 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$R_\text{dm}$: Re-conceptualizing Distribution Matching as a Reward for Diffusion Distillation
Mar 31, 2026Diffusion models achieve state-of-the-art generative performance but are fundamentally bottlenecked by their slow, iterative sampling process. While diffusion distillation techniques enable high-fidelity, few-step generation, traditional objectives often restrict the student's performance by anchoring it solely to the teacher. Recent approaches have attempted to break this ceiling by integrating Reinforcement Learning (RL), typically through a simple summation of distillation and RL objectives. In this work, we propose a novel paradigm by re-conceptualizing distribution matching as a reward, denoted as $R_\text{dm}$. This unified perspective bridges the algorithmic gap between Diffusion Matching Distillation (DMD) and RL, providing several primary benefits. (1) Enhanced Optimization Stability: We introduce Group Normalized Distribution Matching (GNDM), which adapts standard RL group normalization to stabilize $R_\text{dm}$ estimation. By leveraging group-mean statistics, GNDM establishes a more robust and effective optimization direction. (2) Seamless Reward Integration: Our reward-centric formulation inherently supports adaptive weighting mechanisms, allowing for the fluid combination of DMD with external reward models. (3) Improved Sampling Efficiency: By aligning with RL principles, the framework readily incorporates Importance Sampling (IS), leading to a significant boost in sampling efficiency. Extensive experiments demonstrate that GNDM outperforms vanilla DMD, reducing the FID by 1.87. Furthermore, our multi-reward variant, GNDMR, surpasses existing baselines by striking an optimal balance between aesthetic quality and fidelity, achieving a peak HPS of 30.37 and a low FID-SD of 12.21. Ultimately, $R_\text{dm}$ provides a flexible, stable, and efficient framework for real-time, high-fidelity synthesis. Codes are coming soon.
Kling-MotionControl Technical Report
Mar 03, 2026Character animation aims to generate lifelike videos by transferring motion dynamics from a driving video to a reference image. Recent strides in generative models have paved the way for high-fidelity character animation. In this work, we present Kling-MotionControl, a unified DiT-based framework engineered specifically for robust, precise, and expressive holistic character animation. Leveraging a divide-and-conquer strategy within a cohesive system, the model orchestrates heterogeneous motion representations tailored to the distinct characteristics of body, face, and hands, effectively reconciling large-scale structural stability with fine-grained articulatory expressiveness. To ensure robust cross-identity generalization, we incorporate adaptive identity-agnostic learning, facilitating natural motion retargeting for diverse characters ranging from realistic humans to stylized cartoons. Simultaneously, we guarantee faithful appearance preservation through meticulous identity injection and fusion designs, further supported by a subject library mechanism that leverages comprehensive reference contexts. To ensure practical utility, we implement an advanced acceleration framework utilizing multi-stage distillation, boosting inference speed by over 10x. Kling-MotionControl distinguishes itself through intelligent semantic motion understanding and precise text responsiveness, allowing for flexible control beyond visual inputs. Human preference evaluations demonstrate that Kling-MotionControl delivers superior performance compared to leading commercial and open-source solutions, achieving exceptional fidelity in holistic motion control, open domain generalization, and visual quality and coherence. These results establish Kling-MotionControl as a robust solution for high-quality, controllable, and lifelike character animation.
Kling-Omni Technical Report
Dec 18, 2025



We present Kling-Omni, a generalist generative framework designed to synthesize high-fidelity videos directly from multimodal visual language inputs. Adopting an end-to-end perspective, Kling-Omni bridges the functional separation among diverse video generation, editing, and intelligent reasoning tasks, integrating them into a holistic system. Unlike disjointed pipeline approaches, Kling-Omni supports a diverse range of user inputs, including text instructions, reference images, and video contexts, processing them into a unified multimodal representation to deliver cinematic-quality and highly-intelligent video content creation. To support these capabilities, we constructed a comprehensive data system that serves as the foundation for multimodal video creation. The framework is further empowered by efficient large-scale pre-training strategies and infrastructure optimizations for inference. Comprehensive evaluations reveal that Kling-Omni demonstrates exceptional capabilities in in-context generation, reasoning-based editing, and multimodal instruction following. Moving beyond a content creation tool, we believe Kling-Omni is a pivotal advancement toward multimodal world simulators capable of perceiving, reasoning, generating and interacting with the dynamic and complex worlds.
Preparing Lessons: Improve Knowledge Distillation with Better Supervision
Nov 18, 2019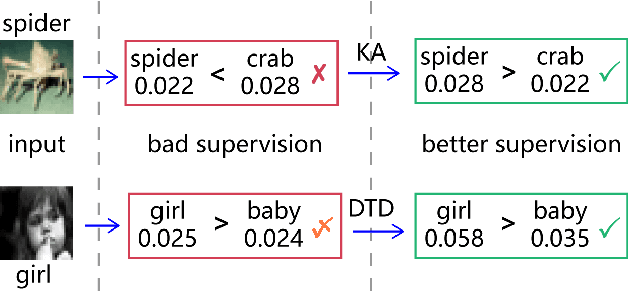
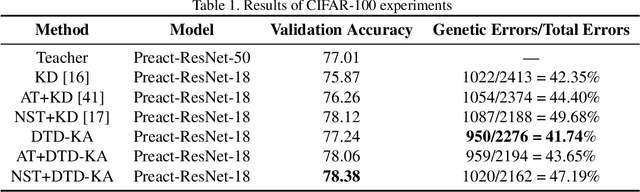
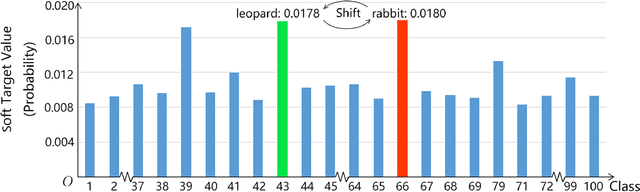
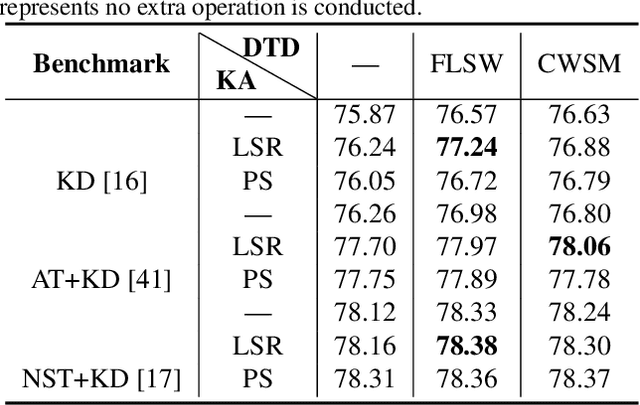
Knowledge distillation (KD) is widely used for training a compact model with the supervision of another large model, which could effectively improve the performance. Previous methods mainly focus on two aspects: 1) training the student to mimic representation space of the teacher; 2) training the model progressively or adding extra module like discriminator. Knowledge from teacher is useful, but it is still not exactly right compared with ground truth. Besides, overly uncertain supervision also influences the result. We introduce two novel approaches, Knowledge Adjustment (KA) and Dynamic Temperature Distillation (DTD), to penalize bad supervision and improve student model. Experiments on CIFAR-100, CINIC-10 and Tiny ImageNet show that our methods get encouraging performance compared with state-of-the-art methods. When combined with other KD-based methods, the performance will be further improved.