 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGQE: Generalized Query Expansion for Enhanced Text-Video Retrieval
Aug 14, 2024In the rapidly expanding domain of web video content, the task of text-video retrieval has become increasingly critical, bridging the semantic gap between textual queries and video data. This paper introduces a novel data-centric approach, Generalized Query Expansion (GQE), to address the inherent information imbalance between text and video, enhancing the effectiveness of text-video retrieval systems. Unlike traditional model-centric methods that focus on designing intricate cross-modal interaction mechanisms, GQE aims to expand the text queries associated with videos both during training and testing phases. By adaptively segmenting videos into short clips and employing zero-shot captioning, GQE enriches the training dataset with comprehensive scene descriptions, effectively bridging the data imbalance gap. Furthermore, during retrieval, GQE utilizes Large Language Models (LLM) to generate a diverse set of queries and a query selection module to filter these queries based on relevance and diversity, thus optimizing retrieval performance while reducing computational overhead. Our contributions include a detailed examination of the information imbalance challenge, a novel approach to query expansion in video-text datasets, and the introduction of a query selection strategy that enhances retrieval accuracy without increasing computational costs. GQE achieves state-of-the-art performance on several benchmarks, including MSR-VTT, MSVD, LSMDC, and VATEX, demonstrating the effectiveness of addressing text-video retrieval from a data-centric perspective.
Hallucination of Multimodal Large Language Models: A Survey
Apr 29, 2024



This survey presents a comprehensive analysis of the phenomenon of hallucination in multimodal large language models (MLLMs), also known as Large Vision-Language Models (LVLMs), which have demonstrated significant advancements and remarkable abilities in multimodal tasks. Despite these promising developments, MLLMs often generate outputs that are inconsistent with the visual content, a challenge known as hallucination, which poses substantial obstacles to their practical deployment and raises concerns regarding their reliability in real-world applications. This problem has attracted increasing attention, prompting efforts to detect and mitigate such inaccuracies. We review recent advances in identifying, evaluating, and mitigating these hallucinations, offering a detailed overview of the underlying causes, evaluation benchmarks, metrics, and strategies developed to address this issue. Additionally, we analyze the current challenges and limitations, formulating open questions that delineate potential pathways for future research. By drawing the granular classification and landscapes of hallucination causes, evaluation benchmarks, and mitigation methods, this survey aims to deepen the understanding of hallucinations in MLLMs and inspire further advancements in the field. Through our thorough and in-depth review, we contribute to the ongoing dialogue on enhancing the robustness and reliability of MLLMs, providing valuable insights and resources for researchers and practitioners alike. Resources are available at: https://github.com/showlab/Awesome-MLLM-Hallucination.
Text Is MASS: Modeling as Stochastic Embedding for Text-Video Retrieval
Mar 26, 2024The increasing prevalence of video clips has sparked growing interest in text-video retrieval. Recent advances focus on establishing a joint embedding space for text and video, relying on consistent embedding representations to compute similarity. However, the text content in existing datasets is generally short and concise, making it hard to fully describe the redundant semantics of a video. Correspondingly, a single text embedding may be less expressive to capture the video embedding and empower the retrieval. In this study, we propose a new stochastic text modeling method T-MASS, i.e., text is modeled as a stochastic embedding, to enrich text embedding with a flexible and resilient semantic range, yielding a text mass. To be specific, we introduce a similarity-aware radius module to adapt the scale of the text mass upon the given text-video pairs. Plus, we design and develop a support text regularization to further control the text mass during the training. The inference pipeline is also tailored to fully exploit the text mass for accurate retrieval. Empirical evidence suggests that T-MASS not only effectively attracts relevant text-video pairs while distancing irrelevant ones, but also enables the determination of precise text embeddings for relevant pairs. Our experimental results show a substantial improvement of T-MASS over baseline (3% to 6.3% by R@1). Also, T-MASS achieves state-of-the-art performance on five benchmark datasets, including MSRVTT, LSMDC, DiDeMo, VATEX, and Charades.
Hourglass Tokenizer for Efficient Transformer-Based 3D Human Pose Estimation
Nov 20, 2023



Transformers have been successfully applied in the field of video-based 3D human pose estimation. However, the high computational costs of these video pose transformers (VPTs) make them impractical on resource-constrained devices. In this paper, we present a plug-and-play pruning-and-recovering framework, called Hourglass Tokenizer (HoT), for efficient transformer-based 3D human pose estimation from videos. Our HoT begins with pruning pose tokens of redundant frames and ends with recovering full-length tokens, resulting in a few pose tokens in the intermediate transformer blocks and thus improving the model efficiency. To effectively achieve this, we propose a token pruning cluster (TPC) that dynamically selects a few representative tokens with high semantic diversity while eliminating the redundancy of video frames. In addition, we develop a token recovering attention (TRA) to restore the detailed spatio-temporal information based on the selected tokens, thereby expanding the network output to the original full-length temporal resolution for fast inference. Extensive experiments on two benchmark datasets (i.e., Human3.6M and MPI-INF-3DHP) demonstrate that our method can achieve both high efficiency and estimation accuracy compared to the original VPT models. For instance, applying to MotionBERT and MixSTE on Human3.6M, our HoT can save nearly 50% FLOPs without sacrificing accuracy and nearly 40% FLOPs with only 0.2% accuracy drop, respectively. Our source code will be open-sourced.
Human Pose-based Estimation, Tracking and Action Recognition with Deep Learning: A Survey
Oct 19, 2023



Human pose analysis has garnered significant attention within both the research community and practical applications, owing to its expanding array of uses, including gaming, video surveillance, sports performance analysis, and human-computer interactions, among others. The advent of deep learning has significantly improved the accuracy of pose capture, making pose-based applications increasingly practical. This paper presents a comprehensive survey of pose-based applications utilizing deep learning, encompassing pose estimation, pose tracking, and action recognition.Pose estimation involves the determination of human joint positions from images or image sequences. Pose tracking is an emerging research direction aimed at generating consistent human pose trajectories over time. Action recognition, on the other hand, targets the identification of action types using pose estimation or tracking data. These three tasks are intricately interconnected, with the latter often reliant on the former. In this survey, we comprehensively review related works, spanning from single-person pose estimation to multi-person pose estimation, from 2D pose estimation to 3D pose estimation, from single image to video, from mining temporal context gradually to pose tracking, and lastly from tracking to pose-based action recognition. As a survey centered on the application of deep learning to pose analysis, we explicitly discuss both the strengths and limitations of existing techniques. Notably, we emphasize methodologies for integrating these three tasks into a unified framework within video sequences. Additionally, we explore the challenges involved and outline potential directions for future research.
SCT: A Simple Baseline for Parameter-Efficient Fine-Tuning via Salient Channels
Sep 18, 2023



Pre-trained vision transformers have strong representation benefits to various downstream tasks. Recently, many parameter-efficient fine-tuning (PEFT) methods have been proposed, and their experiments demonstrate that tuning only 1% of extra parameters could surpass full fine-tuning in low-data resource scenarios. However, these methods overlook the task-specific information when fine-tuning diverse downstream tasks. In this paper, we propose a simple yet effective method called "Salient Channel Tuning" (SCT) to leverage the task-specific information by forwarding the model with the task images to select partial channels in a feature map that enables us to tune only 1/8 channels leading to significantly lower parameter costs. Experiments outperform full fine-tuning on 18 out of 19 tasks in the VTAB-1K benchmark by adding only 0.11M parameters of the ViT-B, which is 780$\times$ fewer than its full fine-tuning counterpart. Furthermore, experiments on domain generalization and few-shot learning surpass other PEFT methods with lower parameter costs, demonstrating our proposed tuning technique's strong capability and effectiveness in the low-data regime.
Multi-stage Factorized Spatio-Temporal Representation for RGB-D Action and Gesture Recognition
Sep 11, 2023



RGB-D action and gesture recognition remain an interesting topic in human-centered scene understanding, primarily due to the multiple granularities and large variation in human motion. Although many RGB-D based action and gesture recognition approaches have demonstrated remarkable results by utilizing highly integrated spatio-temporal representations across multiple modalities (i.e., RGB and depth data), they still encounter several challenges. Firstly, vanilla 3D convolution makes it hard to capture fine-grained motion differences between local clips under different modalities. Secondly, the intricate nature of highly integrated spatio-temporal modeling can lead to optimization difficulties. Thirdly, duplicate and unnecessary information can add complexity and complicate entangled spatio-temporal modeling. To address the above issues, we propose an innovative heuristic architecture called Multi-stage Factorized Spatio-Temporal (MFST) for RGB-D action and gesture recognition. The proposed MFST model comprises a 3D Central Difference Convolution Stem (CDC-Stem) module and multiple factorized spatio-temporal stages. The CDC-Stem enriches fine-grained temporal perception, and the multiple hierarchical spatio-temporal stages construct dimension-independent higher-order semantic primitives. Specifically, the CDC-Stem module captures bottom-level spatio-temporal features and passes them successively to the following spatio-temporal factored stages to capture the hierarchical spatial and temporal features through the Multi- Scale Convolution and Transformer (MSC-Trans) hybrid block and Weight-shared Multi-Scale Transformer (WMS-Trans) block. The seamless integration of these innovative designs results in a robust spatio-temporal representation that outperforms state-of-the-art approaches on RGB-D action and gesture recognition datasets.
Revisiting Vision Transformer from the View of Path Ensemble
Aug 12, 2023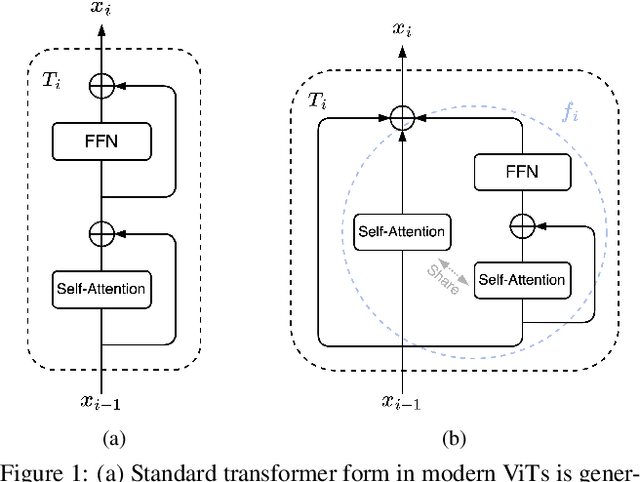
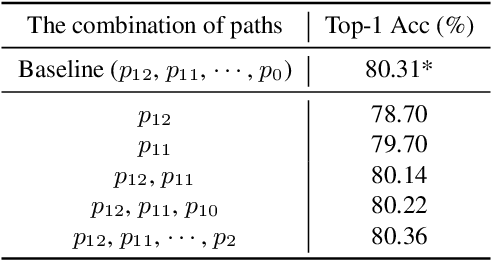
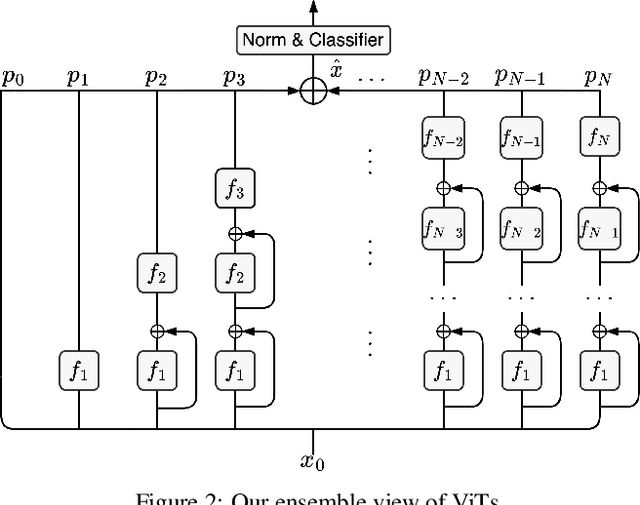
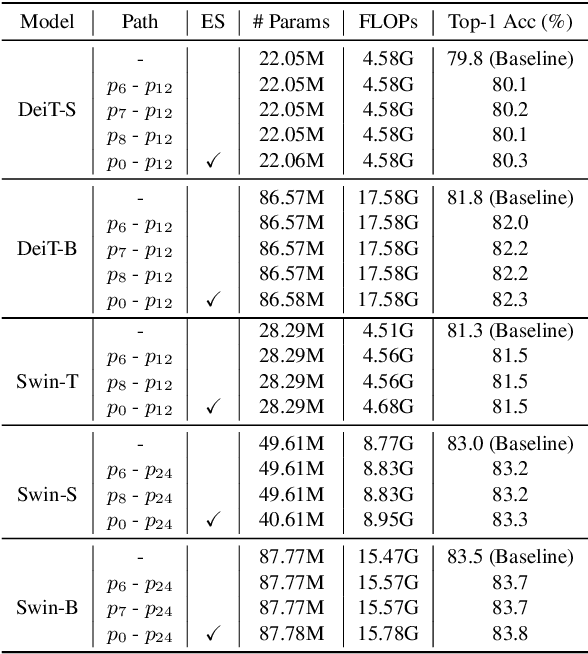
Vision Transformers (ViTs) are normally regarded as a stack of transformer layers. In this work, we propose a novel view of ViTs showing that they can be seen as ensemble networks containing multiple parallel paths with different lengths. Specifically, we equivalently transform the traditional cascade of multi-head self-attention (MSA) and feed-forward network (FFN) into three parallel paths in each transformer layer. Then, we utilize the identity connection in our new transformer form and further transform the ViT into an explicit multi-path ensemble network. From the new perspective, these paths perform two functions: the first is to provide the feature for the classifier directly, and the second is to provide the lower-level feature representation for subsequent longer paths. We investigate the influence of each path for the final prediction and discover that some paths even pull down the performance. Therefore, we propose the path pruning and EnsembleScale skills for improvement, which cut out the underperforming paths and re-weight the ensemble components, respectively, to optimize the path combination and make the short paths focus on providing high-quality representation for subsequent paths. We also demonstrate that our path combination strategies can help ViTs go deeper and act as high-pass filters to filter out partial low-frequency signals. To further enhance the representation of paths served for subsequent paths, self-distillation is applied to transfer knowledge from the long paths to the short paths. This work calls for more future research to explain and design ViTs from new perspectives.
Audio-Enhanced Text-to-Video Retrieval using Text-Conditioned Feature Alignment
Jul 24, 2023



Text-to-video retrieval systems have recently made significant progress by utilizing pre-trained models trained on large-scale image-text pairs. However, most of the latest methods primarily focus on the video modality while disregarding the audio signal for this task. Nevertheless, a recent advancement by ECLIPSE has improved long-range text-to-video retrieval by developing an audiovisual video representation. Nonetheless, the objective of the text-to-video retrieval task is to capture the complementary audio and video information that is pertinent to the text query rather than simply achieving better audio and video alignment. To address this issue, we introduce TEFAL, a TExt-conditioned Feature ALignment method that produces both audio and video representations conditioned on the text query. Instead of using only an audiovisual attention block, which could suppress the audio information relevant to the text query, our approach employs two independent cross-modal attention blocks that enable the text to attend to the audio and video representations separately. Our proposed method's efficacy is demonstrated on four benchmark datasets that include audio: MSR-VTT, LSMDC, VATEX, and Charades, and achieves better than state-of-the-art performance consistently across the four datasets. This is attributed to the additional text-query-conditioned audio representation and the complementary information it adds to the text-query-conditioned video representation.
DOAD: Decoupled One Stage Action Detection Network
Apr 04, 2023



Localizing people and recognizing their actions from videos is a challenging task towards high-level video understanding. Existing methods are mostly two-stage based, with one stage for person bounding box generation and the other stage for action recognition. However, such two-stage methods are generally with low efficiency. We observe that directly unifying detection and action recognition normally suffers from (i) inferior learning due to different desired properties of context representation for detection and action recognition; (ii) optimization difficulty with insufficient training data. In this work, we present a decoupled one-stage network dubbed DOAD, to mitigate above issues and improve the efficiency for spatio-temporal action detection. To achieve it, we decouple detection and action recognition into two branches. Specifically, one branch focuses on detection representation for actor detection, and the other one for action recognition. For the action branch, we design a transformer-based module (TransPC) to model pairwise relationships between people and context. Different from commonly used vector-based dot product in self-attention, it is built upon a novel matrix-based key and value for Hadamard attention to model person-context information. It not only exploits relationships between person pairs but also takes into account context and relative position information. The results on AVA and UCF101-24 datasets show that our method is competitive with two-stage state-of-the-art methods with significant efficiency improvement.