 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGACEM: Generalized Autoregressive Cross Entropy Method for Multi-Modal Black Box Constraint Satisfaction
Feb 17, 2020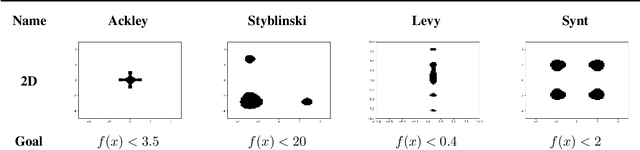
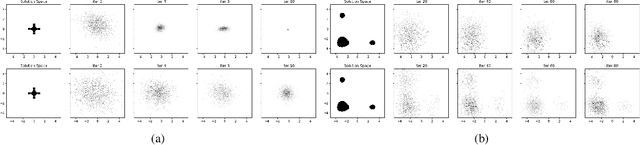
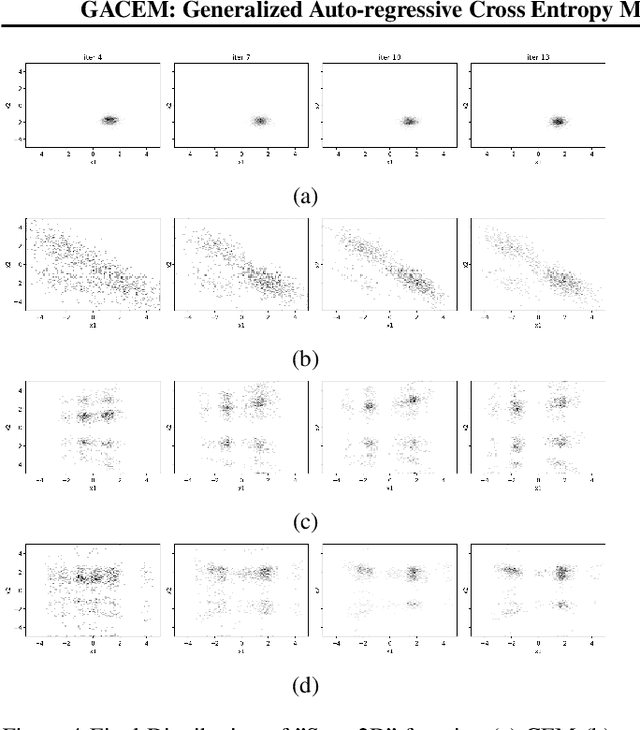
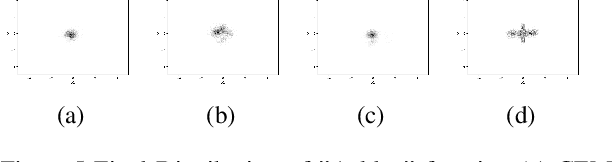
In this work we present a new method of black-box optimization and constraint satisfaction. Existing algorithms that have attempted to solve this problem are unable to consider multiple modes, and are not able to adapt to changes in environment dynamics. To address these issues, we developed a modified Cross-Entropy Method (CEM) that uses a masked auto-regressive neural network for modeling uniform distributions over the solution space. We train the model using maximum entropy policy gradient methods from Reinforcement Learning. Our algorithm is able to express complicated solution spaces, thus allowing it to track a variety of different solution regions. We empirically compare our algorithm with variations of CEM, including one with a Gaussian prior with fixed variance, and demonstrate better performance in terms of: number of diverse solutions, better mode discovery in multi-modal problems, and better sample efficiency in certain cases.
BADGR: An Autonomous Self-Supervised Learning-Based Navigation System
Feb 13, 2020
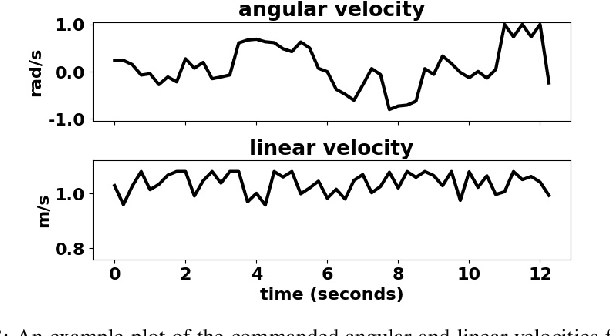


Mobile robot navigation is typically regarded as a geometric problem, in which the robot's objective is to perceive the geometry of the environment in order to plan collision-free paths towards a desired goal. However, a purely geometric view of the world can can be insufficient for many navigation problems. For example, a robot navigating based on geometry may avoid a field of tall grass because it believes it is untraversable, and will therefore fail to reach its desired goal. In this work, we investigate how to move beyond these purely geometric-based approaches using a method that learns about physical navigational affordances from experience. Our approach, which we call BADGR, is an end-to-end learning-based mobile robot navigation system that can be trained with self-supervised off-policy data gathered in real-world environments, without any simulation or human supervision. BADGR can navigate in real-world urban and off-road environments with geometrically distracting obstacles. It can also incorporate terrain preferences, generalize to novel environments, and continue to improve autonomously by gathering more data. Videos, code, and other supplemental material are available on our website https://sites.google.com/view/badgr
Preventing Imitation Learning with Adversarial Policy Ensembles
Jan 31, 2020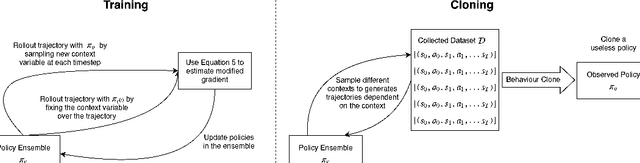

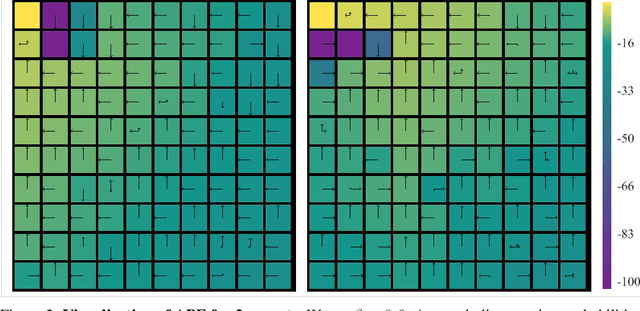

Imitation learning can reproduce policies by observing experts, which poses a problem regarding policy privacy. Policies, such as human, or policies on deployed robots, can all be cloned without consent from the owners. How can we protect against external observers cloning our proprietary policies? To answer this question we introduce a new reinforcement learning framework, where we train an ensemble of near-optimal policies, whose demonstrations are guaranteed to be useless for an external observer. We formulate this idea by a constrained optimization problem, where the objective is to improve proprietary policies, and at the same time deteriorate the virtual policy of an eventual external observer. We design a tractable algorithm to solve this new optimization problem by modifying the standard policy gradient algorithm. Our formulation can be interpreted in lenses of confidentiality and adversarial behaviour, which enables a broader perspective of this work. We demonstrate the existence of "non-clonable" ensembles, providing a solution to the above optimization problem, which is calculated by our modified policy gradient algorithm. To our knowledge, this is the first work regarding the protection of policies in Reinforcement Learning.
Hierarchical Variational Imitation Learning of Control Programs
Dec 29, 2019
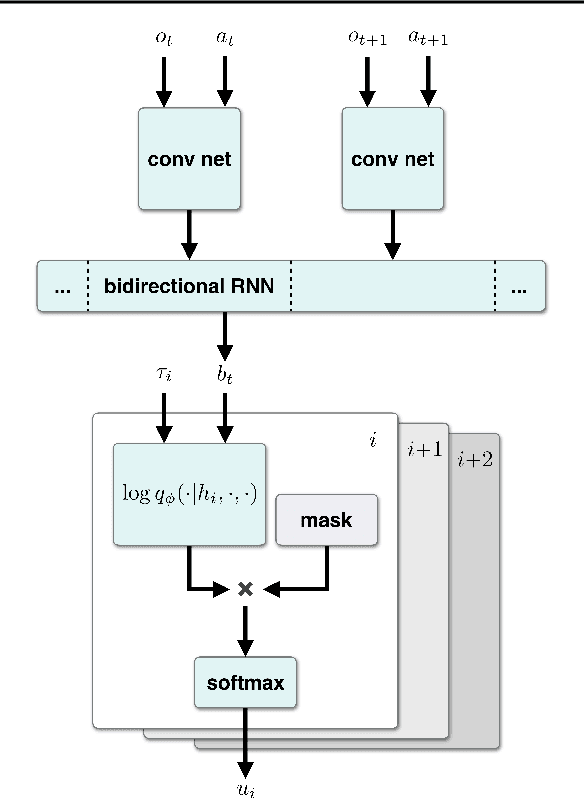
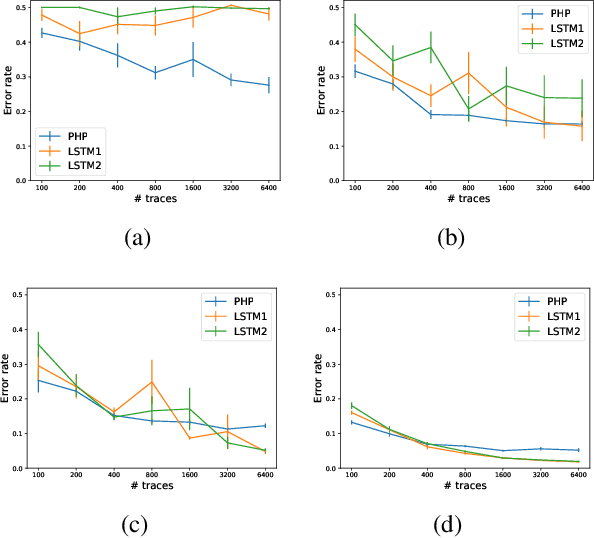
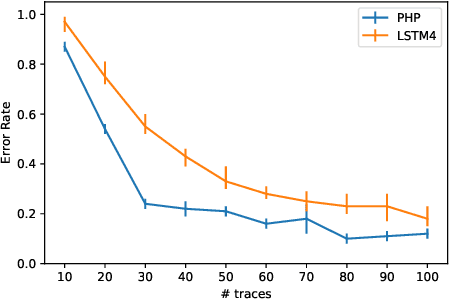
Autonomous agents can learn by imitating teacher demonstrations of the intended behavior. Hierarchical control policies are ubiquitously useful for such learning, having the potential to break down structured tasks into simpler sub-tasks, thereby improving data efficiency and generalization. In this paper, we propose a variational inference method for imitation learning of a control policy represented by parametrized hierarchical procedures (PHP), a program-like structure in which procedures can invoke sub-procedures to perform sub-tasks. Our method discovers the hierarchical structure in a dataset of observation-action traces of teacher demonstrations, by learning an approximate posterior distribution over the latent sequence of procedure calls and terminations. Samples from this learned distribution then guide the training of the hierarchical control policy. We identify and demonstrate a novel benefit of variational inference in the context of hierarchical imitation learning: in decomposing the policy into simpler procedures, inference can leverage acausal information that is unused by other methods. Training PHP with variational inference outperforms LSTM baselines in terms of data efficiency and generalization, requiring less than half as much data to achieve a 24% error rate in executing the bubble sort algorithm, and to achieve no error in executing Karel programs.
Predictive Coding for Boosting Deep Reinforcement Learning with Sparse Rewards
Dec 21, 2019

While recent progress in deep reinforcement learning has enabled robots to learn complex behaviors, tasks with long horizons and sparse rewards remain an ongoing challenge. In this work, we propose an effective reward shaping method through predictive coding to tackle sparse reward problems. By learning predictive representations offline and using these representations for reward shaping, we gain access to reward signals that understand the structure and dynamics of the environment. In particular, our method achieves better learning by providing reward signals that 1) understand environment dynamics 2) emphasize on features most useful for learning 3) resist noise in learned representations through reward accumulation. We demonstrate the usefulness of this approach in different domains ranging from robotic manipulation to navigation, and we show that reward signals produced through predictive coding are as effective for learning as hand-crafted rewards.
AVID: Learning Multi-Stage Tasks via Pixel-Level Translation of Human Videos
Dec 10, 2019



Robotic reinforcement learning (RL) holds the promise of enabling robots to learn complex behaviors through experience. However, realizing this promise requires not only effective and scalable RL algorithms, but also mechanisms to reduce human burden in terms of defining the task and resetting the environment. In this paper, we study how these challenges can be alleviated with an automated robotic learning framework, in which multi-stage tasks are defined simply by providing videos of a human demonstrator and then learned autonomously by the robot from raw image observations. A central challenge in imitating human videos is the difference in morphology between the human and robot, which typically requires manual correspondence. We instead take an automated approach and perform pixel-level image translation via CycleGAN to convert the human demonstration into a video of a robot, which can then be used to construct a reward function for a model-based RL algorithm. The robot then learns the task one stage at a time, automatically learning how to reset each stage to retry it multiple times without human-provided resets. This makes the learning process largely automatic, from intuitive task specification via a video to automated training with minimal human intervention. We demonstrate that our approach is capable of learning complex tasks, such as operating a coffee machine, directly from raw image observations, requiring only 20 minutes to provide human demonstrations and about 180 minutes of robot interaction with the environment. A supplementary video depicting the experimental setup, learning process, and our method's final performance is available from https://sites.google.com/view/icra20avid
Learning Efficient Representation for Intrinsic Motivation
Dec 09, 2019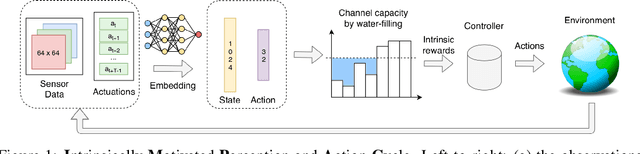

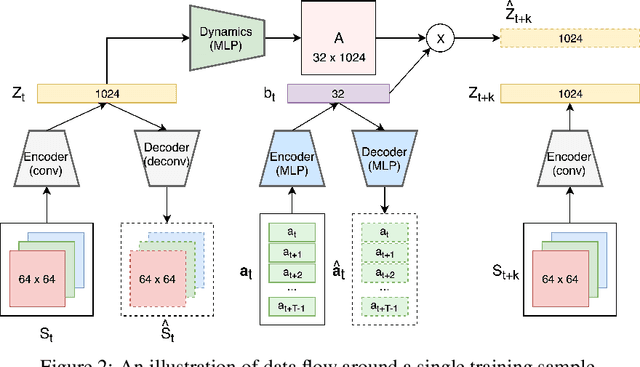
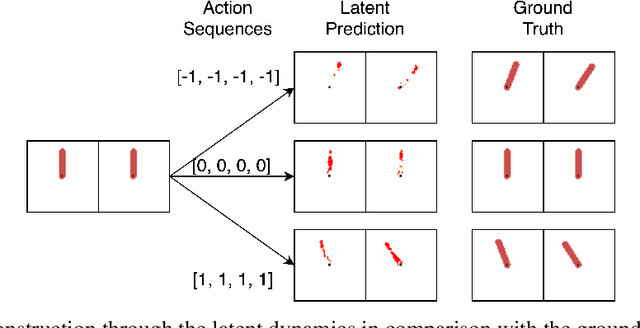
Mutual Information between agent Actions and environment States (MIAS) quantifies the influence of agent on its environment. Recently, it was found that the maximization of MIAS can be used as an intrinsic motivation for artificial agents. In literature, the term empowerment is used to represent the maximum of MIAS at a certain state. While empowerment has been shown to solve a broad range of reinforcement learning problems, its calculation in arbitrary dynamics is a challenging problem because it relies on the estimation of mutual information. Existing approaches, which rely on sampling, are limited to low dimensional spaces, because high-confidence distribution-free lower bounds for mutual information require exponential number of samples. In this work, we develop a novel approach for the estimation of empowerment in unknown dynamics from visual observation only, without the need to sample for MIAS. The core idea is to represent the relation between action sequences and future states using a stochastic dynamic model in latent space with a specific form. This allows us to efficiently compute empowerment with the "Water-Filling" algorithm from information theory. We construct this embedding with deep neural networks trained on a sophisticated objective function. Our experimental results show that the designed embedding preserves information-theoretic properties of the original dynamics.
Adaptive Online Planning for Continual Lifelong Learning
Dec 03, 2019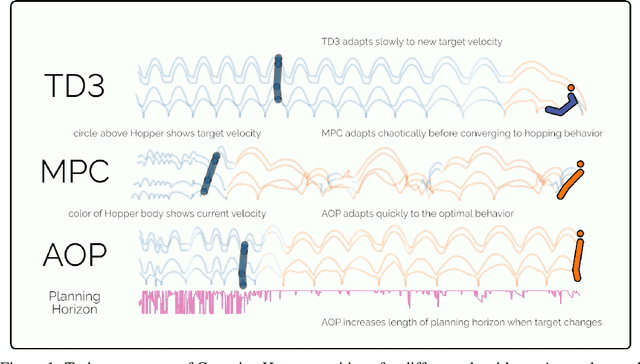
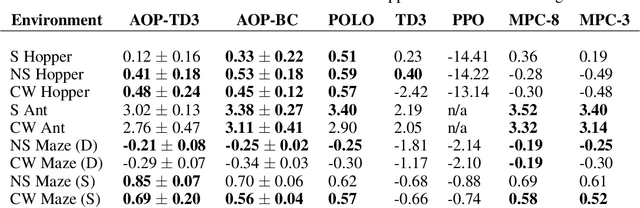
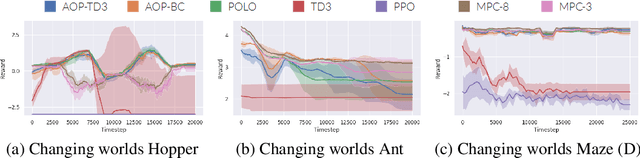

We study learning control in an online lifelong learning scenario, where mistakes can compound catastrophically into the future and the underlying dynamics of the environment may change. Traditional model-free policy learning methods have achieved successes in difficult tasks due to their broad flexibility, and capably condense broad experiences into compact networks, but struggle in this setting, as they can activate failure modes early in their lifetimes which are difficult to recover from and face performance degradation as dynamics change. On the other hand, model-based planning methods learn and adapt quickly, but require prohibitive levels of computational resources. Under constrained computation limits, the agent must allocate its resources wisely, which requires the agent to understand both its own performance and the current state of the environment: knowing that its mastery over control in the current dynamics is poor, the agent should dedicate more time to planning. We present a new algorithm, Adaptive Online Planning (AOP), that achieves strong performance in this setting by combining model-based planning with model-free learning. By measuring the performance of the planner and the uncertainty of the model-free components, AOP is able to call upon more extensive planning only when necessary, leading to reduced computation times. We show that AOP gracefully deals with novel situations, adapting behaviors and policies effectively in the face of unpredictable changes in the world -- challenges that a continual learning agent naturally faces over an extended lifetime -- even when traditional reinforcement learning methods fail.
Natural Image Manipulation for Autoregressive Models Using Fisher Scores
Nov 25, 2019



Deep autoregressive models are one of the most powerful models that exist today which achieve state-of-the-art bits per dim. However, they lie at a strict disadvantage when it comes to controlled sample generation compared to latent variable models. Latent variable models such as VAEs and normalizing flows allow meaningful semantic manipulations in latent space, which autoregressive models do not have. In this paper, we propose using Fisher scores as a method to extract embeddings from an autoregressive model to use for interpolation and show that our method provides more meaningful sample manipulation compared to alternate embeddings such as network activations.
Plan Arithmetic: Compositional Plan Vectors for Multi-Task Control
Oct 30, 2019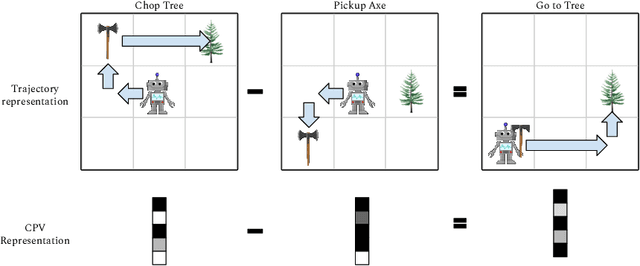
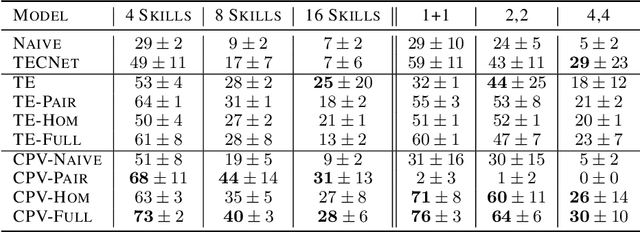
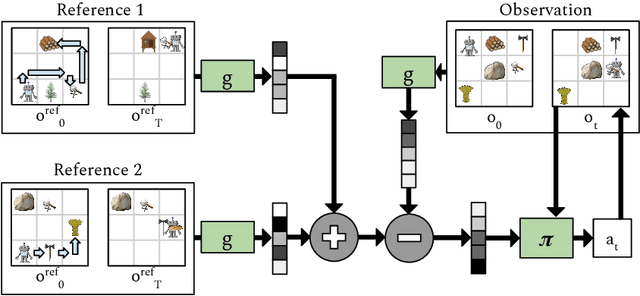
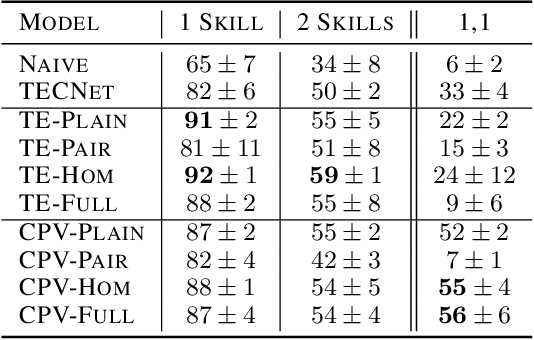
Autonomous agents situated in real-world environments must be able to master large repertoires of skills. While a single short skill can be learned quickly, it would be impractical to learn every task independently. Instead, the agent should share knowledge across behaviors such that each task can be learned efficiently, and such that the resulting model can generalize to new tasks, especially ones that are compositions or subsets of tasks seen previously. A policy conditioned on a goal or demonstration has the potential to share knowledge between tasks if it sees enough diversity of inputs. However, these methods may not generalize to a more complex task at test time. We introduce compositional plan vectors (CPVs) to enable a policy to perform compositions of tasks without additional supervision. CPVs represent trajectories as the sum of the subtasks within them. We show that CPVs can be learned within a one-shot imitation learning framework without any additional supervision or information about task hierarchy, and enable a demonstration-conditioned policy to generalize to tasks that sequence twice as many skills as the tasks seen during training. Analogously to embeddings such as word2vec in NLP, CPVs can also support simple arithmetic operations -- for example, we can add the CPVs for two different tasks to command an agent to compose both tasks, without any additional training.