 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHolistically-Attracted Wireframe Parsing
Mar 03, 2020
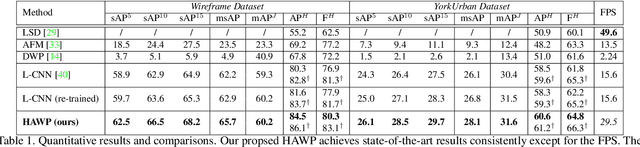
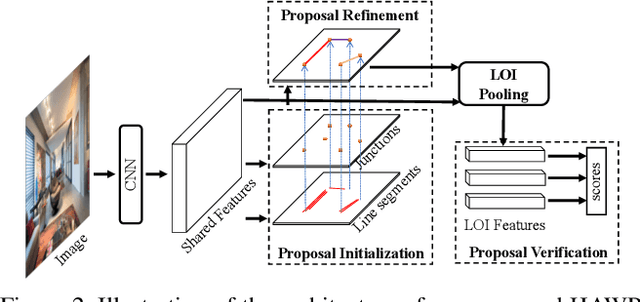
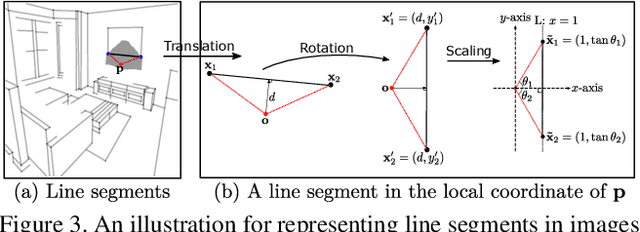
This paper presents a fast and parsimonious parsing method to accurately and robustly detect a vectorized wireframe in an input image with a single forward pass. The proposed method is end-to-end trainable, consisting of three components: (i) line segment and junction proposal generation, (ii) line segment and junction matching, and (iii) line segment and junction verification. For computing line segment proposals, a novel exact dual representation is proposed which exploits a parsimonious geometric reparameterization for line segments and forms a holistic 4-dimensional attraction field map for an input image. Junctions can be treated as the "basins" in the attraction field. The proposed method is thus called Holistically-Attracted Wireframe Parser (HAWP). In experiments, the proposed method is tested on two benchmarks, the Wireframe dataset, and the YorkUrban dataset. On both benchmarks, it obtains state-of-the-art performance in terms of accuracy and efficiency. For example, on the Wireframe dataset, compared to the previous state-of-the-art method L-CNN, it improves the challenging mean structural average precision (msAP) by a large margin ($2.8\%$ absolute improvements) and achieves 29.5 FPS on single GPU ($89\%$ relative improvement). A systematic ablation study is performed to further justify the proposed method.
Lagrangian Decomposition for Neural Network Verification
Feb 24, 2020

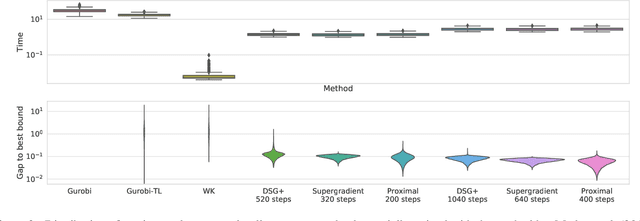

A fundamental component of neural network verification is the computation of bounds on the values their outputs can take. Previous methods have either used off-the-shelf solvers, discarding the problem structure, or relaxed the problem even further, making the bounds unnecessarily loose. We propose a novel approach based on Lagrangian Decomposition. Our formulation admits an efficient supergradient ascent algorithm, as well as an improved proximal algorithm. Both the algorithms offer three advantages: (i) they yield bounds that are provably at least as tight as previous dual algorithms relying on Lagrangian relaxations; (ii) they are based on operations analogous to forward/backward pass of neural networks layers and are therefore easily parallelizable, amenable to GPU implementation and able to take advantage of the convolutional structure of problems; and (iii) they allow for anytime stopping while still providing valid bounds. Empirically, we show that we obtain bounds comparable with off-the-shelf solvers in a fraction of their running time, and obtain tighter bounds in the same time as previous dual algorithms. This results in an overall speed-up when employing the bounds for formal verification.
Calibrating Deep Neural Networks using Focal Loss
Feb 21, 2020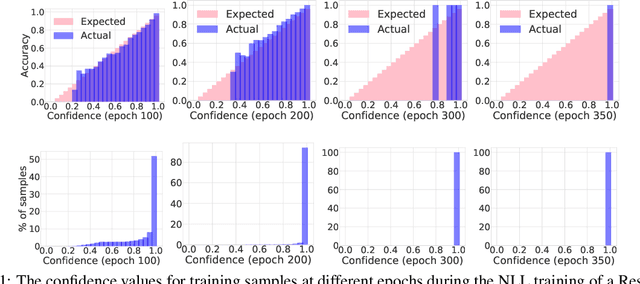
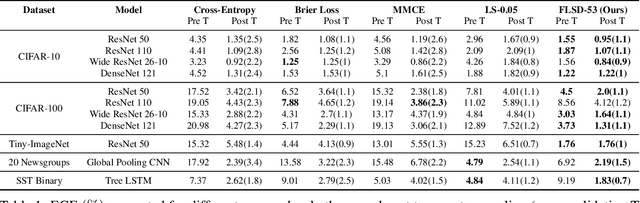
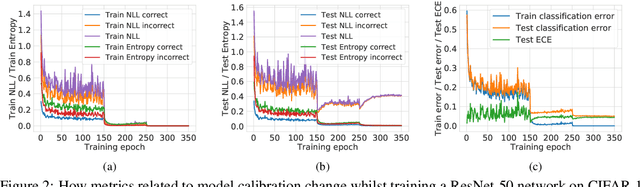
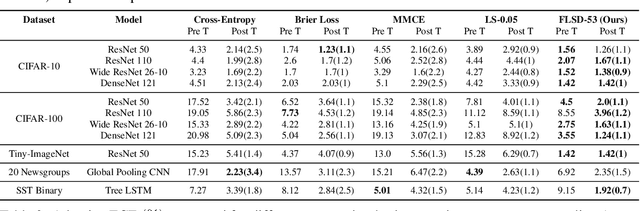
Miscalibration -- a mismatch between a model's confidence and its correctness -- of Deep Neural Networks (DNNs) makes their predictions hard to rely on. Ideally, we want networks to be accurate, calibrated and confident. We show that, as opposed to the standard cross-entropy loss, focal loss (Lin et al., 2017) allows us to learn models that are already very well calibrated. When combined with temperature scaling, whilst preserving accuracy, it yields state-of-the-art calibrated models. We provide a thorough analysis of the factors causing miscalibration, and use the insights we glean from this to justify the empirically excellent performance of focal loss. To facilitate the use of focal loss in practice, we also provide a principled approach to automatically select the hyperparameter involved in the loss function. We perform extensive experiments on a variety of computer vision and NLP datasets, and with a wide variety of network architectures, and show that our approach achieves state-of-the-art accuracy and calibration in almost all cases.
Image-to-Image Translation with Text Guidance
Feb 12, 2020
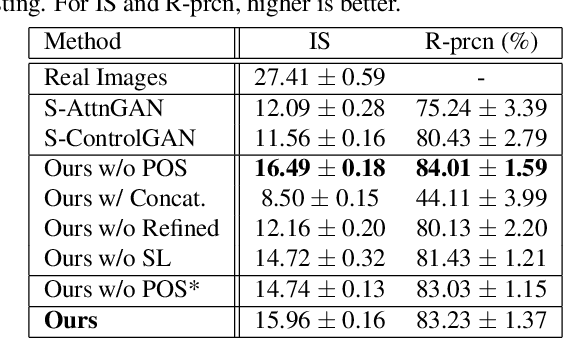
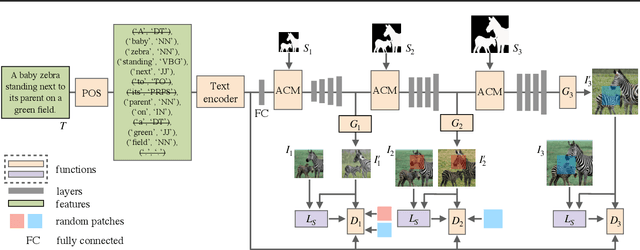

The goal of this paper is to embed controllable factors, i.e., natural language descriptions, into image-to-image translation with generative adversarial networks, which allows text descriptions to determine the visual attributes of synthetic images. We propose four key components: (1) the implementation of part-of-speech tagging to filter out non-semantic words in the given description, (2) the adoption of an affine combination module to effectively fuse different modality text and image features, (3) a novel refined multi-stage architecture to strengthen the differential ability of discriminators and the rectification ability of generators, and (4) a new structure loss to further improve discriminators to better distinguish real and synthetic images. Extensive experiments on the COCO dataset demonstrate that our method has a superior performance on both visual realism and semantic consistency with given descriptions.
Multi-Channel Attention Selection GANs for Guided Image-to-Image Translation
Feb 03, 2020

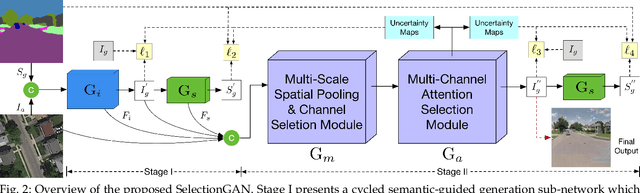
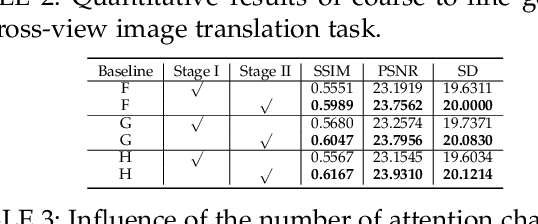
We propose a novel model named Multi-Channel Attention Selection Generative Adversarial Network (SelectionGAN) for guided image-to-image translation, where we translate an input image into another while respecting an external semantic guidance. The proposed SelectionGAN explicitly utilizes the semantic guidance information and consists of two stages. In the first stage, the input image and the conditional semantic guidance are fed into a cycled semantic-guided generation network to produce initial coarse results. In the second stage, we refine the initial results by using the proposed multi-scale spatial pooling \& channel selection module and the multi-channel attention selection module. Moreover, uncertainty maps automatically learned from attention maps are used to guide the pixel loss for better network optimization. Exhaustive experiments on four challenging guided image-to-image translation tasks (face, hand, body and street view) demonstrate that our SelectionGAN is able to generate significantly better results than the state-of-the-art methods. Meanwhile, the proposed framework and modules are unified solutions and can be applied to solve other generation tasks, such as semantic image synthesis. The code is available at https://github.com/Ha0Tang/SelectionGAN.
Unifying Training and Inference for Panoptic Segmentation
Jan 14, 2020
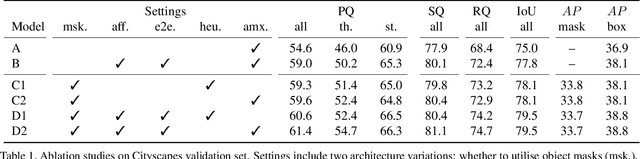
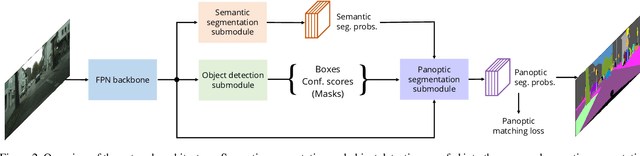
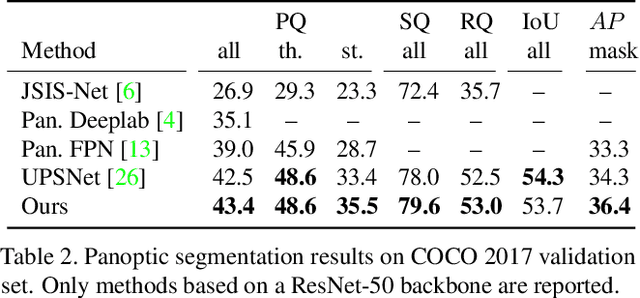
We present an end-to-end network to bridge the gap between training and inference pipeline for panoptic segmentation, a task that seeks to partition an image into semantic regions for "stuff" and object instances for "things". In contrast to recent works, our network exploits a parametrised, yet lightweight panoptic segmentation submodule, powered by an end-to-end learnt dense instance affinity, to capture the probability that any pair of pixels belong to the same instance. This panoptic submodule gives rise to a novel propagation mechanism for panoptic logits and enables the network to output a coherent panoptic segmentation map for both "stuff" and "thing" classes, without any post-processing. Reaping the benefits of end-to-end training, our full system sets new records on the popular street scene dataset, Cityscapes, achieving 61.4 PQ with a ResNet-50 backbone using only the fine annotations. On the challenging COCO dataset, our ResNet-50-based network also delivers state-of-the-art accuracy of 43.4 PQ. Moreover, our network flexibly works with and without object mask cues, performing competitively under both settings, which is of interest for applications with computation budgets.
Rethinking Class Relations: Absolute-relative Few-shot Learning
Jan 12, 2020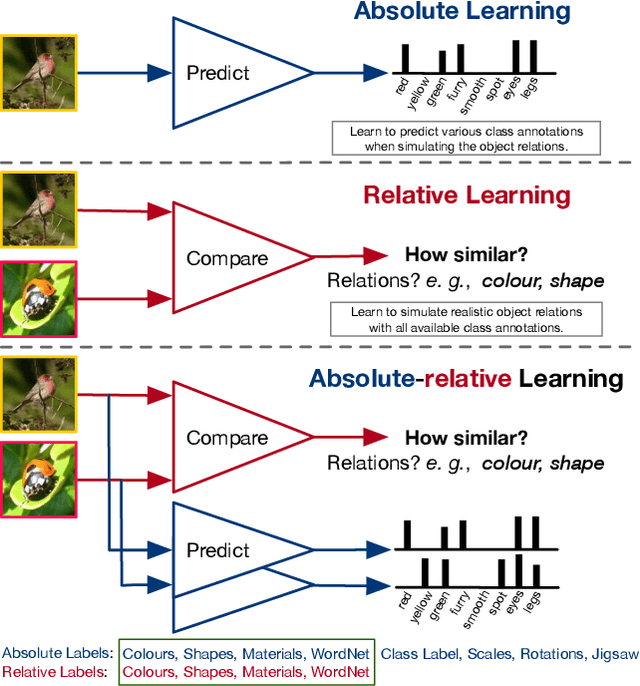
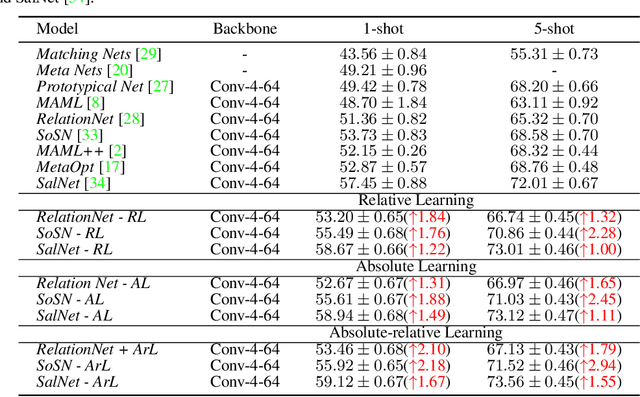
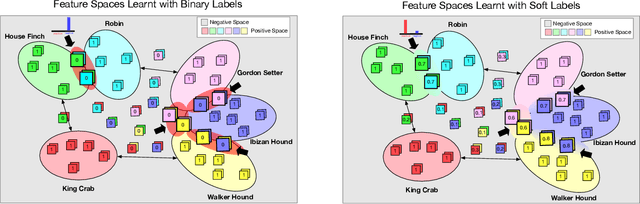
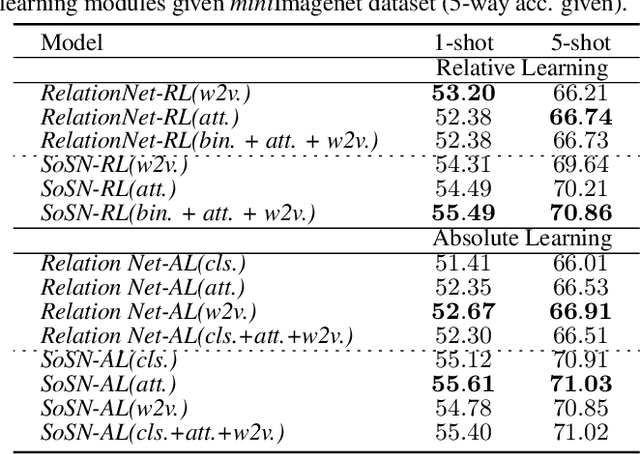
The majority of existing few-shot learning describe image relations with {0,1} binary labels. However, such binary relations are insufficient to teach the network complicated real-world relations, due to the lack of decision smoothness. Furthermore, current few-shot learning models capture only the similarity via relation labels, but they are not exposed to class concepts associated with objects, which is likely detrimental to the classification performance due to underutilization of the available class labels. To paraphrase, while children learn the concept of tiger from a few of examples with ease, and while they learn from comparisons of tiger to other animals, they are also taught the actual concept names. Thus, we hypothesize that in fact both similarity and class concept learning must be occurring simultaneously. With these observations at hand, we study the fundamental problem of simplistic class modeling in current few-shot learning, we rethink the relations between class concepts, and propose a novel absolute-relative learning paradigm to fully take advantage of label information to refine the image representations and correct the relation understanding. Our proposed absolute-relative learning paradigm improves the performance of several the state-of-the-art models on publicly available datasets.
Few-shot Action Recognition via Improved Attention with Self-supervision
Jan 12, 2020
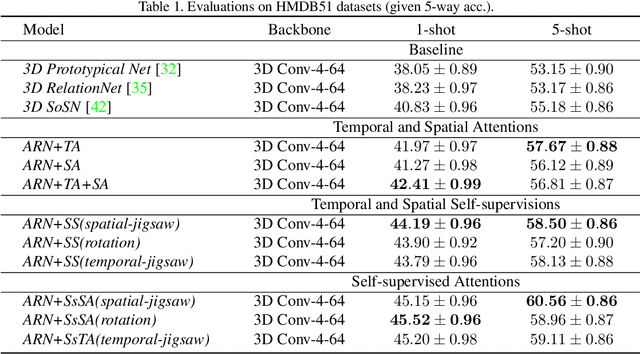
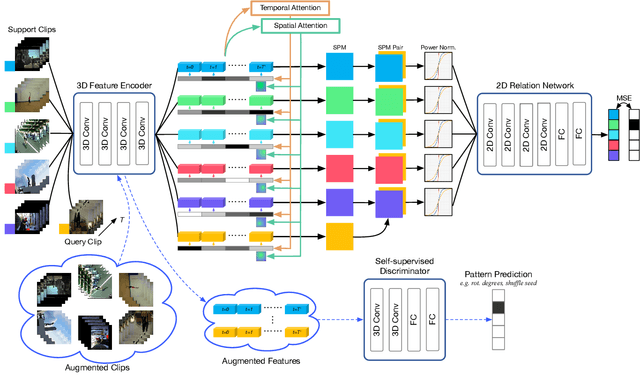
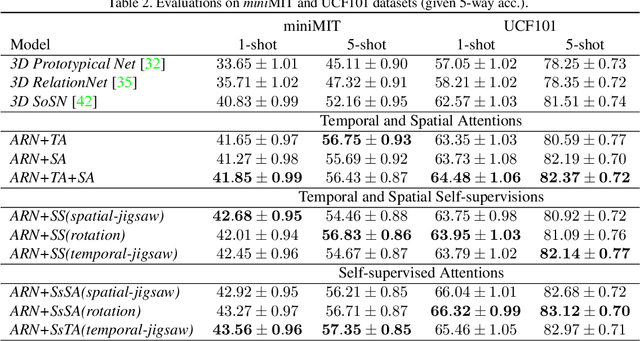
Most existing few-shot learning methods in computer vision focus on class recognition given a few of still images as the input. In contrast, this paper tackles a more challenging task of few-shot action-recognition from video clips. We propose a simple framework which is both flexible and easy to implement. Our approach exploits joint spatial and temporal attention mechanisms in conjunction with self-supervised representation learning on videos. This design encourages the model to discover and encode spatial and temporal attention hotspots important during the similarity learning between dynamic video sequences for which locations of discriminative patterns vary in the spatio-temporal sense. Our method compares favorably with several state-of-the-art baselines on HMDB51, miniMIT and UCF101 datasets, demonstrating its superior performance.
Few-shot Learning with Multi-scale Self-supervision
Jan 06, 2020
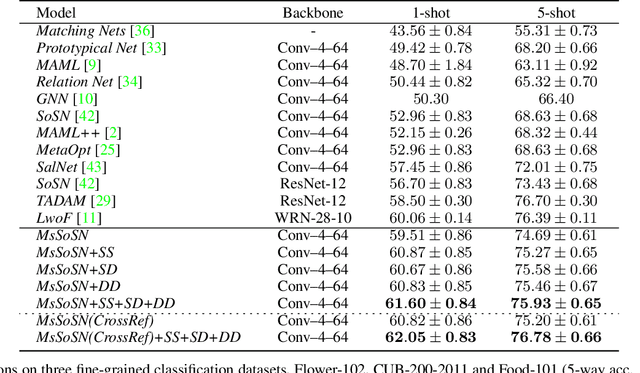
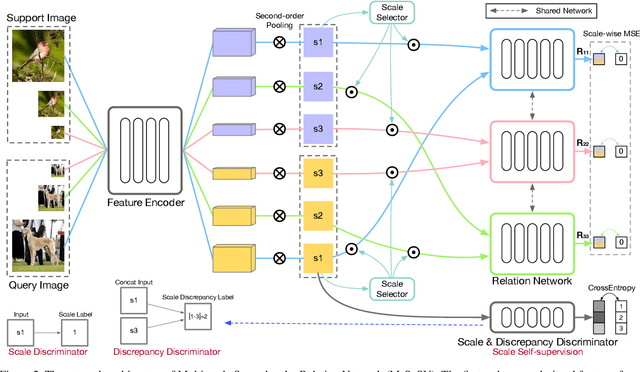
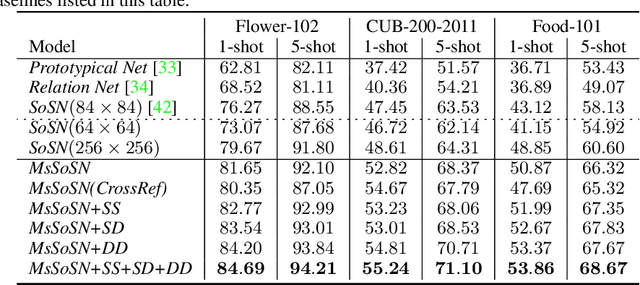
Learning concepts from the limited number of datapoints is a challenging task usually addressed by the so-called one- or few-shot learning. Recently, an application of second-order pooling in few-shot learning demonstrated its superior performance due to the aggregation step handling varying image resolutions without the need of modifying CNNs to fit to specific image sizes, yet capturing highly descriptive co-occurrences. However, using a single resolution per image (even if the resolution varies across a dataset) is suboptimal as the importance of image contents varies across the coarse-to-fine levels depending on the object and its class label e. g., generic objects and scenes rely on their global appearance while fine-grained objects rely more on their localized texture patterns. Multi-scale representations are popular in image deblurring, super-resolution and image recognition but they have not been investigated in few-shot learning due to its relational nature complicating the use of standard techniques. In this paper, we propose a novel multi-scale relation network based on the properties of second-order pooling to estimate image relations in few-shot setting. To optimize the model, we leverage a scale selector to re-weight scale-wise representations based on their second-order features. Furthermore, we propose to a apply self-supervised scale prediction. Specifically, we leverage an extra discriminator to predict the scale labels and the scale discrepancy between pairs of images. Our model achieves state-of-the-art results on standard few-shot learning datasets.
AttentionGAN: Unpaired Image-to-Image Translation using Attention-Guided Generative Adversarial Networks
Dec 28, 2019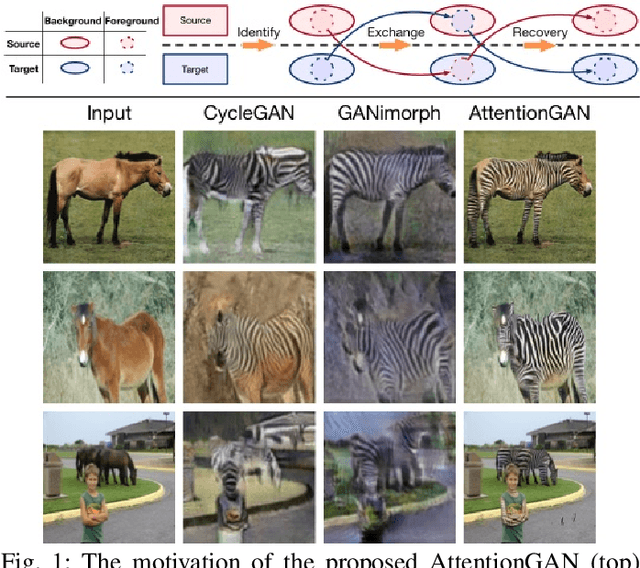



State-of-the-art methods in the unpaired image-to-image translation are capable of learning a mapping from a source domain to a target domain with unpaired image data. Though the existing methods have achieved promising results, they still produce unsatisfied artifacts, being able to convert low-level information while limited in transforming high-level semantics of input images. One possible reason is that generators do not have the ability to perceive the most discriminative semantic parts between the source and target domains, thus making the generated images low quality. In this paper, we propose a new Attention-Guided Generative Adversarial Networks (AttentionGAN) for the unpaired image-to-image translation task. AttentionGAN can identify the most discriminative semantic objects and minimize changes of unwanted parts for semantic manipulation problems without using extra data and models. The attention-guided generators in AttentionGAN are able to produce attention masks via a built-in attention mechanism, and then fuse the generation output with the attention masks to obtain high-quality target images. Accordingly, we also design a novel attention-guided discriminator which only considers attended regions. Extensive experiments are conducted on several generative tasks, demonstrating that the proposed model is effective to generate sharper and more realistic images compared with existing competitive models. The source code for the proposed AttentionGAN is available at https://github.com/Ha0Tang/AttentionGAN.