 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Social Media Cross-Modality Discourse in Linguistic Space
Feb 26, 2023The multimedia communications with texts and images are popular on social media. However, limited studies concern how images are structured with texts to form coherent meanings in human cognition. To fill in the gap, we present a novel concept of cross-modality discourse, reflecting how human readers couple image and text understandings. Text descriptions are first derived from images (named as subtitles) in the multimedia contexts. Five labels -- entity-level insertion, projection and concretization and scene-level restatement and extension -- are further employed to shape the structure of subtitles and texts and present their joint meanings. As a pilot study, we also build the very first dataset containing 16K multimedia tweets with manually annotated discourse labels. The experimental results show that the multimedia encoder based on multi-head attention with captions is able to obtain the-state-of-the-art results.
Feature-Level Debiased Natural Language Understanding
Dec 18, 2022Natural language understanding (NLU) models often rely on dataset biases rather than intended task-relevant features to achieve high performance on specific datasets. As a result, these models perform poorly on datasets outside the training distribution. Some recent studies address this issue by reducing the weights of biased samples during the training process. However, these methods still encode biased latent features in representations and neglect the dynamic nature of bias, which hinders model prediction. We propose an NLU debiasing method, named debiasing contrastive learning (DCT), to simultaneously alleviate the above problems based on contrastive learning. We devise a debiasing, positive sampling strategy to mitigate biased latent features by selecting the least similar biased positive samples. We also propose a dynamic negative sampling strategy to capture the dynamic influence of biases by employing a bias-only model to dynamically select the most similar biased negative samples. We conduct experiments on three NLU benchmark datasets. Experimental results show that DCT outperforms state-of-the-art baselines on out-of-distribution datasets while maintaining in-distribution performance. We also verify that DCT can reduce biased latent features from the model's representation.
A Survey on Backdoor Attack and Defense in Natural Language Processing
Nov 22, 2022



Deep learning is becoming increasingly popular in real-life applications, especially in natural language processing (NLP). Users often choose training outsourcing or adopt third-party data and models due to data and computation resources being limited. In such a situation, training data and models are exposed to the public. As a result, attackers can manipulate the training process to inject some triggers into the model, which is called backdoor attack. Backdoor attack is quite stealthy and difficult to be detected because it has little inferior influence on the model's performance for the clean samples. To get a precise grasp and understanding of this problem, in this paper, we conduct a comprehensive review of backdoor attacks and defenses in the field of NLP. Besides, we summarize benchmark datasets and point out the open issues to design credible systems to defend against backdoor attacks.
uChecker: Masked Pretrained Language Models as Unsupervised Chinese Spelling Checkers
Sep 15, 2022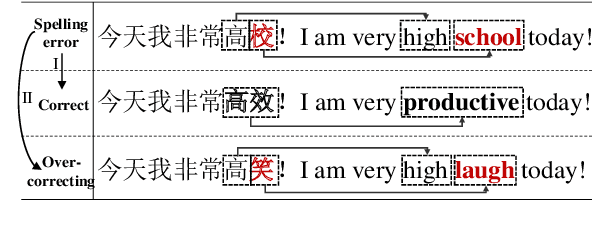


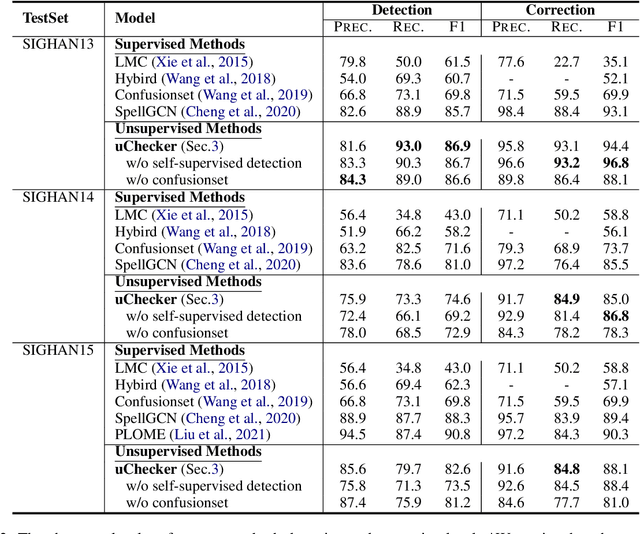
The task of Chinese Spelling Check (CSC) is aiming to detect and correct spelling errors that can be found in the text. While manually annotating a high-quality dataset is expensive and time-consuming, thus the scale of the training dataset is usually very small (e.g., SIGHAN15 only contains 2339 samples for training), therefore supervised-learning based models usually suffer the data sparsity limitation and over-fitting issue, especially in the era of big language models. In this paper, we are dedicated to investigating the \textbf{unsupervised} paradigm to address the CSC problem and we propose a framework named \textbf{uChecker} to conduct unsupervised spelling error detection and correction. Masked pretrained language models such as BERT are introduced as the backbone model considering their powerful language diagnosis capability. Benefiting from the various and flexible MASKing operations, we propose a Confusionset-guided masking strategy to fine-train the masked language model to further improve the performance of unsupervised detection and correction. Experimental results on standard datasets demonstrate the effectiveness of our proposed model uChecker in terms of character-level and sentence-level Accuracy, Precision, Recall, and F1-Measure on tasks of spelling error detection and correction respectively.
PromptAttack: Prompt-based Attack for Language Models via Gradient Search
Sep 05, 2022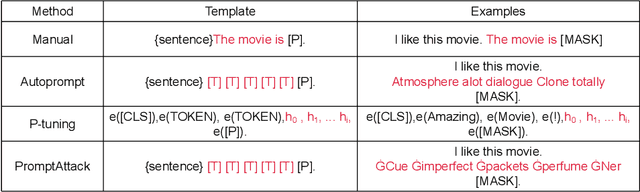
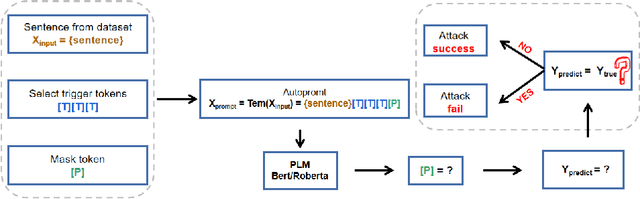

As the pre-trained language models (PLMs) continue to grow, so do the hardware and data requirements for fine-tuning PLMs. Therefore, the researchers have come up with a lighter method called \textit{Prompt Learning}. However, during the investigations, we observe that the prompt learning methods are vulnerable and can easily be attacked by some illegally constructed prompts, resulting in classification errors, and serious security problems for PLMs. Most of the current research ignores the security issue of prompt-based methods. Therefore, in this paper, we propose a malicious prompt template construction method (\textbf{PromptAttack}) to probe the security performance of PLMs. Several unfriendly template construction approaches are investigated to guide the model to misclassify the task. Extensive experiments on three datasets and three PLMs prove the effectiveness of our proposed approach PromptAttack. We also conduct experiments to verify that our method is applicable in few-shot scenarios.
Effidit: Your AI Writing Assistant
Aug 04, 2022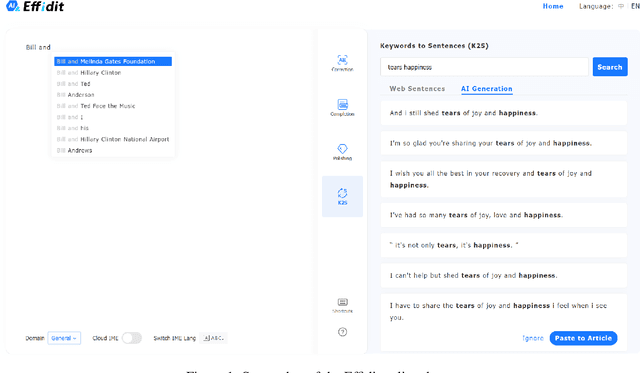

In this technical report, we introduce Effidit (Efficient and Intelligent Editing), a digital writing assistant that facilitates users to write higher-quality text more efficiently by using artificial intelligence (AI) technologies. Previous writing assistants typically provide the function of error checking (to detect and correct spelling and grammatical errors) and limited text-rewriting functionality. With the emergence of large-scale neural language models, some systems support automatically completing a sentence or a paragraph. In Effidit, we significantly expand the capacities of a writing assistant by providing functions in five categories: text completion, error checking, text polishing, keywords to sentences (K2S), and cloud input methods (cloud IME). In the text completion category, Effidit supports generation-based sentence completion, retrieval-based sentence completion, and phrase completion. In contrast, many other writing assistants so far only provide one or two of the three functions. For text polishing, we have three functions: (context-aware) phrase polishing, sentence paraphrasing, and sentence expansion, whereas many other writing assistants often support one or two functions in this category. The main contents of this report include major modules of Effidit, methods for implementing these modules, and evaluation results of some key methods.
COSPLAY: Concept Set Guided Personalized Dialogue Generation Across Both Party Personas
May 15, 2022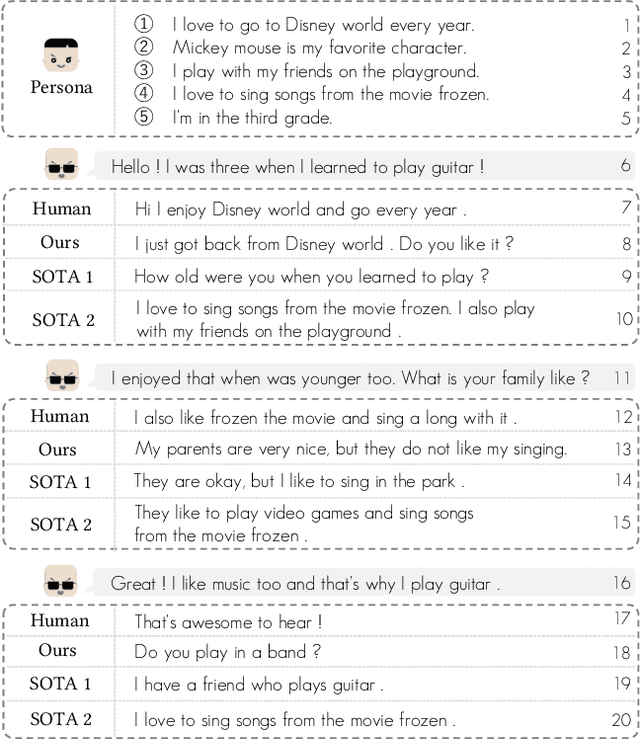
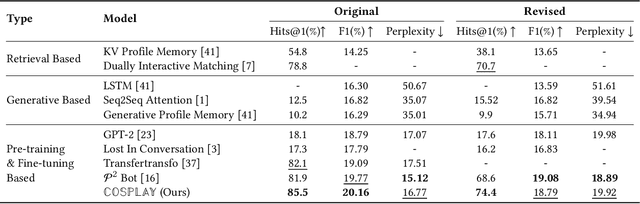
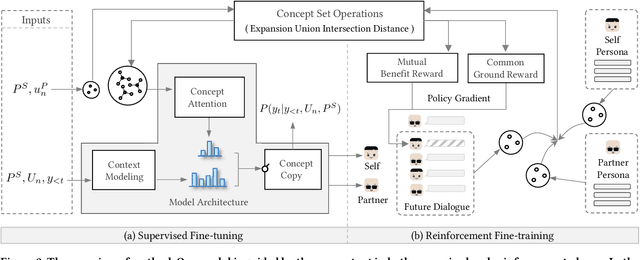
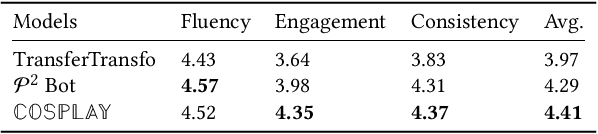
Maintaining a consistent persona is essential for building a human-like conversational model. However, the lack of attention to the partner makes the model more egocentric: they tend to show their persona by all means such as twisting the topic stiffly, pulling the conversation to their own interests regardless, and rambling their persona with little curiosity to the partner. In this work, we propose COSPLAY(COncept Set guided PersonaLized dialogue generation Across both partY personas) that considers both parties as a "team": expressing self-persona while keeping curiosity toward the partner, leading responses around mutual personas, and finding the common ground. Specifically, we first represent self-persona, partner persona and mutual dialogue all in the concept sets. Then, we propose the Concept Set framework with a suite of knowledge-enhanced operations to process them such as set algebras, set expansion, and set distance. Based on these operations as medium, we train the model by utilizing 1) concepts of both party personas, 2) concept relationship between them, and 3) their relationship to the future dialogue. Extensive experiments on a large public dataset, Persona-Chat, demonstrate that our model outperforms state-of-the-art baselines for generating less egocentric, more human-like, and higher quality responses in both automatic and human evaluations.
Event Transition Planning for Open-ended Text Generation
Apr 20, 2022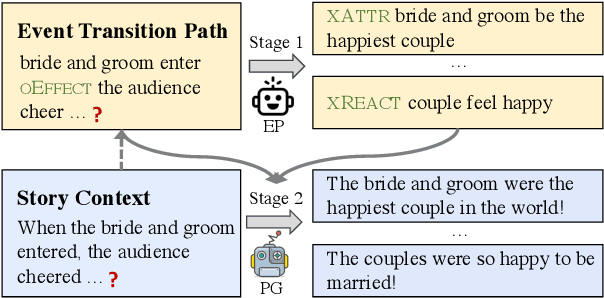

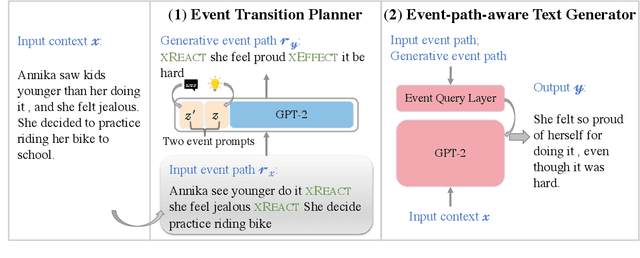
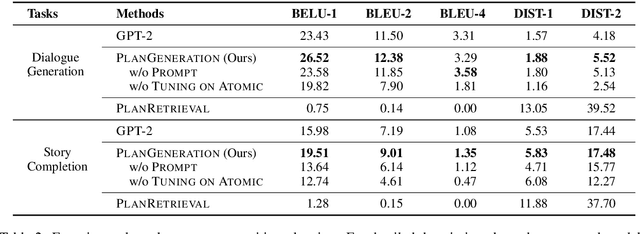
Open-ended text generation tasks, such as dialogue generation and story completion, require models to generate a coherent continuation given limited preceding context. The open-ended nature of these tasks brings new challenges to the neural auto-regressive text generators nowadays. Despite these neural models are good at producing human-like text, it is difficult for them to arrange causalities and relations between given facts and possible ensuing events. To bridge this gap, we propose a novel two-stage method which explicitly arranges the ensuing events in open-ended text generation. Our approach can be understood as a specially-trained coarse-to-fine algorithm, where an event transition planner provides a "coarse" plot skeleton and a text generator in the second stage refines the skeleton. Experiments on two open-ended text generation tasks demonstrate that our proposed method effectively improves the quality of the generated text, especially in coherence and diversity. The code is available at: \url{https://github.com/qtli/EventPlanforTextGen}.
Parameter-Efficient Tuning by Manipulating Hidden States of Pretrained Language Models For Classification Tasks
Apr 13, 2022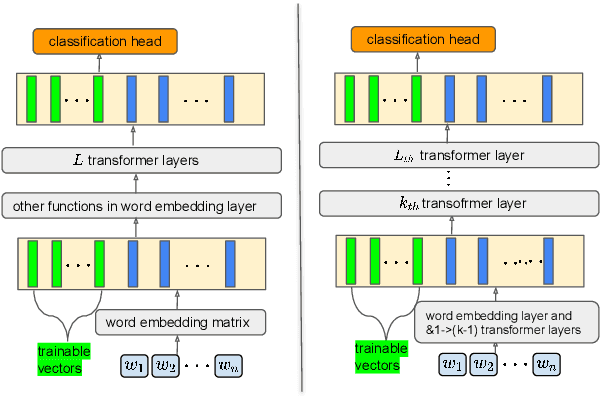
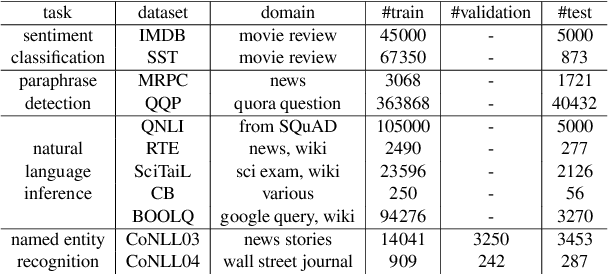
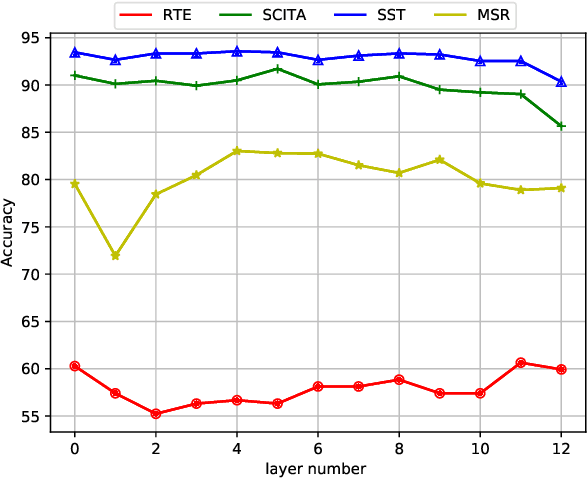
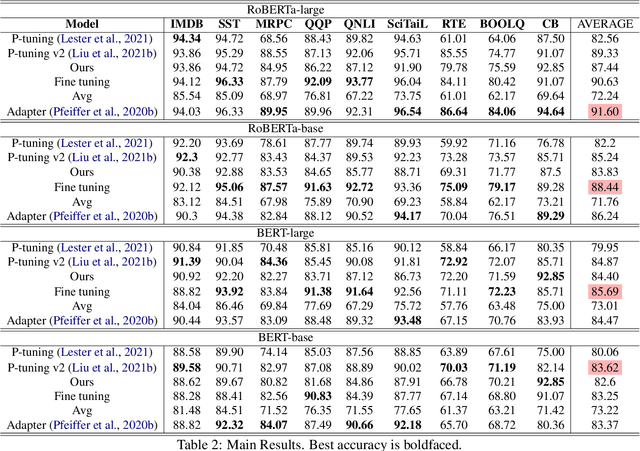
Parameter-efficient tuning aims to distill knowledge for downstream tasks by optimizing a few introduced parameters while freezing the pretrained language models (PLMs). Continuous prompt tuning which prepends a few trainable vectors to the embeddings of input is one of these methods and has drawn much attention due to its effectiveness and efficiency. This family of methods can be illustrated as exerting nonlinear transformations of hidden states inside PLMs. However, a natural question is ignored: can the hidden states be directly used for classification without changing them? In this paper, we aim to answer this question by proposing a simple tuning method which only introduces three trainable vectors. Firstly, we integrate all layers hidden states using the introduced vectors. And then, we input the integrated hidden state(s) to a task-specific linear classifier to predict categories. This scheme is similar to the way ELMo utilises hidden states except that they feed the hidden states to LSTM-based models. Although our proposed tuning scheme is simple, it achieves comparable performance with prompt tuning methods like P-tuning and P-tuning v2, verifying that original hidden states do contain useful information for classification tasks. Moreover, our method has an advantage over prompt tuning in terms of time and the number of parameters.
"Is Whole Word Masking Always Better for Chinese BERT?": Probing on Chinese Grammatical Error Correction
Mar 02, 2022
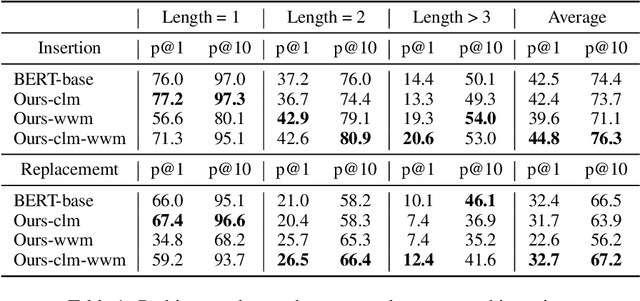

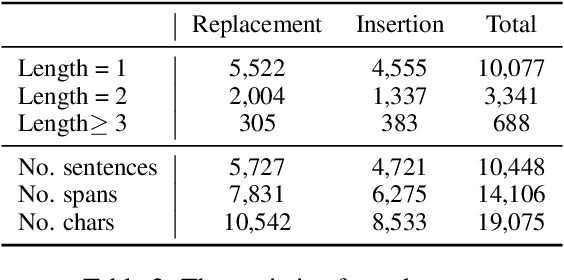
Whole word masking (WWM), which masks all subwords corresponding to a word at once, makes a better English BERT model. For the Chinese language, however, there is no subword because each token is an atomic character. The meaning of a word in Chinese is different in that a word is a compositional unit consisting of multiple characters. Such difference motivates us to investigate whether WWM leads to better context understanding ability for Chinese BERT. To achieve this, we introduce two probing tasks related to grammatical error correction and ask pretrained models to revise or insert tokens in a masked language modeling manner. We construct a dataset including labels for 19,075 tokens in 10,448 sentences. We train three Chinese BERT models with standard character-level masking (CLM), WWM, and a combination of CLM and WWM, respectively. Our major findings are as follows: First, when one character needs to be inserted or replaced, the model trained with CLM performs the best. Second, when more than one character needs to be handled, WWM is the key to better performance. Finally, when being fine-tuned on sentence-level downstream tasks, models trained with different masking strategies perform comparably.