 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNGL-Prompter: Training-Free Sewing Pattern Estimation from a Single Image
Feb 24, 2026Estimating sewing patterns from images is a practical approach for creating high-quality 3D garments. Due to the lack of real-world pattern-image paired data, prior approaches fine-tune large vision language models (VLMs) on synthetic garment datasets generated by randomly sampling from a parametric garment model GarmentCode. However, these methods often struggle to generalize to in-the-wild images, fail to capture real-world correlations between garment parts, and are typically restricted to single-layer outfits. In contrast, we observe that VLMs are effective at describing garments in natural language, yet perform poorly when asked to directly regress GarmentCode parameters from images. To bridge this gap, we propose NGL (Natural Garment Language), a novel intermediate language that restructures GarmentCode into a representation more understandable to language models. Leveraging this language, we introduce NGL-Prompter, a training-free pipeline that queries large VLMs to extract structured garment parameters, which are then deterministically mapped to valid GarmentCode. We evaluate our method on the Dress4D, CloSe and a newly collected dataset of approximately 5,000 in-the-wild fashion images. Our approach achieves state-of-the-art performance on standard geometry metrics and is strongly preferred in both human and GPT-based perceptual evaluations compared to existing baselines. Furthermore, NGL-prompter can recover multi-layer outfits whereas competing methods focus mostly on single-layer garments, highlighting its strong generalization to real-world images even with occluded parts. These results demonstrate that accurate sewing pattern reconstruction is possible without costly model training. Our code and data will be released for research use.
OFER: Occluded Face Expression Reconstruction
Oct 29, 2024Reconstructing 3D face models from a single image is an inherently ill-posed problem, which becomes even more challenging in the presence of occlusions. In addition to fewer available observations, occlusions introduce an extra source of ambiguity, where multiple reconstructions can be equally valid. Despite the ubiquity of the problem, very few methods address its multi-hypothesis nature. In this paper we introduce OFER, a novel approach for single image 3D face reconstruction that can generate plausible, diverse, and expressive 3D faces, even under strong occlusions. Specifically, we train two diffusion models to generate the shape and expression coefficients of a face parametric model, conditioned on the input image. This approach captures the multi-modal nature of the problem, generating a distribution of solutions as output. Although this addresses the ambiguity problem, the challenge remains to pick the best matching shape to ensure consistency across diverse expressions. To achieve this, we propose a novel ranking mechanism that sorts the outputs of the shape diffusion network based on the predicted shape accuracy scores to select the best match. We evaluate our method using standard benchmarks and introduce CO-545, a new protocol and dataset designed to assess the accuracy of expressive faces under occlusion. Our results show improved performance over occlusion-based methods, with added ability to generate multiple expressions for a given image.
Analysis of Classifier-Free Guidance Weight Schedulers
Apr 19, 2024Classifier-Free Guidance (CFG) enhances the quality and condition adherence of text-to-image diffusion models. It operates by combining the conditional and unconditional predictions using a fixed weight. However, recent works vary the weights throughout the diffusion process, reporting superior results but without providing any rationale or analysis. By conducting comprehensive experiments, this paper provides insights into CFG weight schedulers. Our findings suggest that simple, monotonically increasing weight schedulers consistently lead to improved performances, requiring merely a single line of code. In addition, more complex parametrized schedulers can be optimized for further improvement, but do not generalize across different models and tasks.
LED: Latent Variable-based Estimation of Density
Jun 23, 2022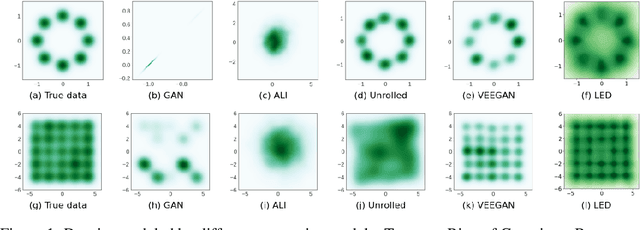
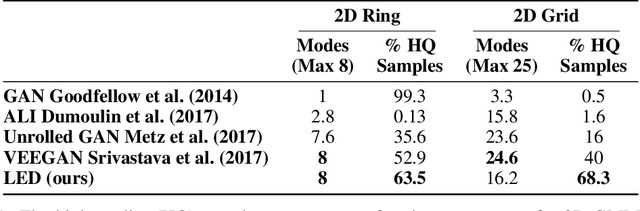

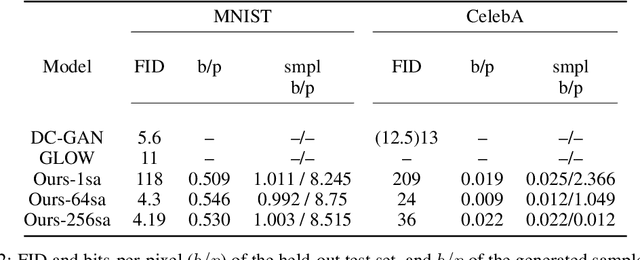
Modern generative models are roughly divided into two main categories: (1) models that can produce high-quality random samples, but cannot estimate the exact density of new data points and (2) those that provide exact density estimation, at the expense of sample quality and compactness of the latent space. In this work we propose LED, a new generative model closely related to GANs, that allows not only efficient sampling but also efficient density estimation. By maximizing log-likelihood on the output of the discriminator, we arrive at an alternative adversarial optimization objective that encourages generated data diversity. This formulation provides insights into the relationships between several popular generative models. Additionally, we construct a flow-based generator that can compute exact probabilities for generated samples, while allowing low-dimensional latent variables as input. Our experimental results, on various datasets, show that our density estimator produces accurate estimates, while retaining good quality in the generated samples.
Cross-modal Deep Face Normals with Deactivable Skip Connections
Mar 30, 2020
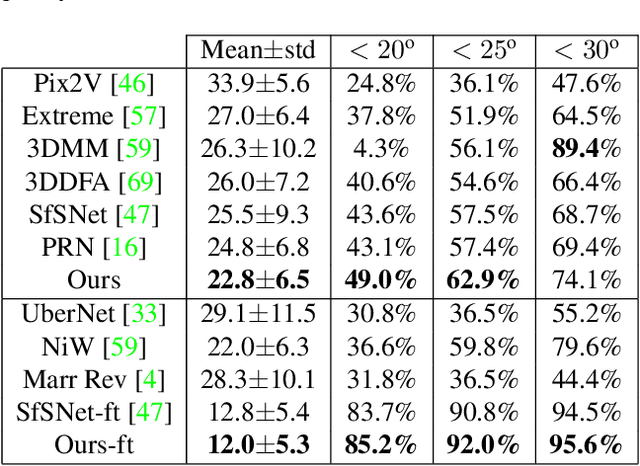
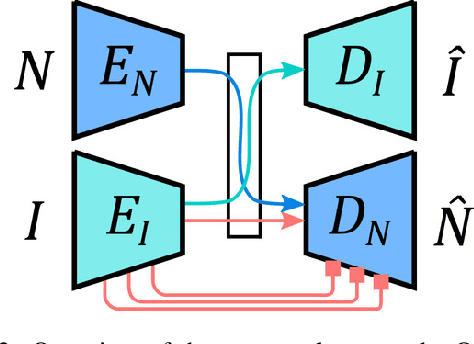
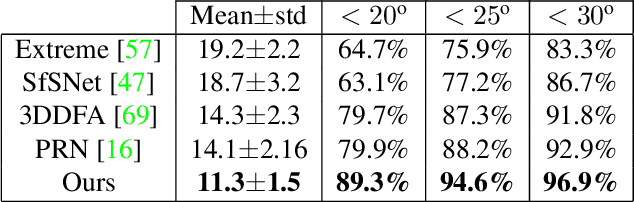
We present an approach for estimating surface normals from in-the-wild color images of faces. While data-driven strategies have been proposed for single face images, limited available ground truth data makes this problem difficult. To alleviate this issue, we propose a method that can leverage all available image and normal data, whether paired or not, thanks to a novel cross-modal learning architecture. In particular, we enable additional training with single modality data, either color or normal, by using two encoder-decoder networks with a shared latent space. The proposed architecture also enables face details to be transferred between the image and normal domains, given paired data, through skip connections between the image encoder and normal decoder. Core to our approach is a novel module that we call deactivable skip connections, which allows integrating both the auto-encoded and image-to-normal branches within the same architecture that can be trained end-to-end. This allows learning of a rich latent space that can accurately capture the normal information. We compare against state-of-the-art methods and show that our approach can achieve significant improvements, both quantitative and qualitative, with natural face images.
A Decoupled 3D Facial Shape Model by Adversarial Training
Apr 17, 2019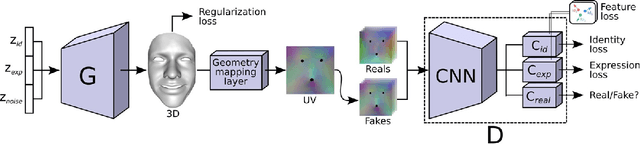
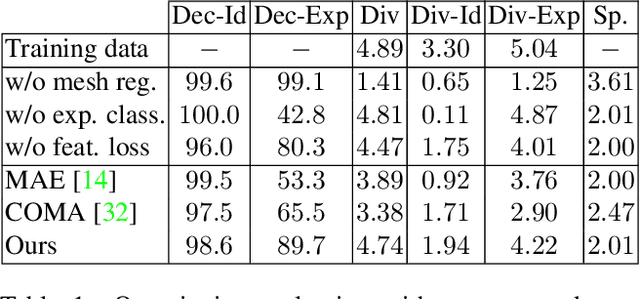
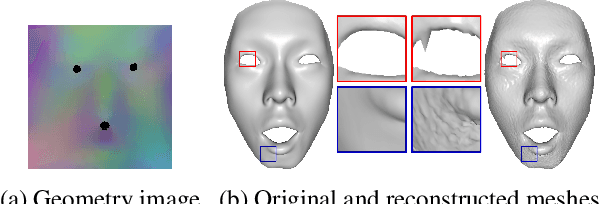
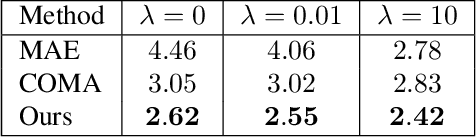
Data-driven generative 3D face models are used to compactly encode facial shape data into meaningful parametric representations. A desirable property of these models is their ability to effectively decouple natural sources of variation, in particular identity and expression. While factorized representations have been proposed for that purpose, they are still limited in the variability they can capture and may present modeling artifacts when applied to tasks such as expression transfer. In this work, we explore a new direction with Generative Adversarial Networks and show that they contribute to better face modeling performances, especially in decoupling natural factors, while also achieving more diverse samples. To train the model we introduce a novel architecture that combines a 3D generator with a 2D discriminator that leverages conventional CNNs, where the two components are bridged by a geometry mapping layer. We further present a training scheme, based on auxiliary classifiers, to explicitly disentangle identity and expression attributes. Through quantitative and qualitative results on standard face datasets, we illustrate the benefits of our model and demonstrate that it outperforms competing state of the art methods in terms of decoupling and diversity.