 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Evaluation of Zeroth-Order Optimization Methods on AI-driven Molecule Optimization
Oct 27, 2022Molecule optimization is an important problem in chemical discovery and has been approached using many techniques, including generative modeling, reinforcement learning, genetic algorithms, and much more. Recent work has also applied zeroth-order (ZO) optimization, a subset of gradient-free optimization that solves problems similarly to gradient-based methods, for optimizing latent vector representations from an autoencoder. In this paper, we study the effectiveness of various ZO optimization methods for optimizing molecular objectives, which are characterized by variable smoothness, infrequent optima, and other challenges. We provide insights on the robustness of various ZO optimizers in this setting, show the advantages of ZO sign-based gradient descent (ZO-signGD), discuss how ZO optimization can be used practically in realistic discovery tasks, and demonstrate the potential effectiveness of ZO optimization methods on widely used benchmark tasks from the Guacamol suite. Code is available at: https://github.com/IBM/QMO-bench.
FLIP: A Provable Defense Framework for Backdoor Mitigation in Federated Learning
Oct 23, 2022



Federated Learning (FL) is a distributed learning paradigm that enables different parties to train a model together for high quality and strong privacy protection. In this scenario, individual participants may get compromised and perform backdoor attacks by poisoning the data (or gradients). Existing work on robust aggregation and certified FL robustness does not study how hardening benign clients can affect the global model (and the malicious clients). In this work, we theoretically analyze the connection among cross-entropy loss, attack success rate, and clean accuracy in this setting. Moreover, we propose a trigger reverse engineering based defense and show that our method can achieve robustness improvement with guarantee (i.e., reducing the attack success rate) without affecting benign accuracy. We conduct comprehensive experiments across different datasets and attack settings. Our results on eight competing SOTA defense methods show the empirical superiority of our method on both single-shot and continuous FL backdoor attacks.
Visual Prompting for Adversarial Robustness
Oct 12, 2022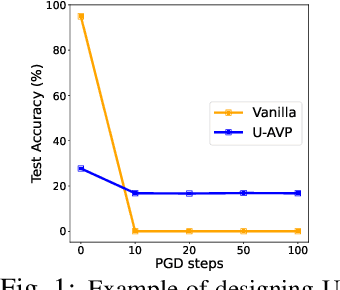
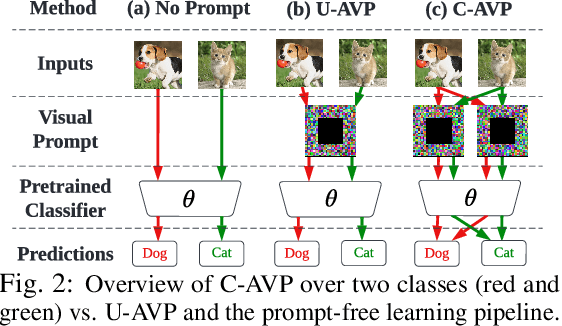


In this work, we leverage visual prompting (VP) to improve adversarial robustness of a fixed, pre-trained model at testing time. Compared to conventional adversarial defenses, VP allows us to design universal (i.e., data-agnostic) input prompting templates, which have plug-and-play capabilities at testing time to achieve desired model performance without introducing much computation overhead. Although VP has been successfully applied to improving model generalization, it remains elusive whether and how it can be used to defend against adversarial attacks. We investigate this problem and show that the vanilla VP approach is not effective in adversarial defense since a universal input prompt lacks the capacity for robust learning against sample-specific adversarial perturbations. To circumvent it, we propose a new VP method, termed Class-wise Adversarial Visual Prompting (C-AVP), to generate class-wise visual prompts so as to not only leverage the strengths of ensemble prompts but also optimize their interrelations to improve model robustness. Our experiments show that C-AVP outperforms the conventional VP method, with 2.1X standard accuracy gain and 2X robust accuracy gain. Compared to classical test-time defenses, C-AVP also yields a 42X inference time speedup.
SynBench: Task-Agnostic Benchmarking of Pretrained Representations using Synthetic Data
Oct 07, 2022
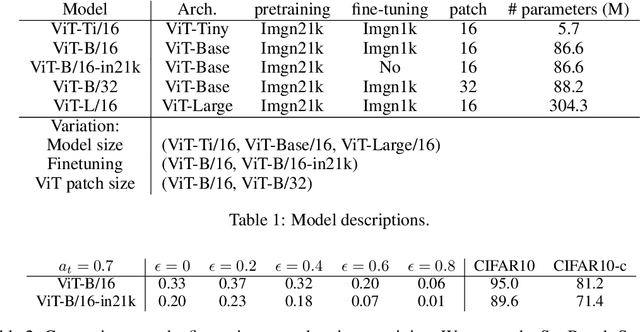
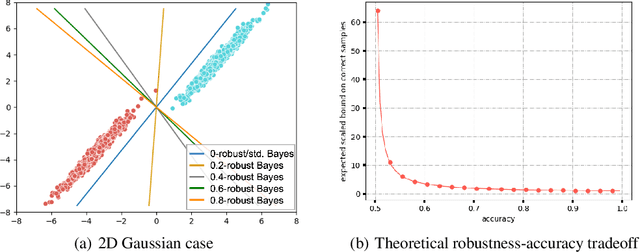
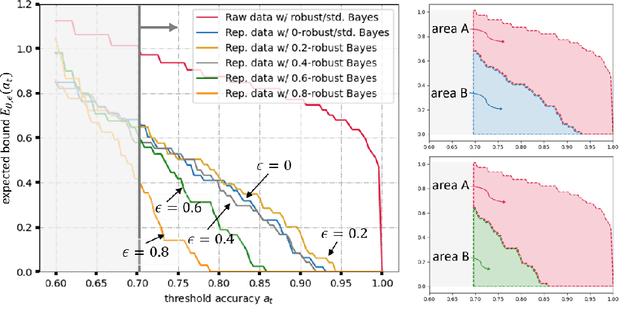
Recent success in fine-tuning large models, that are pretrained on broad data at scale, on downstream tasks has led to a significant paradigm shift in deep learning, from task-centric model design to task-agnostic representation learning and task-specific fine-tuning. As the representations of pretrained models are used as a foundation for different downstream tasks, this paper proposes a new task-agnostic framework, \textit{SynBench}, to measure the quality of pretrained representations using synthetic data. We set up a reference by a theoretically-derived robustness-accuracy tradeoff of the class conditional Gaussian mixture. Given a pretrained model, the representations of data synthesized from the Gaussian mixture are used to compare with our reference to infer the quality. By comparing the ratio of area-under-curve between the raw data and their representations, SynBench offers a quantifiable score for robustness-accuracy performance benchmarking. Our framework applies to a wide range of pretrained models taking continuous data inputs and is independent of the downstream tasks and datasets. Evaluated with several pretrained vision transformer models, the experimental results show that our SynBench score well matches the actual linear probing performance of the pre-trained model when fine-tuned on downstream tasks. Moreover, our framework can be used to inform the design of robust linear probing on pretrained representations to mitigate the robustness-accuracy tradeoff in downstream tasks.
Rethinking Normalization Methods in Federated Learning
Oct 07, 2022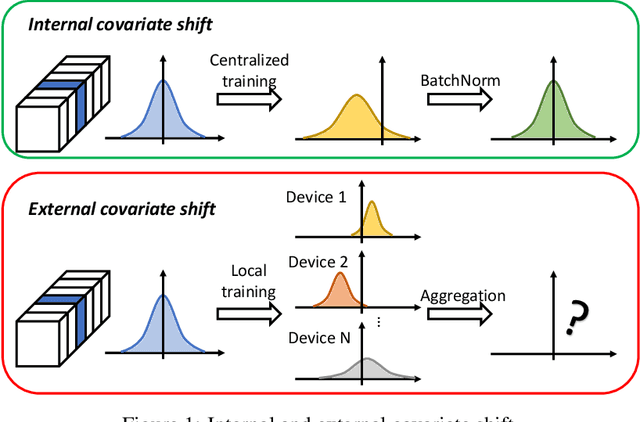

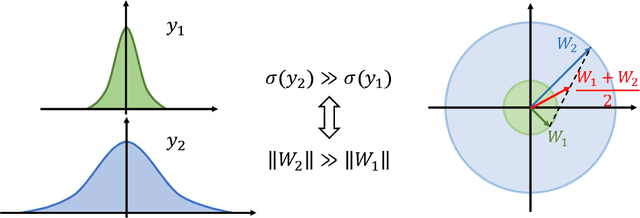
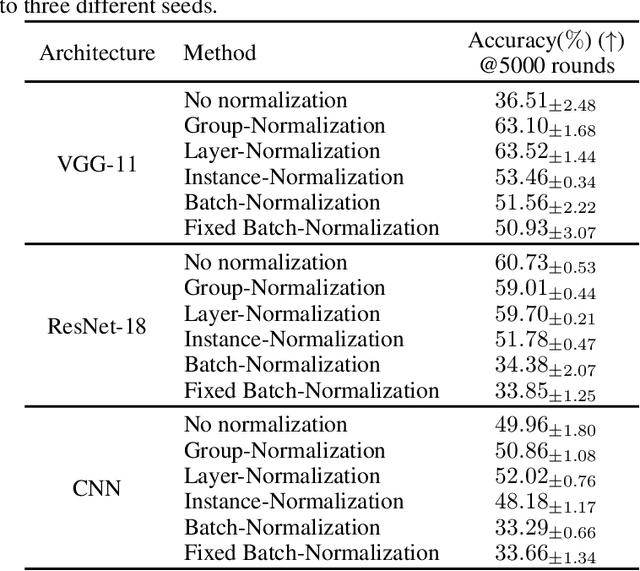
Federated learning (FL) is a popular distributed learning framework that can reduce privacy risks by not explicitly sharing private data. In this work, we explicitly uncover external covariate shift problem in FL, which is caused by the independent local training processes on different devices. We demonstrate that external covariate shifts will lead to the obliteration of some devices' contributions to the global model. Further, we show that normalization layers are indispensable in FL since their inherited properties can alleviate the problem of obliterating some devices' contributions. However, recent works have shown that batch normalization, which is one of the standard components in many deep neural networks, will incur accuracy drop of the global model in FL. The essential reason for the failure of batch normalization in FL is poorly studied. We unveil that external covariate shift is the key reason why batch normalization is ineffective in FL. We also show that layer normalization is a better choice in FL which can mitigate the external covariate shift and improve the performance of the global model. We conduct experiments on CIFAR10 under non-IID settings. The results demonstrate that models with layer normalization converge fastest and achieve the best or comparable accuracy for three different model architectures.
Neural Clamping: Joint Input Perturbation and Temperature Scaling for Neural Network Calibration
Sep 23, 2022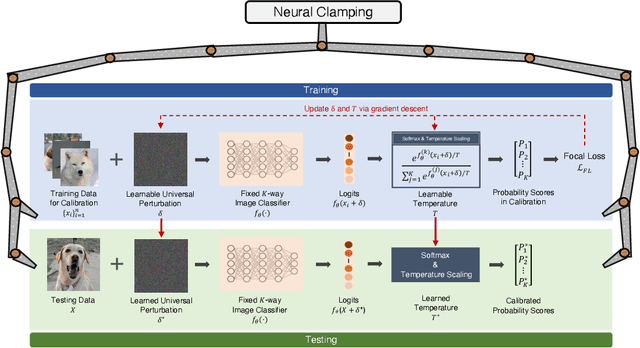
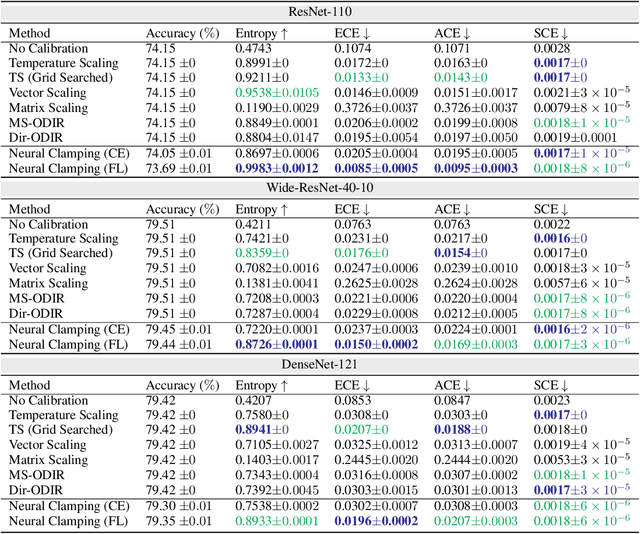
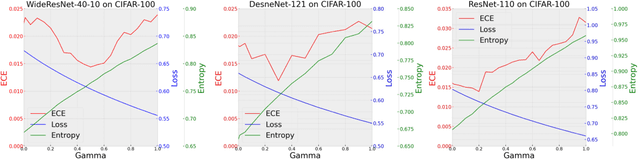
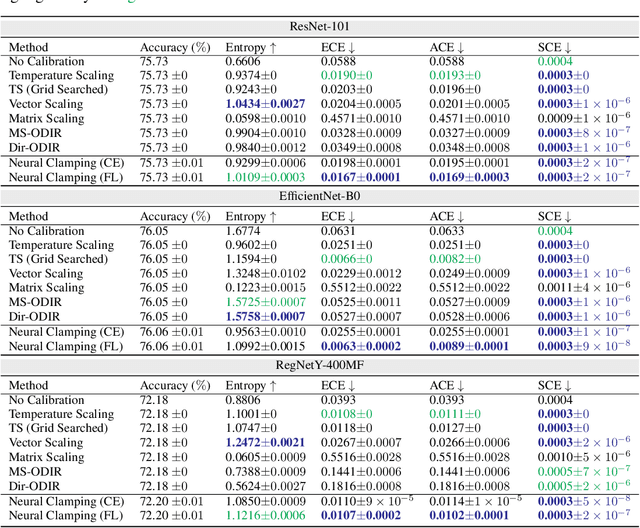
Neural network calibration is an essential task in deep learning to ensure consistency between the confidence of model prediction and the true correctness likelihood. In this paper, we propose a new post-processing calibration method called Neural Clamping, which employs a simple joint input-output transformation on a pre-trained classifier via a learnable universal input perturbation and an output temperature scaling parameter. Moreover, we provide theoretical explanations on why Neural Clamping is provably better than temperature scaling. Evaluated on CIFAR-100 and ImageNet image recognition datasets and a variety of deep neural network models, our empirical results show that Neural Clamping significantly outperforms state-of-the-art post-processing calibration methods.
Uncovering the Connection Between Differential Privacy and Certified Robustness of Federated Learning against Poisoning Attacks
Sep 08, 2022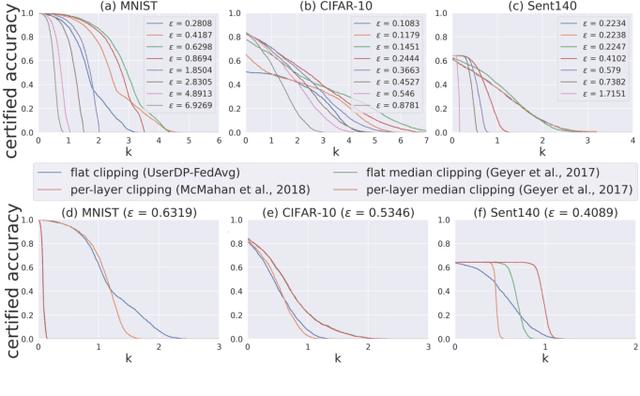
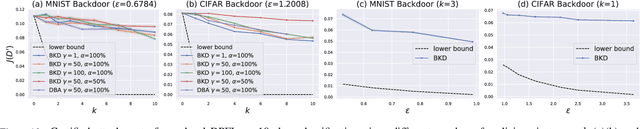
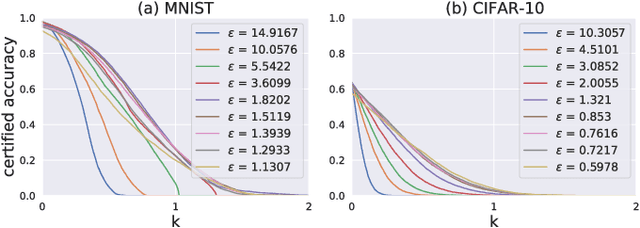
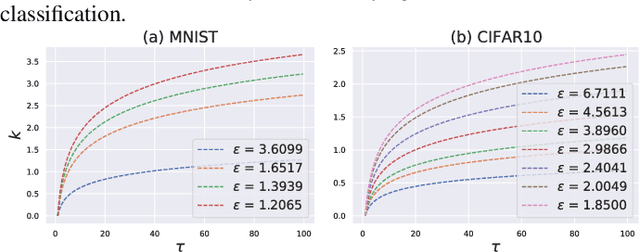
Federated learning (FL) provides an efficient paradigm to jointly train a global model leveraging data from distributed users. As the local training data come from different users who may not be trustworthy, several studies have shown that FL is vulnerable to poisoning attacks. Meanwhile, to protect the privacy of local users, FL is always trained in a differentially private way (DPFL). Thus, in this paper, we ask: Can we leverage the innate privacy property of DPFL to provide certified robustness against poisoning attacks? Can we further improve the privacy of FL to improve such certification? We first investigate both user-level and instance-level privacy of FL and propose novel mechanisms to achieve improved instance-level privacy. We then provide two robustness certification criteria: certified prediction and certified attack cost for DPFL on both levels. Theoretically, we prove the certified robustness of DPFL under a bounded number of adversarial users or instances. Empirically, we conduct extensive experiments to verify our theories under a range of attacks on different datasets. We show that DPFL with a tighter privacy guarantee always provides stronger robustness certification in terms of certified attack cost, but the optimal certified prediction is achieved under a proper balance between privacy protection and utility loss.
Active Sampling of Multiple Sources for Sequential Estimation
Aug 10, 2022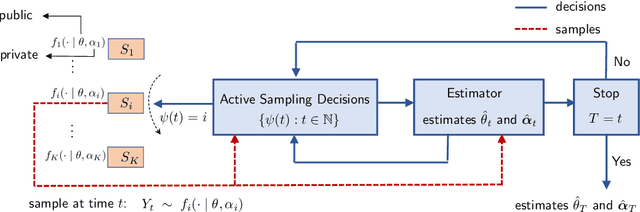
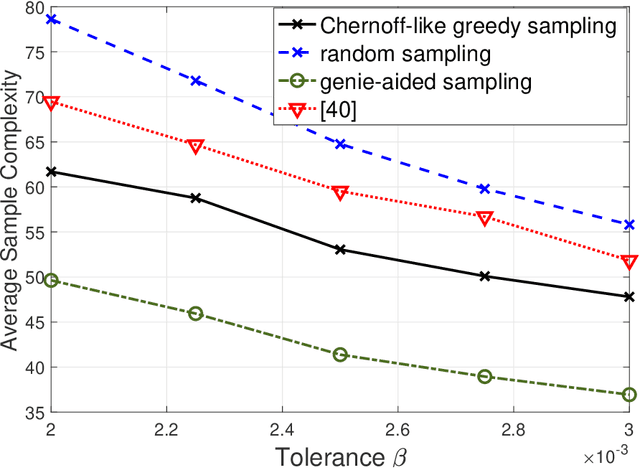
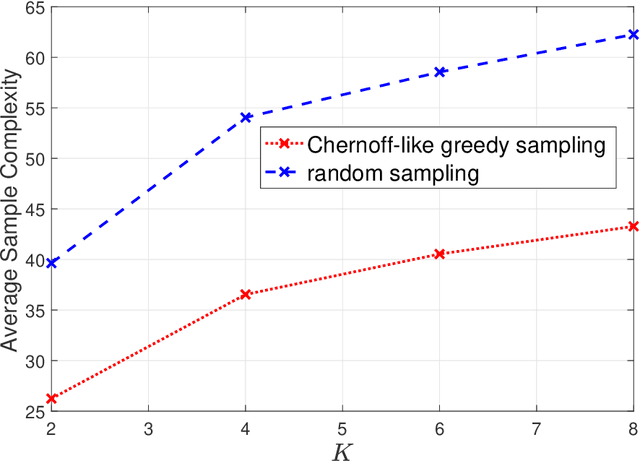
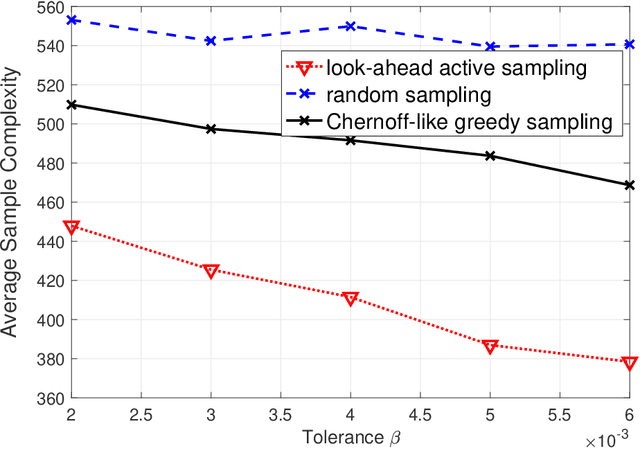
Consider $K$ processes, each generating a sequence of identical and independent random variables. The probability measures of these processes have random parameters that must be estimated. Specifically, they share a parameter $\theta$ common to all probability measures. Additionally, each process $i\in\{1, \dots, K\}$ has a private parameter $\alpha_i$. The objective is to design an active sampling algorithm for sequentially estimating these parameters in order to form reliable estimates for all shared and private parameters with the fewest number of samples. This sampling algorithm has three key components: (i)~data-driven sampling decisions, which dynamically over time specifies which of the $K$ processes should be selected for sampling; (ii)~stopping time for the process, which specifies when the accumulated data is sufficient to form reliable estimates and terminate the sampling process; and (iii)~estimators for all shared and private parameters. Owing to the sequential estimation being known to be analytically intractable, this paper adopts \emph {conditional} estimation cost functions, leading to a sequential estimation approach that was recently shown to render tractable analysis. Asymptotically optimal decision rules (sampling, stopping, and estimation) are delineated, and numerical experiments are provided to compare the efficacy and quality of the proposed procedure with those of the relevant approaches.
Improving Privacy-Preserving Vertical Federated Learning by Efficient Communication with ADMM
Jul 22, 2022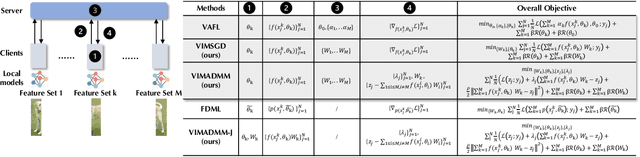
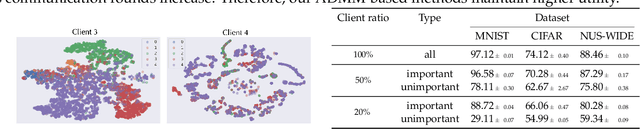
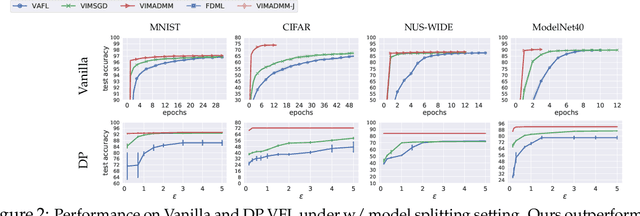

Federated learning (FL) enables distributed devices to jointly train a shared model while keeping the training data local. Different from the horizontal FL (HFL) setting where each client has partial data samples, vertical FL (VFL), which allows each client to collect partial features, has attracted intensive research efforts recently. In this paper, we identified two challenges that state-of-the-art VFL frameworks are facing: (1) some works directly average the learned feature embeddings and therefore might lose the unique properties of each local feature set; (2) server needs to communicate gradients with the clients for each training step, incurring high communication cost that leads to rapid consumption of privacy budgets. In this paper, we aim to address the above challenges and propose an efficient VFL with multiple linear heads (VIM) framework, where each head corresponds to local clients by taking the separate contribution of each client into account. In addition, we propose an Alternating Direction Method of Multipliers (ADMM)-based method to solve our optimization problem, which reduces the communication cost by allowing multiple local updates in each step, and thus leads to better performance under differential privacy. We consider various settings including VFL with model splitting and without model splitting. For both settings, we carefully analyze the differential privacy mechanism for our framework. Moreover, we show that a byproduct of our framework is that the weights of learned linear heads reflect the importance of local clients. We conduct extensive evaluations and show that on four real-world datasets, VIM achieves significantly higher performance and faster convergence compared with state-of-the-arts. We also explicitly evaluate the importance of local clients and show that VIM enables functionalities such as client-level explanation and client denoising.
Benchmarking Machine Learning Robustness in Covid-19 Genome Sequence Classification
Jul 18, 2022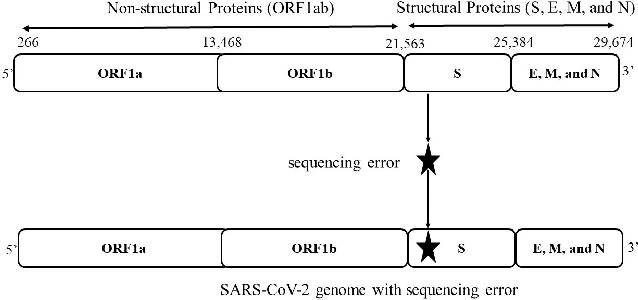
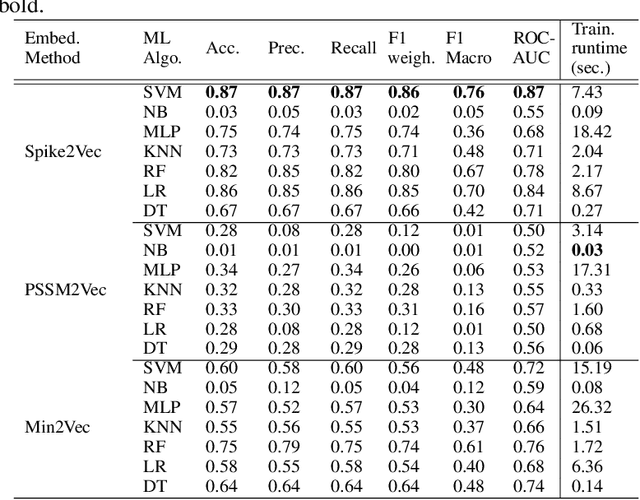
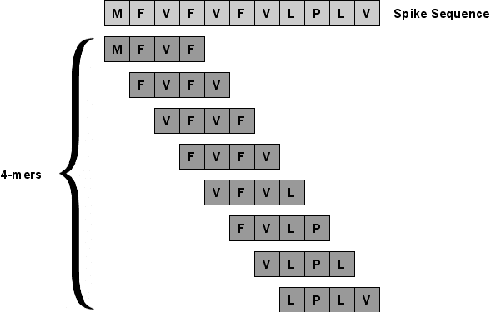
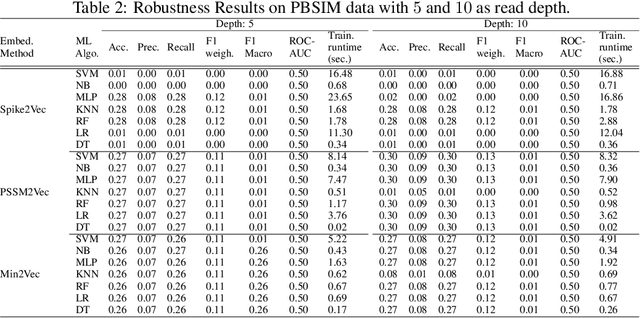
The rapid spread of the COVID-19 pandemic has resulted in an unprecedented amount of sequence data of the SARS-CoV-2 genome -- millions of sequences and counting. This amount of data, while being orders of magnitude beyond the capacity of traditional approaches to understanding the diversity, dynamics, and evolution of viruses is nonetheless a rich resource for machine learning (ML) approaches as alternatives for extracting such important information from these data. It is of hence utmost importance to design a framework for testing and benchmarking the robustness of these ML models. This paper makes the first effort (to our knowledge) to benchmark the robustness of ML models by simulating biological sequences with errors. In this paper, we introduce several ways to perturb SARS-CoV-2 genome sequences to mimic the error profiles of common sequencing platforms such as Illumina and PacBio. We show from experiments on a wide array of ML models that some simulation-based approaches are more robust (and accurate) than others for specific embedding methods to certain adversarial attacks to the input sequences. Our benchmarking framework may assist researchers in properly assessing different ML models and help them understand the behavior of the SARS-CoV-2 virus or avoid possible future pandemics.