 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWordCraft: An Environment for Benchmarking Commonsense Agents
Jul 17, 2020
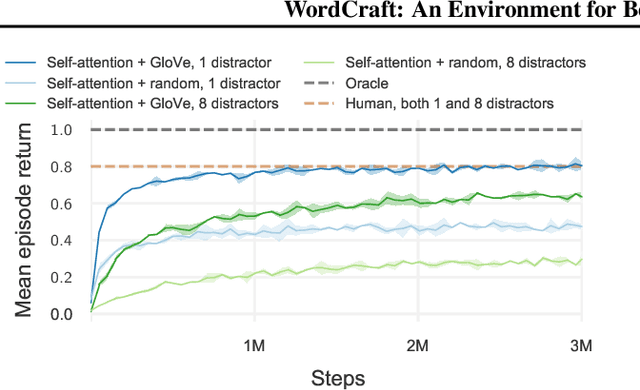

The ability to quickly solve a wide range of real-world tasks requires a commonsense understanding of the world. Yet, how to best extract such knowledge from natural language corpora and integrate it with reinforcement learning (RL) agents remains an open challenge. This is partly due to the lack of lightweight simulation environments that sufficiently reflect the semantics of the real world and provide knowledge sources grounded with respect to observations in an RL environment. To better enable research on agents making use of commonsense knowledge, we propose WordCraft, an RL environment based on Little Alchemy 2. This lightweight environment is fast to run and built upon entities and relations inspired by real-world semantics. We evaluate several representation learning methods on this new benchmark and propose a new method for integrating knowledge graphs with an RL agent.
Progressive Skeletonization: Trimming more fat from a network at initialization
Jul 14, 2020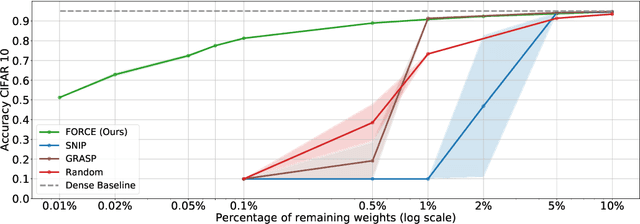
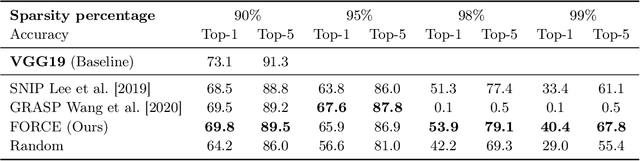
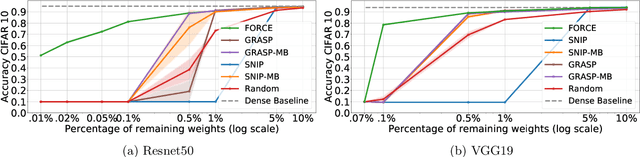
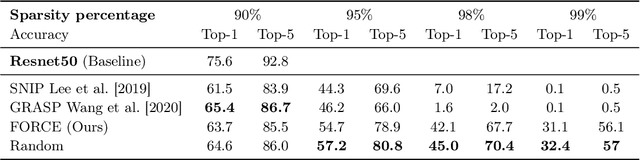
Recent studies have shown that skeletonization (pruning parameters) of networks at initialization provides all the practical benefits of sparsity both at inference and training time, while only marginally degrading their performance. However, we observe that beyond a certain level of sparsity (approx 95%), these approaches fail to preserve the network performance, and to our surprise, in many cases perform even worse than trivial random pruning. To this end, we propose to find a skeletonized network with maximum foresight connection sensitivity (FORCE). Intuitively, out of all possible sub-networks, we propose to find the one whose connections would have a maximum impact on the loss when perturbed. Our approximate solution to maximize the FORCE, progressively prunes connections of a given network at initialization. This allows parameters that were unimportant at earlier stages of skeletonization to become important at later stages. In many cases, our approach enables us to remove up to 99.9% parameters, while keeping networks trainable and providing significantly better performance than recent approaches. We demonstrate the effectiveness of our approach at various levels of sparsity (from medium to extreme) through extensive experiments and analysis. Code can be found in https://github.com/naver/force.
How benign is benign overfitting?
Jul 08, 2020
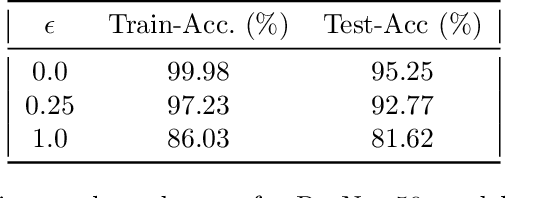
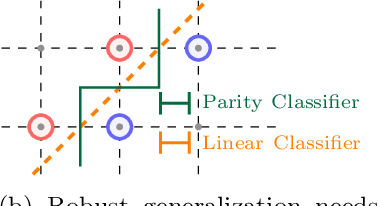
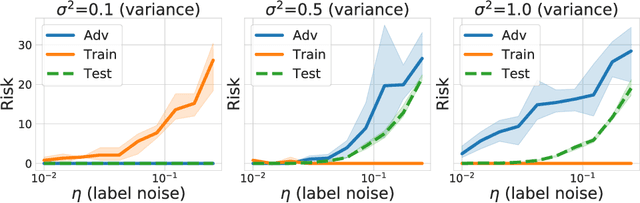
We investigate two causes for adversarial vulnerability in deep neural networks: bad data and (poorly) trained models. When trained with SGD, deep neural networks essentially achieve zero training error, even in the presence of label noise, while also exhibiting good generalization on natural test data, something referred to as benign overfitting [2, 10]. However, these models are vulnerable to adversarial attacks. We identify label noise as one of the causes for adversarial vulnerability, and provide theoretical and empirical evidence in support of this. Surprisingly, we find several instances of label noise in datasets such as MNIST and CIFAR, and that robustly trained models incur training error on some of these, i.e. they don't fit the noise. However, removing noisy labels alone does not suffice to achieve adversarial robustness. Standard training procedures bias neural networks towards learning "simple" classification boundaries, which may be less robust than more complex ones. We observe that adversarial training does produce more complex decision boundaries. We conjecture that in part the need for complex decision boundaries arises from sub-optimal representation learning. By means of simple toy examples, we show theoretically how the choice of representation can drastically affect adversarial robustness.
Relating by Contrasting: A Data-efficient Framework for Multimodal Generative Models
Jul 02, 2020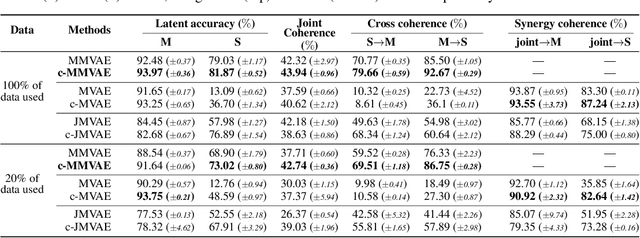
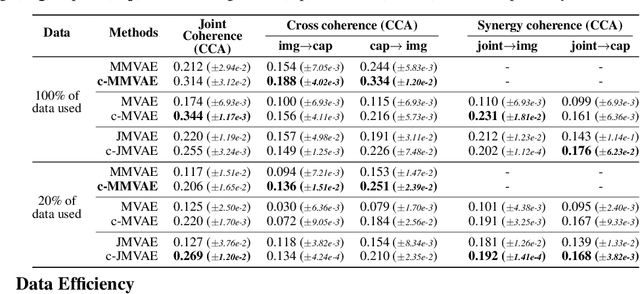


Multimodal learning for generative models often refers to the learning of abstract concepts from the commonality of information in multiple modalities, such as vision and language. While it has proven effective for learning generalisable representations, the training of such models often requires a large amount of "related" multimodal data that shares commonality, which can be expensive to come by. To mitigate this, we develop a novel contrastive framework for generative model learning, allowing us to train the model not just by the commonality between modalities, but by the distinction between "related" and "unrelated" multimodal data. We show in experiments that our method enables data-efficient multimodal learning on challenging datasets for various multimodal VAE models. We also show that under our proposed framework, the generative model can accurately identify related samples from unrelated ones, making it possible to make use of the plentiful unlabeled, unpaired multimodal data.
STEER: Simple Temporal Regularization For Neural ODEs
Jul 01, 2020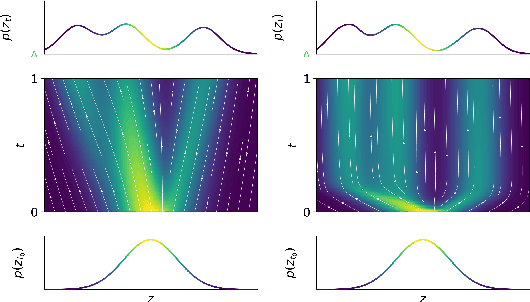
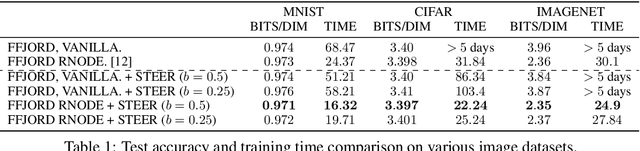
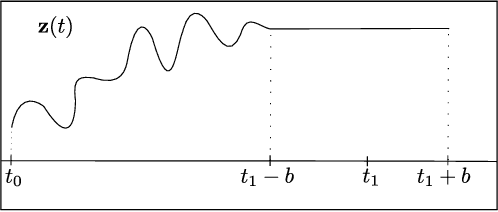
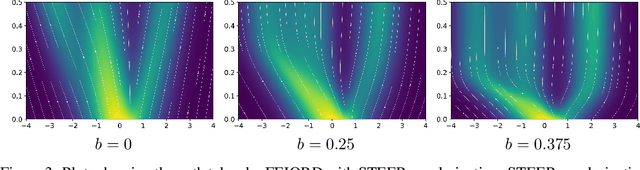
Training Neural Ordinary Differential Equations (ODEs) is often computationally expensive. Indeed, computing the forward pass of such models involves solving an ODE which can become arbitrarily complex during training. Recent works have shown that regularizing the dynamics of the ODE can partially alleviate this. In this paper we propose a new regularization technique: randomly sampling the end time of the ODE during training. The proposed regularization is simple to implement, has negligible overhead and is effective across a wide variety of tasks. Further, the technique is orthogonal to several other methods proposed to regularize the dynamics of ODEs and as such can be used in conjunction with them. We show through experiments on normalizing flows, time series models and image recognition that the proposed regularization can significantly decrease training time and even improve performance over baseline models.
Rethinking Semi-Supervised Learning in VAEs
Jun 17, 2020
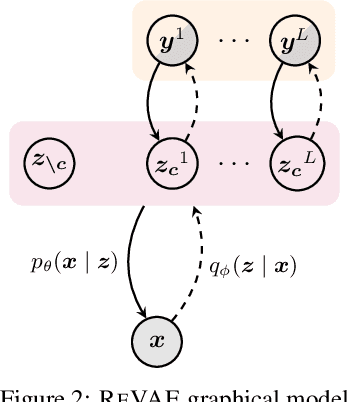

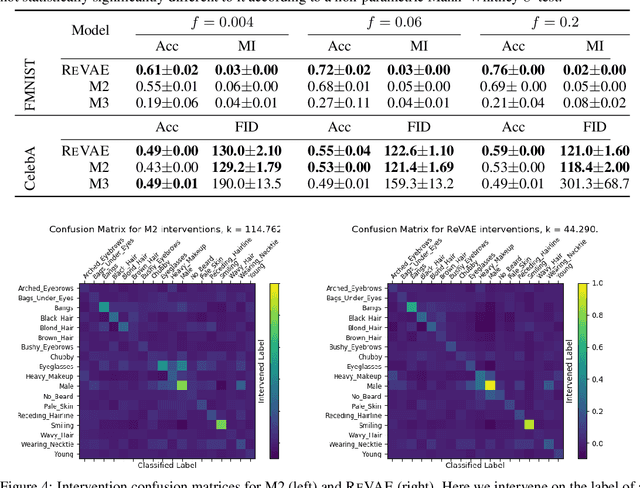
We present an alternative approach to semi-supervision in variational autoencoders(VAEs) that incorporates labels through auxiliary variables rather than directly through the latent variables. Prior work has generally conflated the meaning of labels, i.e. the associated characteristics of interest, with the actual label values themselves-learning latent variables that directly correspond to the label values. We argue that to learn meaningful representations, semi-supervision should instead try to capture these richer characteristics and that the construction of latent variables as label values is not just unnecessary, but actively harmful. To this end, we develop a novel VAE model, the reparameterized VAE (ReVAE), which "reparameterizes" supervision through auxiliary variables and a concomitant variational objective. Through judicious structuring of mappings between latent and auxiliary variables, we show that the ReVAE can effectively learn meaningful representations of data. In particular, we demonstrate that the ReVAE is able to match, and even improve on the classification accuracy of previous approaches, but more importantly, it also allows for more effective and more general interventions to be performed. We include a demo of ReVAE at https://github.com/thwjoy/revae-demo.
A Revised Generative Evaluation of Visual Dialogue
Apr 24, 2020
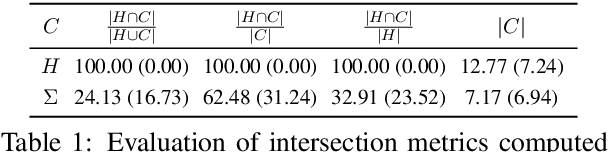
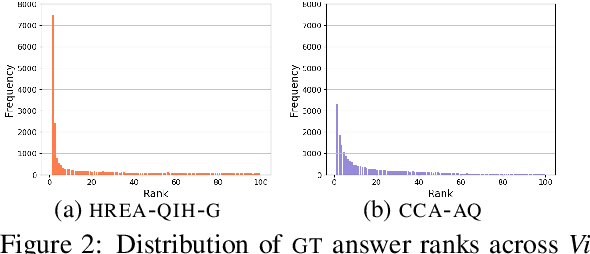
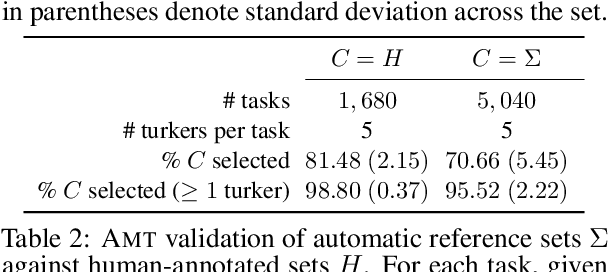
Evaluating Visual Dialogue, the task of answering a sequence of questions relating to a visual input, remains an open research challenge. The current evaluation scheme of the VisDial dataset computes the ranks of ground-truth answers in predefined candidate sets, which Massiceti et al. (2018) show can be susceptible to the exploitation of dataset biases. This scheme also does little to account for the different ways of expressing the same answer--an aspect of language that has been well studied in NLP. We propose a revised evaluation scheme for the VisDial dataset leveraging metrics from the NLP literature to measure consensus between answers generated by the model and a set of relevant answers. We construct these relevant answer sets using a simple and effective semi-supervised method based on correlation, which allows us to automatically extend and scale sparse relevance annotations from humans to the entire dataset. We release these sets and code for the revised evaluation scheme as DenseVisDial, and intend them to be an improvement to the dataset in the face of its existing constraints and design choices.
Edge Guided GANs with Semantic Preserving for Semantic Image Synthesis
Mar 31, 2020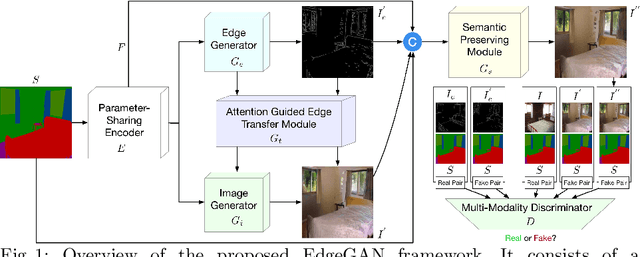
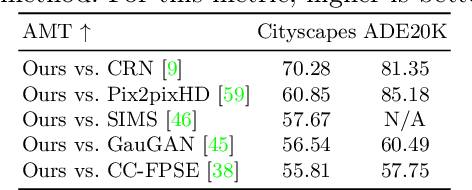
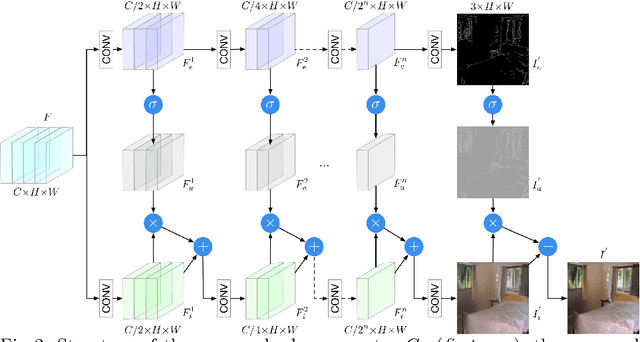
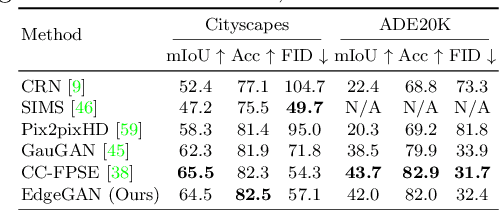
We propose a novel Edge guided Generative Adversarial Network (EdgeGAN) for photo-realistic image synthesis from semantic layouts. Although considerable improvement has been achieved, the quality of synthesized images is far from satisfactory due to two largely unresolved challenges. First, the semantic labels do not provide detailed structural information, making it difficult to synthesize local details and structures. Second, the widely adopted CNN operations such as convolution, down-sampling and normalization usually cause spatial resolution loss and thus are unable to fully preserve the original semantic information, leading to semantically inconsistent results (e.g., missing small objects). To tackle the first challenge, we propose to use the edge as an intermediate representation which is further adopted to guide image generation via a proposed attention guided edge transfer module. Edge information is produced by a convolutional generator and introduces detailed structure information. Further, to preserve the semantic information, we design an effective module to selectively highlight class-dependent feature maps according to the original semantic layout. Extensive experiments on two challenging datasets show that the proposed EdgeGAN can generate significantly better results than state-of-the-art methods. The source code and trained models are available at https://github.com/Ha0Tang/EdgeGAN.
Cross-modal Deep Face Normals with Deactivable Skip Connections
Mar 30, 2020
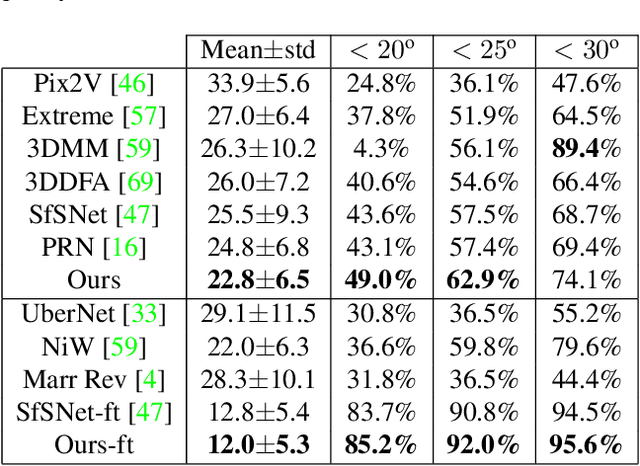
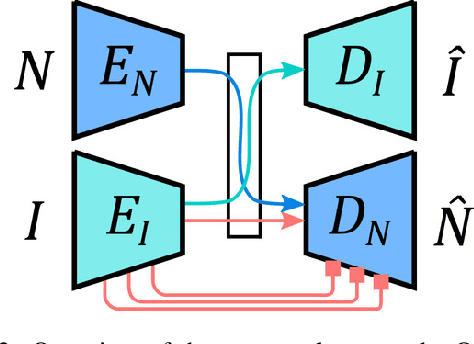
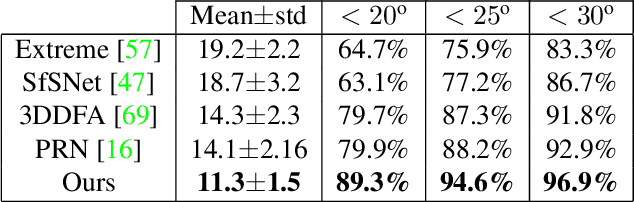
We present an approach for estimating surface normals from in-the-wild color images of faces. While data-driven strategies have been proposed for single face images, limited available ground truth data makes this problem difficult. To alleviate this issue, we propose a method that can leverage all available image and normal data, whether paired or not, thanks to a novel cross-modal learning architecture. In particular, we enable additional training with single modality data, either color or normal, by using two encoder-decoder networks with a shared latent space. The proposed architecture also enables face details to be transferred between the image and normal domains, given paired data, through skip connections between the image encoder and normal decoder. Core to our approach is a novel module that we call deactivable skip connections, which allows integrating both the auto-encoded and image-to-normal branches within the same architecture that can be trained end-to-end. This allows learning of a rich latent space that can accurately capture the normal information. We compare against state-of-the-art methods and show that our approach can achieve significant improvements, both quantitative and qualitative, with natural face images.
Data Parallelism in Training Sparse Neural Networks
Mar 25, 2020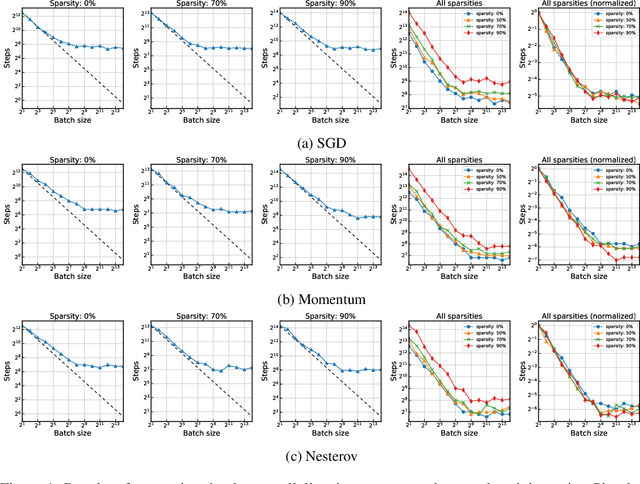
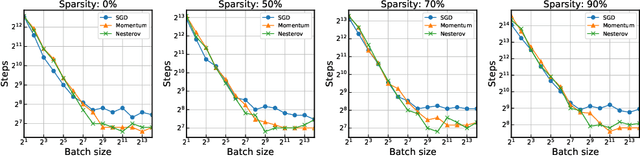
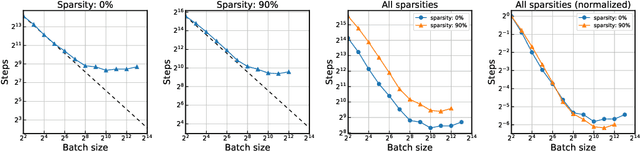
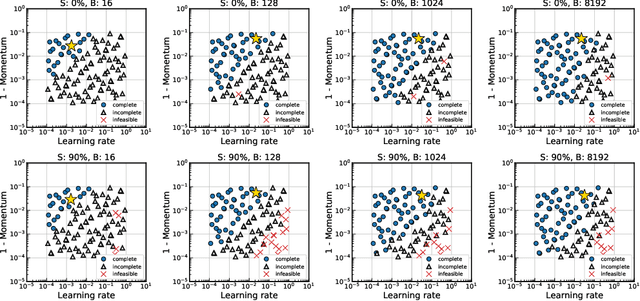
Network pruning is an effective methodology to compress large neural networks, and sparse neural networks obtained by pruning can benefit from their reduced memory and computational costs at use. Notably, recent advances have found that it is possible to find a trainable sparse neural network even at random initialization prior to training; hence the obtained sparse network only needs to be trained. While this approach of pruning at initialization turned out to be highly effective, little has been studied about the training aspects of these sparse neural networks. In this work, we focus on measuring the effects of data parallelism on training sparse neural networks. As a result, we find that the data parallelism in training sparse neural networks is no worse than that in training densely parameterized neural networks, despite the general difficulty of training sparse neural networks. When training sparse networks using SGD with momentum, the breakdown of the perfect scaling regime occurs even much later than the dense at large batch sizes.