 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Image Retrieval: A Survey
Feb 03, 2021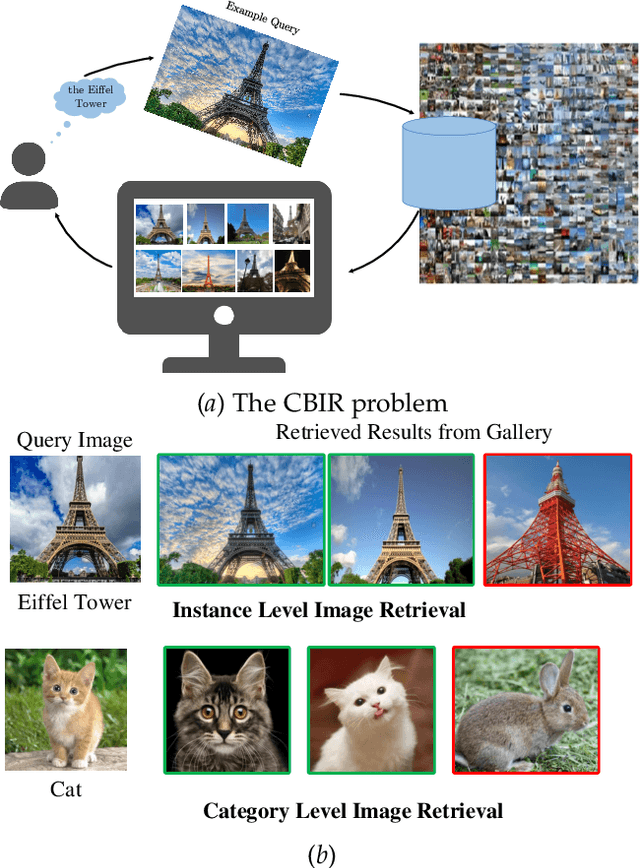
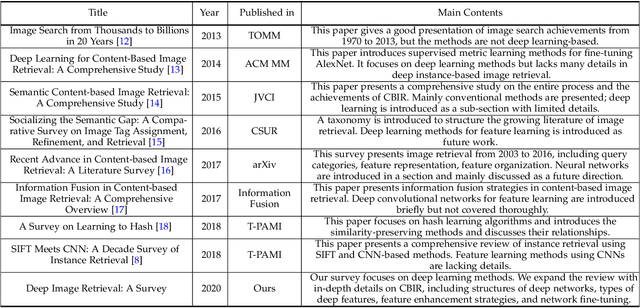
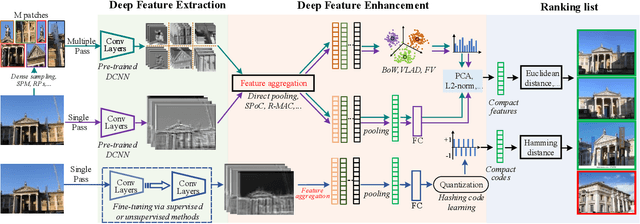
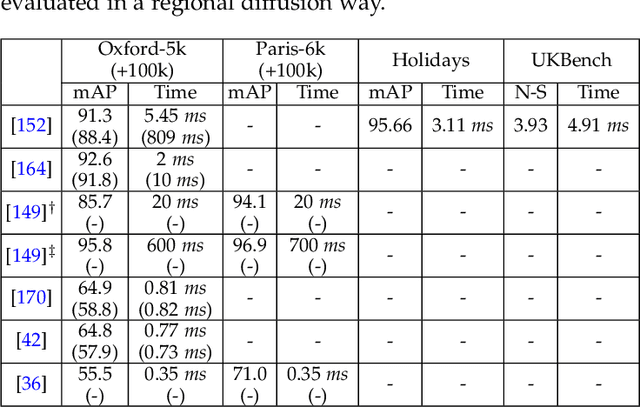
In recent years a vast amount of visual content has been generated and shared from various fields, such as social media platforms, medical images, and robotics. This abundance of content creation and sharing has introduced new challenges. In particular, searching databases for similar content, i.e.content based image retrieval (CBIR), is a long-established research area, and more efficient and accurate methods are needed for real time retrieval. Artificial intelligence has made progress in CBIR and has significantly facilitated the process of intelligent search. In this survey we organize and review recent CBIR works that are developed based on deep learning algorithms and techniques, including insights and techniques from recent papers. We identify and present the commonly-used benchmarks and evaluation methods used in the field. We collect common challenges and propose promising future directions. More specifically, we focus on image retrieval with deep learning and organize the state of the art methods according to the types of deep network structure, deep features, feature enhancement methods, and network fine-tuning strategies. Our survey considers a wide variety of recent methods, aiming to promote a global view of the field of instance-based CBIR.
A Review of Uncertainty Quantification in Deep Learning: Techniques, Applications and Challenges
Nov 17, 2020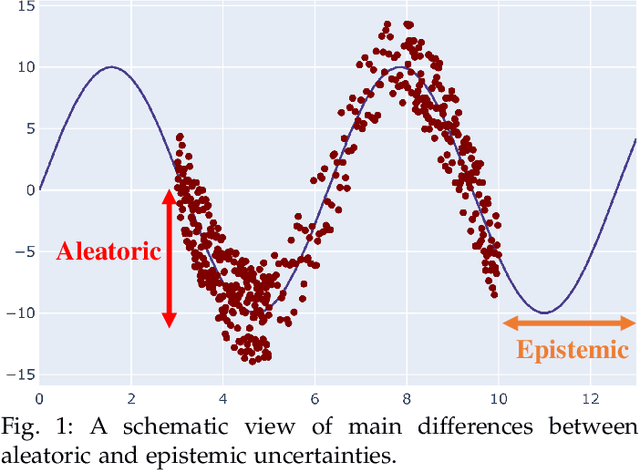
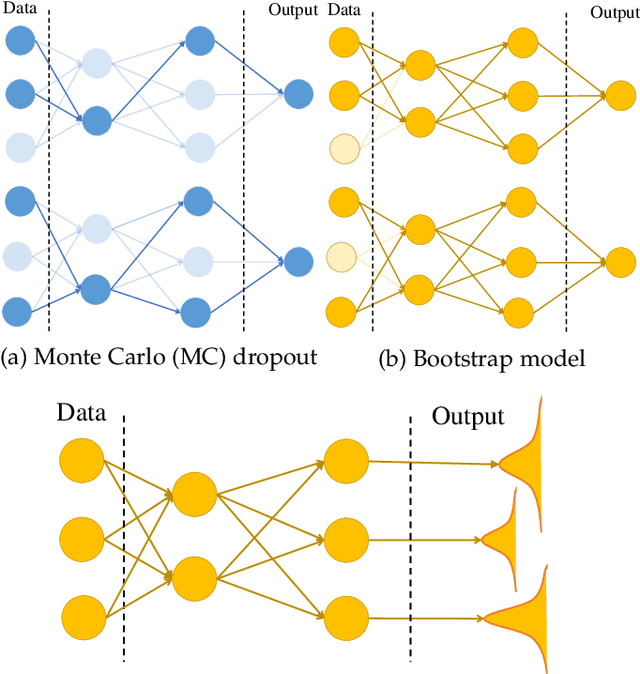
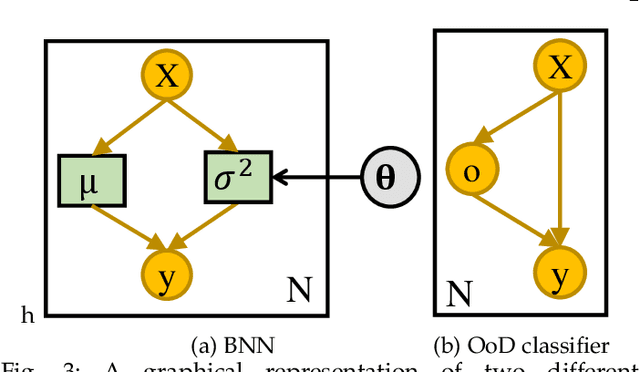
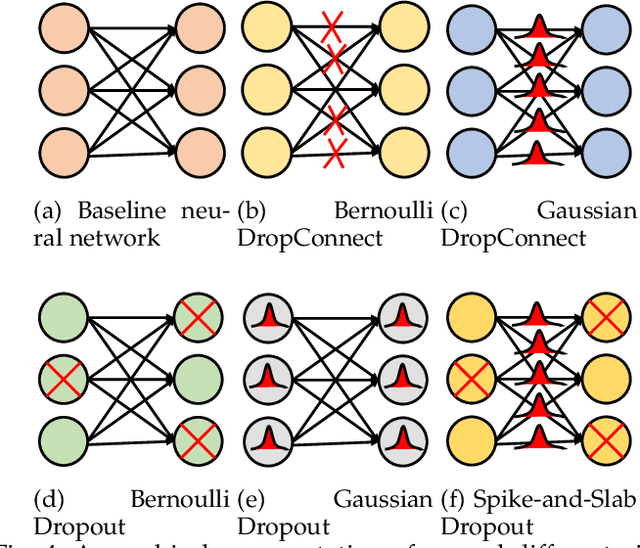
Uncertainty quantification (UQ) plays a pivotal role in reduction of uncertainties during both optimization and decision making processes. It can be applied to solve a variety of real-world applications in science and engineering. Bayesian approximation and ensemble learning techniques are two most widely-used UQ methods in the literature. In this regard, researchers have proposed different UQ methods and examined their performance in a variety of applications such as computer vision (e.g., self-driving cars and object detection), image processing (e.g., image restoration), medical image analysis (e.g., medical image classification and segmentation), natural language processing (e.g., text classification, social media texts and recidivism risk-scoring), bioinformatics, etc. This study reviews recent advances in UQ methods used in deep learning. Moreover, we also investigate the application of these methods in reinforcement learning (RL). Then, we outline a few important applications of UQ methods. Finally, we briefly highlight the fundamental research challenges faced by UQ methods and discuss the future research directions in this field.
Text Detection and Recognition in the Wild: A Review
Jun 30, 2020
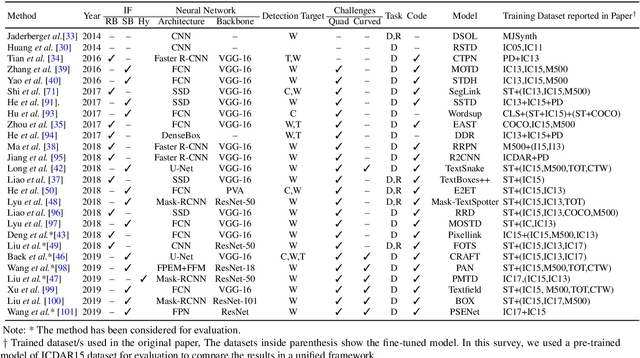
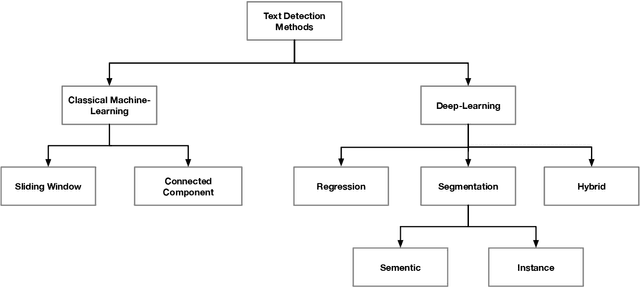

Detection and recognition of text in natural images are two main problems in the field of computer vision that have a wide variety of applications in analysis of sports videos, autonomous driving, industrial automation, to name a few. They face common challenging problems that are factors in how text is represented and affected by several environmental conditions. The current state-of-the-art scene text detection and/or recognition methods have exploited the witnessed advancement in deep learning architectures and reported a superior accuracy on benchmark datasets when tackling multi-resolution and multi-oriented text. However, there are still several remaining challenges affecting text in the wild images that cause existing methods to underperform due to there models are not able to generalize to unseen data and the insufficient labeled data. Thus, unlike previous surveys in this field, the objectives of this survey are as follows: first, offering the reader not only a review on the recent advancement in scene text detection and recognition, but also presenting the results of conducting extensive experiments using a unified evaluation framework that assesses pre-trained models of the selected methods on challenging cases, and applies the same evaluation criteria on these techniques. Second, identifying several existing challenges for detecting or recognizing text in the wild images, namely, in-plane-rotation, multi-oriented and multi-resolution text, perspective distortion, illumination reflection, partial occlusion, complex fonts, and special characters. Finally, the paper also presents insight into the potential research directions in this field to address some of the mentioned challenges that are still encountering scene text detection and recognition techniques.
Deep Neural Network Perception Models and Robust Autonomous Driving Systems
Mar 04, 2020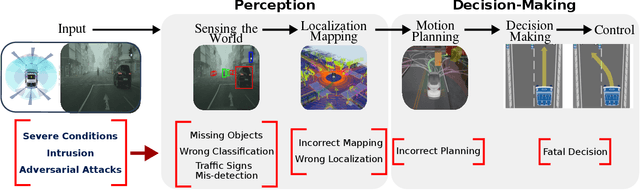


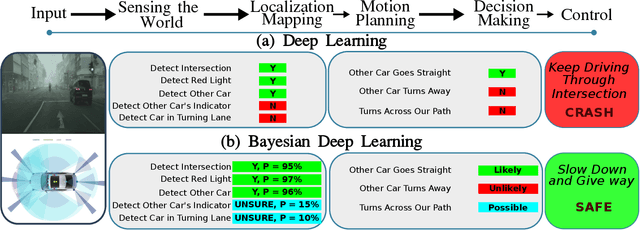
This paper analyzes the robustness of deep learning models in autonomous driving applications and discusses the practical solutions to address that.
Potential adversarial samples for white-box attacks
Dec 13, 2019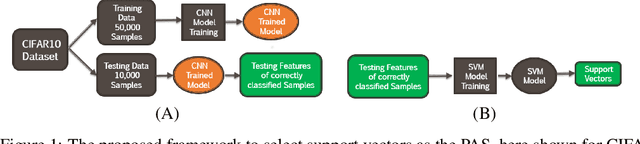
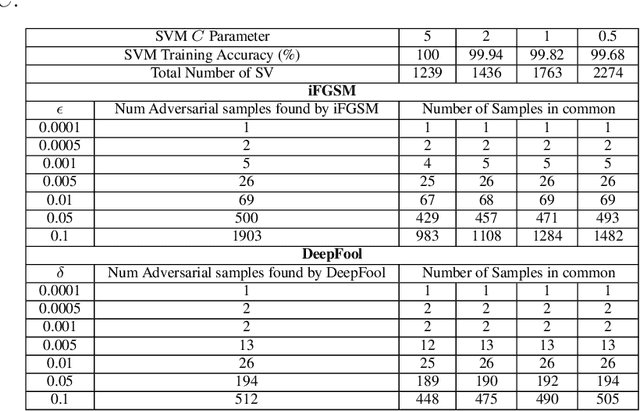
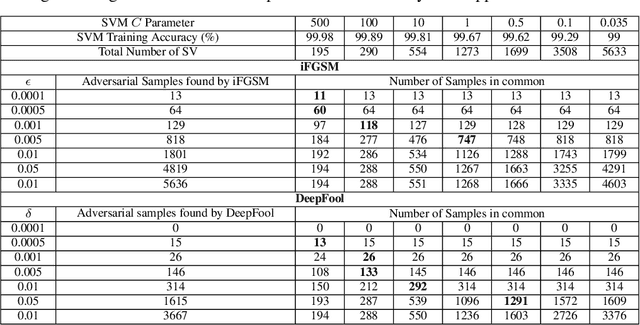
Deep convolutional neural networks can be highly vulnerable to small perturbations of their inputs, potentially a major issue or limitation on system robustness when using deep networks as classifiers. In this paper we propose a low-cost method to explore marginal sample data near trained classifier decision boundaries, thus identifying potential adversarial samples. By finding such adversarial samples it is possible to reduce the search space of adversarial attack algorithms while keeping a reasonable successful perturbation rate. In our developed strategy, the potential adversarial samples represent only 61% of the test data, but in fact cover more than 82% of the adversarial samples produced by iFGSM and 92% of the adversarial samples successfully perturbed by DeepFool on CIFAR10.
Assessing Architectural Similarity in Populations of Deep Neural Networks
Apr 19, 2019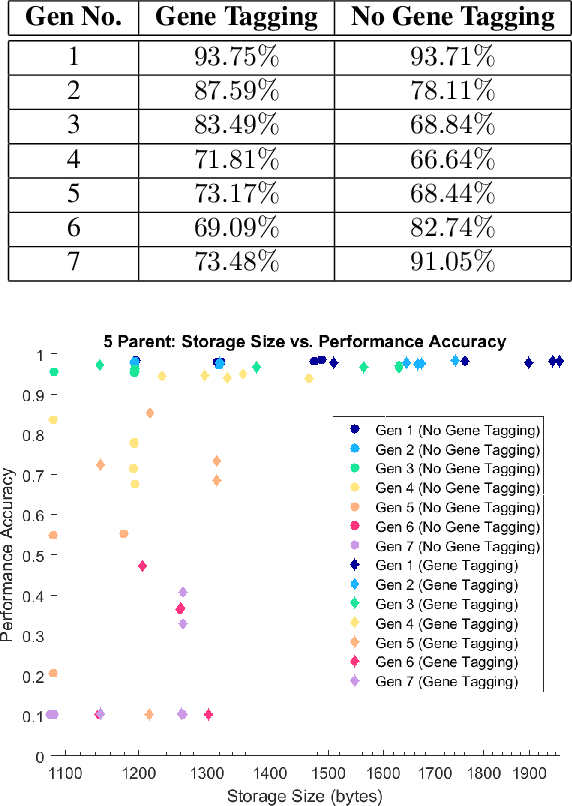
Evolutionary deep intelligence has recently shown great promise for producing small, powerful deep neural network models via the synthesis of increasingly efficient architectures over successive generations. Despite recent research showing the efficacy of multi-parent evolutionary synthesis, little has been done to directly assess architectural similarity between networks during the synthesis process for improved parent network selection. In this work, we present a preliminary study into quantifying architectural similarity via the percentage overlap of architectural clusters. Results show that networks synthesized using architectural alignment (via gene tagging) maintain higher architectural similarities within each generation, potentially restricting the search space of highly efficient network architectures.
ProstateGAN: Mitigating Data Bias via Prostate Diffusion Imaging Synthesis with Generative Adversarial Networks
Nov 21, 2018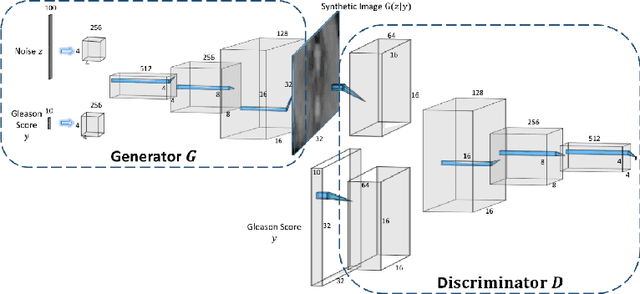

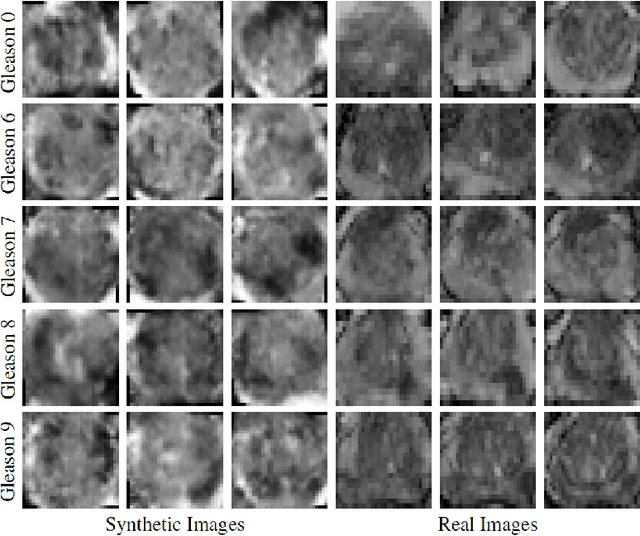
Generative Adversarial Networks (GANs) have shown considerable promise for mitigating the challenge of data scarcity when building machine learning-driven analysis algorithms. Specifically, a number of studies have shown that GAN-based image synthesis for data augmentation can aid in improving classification accuracy in a number of medical image analysis tasks, such as brain and liver image analysis. However, the efficacy of leveraging GANs for tackling prostate cancer analysis has not been previously explored. Motivated by this, in this study we introduce ProstateGAN, a GAN-based model for synthesizing realistic prostate diffusion imaging data. More specifically, in order to generate new diffusion imaging data corresponding to a particular cancer grade (Gleason score), we propose a conditional deep convolutional GAN architecture that takes Gleason scores into consideration during the training process. Experimental results show that high-quality synthetic prostate diffusion imaging data can be generated using the proposed ProstateGAN for specified Gleason scores.
Mitigating Architectural Mismatch During the Evolutionary Synthesis of Deep Neural Networks
Nov 19, 2018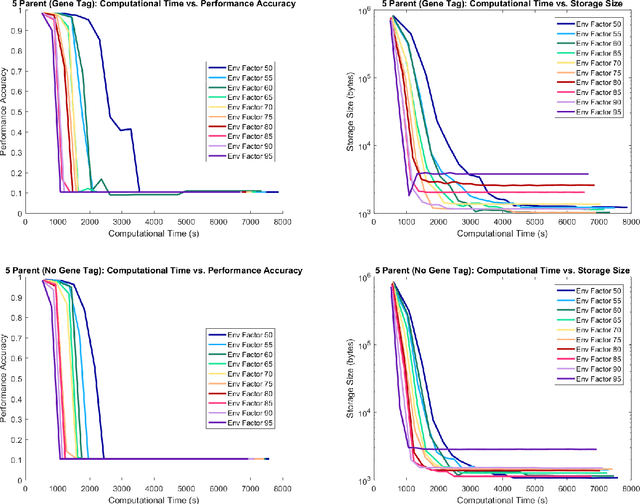

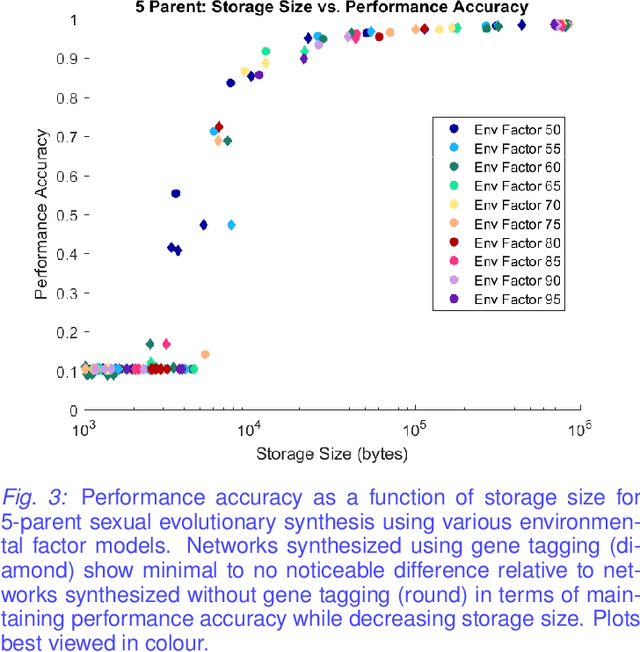
Evolutionary deep intelligence has recently shown great promise for producing small, powerful deep neural network models via the organic synthesis of increasingly efficient architectures over successive generations. Existing evolutionary synthesis processes, however, have allowed the mating of parent networks independent of architectural alignment, resulting in a mismatch of network structures. We present a preliminary study into the effects of architectural alignment during evolutionary synthesis using a gene tagging system. Surprisingly, the network architectures synthesized using the gene tagging approach resulted in slower decreases in performance accuracy and storage size; however, the resultant networks were comparable in size and performance accuracy to the non-gene tagging networks. Furthermore, we speculate that there is a noticeable decrease in network variability for networks synthesized with gene tagging, indicating that enforcing a like-with-like mating policy potentially restricts the exploration of the search space of possible network architectures.
From BoW to CNN: Two Decades of Texture Representation for Texture Classification
Oct 03, 2018

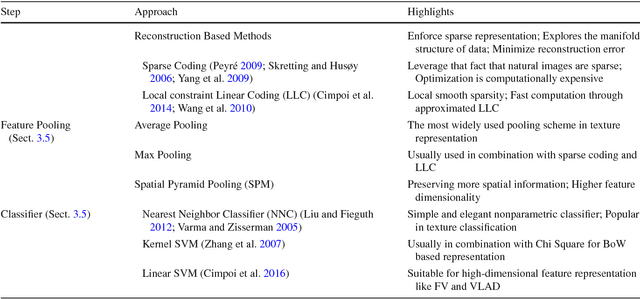
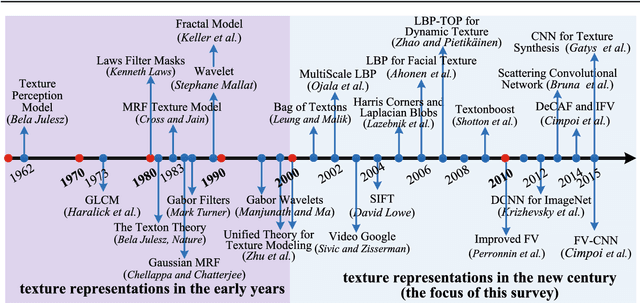
Texture is a fundamental characteristic of many types of images, and texture representation is one of the essential and challenging problems in computer vision and pattern recognition which has attracted extensive research attention. Since 2000, texture representations based on Bag of Words (BoW) and on Convolutional Neural Networks (CNNs) have been extensively studied with impressive performance. Given this period of remarkable evolution, this paper aims to present a comprehensive survey of advances in texture representation over the last two decades. More than 200 major publications are cited in this survey covering different aspects of the research, which includes (i) problem description; (ii) recent advances in the broad categories of BoW-based, CNN-based and attribute-based methods; and (iii) evaluation issues, specifically benchmark datasets and state of the art results. In retrospect of what has been achieved so far, the survey discusses open challenges and directions for future research.
Deep Learning for Generic Object Detection: A Survey
Sep 06, 2018
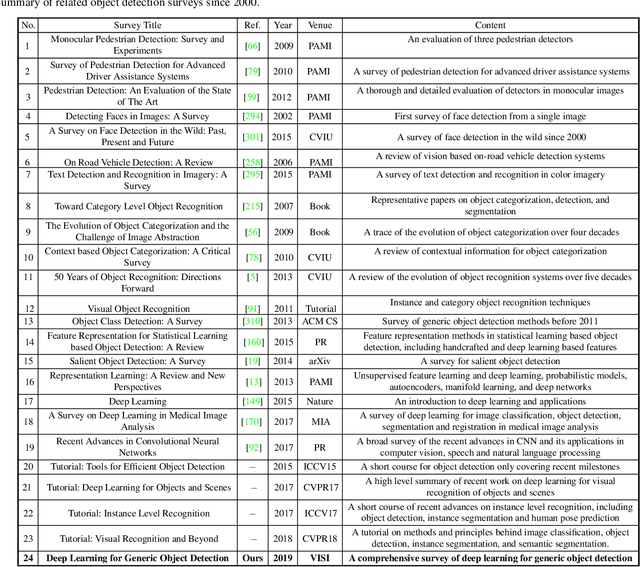


Generic object detection, aiming at locating object instances from a large number of predefined categories in natural images, is one of the most fundamental and challenging problems in computer vision. Deep learning techniques have emerged in recent years as powerful methods for learning feature representations directly from data, and have led to remarkable breakthroughs in the field of generic object detection. Given this time of rapid evolution, the goal of this paper is to provide a comprehensive survey of the recent achievements in this field brought by deep learning techniques. More than 250 key contributions are included in this survey, covering many aspects of generic object detection research: leading detection frameworks and fundamental subproblems including object feature representation, object proposal generation, context information modeling and training strategies; evaluation issues, specifically benchmark datasets, evaluation metrics, and state of the art performance. We finish by identifying promising directions for future research.