 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNext-Scale Prediction: A Self-Supervised Approach for Real-World Image Denoising
Dec 24, 2025Self-supervised real-world image denoising remains a fundamental challenge, arising from the antagonistic trade-off between decorrelating spatially structured noise and preserving high-frequency details. Existing blind-spot network (BSN) methods rely on pixel-shuffle downsampling (PD) to decorrelate noise, but aggressive downsampling fragments fine structures, while milder downsampling fails to remove correlated noise. To address this, we introduce Next-Scale Prediction (NSP), a novel self-supervised paradigm that decouples noise decorrelation from detail preservation. NSP constructs cross-scale training pairs, where BSN takes low-resolution, fully decorrelated sub-images as input to predict high-resolution targets that retain fine details. As a by-product, NSP naturally supports super-resolution of noisy images without retraining or modification. Extensive experiments demonstrate that NSP achieves state-of-the-art self-supervised denoising performance on real-world benchmarks, significantly alleviating the long-standing conflict between noise decorrelation and detail preservation.
Branch Learning in MRI: More Data, More Models, More Training
Dec 23, 2025We investigated two complementary strategies for multicontrast cardiac MR reconstruction: physics-consistent data-space augmentation (DualSpaceCMR) and parameter-efficient capacity scaling via VQPrompt and Moero. DualSpaceCMR couples image-level transforms with kspace noise and motion simulations while preserving forwardmodel consistency. VQPrompt adds a lightweight bottleneck prompt; Moero embeds a sparse mixture of experts within a deep unrolled network with histogram-based routing. In the multivendor, multisite CMRxRecon25 benchmark, we evaluate fewshot and out-of-distribution generalization. On small datasets, k-space motion-plus-noise improves reconstruction; on the large benchmark it degrades performance, revealing sensitivity to augmentation ratio and schedule. VQPrompt produces modest and consistent gains with negligible memory overhead. Moero continues to improve after early plateaus and maintains baseline-like fewshot and out-of-distribution behavior despite mild overfitting, but sparse routing lowers PyTorch throughput and makes wall clock time the main bottleneck. These results motivate scale-aware augmentation and suggest prompt-based capacity scaling as a practical path, while efficiency improvements are crucial for sparse expert models.
Conditional Representation Learning for Customized Tasks
Oct 06, 2025



Conventional representation learning methods learn a universal representation that primarily captures dominant semantics, which may not always align with customized downstream tasks. For instance, in animal habitat analysis, researchers prioritize scene-related features, whereas universal embeddings emphasize categorical semantics, leading to suboptimal results. As a solution, existing approaches resort to supervised fine-tuning, which however incurs high computational and annotation costs. In this paper, we propose Conditional Representation Learning (CRL), aiming to extract representations tailored to arbitrary user-specified criteria. Specifically, we reveal that the semantics of a space are determined by its basis, thereby enabling a set of descriptive words to approximate the basis for a customized feature space. Building upon this insight, given a user-specified criterion, CRL first employs a large language model (LLM) to generate descriptive texts to construct the semantic basis, then projects the image representation into this conditional feature space leveraging a vision-language model (VLM). The conditional representation better captures semantics for the specific criterion, which could be utilized for multiple customized tasks. Extensive experiments on classification and retrieval tasks demonstrate the superiority and generality of the proposed CRL. The code is available at https://github.com/XLearning-SCU/2025-NeurIPS-CRL.
DUDE: Diffusion-Based Unsupervised Cross-Domain Image Retrieval
Sep 04, 2025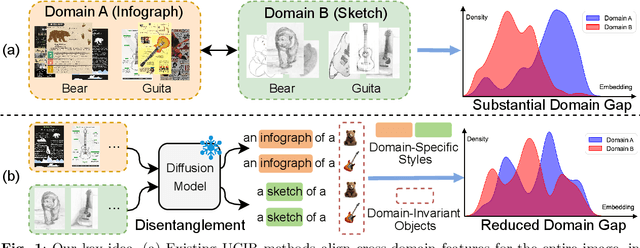



Unsupervised cross-domain image retrieval (UCIR) aims to retrieve images of the same category across diverse domains without relying on annotations. Existing UCIR methods, which align cross-domain features for the entire image, often struggle with the domain gap, as the object features critical for retrieval are frequently entangled with domain-specific styles. To address this challenge, we propose DUDE, a novel UCIR method building upon feature disentanglement. In brief, DUDE leverages a text-to-image generative model to disentangle object features from domain-specific styles, thus facilitating semantical image retrieval. To further achieve reliable alignment of the disentangled object features, DUDE aligns mutual neighbors from within domains to across domains in a progressive manner. Extensive experiments demonstrate that DUDE achieves state-of-the-art performance across three benchmark datasets over 13 domains. The code will be released.
SSG-Dit: A Spatial Signal Guided Framework for Controllable Video Generation
Aug 23, 2025Controllable video generation aims to synthesize video content that aligns precisely with user-provided conditions, such as text descriptions and initial images. However, a significant challenge persists in this domain: existing models often struggle to maintain strong semantic consistency, frequently generating videos that deviate from the nuanced details specified in the prompts. To address this issue, we propose SSG-DiT (Spatial Signal Guided Diffusion Transformer), a novel and efficient framework for high-fidelity controllable video generation. Our approach introduces a decoupled two-stage process. The first stage, Spatial Signal Prompting, generates a spatially aware visual prompt by leveraging the rich internal representations of a pre-trained multi-modal model. This prompt, combined with the original text, forms a joint condition that is then injected into a frozen video DiT backbone via our lightweight and parameter-efficient SSG-Adapter. This unique design, featuring a dual-branch attention mechanism, allows the model to simultaneously harness its powerful generative priors while being precisely steered by external spatial signals. Extensive experiments demonstrate that SSG-DiT achieves state-of-the-art performance, outperforming existing models on multiple key metrics in the VBench benchmark, particularly in spatial relationship control and overall consistency.
AI-Driven Collaborative Satellite Object Detection for Space Sustainability
Aug 01, 2025The growing density of satellites in low-Earth orbit (LEO) presents serious challenges to space sustainability, primarily due to the increased risk of in-orbit collisions. Traditional ground-based tracking systems are constrained by latency and coverage limitations, underscoring the need for onboard, vision-based space object detection (SOD) capabilities. In this paper, we propose a novel satellite clustering framework that enables the collaborative execution of deep learning (DL)-based SOD tasks across multiple satellites. To support this approach, we construct a high-fidelity dataset simulating imaging scenarios for clustered satellite formations. A distance-aware viewpoint selection strategy is introduced to optimize detection performance, and recent DL models are used for evaluation. Experimental results show that the clustering-based method achieves competitive detection accuracy compared to single-satellite and existing approaches, while maintaining a low size, weight, and power (SWaP) footprint. These findings underscore the potential of distributed, AI-enabled in-orbit systems to enhance space situational awareness and contribute to long-term space sustainability.
Robust Duality Learning for Unsupervised Visible-Infrared Person Re-Identfication
May 05, 2025
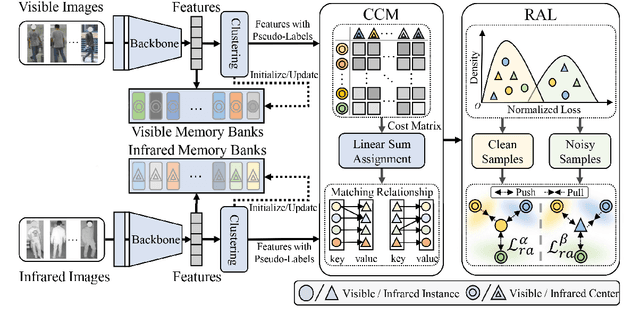


Unsupervised visible-infrared person re-identification (UVI-ReID) aims to retrieve pedestrian images across different modalities without costly annotations, but faces challenges due to the modality gap and lack of supervision. Existing methods often adopt self-training with clustering-generated pseudo-labels but implicitly assume these labels are always correct. In practice, however, this assumption fails due to inevitable pseudo-label noise, which hinders model learning. To address this, we introduce a new learning paradigm that explicitly considers Pseudo-Label Noise (PLN), characterized by three key challenges: noise overfitting, error accumulation, and noisy cluster correspondence. To this end, we propose a novel Robust Duality Learning framework (RoDE) for UVI-ReID to mitigate the effects of noisy pseudo-labels. First, to combat noise overfitting, a Robust Adaptive Learning mechanism (RAL) is proposed to dynamically emphasize clean samples while down-weighting noisy ones. Second, to alleviate error accumulation-where the model reinforces its own mistakes-RoDE employs dual distinct models that are alternately trained using pseudo-labels from each other, encouraging diversity and preventing collapse. However, this dual-model strategy introduces misalignment between clusters across models and modalities, creating noisy cluster correspondence. To resolve this, we introduce Cluster Consistency Matching (CCM), which aligns clusters across models and modalities by measuring cross-cluster similarity. Extensive experiments on three benchmarks demonstrate the effectiveness of RoDE.
Toward Onboard AI-Enabled Solutions to Space Object Detection for Space Sustainability
May 03, 2025



The rapid expansion of advanced low-Earth orbit (LEO) satellites in large constellations is positioning space assets as key to the future, enabling global internet access and relay systems for deep space missions. A solution to the challenge is effective space object detection (SOD) for collision assessment and avoidance. In SOD, an LEO satellite must detect other satellites and objects with high precision and minimal delay. This paper investigates the feasibility and effectiveness of employing vision sensors for SOD tasks based on deep learning (DL) models. It introduces models based on the Squeeze-and-Excitation (SE) layer, Vision Transformer (ViT), and the Generalized Efficient Layer Aggregation Network (GELAN) and evaluates their performance under SOD scenarios. Experimental results show that the proposed models achieve mean average precision at intersection over union threshold 0.5 (mAP50) scores of up to 0.751 and mean average precision averaged over intersection over union thresholds from 0.5 to 0.95 (mAP50:95) scores of up to 0.280. Compared to the baseline GELAN-t model, the proposed GELAN-ViT-SE model increases the average mAP50 from 0.721 to 0.751, improves the mAP50:95 from 0.266 to 0.274, reduces giga floating point operations (GFLOPs) from 7.3 to 5.6, and lowers peak power consumption from 2080.7 mW to 2028.7 mW by 2.5\%.
Rotational ultrasound and photoacoustic tomography of the human body
Apr 22, 2025Imaging the human body's morphological and angiographic information is essential for diagnosing, monitoring, and treating medical conditions. Ultrasonography performs the morphological assessment of the soft tissue based on acoustic impedance variations, whereas photoacoustic tomography (PAT) can visualize blood vessels based on intrinsic hemoglobin absorption. Three-dimensional (3D) panoramic imaging of the vasculature is generally not practical in conventional ultrasonography with limited field-of-view (FOV) probes, and PAT does not provide sufficient scattering-based soft tissue morphological contrast. Complementing each other, fast panoramic rotational ultrasound tomography (RUST) and PAT are integrated for hybrid rotational ultrasound and photoacoustic tomography (RUS-PAT), which obtains 3D ultrasound structural and PAT angiographic images of the human body quasi-simultaneously. The RUST functionality is achieved in a cost-effective manner using a single-element ultrasonic transducer for ultrasound transmission and rotating arc-shaped arrays for 3D panoramic detection. RUST is superior to conventional ultrasonography, which either has a limited FOV with a linear array or is high-cost with a hemispherical array that requires both transmission and receiving. By switching the acoustic source to a light source, the system is conveniently converted to PAT mode to acquire angiographic images in the same region. Using RUS-PAT, we have successfully imaged the human head, breast, hand, and foot with a 10 cm diameter FOV, submillimeter isotropic resolution, and 10 s imaging time for each modality. The 3D RUS-PAT is a powerful tool for high-speed, 3D, dual-contrast imaging of the human body with potential for rapid clinical translation.
LLaVA-ReID: Selective Multi-image Questioner for Interactive Person Re-Identification
Apr 15, 2025

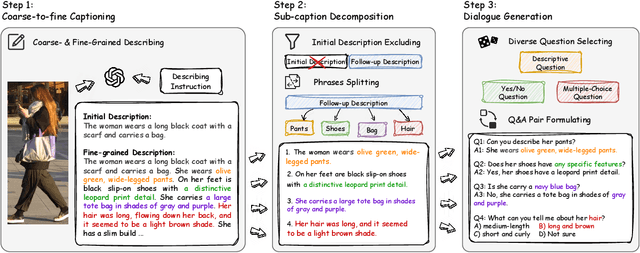

Traditional text-based person ReID assumes that person descriptions from witnesses are complete and provided at once. However, in real-world scenarios, such descriptions are often partial or vague. To address this limitation, we introduce a new task called interactive person re-identification (Inter-ReID). Inter-ReID is a dialogue-based retrieval task that iteratively refines initial descriptions through ongoing interactions with the witnesses. To facilitate the study of this new task, we construct a dialogue dataset that incorporates multiple types of questions by decomposing fine-grained attributes of individuals. We further propose LLaVA-ReID, a question model that generates targeted questions based on visual and textual contexts to elicit additional details about the target person. Leveraging a looking-forward strategy, we prioritize the most informative questions as supervision during training. Experimental results on both Inter-ReID and text-based ReID benchmarks demonstrate that LLaVA-ReID significantly outperforms baselines.