 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLIGHT: Fibonacci Lattice-based Inference for Geometric Heading in real-Time
Feb 26, 2026Estimating camera motion from monocular video is a fundamental problem in computer vision, central to tasks such as SLAM, visual odometry, and structure-from-motion. Existing methods that recover the camera's heading under known rotation, whether from an IMU or an optimization algorithm, tend to perform well in low-noise, low-outlier conditions, but often decrease in accuracy or become computationally expensive as noise and outlier levels increase. To address these limitations, we propose a novel generalization of the Hough transform on the unit sphere (S(2)) to estimate the camera's heading. First, the method extracts correspondences between two frames and generates a great circle of directions compatible with each pair of correspondences. Then, by discretizing the unit sphere using a Fibonacci lattice as bin centers, each great circle casts votes for a range of directions, ensuring that features unaffected by noise or dynamic objects vote consistently for the correct motion direction. Experimental results on three datasets demonstrate that the proposed method is on the Pareto frontier of accuracy versus efficiency. Additionally, experiments on SLAM show that the proposed method reduces RMSE by correcting the heading during camera pose initialization.
LASER: Layer-wise Scale Alignment for Training-Free Streaming 4D Reconstruction
Dec 15, 2025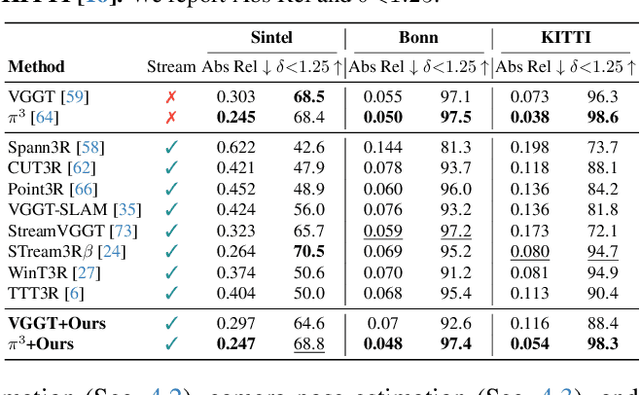
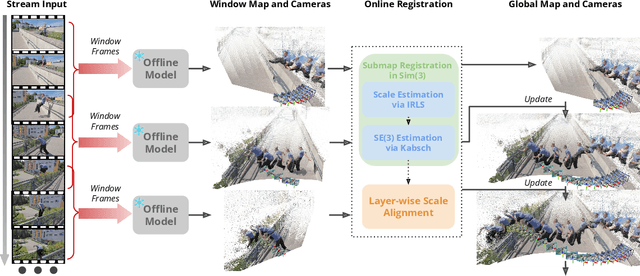
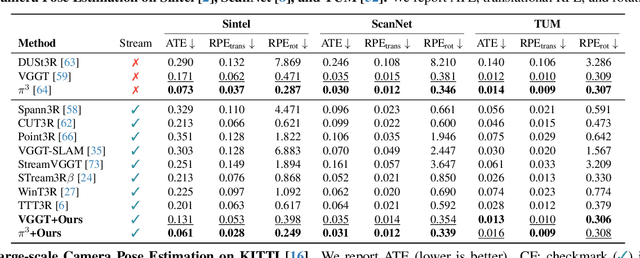
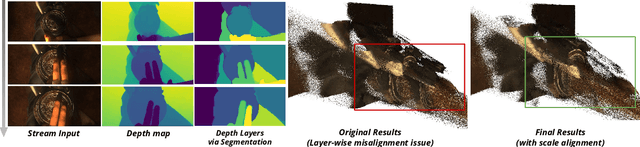
Recent feed-forward reconstruction models like VGGT and $π^3$ achieve impressive reconstruction quality but cannot process streaming videos due to quadratic memory complexity, limiting their practical deployment. While existing streaming methods address this through learned memory mechanisms or causal attention, they require extensive retraining and may not fully leverage the strong geometric priors of state-of-the-art offline models. We propose LASER, a training-free framework that converts an offline reconstruction model into a streaming system by aligning predictions across consecutive temporal windows. We observe that simple similarity transformation ($\mathrm{Sim}(3)$) alignment fails due to layer depth misalignment: monocular scale ambiguity causes relative depth scales of different scene layers to vary inconsistently between windows. To address this, we introduce layer-wise scale alignment, which segments depth predictions into discrete layers, computes per-layer scale factors, and propagates them across both adjacent windows and timestamps. Extensive experiments show that LASER achieves state-of-the-art performance on camera pose estimation and point map reconstruction %quality with offline models while operating at 14 FPS with 6 GB peak memory on a RTX A6000 GPU, enabling practical deployment for kilometer-scale streaming videos. Project website: $\href{https://neu-vi.github.io/LASER/}{\texttt{https://neu-vi.github.io/LASER/}}$
RAPTR: Radar-based 3D Pose Estimation using Transformer
Nov 11, 2025Radar-based indoor 3D human pose estimation typically relied on fine-grained 3D keypoint labels, which are costly to obtain especially in complex indoor settings involving clutter, occlusions, or multiple people. In this paper, we propose \textbf{RAPTR} (RAdar Pose esTimation using tRansformer) under weak supervision, using only 3D BBox and 2D keypoint labels which are considerably easier and more scalable to collect. Our RAPTR is characterized by a two-stage pose decoder architecture with a pseudo-3D deformable attention to enhance (pose/joint) queries with multi-view radar features: a pose decoder estimates initial 3D poses with a 3D template loss designed to utilize the 3D BBox labels and mitigate depth ambiguities; and a joint decoder refines the initial poses with 2D keypoint labels and a 3D gravity loss. Evaluated on two indoor radar datasets, RAPTR outperforms existing methods, reducing joint position error by $34.3\%$ on HIBER and $76.9\%$ on MMVR. Our implementation is available at https://github.com/merlresearch/radar-pose-transformer.
SurfR: Surface Reconstruction with Multi-scale Attention
Jun 10, 2025We propose a fast and accurate surface reconstruction algorithm for unorganized point clouds using an implicit representation. Recent learning methods are either single-object representations with small neural models that allow for high surface details but require per-object training or generalized representations that require larger models and generalize to newer shapes but lack details, and inference is slow. We propose a new implicit representation for general 3D shapes that is faster than all the baselines at their optimum resolution, with only a marginal loss in performance compared to the state-of-the-art. We achieve the best accuracy-speed trade-off using three key contributions. Many implicit methods extract features from the point cloud to classify whether a query point is inside or outside the object. First, to speed up the reconstruction, we show that this feature extraction does not need to use the query point at an early stage (lazy query). Second, we use a parallel multi-scale grid representation to develop robust features for different noise levels and input resolutions. Finally, we show that attention across scales can provide improved reconstruction results.
* Accepted in 3DV 2025
A Probability-guided Sampler for Neural Implicit Surface Rendering
Jun 10, 2025Several variants of Neural Radiance Fields (NeRFs) have significantly improved the accuracy of synthesized images and surface reconstruction of 3D scenes/objects. In all of these methods, a key characteristic is that none can train the neural network with every possible input data, specifically, every pixel and potential 3D point along the projection rays due to scalability issues. While vanilla NeRFs uniformly sample both the image pixels and 3D points along the projection rays, some variants focus only on guiding the sampling of the 3D points along the projection rays. In this paper, we leverage the implicit surface representation of the foreground scene and model a probability density function in a 3D image projection space to achieve a more targeted sampling of the rays toward regions of interest, resulting in improved rendering. Additionally, a new surface reconstruction loss is proposed for improved performance. This new loss fully explores the proposed 3D image projection space model and incorporates near-to-surface and empty space components. By integrating our novel sampling strategy and novel loss into current state-of-the-art neural implicit surface renderers, we achieve more accurate and detailed 3D reconstructions and improved image rendering, especially for the regions of interest in any given scene.
* Accepted in ECCV 2024
FreBIS: Frequency-Based Stratification for Neural Implicit Surface Representations
Apr 28, 2025Neural implicit surface representation techniques are in high demand for advancing technologies in augmented reality/virtual reality, digital twins, autonomous navigation, and many other fields. With their ability to model object surfaces in a scene as a continuous function, such techniques have made remarkable strides recently, especially over classical 3D surface reconstruction methods, such as those that use voxels or point clouds. However, these methods struggle with scenes that have varied and complex surfaces principally because they model any given scene with a single encoder network that is tasked to capture all of low through high-surface frequency information in the scene simultaneously. In this work, we propose a novel, neural implicit surface representation approach called FreBIS to overcome this challenge. FreBIS works by stratifying the scene based on the frequency of surfaces into multiple frequency levels, with each level (or a group of levels) encoded by a dedicated encoder. Moreover, FreBIS encourages these encoders to capture complementary information by promoting mutual dissimilarity of the encoded features via a novel, redundancy-aware weighting module. Empirical evaluations on the challenging BlendedMVS dataset indicate that replacing the standard encoder in an off-the-shelf neural surface reconstruction method with our frequency-stratified encoders yields significant improvements. These enhancements are evident both in the quality of the reconstructed 3D surfaces and in the fidelity of their renderings from any viewpoint.
Gear-NeRF: Free-Viewpoint Rendering and Tracking with Motion-aware Spatio-Temporal Sampling
Jun 06, 2024



Extensions of Neural Radiance Fields (NeRFs) to model dynamic scenes have enabled their near photo-realistic, free-viewpoint rendering. Although these methods have shown some potential in creating immersive experiences, two drawbacks limit their ubiquity: (i) a significant reduction in reconstruction quality when the computing budget is limited, and (ii) a lack of semantic understanding of the underlying scenes. To address these issues, we introduce Gear-NeRF, which leverages semantic information from powerful image segmentation models. Our approach presents a principled way for learning a spatio-temporal (4D) semantic embedding, based on which we introduce the concept of gears to allow for stratified modeling of dynamic regions of the scene based on the extent of their motion. Such differentiation allows us to adjust the spatio-temporal sampling resolution for each region in proportion to its motion scale, achieving more photo-realistic dynamic novel view synthesis. At the same time, almost for free, our approach enables free-viewpoint tracking of objects of interest - a functionality not yet achieved by existing NeRF-based methods. Empirical studies validate the effectiveness of our method, where we achieve state-of-the-art rendering and tracking performance on multiple challenging datasets.
Oriented-grid Encoder for 3D Implicit Representations
Feb 09, 2024



Encoding 3D points is one of the primary steps in learning-based implicit scene representation. Using features that gather information from neighbors with multi-resolution grids has proven to be the best geometric encoder for this task. However, prior techniques do not exploit some characteristics of most objects or scenes, such as surface normals and local smoothness. This paper is the first to exploit those 3D characteristics in 3D geometric encoders explicitly. In contrast to prior work on using multiple levels of details, regular cube grids, and trilinear interpolation, we propose 3D-oriented grids with a novel cylindrical volumetric interpolation for modeling local planar invariance. In addition, we explicitly include a local feature aggregation for feature regularization and smoothing of the cylindrical interpolation features. We evaluate our approach on ABC, Thingi10k, ShapeNet, and Matterport3D, for object and scene representation. Compared to the use of regular grids, our geometric encoder is shown to converge in fewer steps and obtain sharper 3D surfaces. When compared to the prior techniques, our method gets state-of-the-art results.
BANSAC: A dynamic BAyesian Network for adaptive SAmple Consensus
Sep 25, 2023



RANSAC-based algorithms are the standard techniques for robust estimation in computer vision. These algorithms are iterative and computationally expensive; they alternate between random sampling of data, computing hypotheses, and running inlier counting. Many authors tried different approaches to improve efficiency. One of the major improvements is having a guided sampling, letting the RANSAC cycle stop sooner. This paper presents a new adaptive sampling process for RANSAC. Previous methods either assume no prior information about the inlier/outlier classification of data points or use some previously computed scores in the sampling. In this paper, we derive a dynamic Bayesian network that updates individual data points' inlier scores while iterating RANSAC. At each iteration, we apply weighted sampling using the updated scores. Our method works with or without prior data point scorings. In addition, we use the updated inlier/outlier scoring for deriving a new stopping criterion for the RANSAC loop. We test our method in multiple real-world datasets for several applications and obtain state-of-the-art results. Our method outperforms the baselines in accuracy while needing less computational time.
Robust Frame-to-Frame Camera Rotation Estimation in Crowded Scenes
Sep 15, 2023



We present an approach to estimating camera rotation in crowded, real-world scenes from handheld monocular video. While camera rotation estimation is a well-studied problem, no previous methods exhibit both high accuracy and acceptable speed in this setting. Because the setting is not addressed well by other datasets, we provide a new dataset and benchmark, with high-accuracy, rigorously verified ground truth, on 17 video sequences. Methods developed for wide baseline stereo (e.g., 5-point methods) perform poorly on monocular video. On the other hand, methods used in autonomous driving (e.g., SLAM) leverage specific sensor setups, specific motion models, or local optimization strategies (lagging batch processing) and do not generalize well to handheld video. Finally, for dynamic scenes, commonly used robustification techniques like RANSAC require large numbers of iterations, and become prohibitively slow. We introduce a novel generalization of the Hough transform on SO(3) to efficiently and robustly find the camera rotation most compatible with optical flow. Among comparably fast methods, ours reduces error by almost 50\% over the next best, and is more accurate than any method, irrespective of speed. This represents a strong new performance point for crowded scenes, an important setting for computer vision. The code and the dataset are available at https://fabiendelattre.com/robust-rotation-estimation.