace of interest, we can efficiently generate new data necessary for a particular task. Learning disentangled representations is a challenging problem, especially when certain factors of variation are difficult to label. In this paper, we introduce a novel architecture that disentangles the latent space into two complementary subspaces by using only weak supervision in form of pairwise similarity labels. Inspired by the recent success of cycle-consistent adversarial architectures, we use cycle-consistency in a variational auto-encoder framework. Our non-adversarial approach is in contrast with the recent works that combine adversarial training with auto-encoders to disentangle representations. We show compelling results of disentangled latent subspaces on three datasets and compare with recent works that leverage adversarial training.