 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeRF-VPT: Learning Novel View Representations with Neural Radiance Fields via View Prompt Tuning
Mar 02, 2024



Neural Radiance Fields (NeRF) have garnered remarkable success in novel view synthesis. Nonetheless, the task of generating high-quality images for novel views persists as a critical challenge. While the existing efforts have exhibited commendable progress, capturing intricate details, enhancing textures, and achieving superior Peak Signal-to-Noise Ratio (PSNR) metrics warrant further focused attention and advancement. In this work, we propose NeRF-VPT, an innovative method for novel view synthesis to address these challenges. Our proposed NeRF-VPT employs a cascading view prompt tuning paradigm, wherein RGB information gained from preceding rendering outcomes serves as instructive visual prompts for subsequent rendering stages, with the aspiration that the prior knowledge embedded in the prompts can facilitate the gradual enhancement of rendered image quality. NeRF-VPT only requires sampling RGB data from previous stage renderings as priors at each training stage, without relying on extra guidance or complex techniques. Thus, our NeRF-VPT is plug-and-play and can be readily integrated into existing methods. By conducting comparative analyses of our NeRF-VPT against several NeRF-based approaches on demanding real-scene benchmarks, such as Realistic Synthetic 360, Real Forward-Facing, Replica dataset, and a user-captured dataset, we substantiate that our NeRF-VPT significantly elevates baseline performance and proficiently generates more high-quality novel view images than all the compared state-of-the-art methods. Furthermore, the cascading learning of NeRF-VPT introduces adaptability to scenarios with sparse inputs, resulting in a significant enhancement of accuracy for sparse-view novel view synthesis. The source code and dataset are available at \url{https://github.com/Freedomcls/NeRF-VPT}.
Placing Objects in Context via Inpainting for Out-of-distribution Segmentation
Feb 26, 2024When deploying a semantic segmentation model into the real world, it will inevitably be confronted with semantic classes unseen during training. Thus, to safely deploy such systems, it is crucial to accurately evaluate and improve their anomaly segmentation capabilities. However, acquiring and labelling semantic segmentation data is expensive and unanticipated conditions are long-tail and potentially hazardous. Indeed, existing anomaly segmentation datasets capture a limited number of anomalies, lack realism or have strong domain shifts. In this paper, we propose the Placing Objects in Context (POC) pipeline to realistically add any object into any image via diffusion models. POC can be used to easily extend any dataset with an arbitrary number of objects. In our experiments, we present different anomaly segmentation datasets based on POC-generated data and show that POC can improve the performance of recent state-of-the-art anomaly fine-tuning methods in several standardized benchmarks. POC is also effective to learn new classes. For example, we use it to edit Cityscapes samples by adding a subset of Pascal classes and show that models trained on such data achieve comparable performance to the Pascal-trained baseline. This corroborates the low sim-to-real gap of models trained on POC-generated images.
Prompting a Pretrained Transformer Can Be a Universal Approximator
Feb 22, 2024Despite the widespread adoption of prompting, prompt tuning and prefix-tuning of transformer models, our theoretical understanding of these fine-tuning methods remains limited. A key question is whether one can arbitrarily modify the behavior of pretrained model by prompting or prefix-tuning it. Formally, whether prompting and prefix-tuning a pretrained model can universally approximate sequence-to-sequence functions. This paper answers in the affirmative and demonstrates that much smaller pretrained models than previously thought can be universal approximators when prefixed. In fact, the attention mechanism is uniquely suited for universal approximation with prefix-tuning a single attention head being sufficient to approximate any continuous function. Moreover, any sequence-to-sequence function can be approximated by prefixing a transformer with depth linear in the sequence length. Beyond these density-type results, we also offer Jackson-type bounds on the length of the prefix needed to approximate a function to a desired precision.
Self-consistent Validation for Machine Learning Electronic Structure
Feb 15, 2024Machine learning has emerged as a significant approach to efficiently tackle electronic structure problems. Despite its potential, there is less guarantee for the model to generalize to unseen data that hinders its application in real-world scenarios. To address this issue, a technique has been proposed to estimate the accuracy of the predictions. This method integrates machine learning with self-consistent field methods to achieve both low validation cost and interpret-ability. This, in turn, enables exploration of the model's ability with active learning and instills confidence in its integration into real-world studies.
RanDumb: A Simple Approach that Questions the Efficacy of Continual Representation Learning
Feb 13, 2024



We propose RanDumb to examine the efficacy of continual representation learning. RanDumb embeds raw pixels using a fixed random transform which approximates an RBF-Kernel, initialized before seeing any data, and learns a simple linear classifier on top. We present a surprising and consistent finding: RanDumb significantly outperforms the continually learned representations using deep networks across numerous continual learning benchmarks, demonstrating the poor performance of representation learning in these scenarios. RanDumb stores no exemplars and performs a single pass over the data, processing one sample at a time. It complements GDumb, operating in a low-exemplar regime where GDumb has especially poor performance. We reach the same consistent conclusions when RanDumb is extended to scenarios with pretrained models replacing the random transform with pretrained feature extractor. Our investigation is both surprising and alarming as it questions our understanding of how to effectively design and train models that require efficient continual representation learning, and necessitates a principled reinvestigation of the widely explored problem formulation itself. Our code is available at https://github.com/drimpossible/RanDumb.
Revealing Decurve Flows for Generalized Graph Propagation
Feb 13, 2024

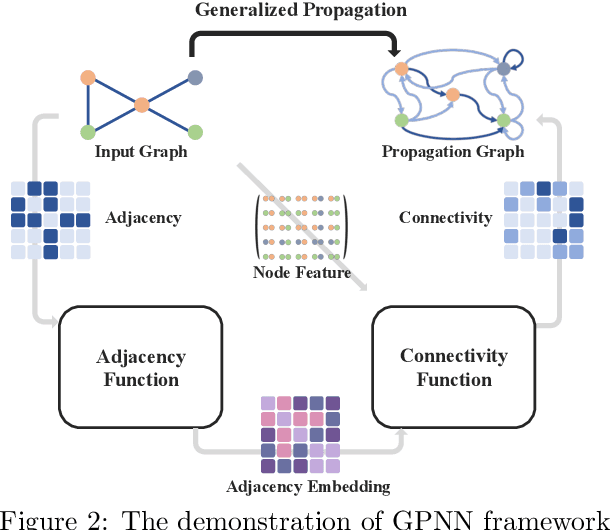

This study addresses the limitations of the traditional analysis of message-passing, central to graph learning, by defining {\em \textbf{generalized propagation}} with directed and weighted graphs. The significance manifest in two ways. \textbf{Firstly}, we propose {\em Generalized Propagation Neural Networks} (\textbf{GPNNs}), a framework that unifies most propagation-based graph neural networks. By generating directed-weighted propagation graphs with adjacency function and connectivity function, GPNNs offer enhanced insights into attention mechanisms across various graph models. We delve into the trade-offs within the design space with empirical experiments and emphasize the crucial role of the adjacency function for model expressivity via theoretical analysis. \textbf{Secondly}, we propose the {\em Continuous Unified Ricci Curvature} (\textbf{CURC}), an extension of celebrated {\em Ollivier-Ricci Curvature} for directed and weighted graphs. Theoretically, we demonstrate that CURC possesses continuity, scale invariance, and a lower bound connection with the Dirichlet isoperimetric constant validating bottleneck analysis for GPNNs. We include a preliminary exploration of learned propagation patterns in datasets, a first in the field. We observe an intriguing ``{\em \textbf{decurve flow}}'' - a curvature reduction during training for models with learnable propagation, revealing the evolution of propagation over time and a deeper connection to over-smoothing and bottleneck trade-off.
Secret Collusion Among Generative AI Agents
Feb 12, 2024



Recent capability increases in large language models (LLMs) open up applications in which teams of communicating generative AI agents solve joint tasks. This poses privacy and security challenges concerning the unauthorised sharing of information, or other unwanted forms of agent coordination. Modern steganographic techniques could render such dynamics hard to detect. In this paper, we comprehensively formalise the problem of secret collusion in systems of generative AI agents by drawing on relevant concepts from both the AI and security literature. We study incentives for the use of steganography, and propose a variety of mitigation measures. Our investigations result in a model evaluation framework that systematically tests capabilities required for various forms of secret collusion. We provide extensive empirical results across a range of contemporary LLMs. While the steganographic capabilities of current models remain limited, GPT-4 displays a capability jump suggesting the need for continuous monitoring of steganographic frontier model capabilities. We conclude by laying out a comprehensive research program to mitigate future risks of collusion between generative AI models.
From Categories to Classifier: Name-Only Continual Learning by Exploring the Web
Nov 19, 2023Continual Learning (CL) often relies on the availability of extensive annotated datasets, an assumption that is unrealistically time-consuming and costly in practice. We explore a novel paradigm termed name-only continual learning where time and cost constraints prohibit manual annotation. In this scenario, learners adapt to new category shifts using only category names without the luxury of annotated training data. Our proposed solution leverages the expansive and ever-evolving internet to query and download uncurated webly-supervised data for image classification. We investigate the reliability of our web data and find them comparable, and in some cases superior, to manually annotated datasets. Additionally, we show that by harnessing the web, we can create support sets that surpass state-of-the-art name-only classification that create support sets using generative models or image retrieval from LAION-5B, achieving up to 25% boost in accuracy. When applied across varied continual learning contexts, our method consistently exhibits a small performance gap in comparison to models trained on manually annotated datasets. We present EvoTrends, a class-incremental dataset made from the web to capture real-world trends, created in just minutes. Overall, this paper underscores the potential of using uncurated webly-supervised data to mitigate the challenges associated with manual data labeling in continual learning.
When Do Prompting and Prefix-Tuning Work? A Theory of Capabilities and Limitations
Oct 30, 2023Context-based fine-tuning methods, including prompting, in-context learning, soft prompting (also known as prompt tuning), and prefix-tuning, have gained popularity due to their ability to often match the performance of full fine-tuning with a fraction of the parameters. Despite their empirical successes, there is little theoretical understanding of how these techniques influence the internal computation of the model and their expressiveness limitations. We show that despite the continuous embedding space being more expressive than the discrete token space, soft-prompting and prefix-tuning are strictly less expressive than full fine-tuning, even with the same number of learnable parameters. Concretely, context-based fine-tuning cannot change the relative attention pattern over the content and can only bias the outputs of an attention layer in a fixed direction. This suggests that while techniques like prompting, in-context learning, soft prompting, and prefix-tuning can effectively elicit skills present in the pretrained model, they cannot learn novel tasks that require new attention patterns.
Revisiting Evaluation Metrics for Semantic Segmentation: Optimization and Evaluation of Fine-grained Intersection over Union
Oct 30, 2023



Semantic segmentation datasets often exhibit two types of imbalance: \textit{class imbalance}, where some classes appear more frequently than others and \textit{size imbalance}, where some objects occupy more pixels than others. This causes traditional evaluation metrics to be biased towards \textit{majority classes} (e.g. overall pixel-wise accuracy) and \textit{large objects} (e.g. mean pixel-wise accuracy and per-dataset mean intersection over union). To address these shortcomings, we propose the use of fine-grained mIoUs along with corresponding worst-case metrics, thereby offering a more holistic evaluation of segmentation techniques. These fine-grained metrics offer less bias towards large objects, richer statistical information, and valuable insights into model and dataset auditing. Furthermore, we undertake an extensive benchmark study, where we train and evaluate 15 modern neural networks with the proposed metrics on 12 diverse natural and aerial segmentation datasets. Our benchmark study highlights the necessity of not basing evaluations on a single metric and confirms that fine-grained mIoUs reduce the bias towards large objects. Moreover, we identify the crucial role played by architecture designs and loss functions, which lead to best practices in optimizing fine-grained metrics. The code is available at \href{https://github.com/zifuwanggg/JDTLosses}{https://github.com/zifuwanggg/JDTLosses}.