 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Batch Normalisation for Approximate Bayesian Inference
Dec 24, 2020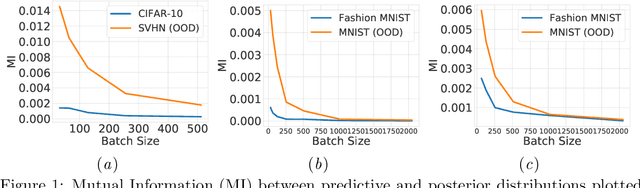
We study batch normalisation in the context of variational inference methods in Bayesian neural networks, such as mean-field or MC Dropout. We show that batch-normalisation does not affect the optimum of the evidence lower bound (ELBO). Furthermore, we study the Monte Carlo Batch Normalisation (MCBN) algorithm, proposed as an approximate inference technique parallel to MC Dropout, and show that for larger batch sizes, MCBN fails to capture epistemic uncertainty. Finally, we provide insights into what is required to fix this failure, namely having to view the mini-batch size as a variational parameter in MCBN. We comment on the asymptotics of the ELBO with respect to this variational parameter, showing that as dataset size increases towards infinity, the batch-size must increase towards infinity as well for MCBN to be a valid approximate inference technique.
Multi-shot Temporal Event Localization: a Benchmark
Dec 17, 2020


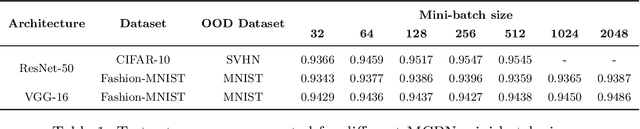
Current developments in temporal event or action localization usually target actions captured by a single camera. However, extensive events or actions in the wild may be captured as a sequence of shots by multiple cameras at different positions. In this paper, we propose a new and challenging task called multi-shot temporal event localization, and accordingly, collect a large scale dataset called MUlti-Shot EventS (MUSES). MUSES has 31,477 event instances for a total of 716 video hours. The core nature of MUSES is the frequent shot cuts, for an average of 19 shots per instance and 176 shots per video, which induces large intrainstance variations. Our comprehensive evaluations show that the state-of-the-art method in temporal action localization only achieves an mAP of 13.1% at IoU=0.5. As a minor contribution, we present a simple baseline approach for handling the intra-instance variations, which reports an mAP of 18.9% on MUSES and 56.9% on THUMOS14 at IoU=0.5. To facilitate research in this direction, we release the dataset and the project code at https://songbai.site/muses.
GeoNet++: Iterative Geometric Neural Network with Edge-Aware Refinement for Joint Depth and Surface Normal Estimation
Dec 13, 2020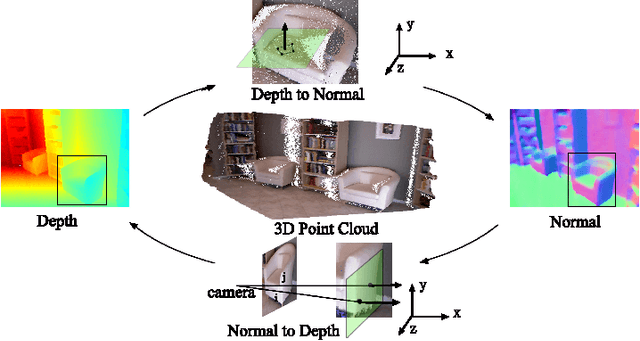
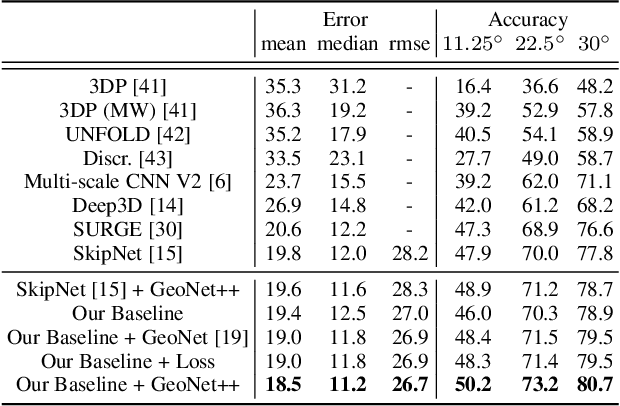
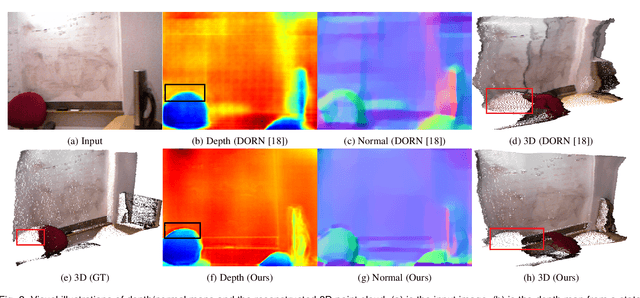
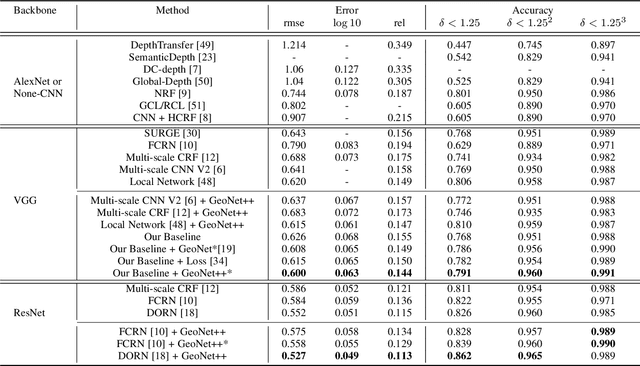
In this paper, we propose a geometric neural network with edge-aware refinement (GeoNet++) to jointly predict both depth and surface normal maps from a single image. Building on top of two-stream CNNs, GeoNet++ captures the geometric relationships between depth and surface normals with the proposed depth-to-normal and normal-to-depth modules. In particular, the "depth-to-normal" module exploits the least square solution of estimating surface normals from depth to improve their quality, while the "normal-to-depth" module refines the depth map based on the constraints on surface normals through kernel regression. Boundary information is exploited via an edge-aware refinement module. GeoNet++ effectively predicts depth and surface normals with strong 3D consistency and sharp boundaries resulting in better reconstructed 3D scenes. Note that GeoNet++ is generic and can be used in other depth/normal prediction frameworks to improve the quality of 3D reconstruction and pixel-wise accuracy of depth and surface normals. Furthermore, we propose a new 3D geometric metric (3DGM) for evaluating depth prediction in 3D. In contrast to current metrics that focus on evaluating pixel-wise error/accuracy, 3DGM measures whether the predicted depth can reconstruct high-quality 3D surface normals. This is a more natural metric for many 3D application domains. Our experiments on NYUD-V2 and KITTI datasets verify that GeoNet++ produces fine boundary details, and the predicted depth can be used to reconstruct high-quality 3D surfaces. Code has been made publicly available.
Data Dependent Randomized Smoothing
Dec 08, 2020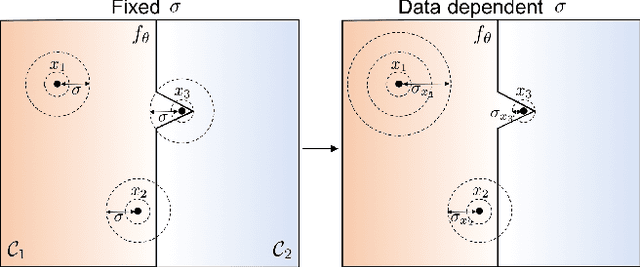
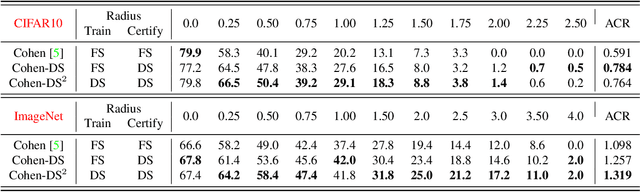
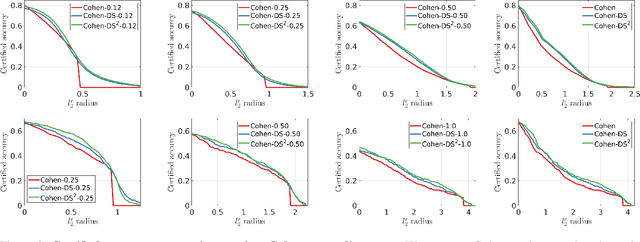
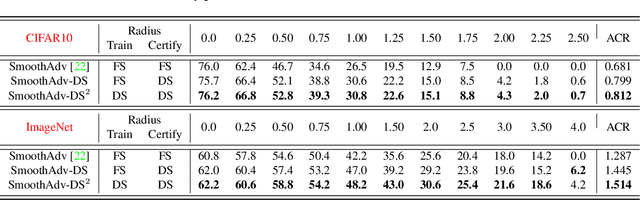
Randomized smoothing is a recent technique that achieves state-of-art performance in training certifiably robust deep neural networks. While the smoothing family of distributions is often connected to the choice of the norm used for certification, the parameters of the distributions are always set as global hyper parameters independent of the input data on which a network is certified. In this work, we revisit Gaussian randomized smoothing where we show that the variance of the Gaussian distribution can be optimized at each input so as to maximize the certification radius for the construction of the smoothed classifier. This new approach is generic, parameter-free, and easy to implement. In fact, we show that our data dependent framework can be seamlessly incorporated into 3 randomized smoothing approaches, leading to consistent improved certified accuracy. When this framework is used in the training routine of these approaches followed by a data dependent certification, we get 9% and 6% improvement over the certified accuracy of the strongest baseline for a radius of 0.5 on CIFAR10 and ImageNet, respectively.
Is Independent Learning All You Need in the StarCraft Multi-Agent Challenge?
Nov 18, 2020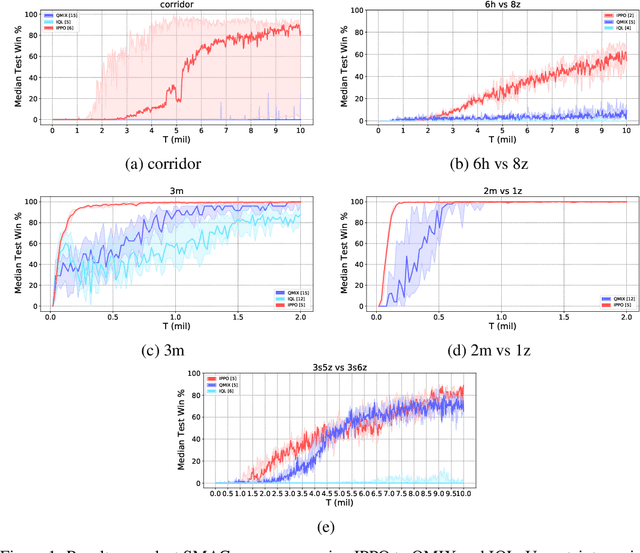
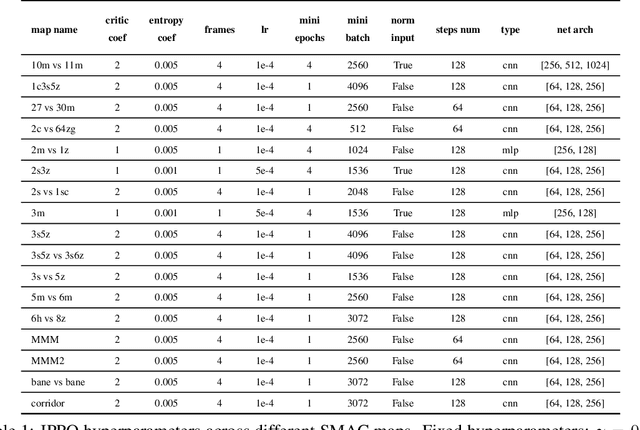

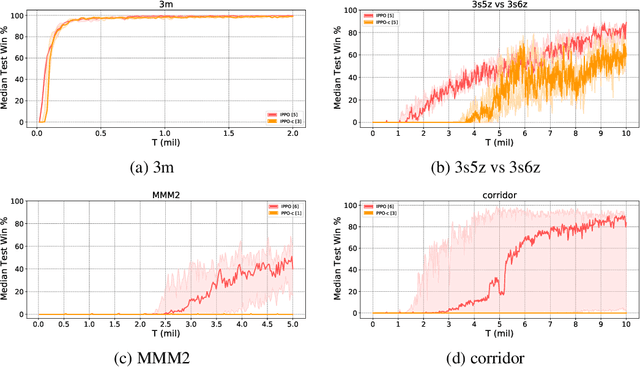
Most recently developed approaches to cooperative multi-agent reinforcement learning in the \emph{centralized training with decentralized execution} setting involve estimating a centralized, joint value function. In this paper, we demonstrate that, despite its various theoretical shortcomings, Independent PPO (IPPO), a form of independent learning in which each agent simply estimates its local value function, can perform just as well as or better than state-of-the-art joint learning approaches on popular multi-agent benchmark suite SMAC with little hyperparameter tuning. We also compare IPPO to several variants; the results suggest that IPPO's strong performance may be due to its robustness to some forms of environment non-stationarity.
Lightweight Generative Adversarial Networks for Text-Guided Image Manipulation
Oct 23, 2020
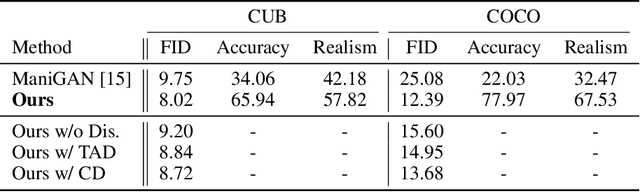
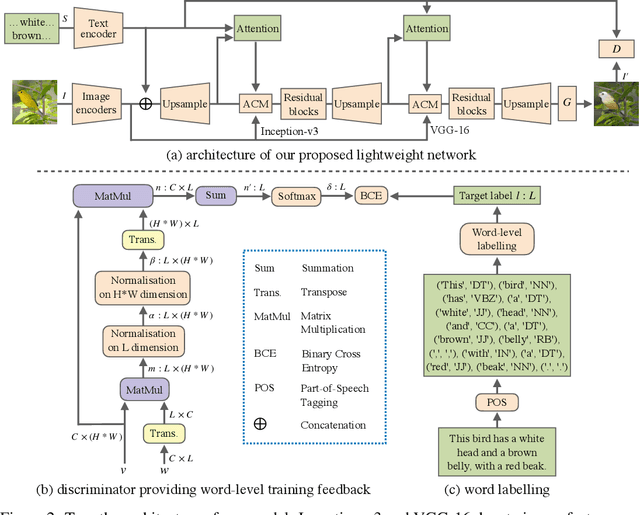

We propose a novel lightweight generative adversarial network for efficient image manipulation using natural language descriptions. To achieve this, a new word-level discriminator is proposed, which provides the generator with fine-grained training feedback at word-level, to facilitate training a lightweight generator that has a small number of parameters, but can still correctly focus on specific visual attributes of an image, and then edit them without affecting other contents that are not described in the text. Furthermore, thanks to the explicit training signal related to each word, the discriminator can also be simplified to have a lightweight structure. Compared with the state of the art, our method has a much smaller number of parameters, but still achieves a competitive manipulation performance. Extensive experimental results demonstrate that our method can better disentangle different visual attributes, then correctly map them to corresponding semantic words, and thus achieve a more accurate image modification using natural language descriptions.
Continual Learning in Low-rank Orthogonal Subspaces
Oct 22, 2020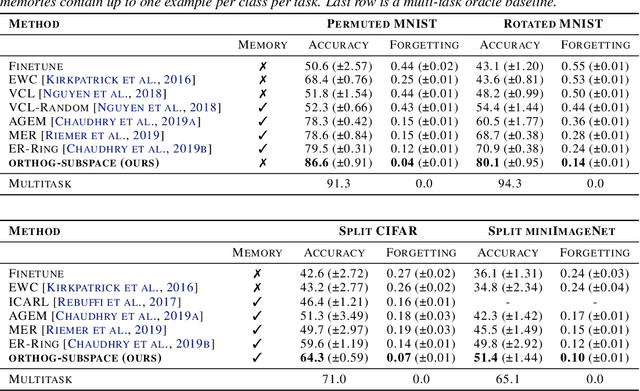

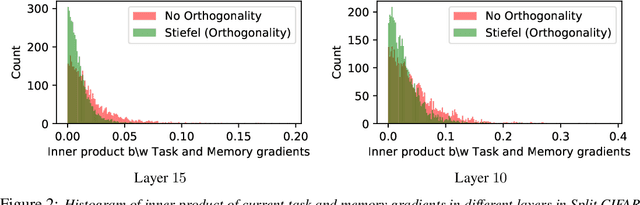
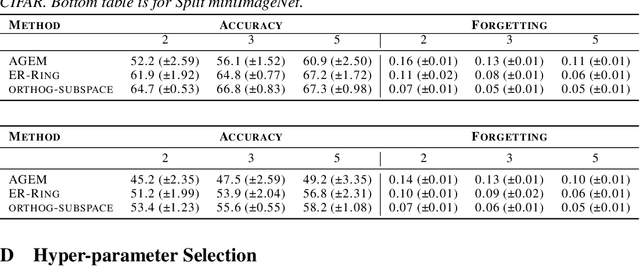
In continual learning (CL), a learner is faced with a sequence of tasks, arriving one after the other, and the goal is to remember all the tasks once the continual learning experience is finished. The prior art in CL uses episodic memory, parameter regularization or extensible network structures to reduce interference among tasks, but in the end, all the approaches learn different tasks in a joint vector space. We believe this invariably leads to interference among different tasks. We propose to learn tasks in different (low-rank) vector subspaces that are kept orthogonal to each other in order to minimize interference. Further, to keep the gradients of different tasks coming from these subspaces orthogonal to each other, we learn isometric mappings by posing network training as an optimization problem over the Stiefel manifold. To the best of our understanding, we report, for the first time, strong results over experience-replay baseline with and without memory on standard classification benchmarks in continual learning. The code is made publicly available.
* The paper is accepted at NeurIPS'20
Bipartite Graph Reasoning GANs for Person Image Generation
Aug 20, 2020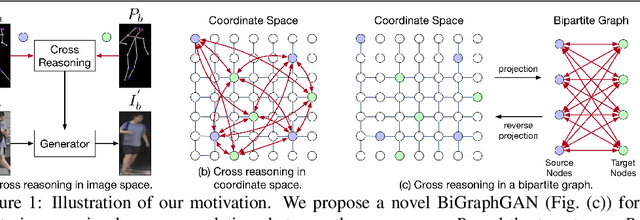
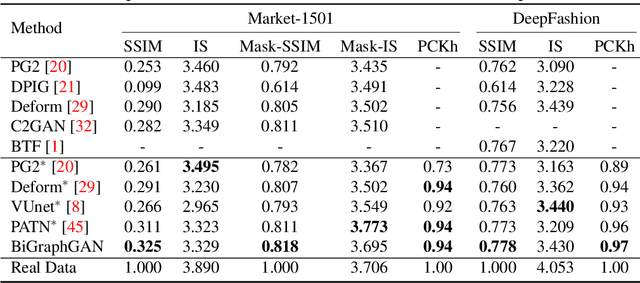
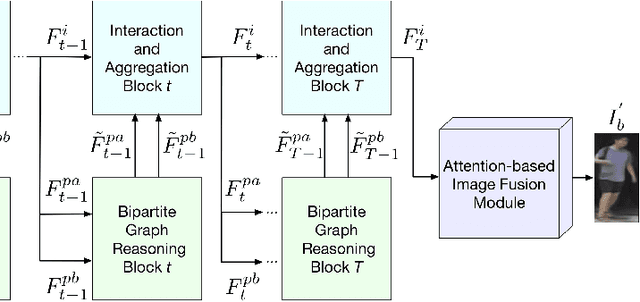
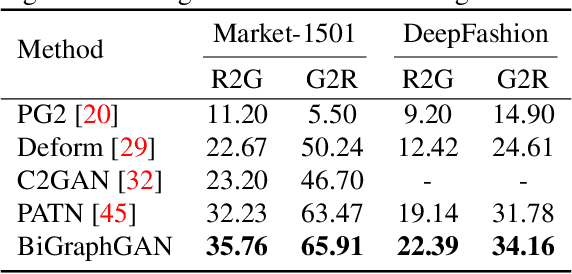
We present a novel Bipartite Graph Reasoning GAN (BiGraphGAN) for the challenging person image generation task. The proposed graph generator mainly consists of two novel blocks that aim to model the pose-to-pose and pose-to-image relations, respectively. Specifically, the proposed Bipartite Graph Reasoning (BGR) block aims to reason the crossing long-range relations between the source pose and the target pose in a bipartite graph, which mitigates some challenges caused by pose deformation. Moreover, we propose a new Interaction-and-Aggregation (IA) block to effectively update and enhance the feature representation capability of both person's shape and appearance in an interactive way. Experiments on two challenging and public datasets, i.e., Market-1501 and DeepFashion, show the effectiveness of the proposed BiGraphGAN in terms of objective quantitative scores and subjective visual realness. The source code and trained models are available at https://github.com/Ha0Tang/BiGraphGAN.
AutoSimulate: (Quickly) Learning Synthetic Data Generation
Aug 16, 2020

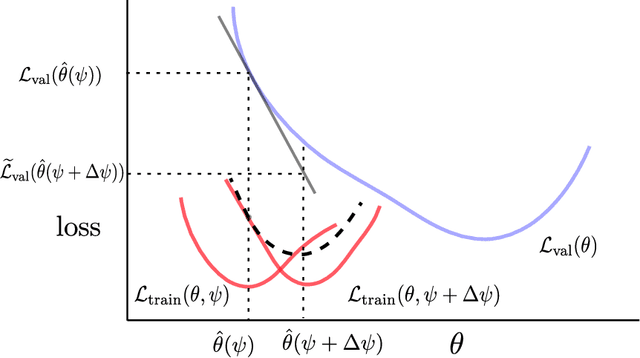

Simulation is increasingly being used for generating large labelled datasets in many machine learning problems. Recent methods have focused on adjusting simulator parameters with the goal of maximising accuracy on a validation task, usually relying on REINFORCE-like gradient estimators. However these approaches are very expensive as they treat the entire data generation, model training, and validation pipeline as a black-box and require multiple costly objective evaluations at each iteration. We propose an efficient alternative for optimal synthetic data generation, based on a novel differentiable approximation of the objective. This allows us to optimize the simulator, which may be non-differentiable, requiring only one objective evaluation at each iteration with a little overhead. We demonstrate on a state-of-the-art photorealistic renderer that the proposed method finds the optimal data distribution faster (up to $50\times$), with significantly reduced training data generation (up to $30\times$) and better accuracy ($+8.7\%$) on real-world test datasets than previous methods.
* ECCV 2020
XingGAN for Person Image Generation
Jul 17, 2020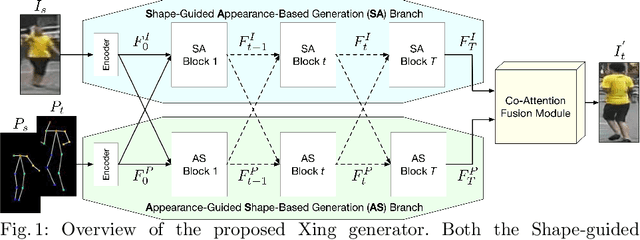
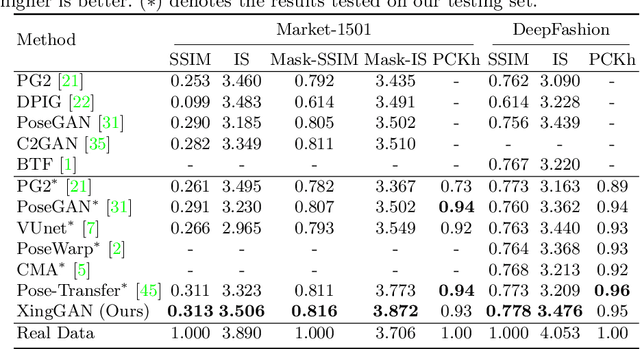
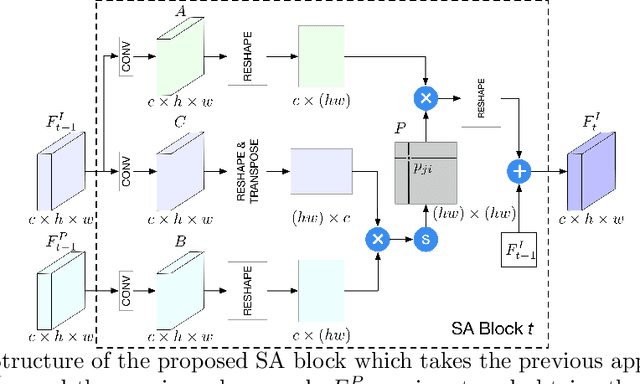
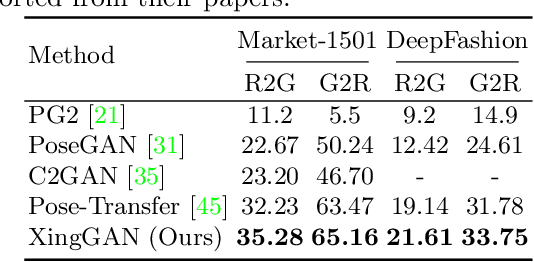
We propose a novel Generative Adversarial Network (XingGAN or CrossingGAN) for person image generation tasks, i.e., translating the pose of a given person to a desired one. The proposed Xing generator consists of two generation branches that model the person's appearance and shape information, respectively. Moreover, we propose two novel blocks to effectively transfer and update the person's shape and appearance embeddings in a crossing way to mutually improve each other, which has not been considered by any other existing GAN-based image generation work. Extensive experiments on two challenging datasets, i.e., Market-1501 and DeepFashion, demonstrate that the proposed XingGAN advances the state-of-the-art performance both in terms of objective quantitative scores and subjective visual realness. The source code and trained models are available at https://github.com/Ha0Tang/XingGAN.