 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing Detectability in 3DGS Poisoning: A Stage-wise Benchmark
Jun 02, 20263D Gaussian Splatting (3DGS) has rapidly emerged as a leading representation for real-time novel view synthesis, but recent work shows it is vulnerable to diverse poisoning attacks, including illusory object injection, computation cost amplification, and post hoc model watermarking. Despite this expanding threat surface, existing studies focus mainly on attack success, while defense and detection remain underexplored. From a detection perspective, a key challenge and opportunity arise from the multi-stage nature of the 3DGS reconstruction pipeline, which produces heterogeneous intermediate representations. Forensic signals for detecting poisoning are inherently stage dependent: an attack introduced at one stage may produce signals that emerge only at later stages. This motivates a stage-wise view of detectability that goes beyond single-stage evaluation. We introduce Poison-3DGS, a benchmark for stage-wise characterization of poisoning detection in 3DGS. It exposes stage-specific artifacts, including multi-view images, geometry, training dynamics, and Gaussian parameters, across a diverse set of scenes and attacks. Using it, we conduct a systematic study of detectability across pipeline stages. Our analysis reveals several insights. First, detectability varies significantly across stages, and no single stage consistently dominates across attack types. Second, different attacks exhibit distinct stage-specific forensic signals, so detection effectiveness depends critically on where signals are observed. Third, later-stage signals such as training dynamics and Gaussian parameter statistics provide strong cues not observable at earlier stages. Overall, our work provides a principled benchmark and the first systematic characterization of stage-dependent detectability in 3DGS, offering a foundation for future research on robust and reliable 3DGS systems.
Joint Architecture-Token-Bitwidth Multi-Axis Optimization of Vision Transformers for Semiconductor IC Packaging
May 03, 2026Vision Transformers (ViTs) have achieved strong performance in visual recognition, yet their deployment in resource-constrained industrial environments remains limited. Some main challenges are their high computational cost, memory requirement, and energy consumption. While individual efficiency techniques such as neural architecture search (NAS), token compression, and low-precision inference have been extensively studied, most prior work targets only a single optimization axis, limiting overall deployment gains while preserving accuracy. In this paper, we present one of the first holistic frameworks that jointly optimizes three complementary axes: architecture, token, and bit-width. Specifically, the framework identifies compact backbones via Neural Architecture Search (AutoFormer), reduces information processing via token merging (ToMe), and accelerates per-operation execution via fp16 mixed-precision inference. Starting from a DeiT-B/16 baseline, we first analyze accuracy-efficiency trade-offs on ImageNet-1K under aggressive compression. Then, we apply the selected configurations to a real-world in-house 3D X-ray semiconductor defect classification dataset for IC chip packaging inspection. Results show that the proposed multi-axis framework achieves more than 10 times improvement in throughput along with over 10 times reductions in parameter count, FLOPs, and energy consumption, while maintaining the required accuracy on the downstream industrial task. To the best of our knowledge, this is among the earliest works to jointly optimize architecture, token, and bit-width dimensions in ViTs and the first such resource-efficient, deployment-focused study tailored to semiconductor manufacturing.
Transform Quantization for CNN Compression
Sep 02, 2020
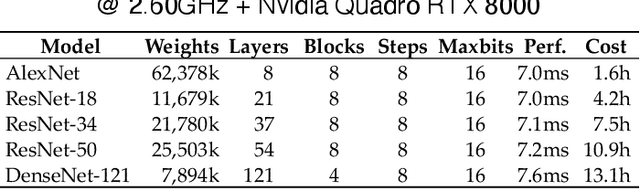
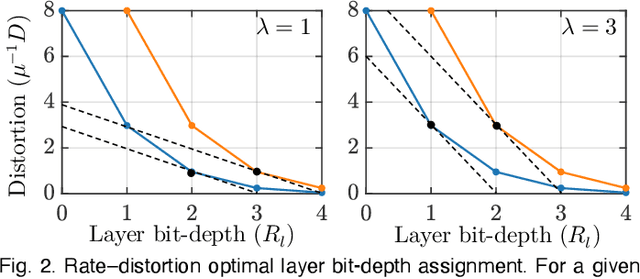
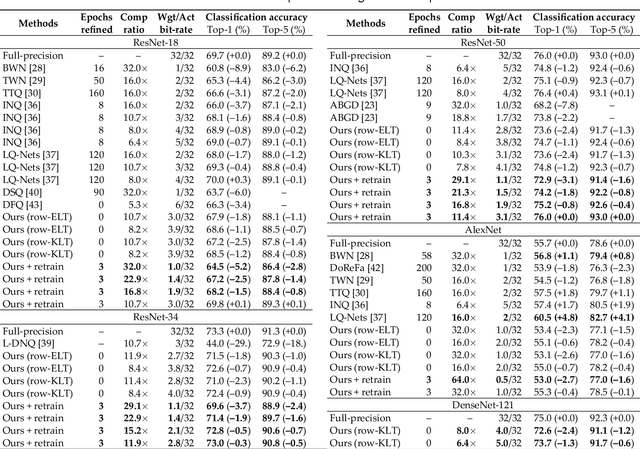
In this paper, we compress convolutional neural network (CNN) weights post-training via transform quantization. Previous CNN quantization techniques tend to ignore the joint statistics of weights and activations, producing sub-optimal CNN performance at a given quantization bit-rate, or consider their joint statistics during training only and do not facilitate efficient compression of already trained CNN models. We optimally transform (decorrelate) and quantize the weights post-training using a rate-distortion framework to improve compression at any given quantization bit-rate. Transform quantization unifies quantization and dimensionality reduction (decorrelation) techniques in a single framework to facilitate low bit-rate compression of CNNs and efficient inference in the transform domain. We first introduce a theory of rate and distortion for CNN quantization, and pose optimum quantization as a rate-distortion optimization problem. We then show that this problem can be solved using optimal bit-depth allocation following decorrelation by the optimal End-to-end Learned Transform (ELT) we derive in this paper. Experiments demonstrate that transform quantization advances the state of the art in CNN compression in both retrained and non-retrained quantization scenarios. In particular, we find that transform quantization with retraining is able to compress CNN models such as AlexNet, ResNet and DenseNet to very low bit-rates (1-2 bits).