 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBucketed Ranking-based Losses for Efficient Training of Object Detectors
Jul 19, 2024Ranking-based loss functions, such as Average Precision Loss and Rank&Sort Loss, outperform widely used score-based losses in object detection. These loss functions better align with the evaluation criteria, have fewer hyperparameters, and offer robustness against the imbalance between positive and negative classes. However, they require pairwise comparisons among $P$ positive and $N$ negative predictions, introducing a time complexity of $\mathcal{O}(PN)$, which is prohibitive since $N$ is often large (e.g., $10^8$ in ATSS). Despite their advantages, the widespread adoption of ranking-based losses has been hindered by their high time and space complexities. In this paper, we focus on improving the efficiency of ranking-based loss functions. To this end, we propose Bucketed Ranking-based Losses which group negative predictions into $B$ buckets ($B \ll N$) in order to reduce the number of pairwise comparisons so that time complexity can be reduced. Our method enhances the time complexity, reducing it to $\mathcal{O}(\max (N \log(N), P^2))$. To validate our method and show its generality, we conducted experiments on 2 different tasks, 3 different datasets, 7 different detectors. We show that Bucketed Ranking-based (BR) Losses yield the same accuracy with the unbucketed versions and provide $2\times$ faster training on average. We also train, for the first time, transformer-based object detectors using ranking-based losses, thanks to the efficiency of our BR. When we train CoDETR, a state-of-the-art transformer-based object detector, using our BR Loss, we consistently outperform its original results over several different backbones. Code is available at https://github.com/blisgard/BucketedRankingBasedLosses
What Makes and Breaks Safety Fine-tuning? A Mechanistic Study
Jul 16, 2024



Safety fine-tuning helps align Large Language Models (LLMs) with human preferences for their safe deployment. To better understand the underlying factors that make models safe via safety fine-tuning, we design a synthetic data generation framework that captures salient aspects of an unsafe input by modeling the interaction between the task the model is asked to perform (e.g., "design") versus the specific concepts the task is asked to be performed upon (e.g., a "cycle" vs. a "bomb"). Using this, we investigate three well-known safety fine-tuning methods -- supervised safety fine-tuning, direct preference optimization, and unlearning -- and provide significant evidence demonstrating that these methods minimally transform MLP weights to specifically align unsafe inputs into its weights' null space. This yields a clustering of inputs based on whether the model deems them safe or not. Correspondingly, when an adversarial input (e.g., a jailbreak) is provided, its activations are closer to safer samples, leading to the model processing such an input as if it were safe. We validate our findings, wherever possible, on real-world models -- specifically, Llama-2 7B and Llama-3 8B.
What Makes and Breaks Safety Fine-tuning? Mechanistic Study
Jul 14, 2024Safety fine-tuning helps align Large Language Models (LLMs) with human preferences for their safe deployment. To better understand the underlying factors that make models safe via safety fine-tuning, we design a synthetic data generation framework that captures salient aspects of an unsafe input by modeling the interaction between the task the model is asked to perform (e.g., ``design'') versus the specific concepts the task is asked to be performed upon (e.g., a ``cycle'' vs. a ``bomb''). Using this, we investigate three well-known safety fine-tuning methods -- supervised safety fine-tuning, direct preference optimization, and unlearning -- and provide significant evidence demonstrating that these methods minimally transform MLP weights to specifically align unsafe inputs into its weights' null space. This yields a clustering of inputs based on whether the model deems them safe or not. Correspondingly, when an adversarial input (e.g., a jailbreak) is provided, its activations are closer to safer samples, leading to the model processing such an input as if it were safe. We validate our findings, wherever possible, on real-world models -- specifically, Llama-2 7B and Llama-3 8B.
On Calibration of Object Detectors: Pitfalls, Evaluation and Baselines
May 30, 2024Reliable usage of object detectors require them to be calibrated -- a crucial problem that requires careful attention. Recent approaches towards this involve (1) designing new loss functions to obtain calibrated detectors by training them from scratch, and (2) post-hoc Temperature Scaling (TS) that learns to scale the likelihood of a trained detector to output calibrated predictions. These approaches are then evaluated based on a combination of Detection Expected Calibration Error (D-ECE) and Average Precision. In this work, via extensive analysis and insights, we highlight that these recent evaluation frameworks, evaluation metrics, and the use of TS have notable drawbacks leading to incorrect conclusions. As a step towards fixing these issues, we propose a principled evaluation framework to jointly measure calibration and accuracy of object detectors. We also tailor efficient and easy-to-use post-hoc calibration approaches such as Platt Scaling and Isotonic Regression specifically for object detection task. Contrary to the common notion, our experiments show that once designed and evaluated properly, post-hoc calibrators, which are extremely cheap to build and use, are much more powerful and effective than the recent train-time calibration methods. To illustrate, D-DETR with our post-hoc Isotonic Regression calibrator outperforms the recent train-time state-of-the-art calibration method Cal-DETR by more than 7 D-ECE on the COCO dataset. Additionally, we propose improved versions of the recently proposed Localization-aware ECE and show the efficacy of our method on these metrics as well. Code is available at: https://github.com/fiveai/detection_calibration.
Segment, Select, Correct: A Framework for Weakly-Supervised Referring Segmentation
Oct 23, 2023Referring Image Segmentation (RIS) - the problem of identifying objects in images through natural language sentences - is a challenging task currently mostly solved through supervised learning. However, while collecting referred annotation masks is a time-consuming process, the few existing weakly-supervised and zero-shot approaches fall significantly short in performance compared to fully-supervised learning ones. To bridge the performance gap without mask annotations, we propose a novel weakly-supervised framework that tackles RIS by decomposing it into three steps: obtaining instance masks for the object mentioned in the referencing instruction (segment), using zero-shot learning to select a potentially correct mask for the given instruction (select), and bootstrapping a model which allows for fixing the mistakes of zero-shot selection (correct). In our experiments, using only the first two steps (zero-shot segment and select) outperforms other zero-shot baselines by as much as 19%, while our full method improves upon this much stronger baseline and sets the new state-of-the-art for weakly-supervised RIS, reducing the gap between the weakly-supervised and fully-supervised methods in some cases from around 33% to as little as 14%. Code is available at https://github.com/fgirbal/segment-select-correct.
MoCaE: Mixture of Calibrated Experts Significantly Improves Object Detection
Sep 27, 2023



We propose an extremely simple and highly effective approach to faithfully combine different object detectors to obtain a Mixture of Experts (MoE) that has a superior accuracy to the individual experts in the mixture. We find that naively combining these experts in a similar way to the well-known Deep Ensembles (DEs), does not result in an effective MoE. We identify the incompatibility between the confidence score distribution of different detectors to be the primary reason for such failure cases. Therefore, to construct the MoE, our proposal is to first calibrate each individual detector against a target calibration function. Then, filter and refine all the predictions from different detectors in the mixture. We term this approach as MoCaE and demonstrate its effectiveness through extensive experiments on object detection, instance segmentation and rotated object detection tasks. Specifically, MoCaE improves (i) three strong object detectors on COCO test-dev by $2.4$ $\mathrm{AP}$ by reaching $59.0$ $\mathrm{AP}$; (ii) instance segmentation methods on the challenging long-tailed LVIS dataset by $2.3$ $\mathrm{AP}$; and (iii) all existing rotated object detectors by reaching $82.62$ $\mathrm{AP_{50}}$ on DOTA dataset, establishing a new state-of-the-art (SOTA). Code will be made public.
Towards Building Self-Aware Object Detectors via Reliable Uncertainty Quantification and Calibration
Jul 03, 2023



The current approach for testing the robustness of object detectors suffers from serious deficiencies such as improper methods of performing out-of-distribution detection and using calibration metrics which do not consider both localisation and classification quality. In this work, we address these issues, and introduce the Self-Aware Object Detection (SAOD) task, a unified testing framework which respects and adheres to the challenges that object detectors face in safety-critical environments such as autonomous driving. Specifically, the SAOD task requires an object detector to be: robust to domain shift; obtain reliable uncertainty estimates for the entire scene; and provide calibrated confidence scores for the detections. We extensively use our framework, which introduces novel metrics and large scale test datasets, to test numerous object detectors in two different use-cases, allowing us to highlight critical insights into their robustness performance. Finally, we introduce a simple baseline for the SAOD task, enabling researchers to benchmark future proposed methods and move towards robust object detectors which are fit for purpose. Code is available at https://github.com/fiveai/saod
Correlation Loss: Enforcing Correlation between Classification and Localization
Jan 03, 2023



Object detectors are conventionally trained by a weighted sum of classification and localization losses. Recent studies (e.g., predicting IoU with an auxiliary head, Generalized Focal Loss, Rank & Sort Loss) have shown that forcing these two loss terms to interact with each other in non-conventional ways creates a useful inductive bias and improves performance. Inspired by these works, we focus on the correlation between classification and localization and make two main contributions: (i) We provide an analysis about the effects of correlation between classification and localization tasks in object detectors. We identify why correlation affects the performance of various NMS-based and NMS-free detectors, and we devise measures to evaluate the effect of correlation and use them to analyze common detectors. (ii) Motivated by our observations, e.g., that NMS-free detectors can also benefit from correlation, we propose Correlation Loss, a novel plug-in loss function that improves the performance of various object detectors by directly optimizing correlation coefficients: E.g., Correlation Loss on Sparse R-CNN, an NMS-free method, yields 1.6 AP gain on COCO and 1.8 AP gain on Cityscapes dataset. Our best model on Sparse R-CNN reaches 51.0 AP without test-time augmentation on COCO test-dev, reaching state-of-the-art. Code is available at https://github.com/fehmikahraman/CorrLoss
Mask-aware IoU for Anchor Assignment in Real-time Instance Segmentation
Oct 19, 2021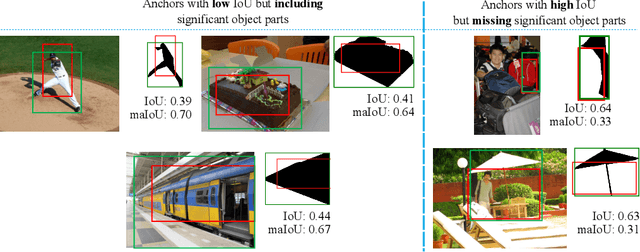
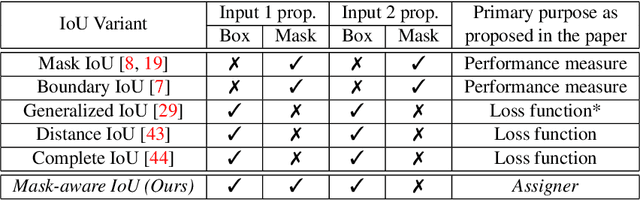
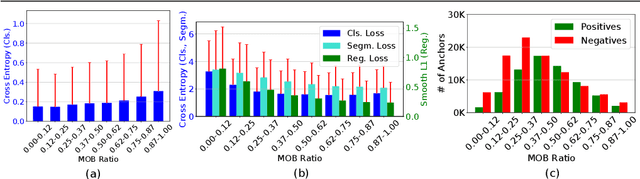
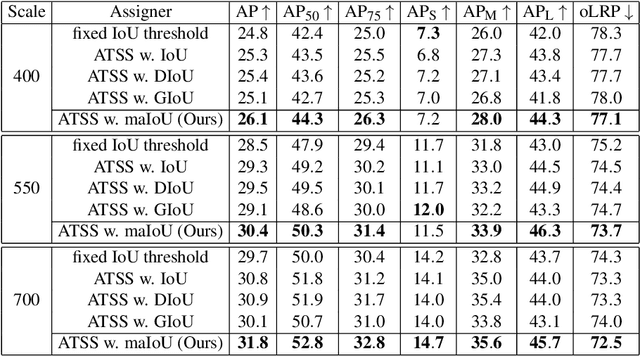
This paper presents Mask-aware Intersection-over-Union (maIoU) for assigning anchor boxes as positives and negatives during training of instance segmentation methods. Unlike conventional IoU or its variants, which only considers the proximity of two boxes; maIoU consistently measures the proximity of an anchor box with not only a ground truth box but also its associated ground truth mask. Thus, additionally considering the mask, which, in fact, represents the shape of the object, maIoU enables a more accurate supervision during training. We present the effectiveness of maIoU on a state-of-the-art (SOTA) assigner, ATSS, by replacing IoU operation by our maIoU and training YOLACT, a SOTA real-time instance segmentation method. Using ATSS with maIoU consistently outperforms (i) ATSS with IoU by $\sim 1$ mask AP, (ii) baseline YOLACT with fixed IoU threshold assigner by $\sim 2$ mask AP over different image sizes and (iii) decreases the inference time by $25 \%$ owing to using less anchors. Then, exploiting this efficiency, we devise maYOLACT, a faster and $+6$ AP more accurate detector than YOLACT. Our best model achieves $37.7$ mask AP at $25$ fps on COCO test-dev establishing a new state-of-the-art for real-time instance segmentation. Code is available at https://github.com/kemaloksuz/Mask-aware-IoU
Rank & Sort Loss for Object Detection and Instance Segmentation
Jul 24, 2021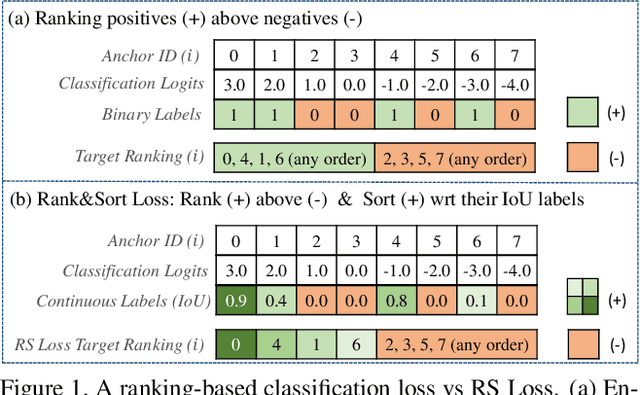
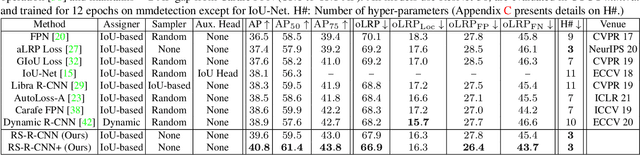
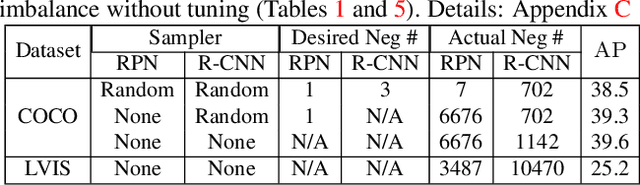
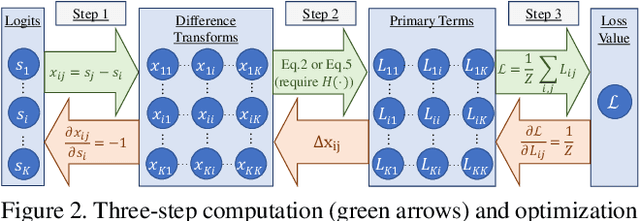
We propose Rank & Sort (RS) Loss, as a ranking-based loss function to train deep object detection and instance segmentation methods (i.e. visual detectors). RS Loss supervises the classifier, a sub-network of these methods, to rank each positive above all negatives as well as to sort positives among themselves with respect to (wrt.) their continuous localisation qualities (e.g. Intersection-over-Union - IoU). To tackle the non-differentiable nature of ranking and sorting, we reformulate the incorporation of error-driven update with backpropagation as Identity Update, which enables us to model our novel sorting error among positives. With RS Loss, we significantly simplify training: (i) Thanks to our sorting objective, the positives are prioritized by the classifier without an additional auxiliary head (e.g. for centerness, IoU, mask-IoU), (ii) due to its ranking-based nature, RS Loss is robust to class imbalance, and thus, no sampling heuristic is required, and (iii) we address the multi-task nature of visual detectors using tuning-free task-balancing coefficients. Using RS Loss, we train seven diverse visual detectors only by tuning the learning rate, and show that it consistently outperforms baselines: e.g. our RS Loss improves (i) Faster R-CNN by ~ 3 box AP and aLRP Loss (ranking-based baseline) by ~ 2 box AP on COCO dataset, (ii) Mask R-CNN with repeat factor sampling (RFS) by 3.5 mask AP (~ 7 AP for rare classes) on LVIS dataset; and also outperforms all counterparts. Code available at https://github.com/kemaloksuz/RankSortLoss