 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Engineering for Everyone
Feb 23, 2021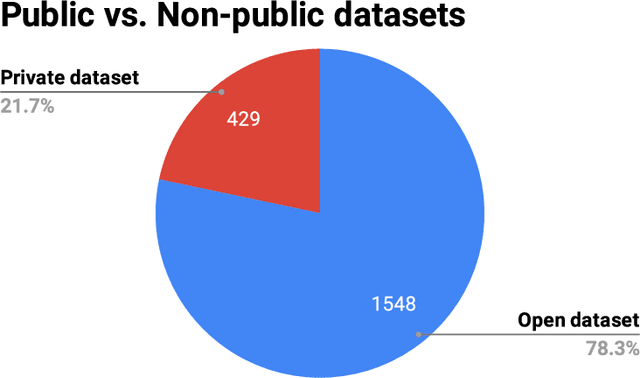
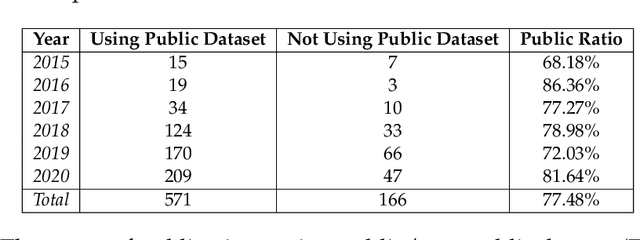
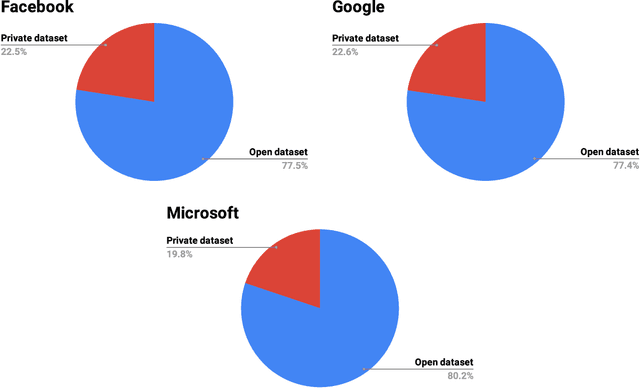
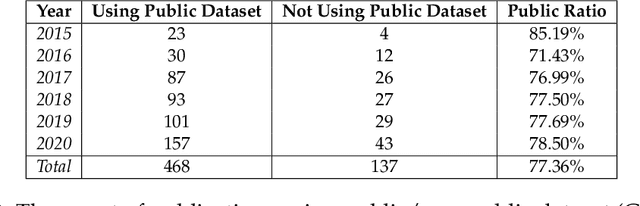
Data engineering is one of the fastest-growing fields within machine learning (ML). As ML becomes more common, the appetite for data grows more ravenous. But ML requires more data than individual teams of data engineers can readily produce, which presents a severe challenge to ML deployment at scale. Much like the software-engineering revolution, where mass adoption of open-source software replaced the closed, in-house development model for infrastructure code, there is a growing need to enable rapid development and open contribution to massive machine learning data sets. This article shows that open-source data sets are the rocket fuel for research and innovation at even some of the largest AI organizations. Our analysis of nearly 2000 research publications from Facebook, Google and Microsoft over the past five years shows the widespread use and adoption of open data sets. Open data sets that are easily accessible to the public are vital to accelerating ML innovation for everyone. But such open resources are scarce in the wild. So, what if we are able to accelerate data-set creation via automatic data set generation tools?
MLPerf Mobile Inference Benchmark: Why Mobile AI Benchmarking Is Hard and What to Do About It
Dec 03, 2020

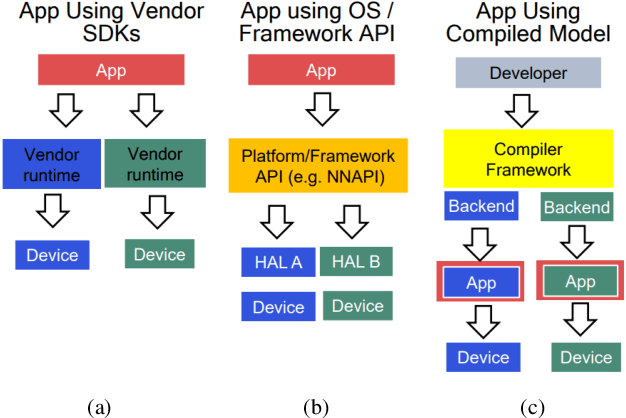
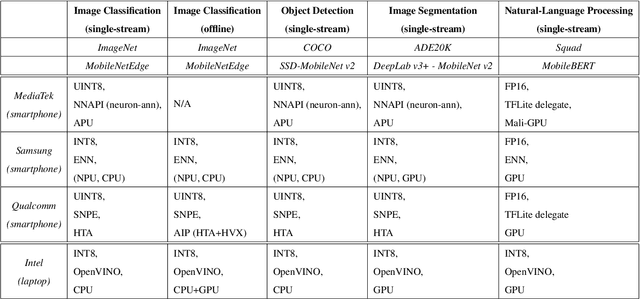
MLPerf Mobile is the first industry-standard open-source mobile benchmark developed by industry members and academic researchers to allow performance/accuracy evaluation of mobile devices with different AI chips and software stacks. The benchmark draws from the expertise of leading mobile-SoC vendors, ML-framework providers, and model producers. In this paper, we motivate the drive to demystify mobile-AI performance and present MLPerf Mobile's design considerations, architecture, and implementation. The benchmark comprises a suite of models that operate under standard models, data sets, quality metrics, and run rules. For the first iteration, we developed an app to provide an "out-of-the-box" inference-performance benchmark for computer vision and natural-language processing on mobile devices. MLPerf Mobile can serve as a framework for integrating future models, for customizing quality-target thresholds to evaluate system performance, for comparing software frameworks, and for assessing heterogeneous-hardware capabilities for machine learning, all fairly and faithfully with fully reproducible results.
MLPerf Inference Benchmark
Nov 06, 2019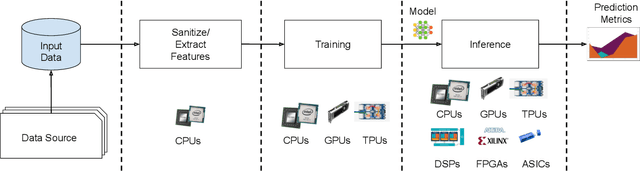
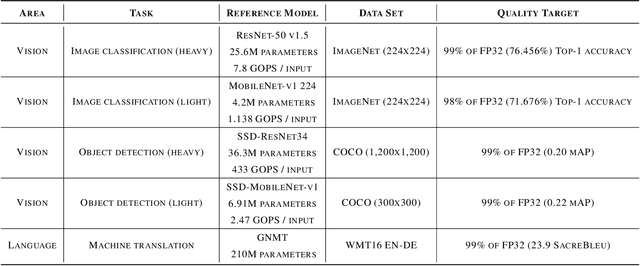
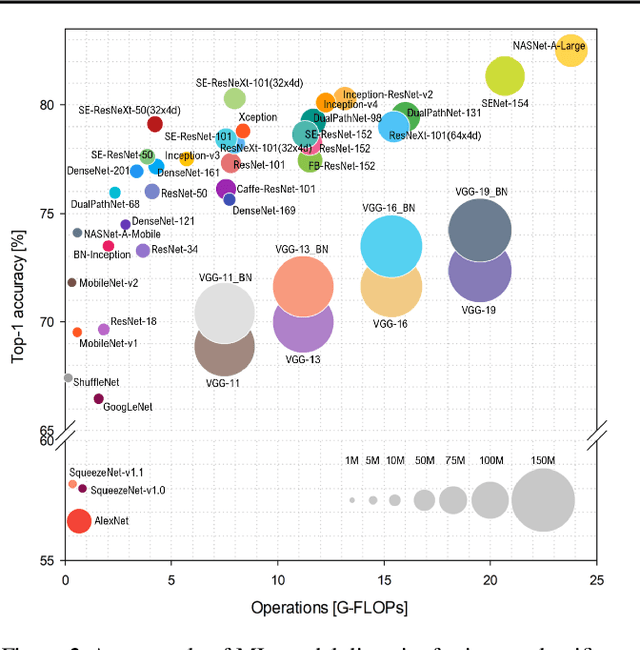
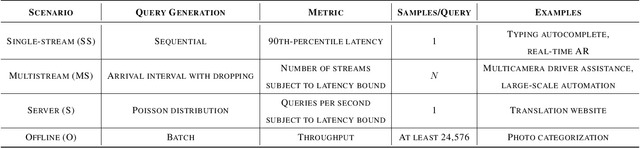
Machine-learning (ML) hardware and software system demand is burgeoning. Driven by ML applications, the number of different ML inference systems has exploded. Over 100 organizations are building ML inference chips, and the systems that incorporate existing models span at least three orders of magnitude in power consumption and four orders of magnitude in performance; they range from embedded devices to data-center solutions. Fueling the hardware are a dozen or more software frameworks and libraries. The myriad combinations of ML hardware and ML software make assessing ML-system performance in an architecture-neutral, representative, and reproducible manner challenging. There is a clear need for industry-wide standard ML benchmarking and evaluation criteria. MLPerf Inference answers that call. Driven by more than 30 organizations as well as more than 200 ML engineers and practitioners, MLPerf implements a set of rules and practices to ensure comparability across systems with wildly differing architectures. In this paper, we present the method and design principles of the initial MLPerf Inference release. The first call for submissions garnered more than 600 inference-performance measurements from 14 organizations, representing over 30 systems that show a range of capabilities.
MLPerf Training Benchmark
Oct 30, 2019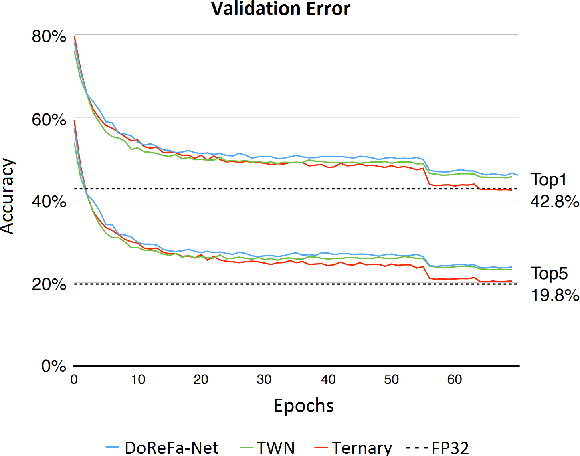
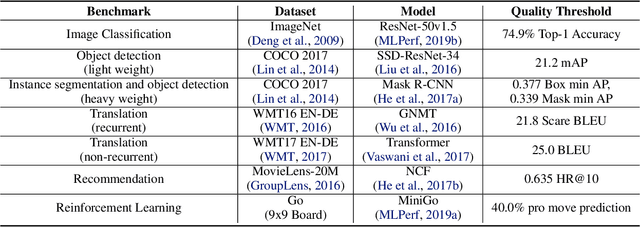
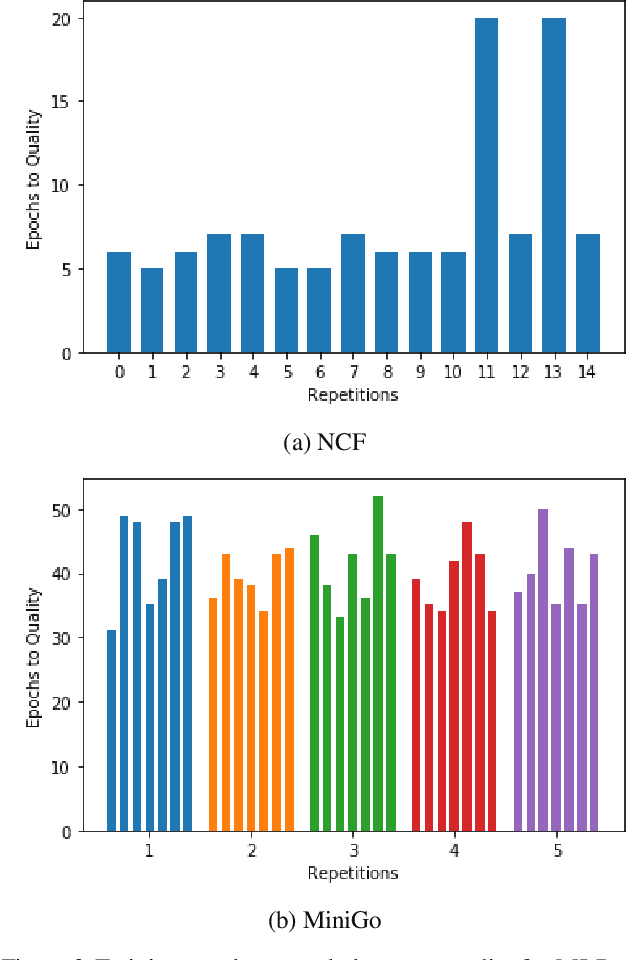
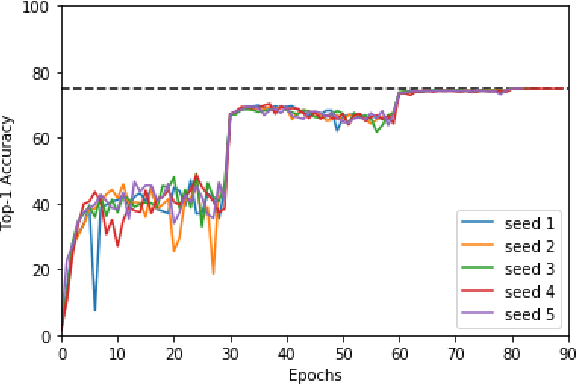
Machine learning is experiencing an explosion of software and hardware solutions, and needs industry-standard performance benchmarks to drive design and enable competitive evaluation. However, machine learning training presents a number of unique challenges to benchmarking that do not exist in other domains: (1) some optimizations that improve training throughput actually increase time to solution, (2) training is stochastic and time to solution has high variance, and (3) the software and hardware systems are so diverse that they cannot be fairly benchmarked with the same binary, code, or even hyperparameters. We present MLPerf, a machine learning benchmark that overcomes these challenges. We quantitatively evaluate the efficacy of MLPerf in driving community progress on performance and scalability across two rounds of results from multiple vendors.
Scale MLPerf-0.6 models on Google TPU-v3 Pods
Oct 02, 2019
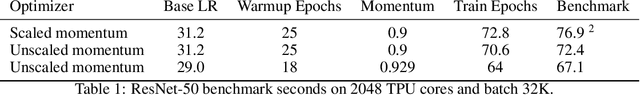

The recent submission of Google TPU-v3 Pods to the industry wide MLPerf v0.6 training benchmark demonstrates the scalability of a suite of industry relevant ML models. MLPerf defines a suite of models, datasets and rules to follow when benchmarking to ensure results are comparable across hardware, frameworks and companies. Using this suite of models, we discuss the optimizations and techniques including choice of optimizer, spatial partitioning and weight update sharding necessary to scale to 1024 TPU chips. Furthermore, we identify properties of models that make scaling them challenging, such as limited data parallelism and unscaled weights. These optimizations contribute to record performance in transformer, Resnet-50 and SSD in the Google MLPerf-0.6 submission.