 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Learning and Learnablity of Quasimetrics
Jul 18, 2022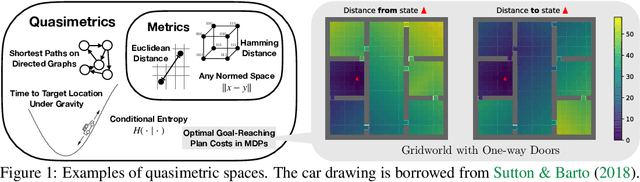
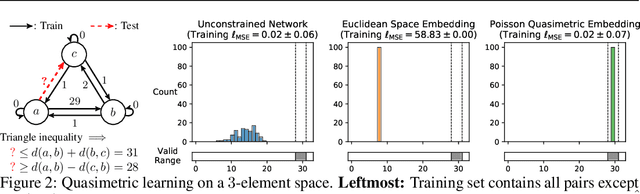
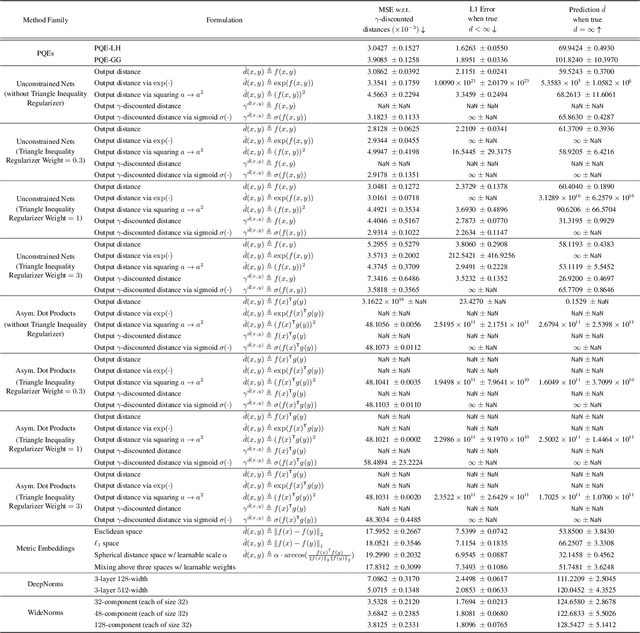
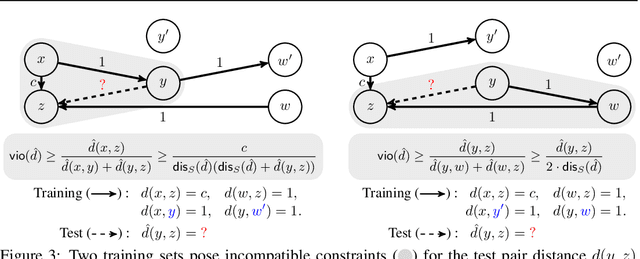
Our world is full of asymmetries. Gravity and wind can make reaching a place easier than coming back. Social artifacts such as genealogy charts and citation graphs are inherently directed. In reinforcement learning and control, optimal goal-reaching strategies are rarely reversible (symmetrical). Distance functions supported on these asymmetrical structures are called quasimetrics. Despite their common appearance, little research has been done on the learning of quasimetrics. Our theoretical analysis reveals that a common class of learning algorithms, including unconstrained multilayer perceptrons (MLPs), provably fails to learn a quasimetric consistent with training data. In contrast, our proposed Poisson Quasimetric Embedding (PQE) is the first quasimetric learning formulation that both is learnable with gradient-based optimization and enjoys strong performance guarantees. Experiments on random graphs, social graphs, and offline Q-learning demonstrate its effectiveness over many common baselines.
Denoised MDPs: Learning World Models Better Than the World Itself
Jul 18, 2022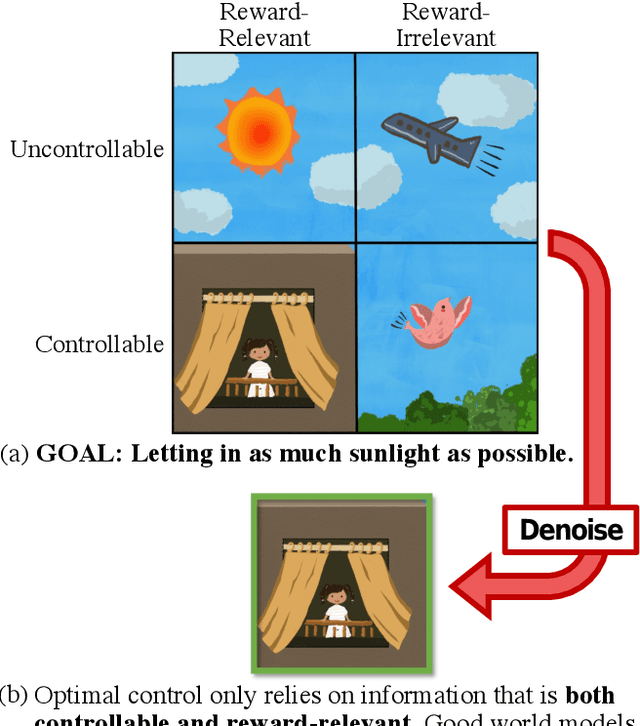
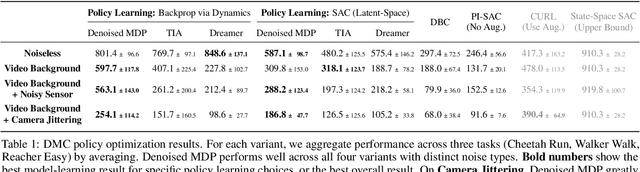
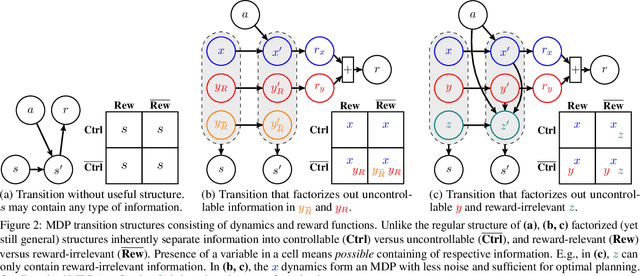
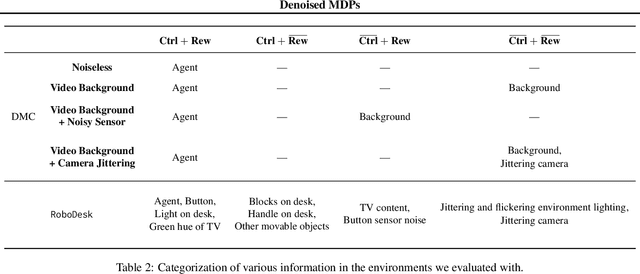
The ability to separate signal from noise, and reason with clean abstractions, is critical to intelligence. With this ability, humans can efficiently perform real world tasks without considering all possible nuisance factors.How can artificial agents do the same? What kind of information can agents safely discard as noises? In this work, we categorize information out in the wild into four types based on controllability and relation with reward, and formulate useful information as that which is both controllable and reward-relevant. This framework clarifies the kinds information removed by various prior work on representation learning in reinforcement learning (RL), and leads to our proposed approach of learning a Denoised MDP that explicitly factors out certain noise distractors. Extensive experiments on variants of DeepMind Control Suite and RoboDesk demonstrate superior performance of our denoised world model over using raw observations alone, and over prior works, across policy optimization control tasks as well as the non-control task of joint position regression.
Developing a Series of AI Challenges for the United States Department of the Air Force
Jul 14, 2022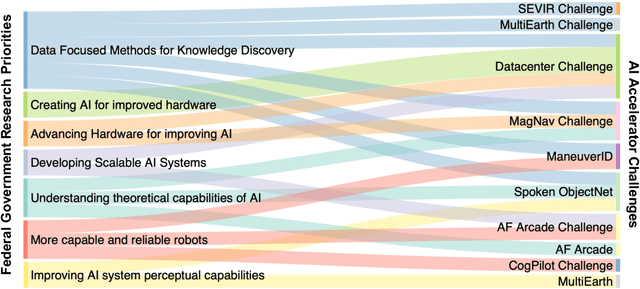

Through a series of federal initiatives and orders, the U.S. Government has been making a concerted effort to ensure American leadership in AI. These broad strategy documents have influenced organizations such as the United States Department of the Air Force (DAF). The DAF-MIT AI Accelerator is an initiative between the DAF and MIT to bridge the gap between AI researchers and DAF mission requirements. Several projects supported by the DAF-MIT AI Accelerator are developing public challenge problems that address numerous Federal AI research priorities. These challenges target priorities by making large, AI-ready datasets publicly available, incentivizing open-source solutions, and creating a demand signal for dual use technologies that can stimulate further research. In this article, we describe these public challenges being developed and how their application contributes to scientific advances.
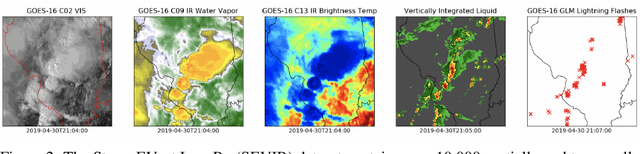
MultiEarth 2022 -- Multimodal Learning for Earth and Environment Workshop and Challenge
Apr 27, 2022


The Multimodal Learning for Earth and Environment Challenge (MultiEarth 2022) will be the first competition aimed at the monitoring and analysis of deforestation in the Amazon rainforest at any time and in any weather conditions. The goal of the Challenge is to provide a common benchmark for multimodal information processing and to bring together the earth and environmental science communities as well as multimodal representation learning communities to compare the relative merits of the various multimodal learning methods to deforestation estimation under well-defined and strictly comparable conditions. MultiEarth 2022 will have three sub-challenges: 1) matrix completion, 2) deforestation estimation, and 3) image-to-image translation. This paper presents the challenge guidelines, datasets, and evaluation metrics for the three sub-challenges. Our challenge website is available at https://sites.google.com/view/rainforest-challenge.
Any-resolution Training for High-resolution Image Synthesis
Apr 14, 2022
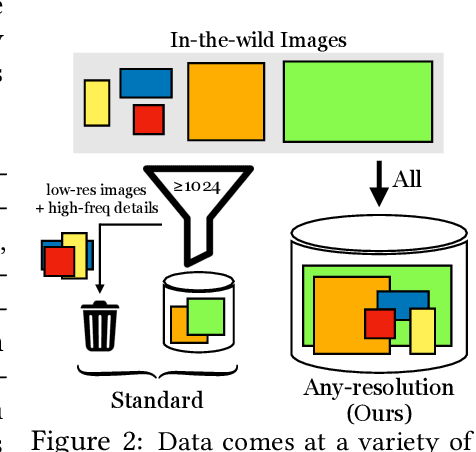
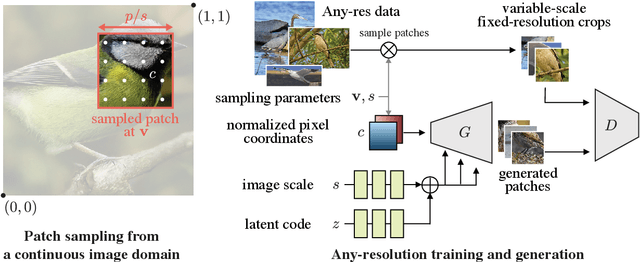
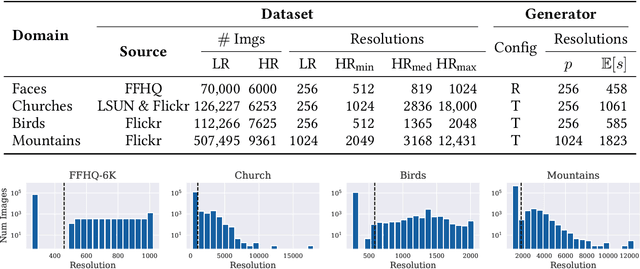
Generative models operate at fixed resolution, even though natural images come in a variety of sizes. As high-resolution details are downsampled away, and low-resolution images are discarded altogether, precious supervision is lost. We argue that every pixel matters and create datasets with variable-size images, collected at their native resolutions. Taking advantage of this data is challenging; high-resolution processing is costly, and current architectures can only process fixed-resolution data. We introduce continuous-scale training, a process that samples patches at random scales to train a new generator with variable output resolutions. First, conditioning the generator on a target scale allows us to generate higher resolutions images than previously possible, without adding layers to the model. Second, by conditioning on continuous coordinates, we can sample patches that still obey a consistent global layout, which also allows for scalable training at higher resolutions. Controlled FFHQ experiments show our method takes advantage of the multi-resolution training data better than discrete multi-scale approaches, achieving better FID scores and cleaner high-frequency details. We also train on other natural image domains including churches, mountains, and birds, and demonstrate arbitrary scale synthesis with both coherent global layouts and realistic local details, going beyond 2K resolution in our experiments. Our project page is available at: https://chail.github.io/anyres-gan/.
Visual Prompting: Modifying Pixel Space to Adapt Pre-trained Models
Mar 31, 2022

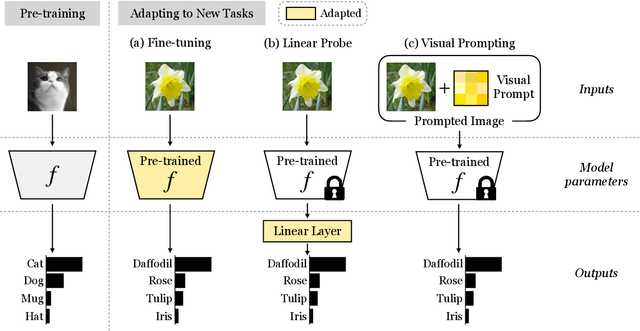
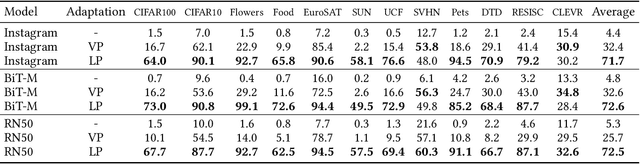
Prompting has recently become a popular paradigm for adapting language models to downstream tasks. Rather than fine-tuning model parameters or adding task-specific heads, this approach steers a model to perform a new task simply by adding a text prompt to the model's inputs. In this paper, we explore the question: can we create prompts with pixels instead? In other words, can pre-trained vision models be adapted to a new task solely by adding pixels to their inputs? We introduce visual prompting, which learns a task-specific image perturbation such that a frozen pre-trained model prompted with this perturbation performs a new task. We discover that changing only a few pixels is enough to adapt models to new tasks and datasets, and performs on par with linear probing, the current de facto approach to lightweight adaptation. The surprising effectiveness of visual prompting provides a new perspective on how to adapt pre-trained models in vision, and opens up the possibility of adapting models solely through their inputs, which, unlike model parameters or outputs, are typically under an end-user's control. Code is available at http://hjbahng.github.io/visual_prompting .
Learning to generate line drawings that convey geometry and semantics
Mar 29, 2022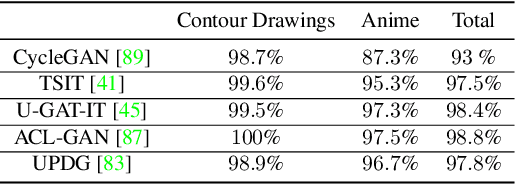
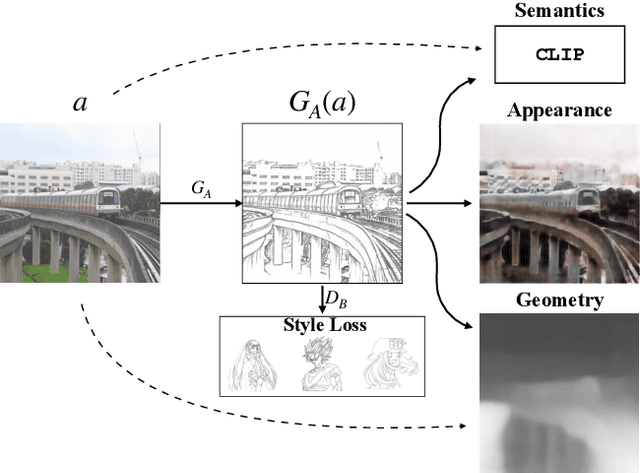
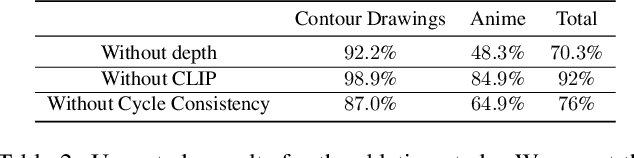

This paper presents an unpaired method for creating line drawings from photographs. Current methods often rely on high quality paired datasets to generate line drawings. However, these datasets often have limitations due to the subjects of the drawings belonging to a specific domain, or in the amount of data collected. Although recent work in unsupervised image-to-image translation has shown much progress, the latest methods still struggle to generate compelling line drawings. We observe that line drawings are encodings of scene information and seek to convey 3D shape and semantic meaning. We build these observations into a set of objectives and train an image translation to map photographs into line drawings. We introduce a geometry loss which predicts depth information from the image features of a line drawing, and a semantic loss which matches the CLIP features of a line drawing with its corresponding photograph. Our approach outperforms state-of-the-art unpaired image translation and line drawing generation methods on creating line drawings from arbitrary photographs. For code and demo visit our webpage carolineec.github.io/informative_drawings
NeRF-Supervision: Learning Dense Object Descriptors from Neural Radiance Fields
Mar 03, 2022



Thin, reflective objects such as forks and whisks are common in our daily lives, but they are particularly challenging for robot perception because it is hard to reconstruct them using commodity RGB-D cameras or multi-view stereo techniques. While traditional pipelines struggle with objects like these, Neural Radiance Fields (NeRFs) have recently been shown to be remarkably effective for performing view synthesis on objects with thin structures or reflective materials. In this paper we explore the use of NeRF as a new source of supervision for robust robot vision systems. In particular, we demonstrate that a NeRF representation of a scene can be used to train dense object descriptors. We use an optimized NeRF to extract dense correspondences between multiple views of an object, and then use these correspondences as training data for learning a view-invariant representation of the object. NeRF's usage of a density field allows us to reformulate the correspondence problem with a novel distribution-of-depths formulation, as opposed to the conventional approach of using a depth map. Dense correspondence models supervised with our method significantly outperform off-the-shelf learned descriptors by 106% (PCK@3px metric, more than doubling performance) and outperform our baseline supervised with multi-view stereo by 29%. Furthermore, we demonstrate the learned dense descriptors enable robots to perform accurate 6-degree of freedom (6-DoF) pick and place of thin and reflective objects.
Contrastive Feature Loss for Image Prediction
Nov 12, 2021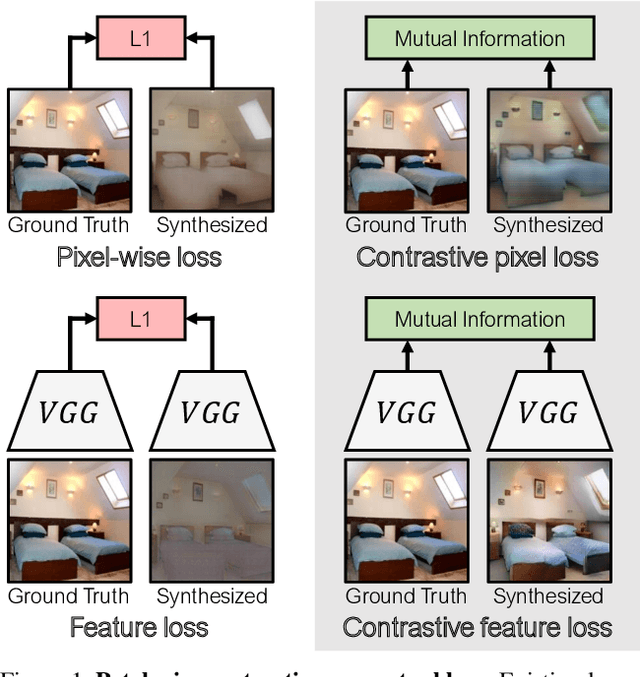
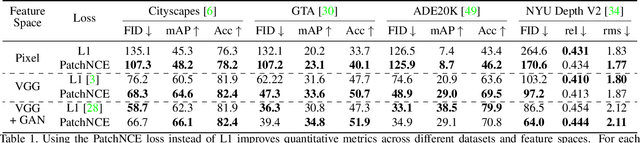
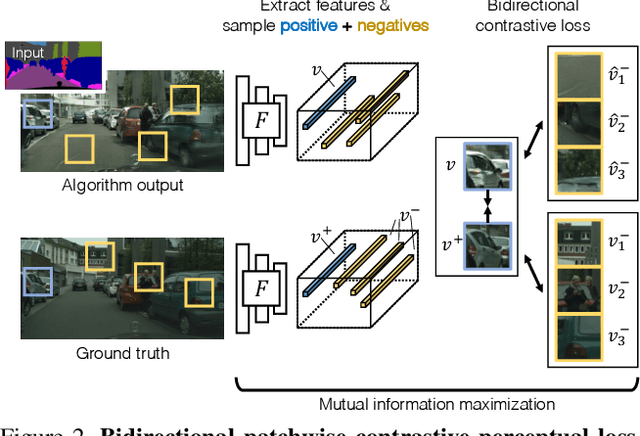
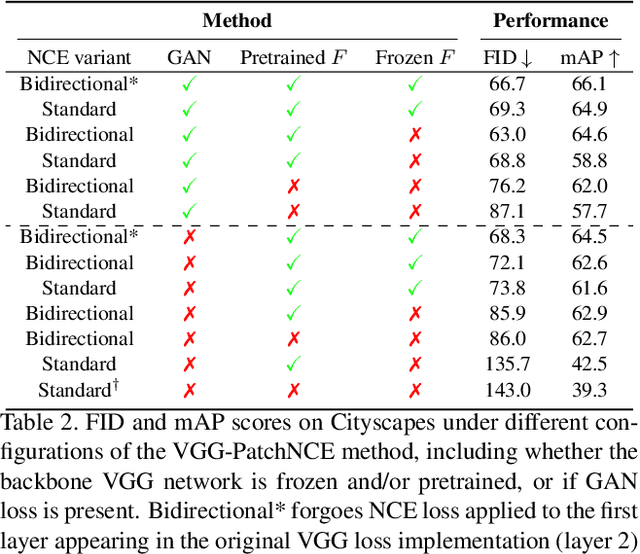
Training supervised image synthesis models requires a critic to compare two images: the ground truth to the result. Yet, this basic functionality remains an open problem. A popular line of approaches uses the L1 (mean absolute error) loss, either in the pixel or the feature space of pretrained deep networks. However, we observe that these losses tend to produce overly blurry and grey images, and other techniques such as GANs need to be employed to fight these artifacts. In this work, we introduce an information theory based approach to measuring similarity between two images. We argue that a good reconstruction should have high mutual information with the ground truth. This view enables learning a lightweight critic to "calibrate" a feature space in a contrastive manner, such that reconstructions of corresponding spatial patches are brought together, while other patches are repulsed. We show that our formulation immediately boosts the perceptual realism of output images when used as a drop-in replacement for the L1 loss, with or without an additional GAN loss.
Learning to Ground Multi-Agent Communication with Autoencoders
Oct 28, 2021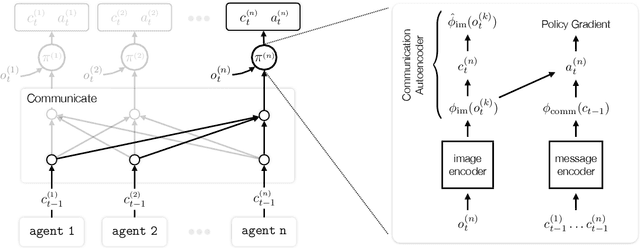
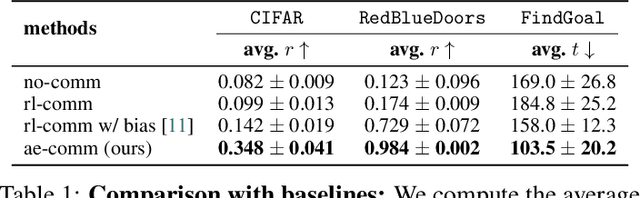
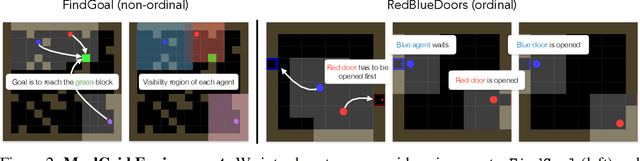

Communication requires having a common language, a lingua franca, between agents. This language could emerge via a consensus process, but it may require many generations of trial and error. Alternatively, the lingua franca can be given by the environment, where agents ground their language in representations of the observed world. We demonstrate a simple way to ground language in learned representations, which facilitates decentralized multi-agent communication and coordination. We find that a standard representation learning algorithm -- autoencoding -- is sufficient for arriving at a grounded common language. When agents broadcast these representations, they learn to understand and respond to each other's utterances and achieve surprisingly strong task performance across a variety of multi-agent communication environments.