 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Identity, Many Roles: Multimodal Entity Coreference for Enhanced Video Situation Recognition
Apr 25, 2026Video Situation Recognition (VidSitu) addresses the challenging problem of "who did what to whom, with what, how, and where" in a video. It tests thorough video understanding by requiring identification of salient actions and associated short descriptions for event roles across multiple events. Grounding with VidSitu requires spatio-temporal localization of key entities across shots and varied appearances. We posit that coherent video understanding requires consistent identification of entities that play different roles. We propose Multimodal Entity Coreference (MEC) to unite entity descriptions in text with grounding across the video. Towards this, we introduce CineMEC, a multi-stage approach that unites event role mention groups with visual clusters of entities, without explicit grounding supervision during training. Our approach is designed to exploit the synergy between visual grounding and captioning, where improving one influences the other and vice versa. For evaluation, we extend the VidSitu dataset with grounding annotations. While previous work focuses primarily on descriptions, CineMEC improves consistency across both: captioning (+2.5% CIDEr, +7% LEA) and visual grounding (+18% HOTA).
Perceptio: Perception Enhanced Vision Language Models via Spatial Token Generation
Mar 19, 2026Large Vision Language Models (LVLMs) excel at semantic understanding but struggle with fine grained spatial grounding, as the model must implicitly infer complex geometry without ever producing a spatial interpretation. We present Perceptio, a perception enhanced LVLM with 2D and 3D spatial reasoning abilities, enabled via explicit semantic segmentation tokens and depth tokens generated directly within the autoregressive sequence. Concretely, we (i) distill a VQVAE depth codebook from a strong monocular teacher to tokenize dense depth into compact sequences, and (ii) integrate SAM2 based semantic segmentation tokens and VQ-VAE depth tokens inside the LLM so the model first emits spatial tokens and then answers. To stabilize depth token generation, we introduce novel composite depth-token objectives (marker, token, and count losses) and a soft-merging technique for differentiable reconstruction. We adopt a multi-task co-training strategy across diverse datasets, letting the model learn perception tokens to tackle multiple downstream tasks. Building on InternVL, Perceptio achieves state-of-the-art performance across benchmarks: improving referring expression segmentation by +0.8/+1.4/+1.1 cIoU on RefCOCO/+/g HardBLINK spatial understanding accuracy by 10.3%, and MMBench accuracy by 1.0%, demonstrating that explicit spatial chain-of-thought materially strengthens spatial grounding in LVLMs.
CounterVid: Counterfactual Video Generation for Mitigating Action and Temporal Hallucinations in Video-Language Models
Jan 08, 2026Video-language models (VLMs) achieve strong multimodal understanding but remain prone to hallucinations, especially when reasoning about actions and temporal order. Existing mitigation strategies, such as textual filtering or random video perturbations, often fail to address the root cause: over-reliance on language priors rather than fine-grained visual dynamics. We propose a scalable framework for counterfactual video generation that synthesizes videos differing only in actions or temporal structure while preserving scene context. Our pipeline combines multimodal LLMs for action proposal and editing guidance with diffusion-based image and video models to generate semantic hard negatives at scale. Using this framework, we build CounterVid, a synthetic dataset of ~26k preference pairs targeting action recognition and temporal reasoning. We further introduce MixDPO, a unified Direct Preference Optimization approach that jointly leverages textual and visual preferences. Fine-tuning Qwen2.5-VL with MixDPO yields consistent improvements, notably in temporal ordering, and transfers effectively to standard video hallucination benchmarks. Code and models will be made publicly available.
Augment the Pairs: Semantics-Preserving Image-Caption Pair Augmentation for Grounding-Based Vision and Language Models
Nov 05, 2023Grounding-based vision and language models have been successfully applied to low-level vision tasks, aiming to precisely locate objects referred in captions. The effectiveness of grounding representation learning heavily relies on the scale of the training dataset. Despite being a useful data enrichment strategy, data augmentation has received minimal attention in existing vision and language tasks as augmentation for image-caption pairs is non-trivial. In this study, we propose a robust phrase grounding model trained with text-conditioned and text-unconditioned data augmentations. Specifically, we apply text-conditioned color jittering and horizontal flipping to ensure semantic consistency between images and captions. To guarantee image-caption correspondence in the training samples, we modify the captions according to pre-defined keywords when applying horizontal flipping. Additionally, inspired by recent masked signal reconstruction, we propose to use pixel-level masking as a novel form of data augmentation. While we demonstrate our data augmentation method with MDETR framework, the proposed approach is applicable to common grounding-based vision and language tasks with other frameworks. Finally, we show that image encoder pretrained on large-scale image and language datasets (such as CLIP) can further improve the results. Through extensive experiments on three commonly applied datasets: Flickr30k, referring expressions and GQA, our method demonstrates advanced performance over the state-of-the-arts with various metrics. Code can be found in https://github.com/amzn/augment-the-pairs-wacv2024.
Audio-Enhanced Text-to-Video Retrieval using Text-Conditioned Feature Alignment
Jul 24, 2023



Text-to-video retrieval systems have recently made significant progress by utilizing pre-trained models trained on large-scale image-text pairs. However, most of the latest methods primarily focus on the video modality while disregarding the audio signal for this task. Nevertheless, a recent advancement by ECLIPSE has improved long-range text-to-video retrieval by developing an audiovisual video representation. Nonetheless, the objective of the text-to-video retrieval task is to capture the complementary audio and video information that is pertinent to the text query rather than simply achieving better audio and video alignment. To address this issue, we introduce TEFAL, a TExt-conditioned Feature ALignment method that produces both audio and video representations conditioned on the text query. Instead of using only an audiovisual attention block, which could suppress the audio information relevant to the text query, our approach employs two independent cross-modal attention blocks that enable the text to attend to the audio and video representations separately. Our proposed method's efficacy is demonstrated on four benchmark datasets that include audio: MSR-VTT, LSMDC, VATEX, and Charades, and achieves better than state-of-the-art performance consistently across the four datasets. This is attributed to the additional text-query-conditioned audio representation and the complementary information it adds to the text-query-conditioned video representation.
PodSumm -- Podcast Audio Summarization
Sep 22, 2020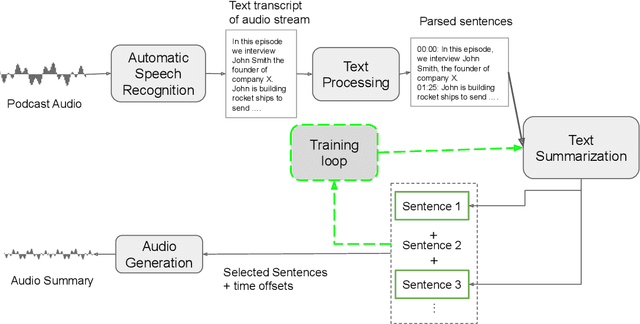
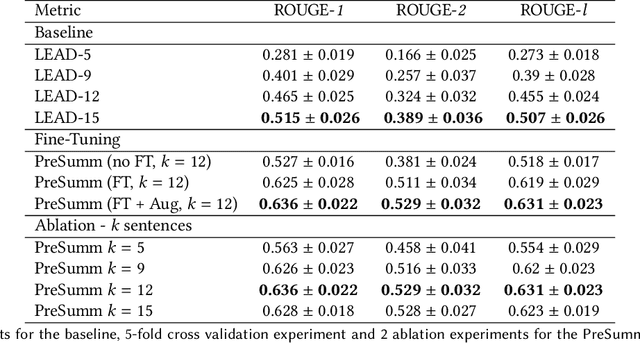
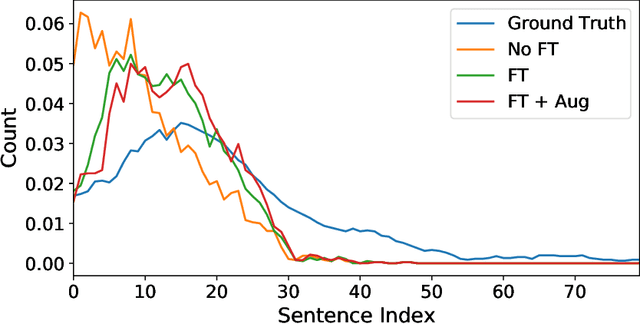
The diverse nature, scale, and specificity of podcasts present a unique challenge to content discovery systems. Listeners often rely on text descriptions of episodes provided by the podcast creators to discover new content. Some factors like the presentation style of the narrator and production quality are significant indicators of subjective user preference but are difficult to quantify and not reflected in the text descriptions provided by the podcast creators. We propose the automated creation of podcast audio summaries to aid in content discovery and help listeners to quickly preview podcast content before investing time in listening to an entire episode. In this paper, we present a method to automatically construct a podcast summary via guidance from the text-domain. Our method performs two key steps, namely, audio to text transcription and text summary generation. Motivated by a lack of datasets for this task, we curate an internal dataset, find an effective scheme for data augmentation, and design a protocol to gather summaries from annotators. We fine-tune a PreSumm[10] model with our augmented dataset and perform an ablation study. Our method achieves ROUGE-F(1/2/L) scores of 0.63/0.53/0.63 on our dataset. We hope these results may inspire future research in this direction.