 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Loss Modelling for Unstructured Pruning
Jun 22, 2020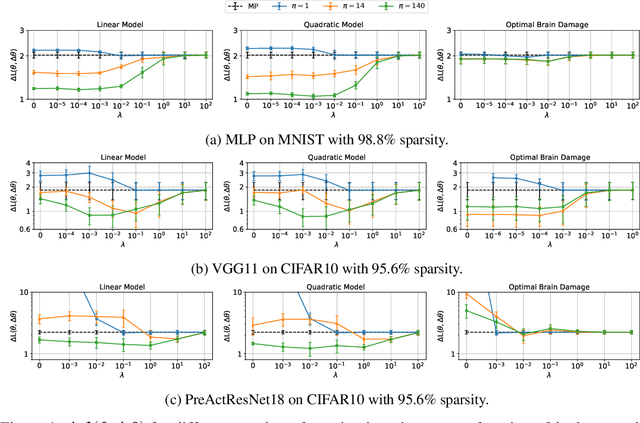
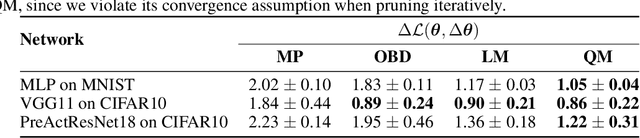

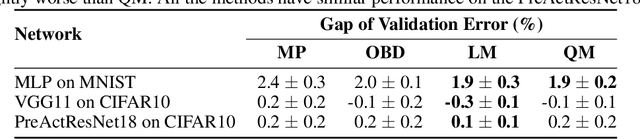
By removing parameters from deep neural networks, unstructured pruning methods aim at cutting down memory footprint and computational cost, while maintaining prediction accuracy. In order to tackle this otherwise intractable problem, many of these methods model the loss landscape using first or second order Taylor expansions to identify which parameters can be discarded. We revisit loss modelling for unstructured pruning: we show the importance of ensuring locality of the pruning steps. We systematically compare first and second order Taylor expansions and empirically show that both can reach similar levels of performance. Finally, we show that better preserving the original network function does not necessarily transfer to better performing networks after fine-tuning, suggesting that only considering the impact of pruning on the loss might not be a sufficient objective to design good pruning criteria.
Do sequence-to-sequence VAEs learn global features of sentences?
Apr 16, 2020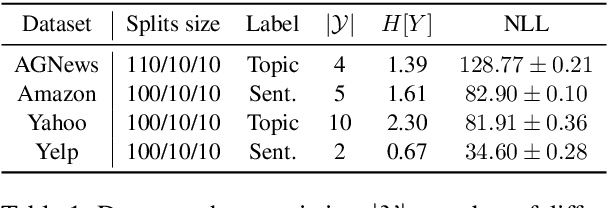
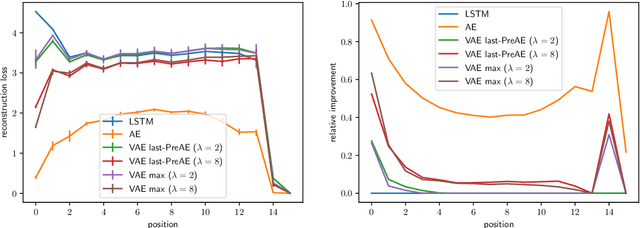
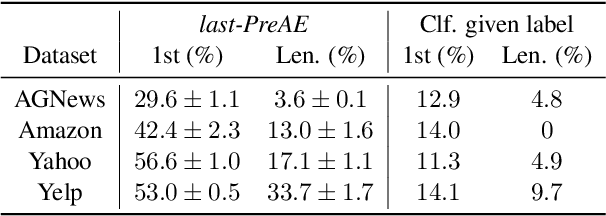
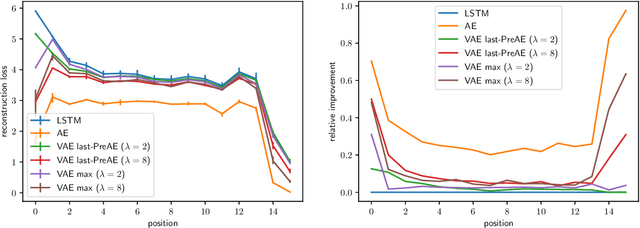
A longstanding goal in NLP is to compute global sentence representations. Such representations would be useful for sample-efficient semi-supervised learning and controllable text generation. To learn to represent global and local information separately, Bowman & al. (2016) proposed to train a sequence-to-sequence model with the variational auto-encoder (VAE) objective. What precisely is encoded in these latent variables expected to capture global features? We measure which words benefit most from the latent information by decomposing the reconstruction loss per position in the sentence. Using this method, we see that VAEs are prone to memorizing the first words and the sentence length, drastically limiting their usefulness. To alleviate this, we propose variants based on bag-of-words assumptions and language model pretraining. These variants learn latents that are more global: they are more predictive of topic or sentiment labels, and their reconstructions are more faithful to the labels of the original documents.
Stable Policy Optimization via Off-Policy Divergence Regularization
Mar 09, 2020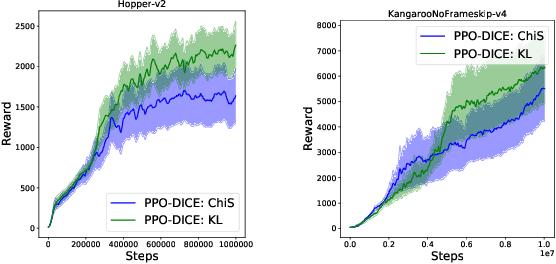
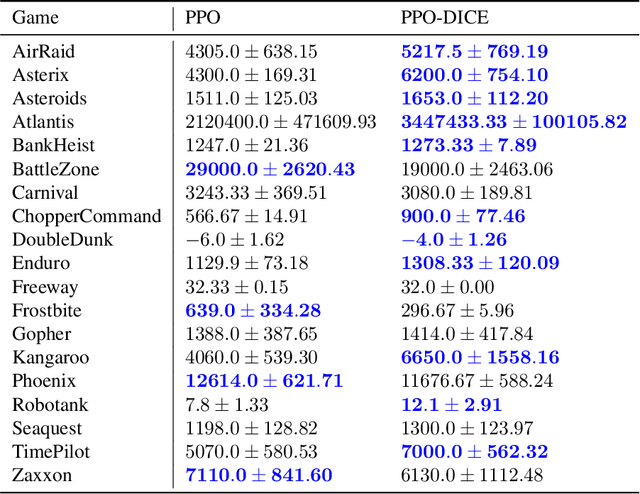
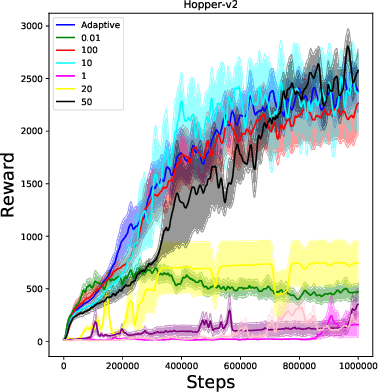
Trust Region Policy Optimization (TRPO) and Proximal Policy Optimization (PPO) are among the most successful policy gradient approaches in deep reinforcement learning (RL). While these methods achieve state-of-the-art performance across a wide range of challenging tasks, there is room for improvement in the stabilization of the policy learning and how the off-policy data are used. In this paper we revisit the theoretical foundations of these algorithms and propose a new algorithm which stabilizes the policy improvement through a proximity term that constrains the discounted state-action visitation distribution induced by consecutive policies to be close to one another. This proximity term, expressed in terms of the divergence between the visitation distributions, is learned in an off-policy and adversarial manner. We empirically show that our proposed method can have a beneficial effect on stability and improve final performance in benchmark high-dimensional control tasks.
An Empirical Study of Batch Normalization and Group Normalization in Conditional Computation
Jul 31, 2019


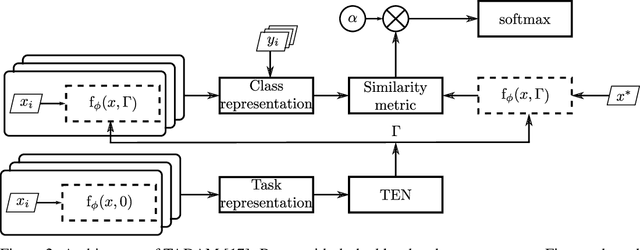
Batch normalization has been widely used to improve optimization in deep neural networks. While the uncertainty in batch statistics can act as a regularizer, using these dataset statistics specific to the training set impairs generalization in certain tasks. Recently, alternative methods for normalizing feature activations in neural networks have been proposed. Among them, group normalization has been shown to yield similar, in some domains even superior performance to batch normalization. All these methods utilize a learned affine transformation after the normalization operation to increase representational power. Methods used in conditional computation define the parameters of these transformations as learnable functions of conditioning information. In this work, we study whether and where the conditional formulation of group normalization can improve generalization compared to conditional batch normalization. We evaluate performances on the tasks of visual question answering, few-shot learning, and conditional image generation.
A Closer Look at the Optimization Landscapes of Generative Adversarial Networks
Jun 11, 2019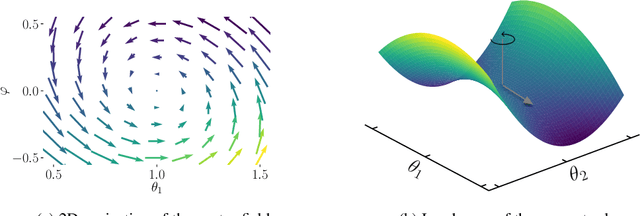
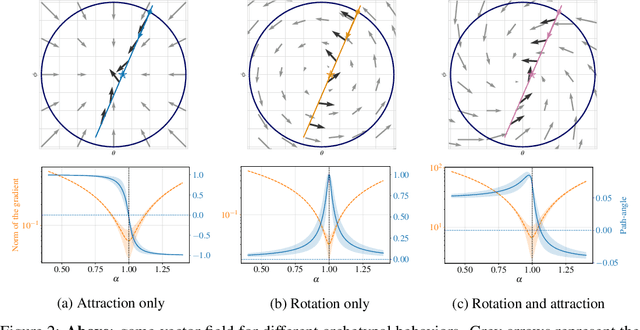
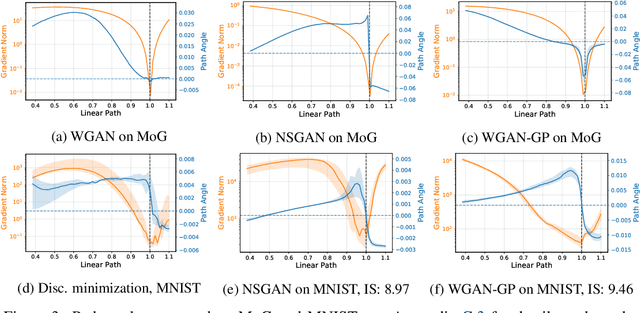
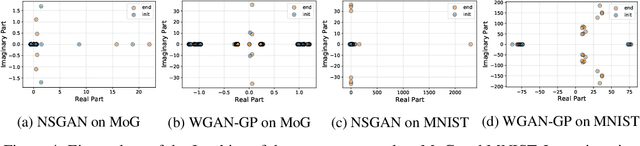
Generative adversarial networks have been very successful in generative modeling, however they remain relatively hard to optimize compared to standard deep neural networks. In this paper, we try to gain insight into the optimization of GANs by looking at the game vector field resulting from the concatenation of the gradient of both players. Based on this point of view, we propose visualization techniques that allow us to make the following empirical observations. First, the training of GANs suffers from rotational behavior around locally stable stationary points, which, as we show, corresponds to the presence of imaginary components in the eigenvalues of the Jacobian of the game. Secondly, GAN training seems to converge to a stable stationary point which is a saddle point for the generator loss, not a minimum, while still achieving excellent performance. This counter-intuitive yet persistent observation questions whether we actually need a Nash equilibrium to get good performance in GANs.
Stochastic Neural Network with Kronecker Flow
Jun 10, 2019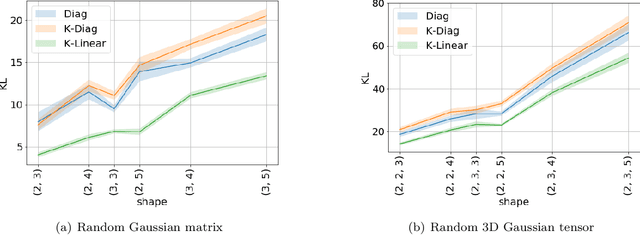



Recent advances in variational inference enable the modelling of highly structured joint distributions, but are limited in their capacity to scale to the high-dimensional setting of stochastic neural networks. This limitation motivates a need for scalable parameterizations of the noise generation process, in a manner that adequately captures the dependencies among the various parameters. In this work, we address this need and present the Kronecker Flow, a generalization of the Kronecker product to invertible mappings designed for stochastic neural networks. We apply our method to variational Bayesian neural networks on predictive tasks, PAC-Bayes generalization bound estimation, and approximate Thompson sampling in contextual bandits. In all setups, our methods prove to be competitive with existing methods and better than the baselines.
SVRG for Policy Evaluation with Fewer Gradient Evaluations
Jun 09, 2019
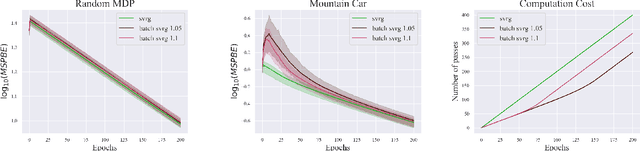
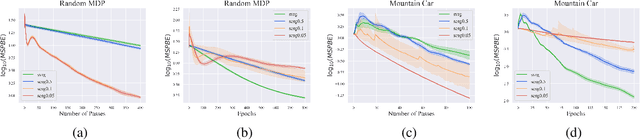
Stochastic variance-reduced gradient (SVRG) is an optimization method originally designed for tackling machine learning problems with a finite sum structure. SVRG was later shown to work for policy evaluation, a problem in reinforcement learning in which one aims to estimate the value function of a given policy. SVRG makes use of gradient estimates at two scales. At the slower scale, SVRG computes a full gradient over the whole dataset, which could lead to prohibitive computation costs. In this work, we show that two variants of SVRG for policy evaluation could significantly diminish the number of gradient calculations while preserving a linear convergence speed. More importantly, our theoretical result implies that one does not need to use the entire dataset in every epoch of SVRG when it is applied to policy evaluation with linear function approximation. Our experiments demonstrate large computational savings provided by the proposed methods.
Reducing Uncertainty in Undersampled MRI Reconstruction with Active Acquisition
Feb 08, 2019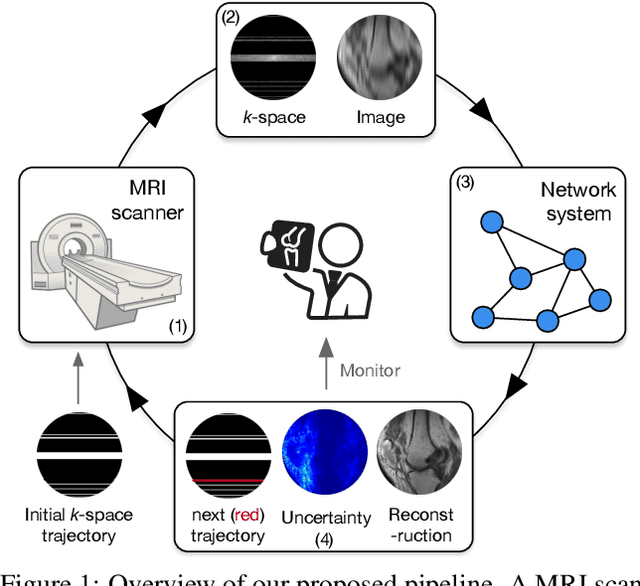
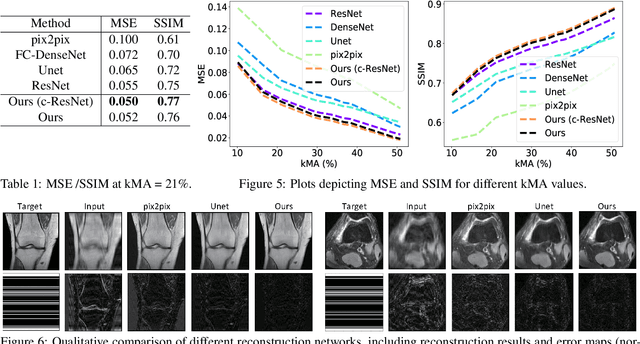
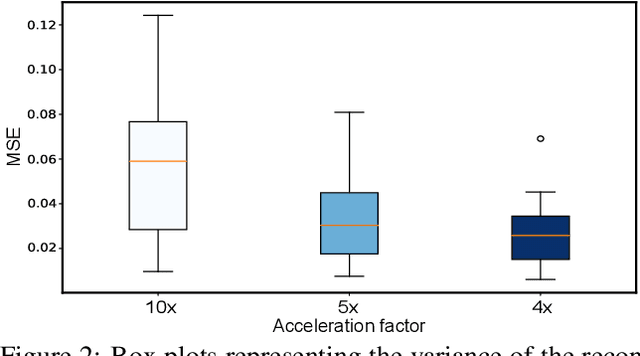
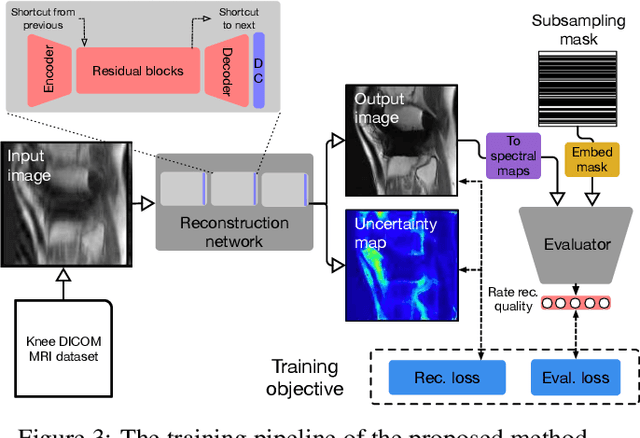
The goal of MRI reconstruction is to restore a high fidelity image from partially observed measurements. This partial view naturally induces reconstruction uncertainty that can only be reduced by acquiring additional measurements. In this paper, we present a novel method for MRI reconstruction that, at inference time, dynamically selects the measurements to take and iteratively refines the prediction in order to best reduce the reconstruction error and, thus, its uncertainty. We validate our method on a large scale knee MRI dataset, as well as on ImageNet. Results show that (1) our system successfully outperforms active acquisition baselines; (2) our uncertainty estimates correlate with error maps; and (3) our ResNet-based architecture surpasses standard pixel-to-pixel models in the task of MRI reconstruction. The proposed method not only shows high-quality reconstructions but also paves the road towards more applicable solutions for accelerating MRI.
fastMRI: An Open Dataset and Benchmarks for Accelerated MRI
Nov 21, 2018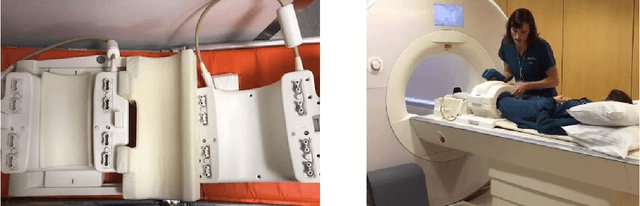
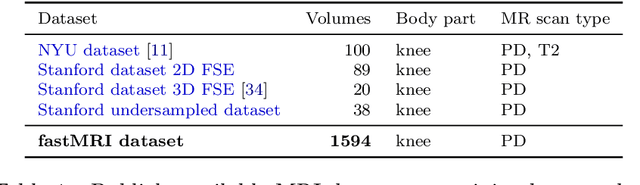
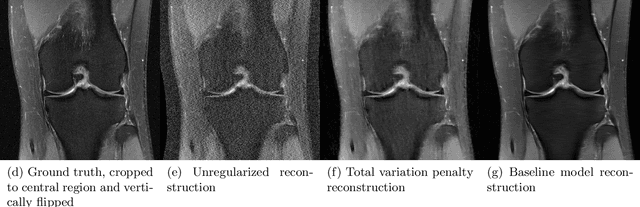
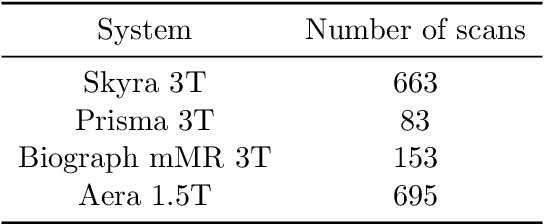
Accelerating Magnetic Resonance Imaging (MRI) by taking fewer measurements has the potential to reduce medical costs, minimize stress to patients and make MRI possible in applications where it is currently prohibitively slow or expensive. We introduce the fastMRI dataset, a large-scale collection of both raw MR measurements and clinical MR images, that can be used for training and evaluation of machine-learning approaches to MR image reconstruction. By introducing standardized evaluation criteria and a freely-accessible dataset, our goal is to help the community make rapid advances in the state of the art for MR image reconstruction. We also provide a self-contained introduction to MRI for machine learning researchers with no medical imaging background.
A Variational Inequality Perspective on Generative Adversarial Networks
Nov 02, 2018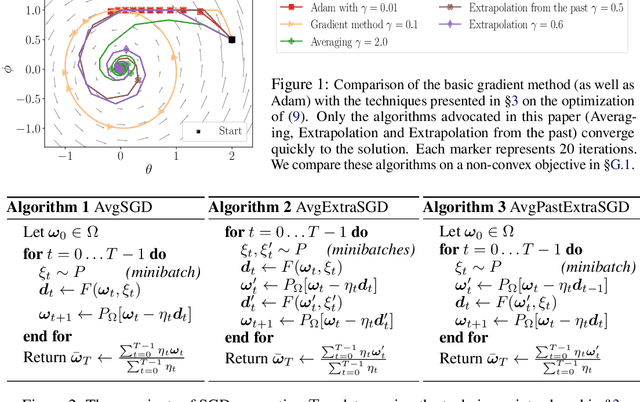
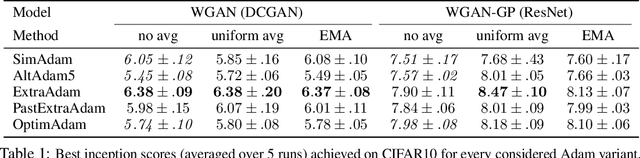
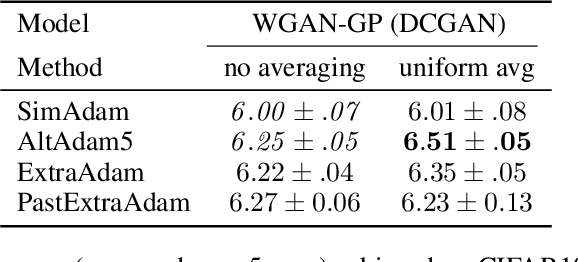
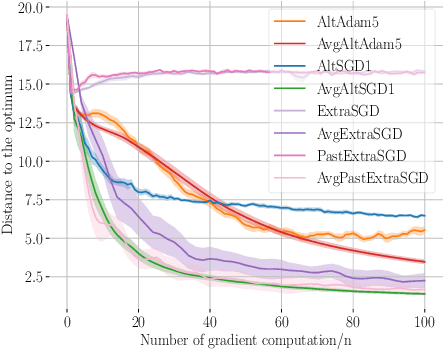
Generative adversarial networks (GANs) form a generative modeling approach known for producing appealing samples, but they are notably difficult to train. One common way to tackle this issue has been to propose new formulations of the GAN objective. Yet, surprisingly few studies have looked at optimization methods designed for this adversarial training. In this work, we cast GAN optimization problems in the general variational inequality framework. Tapping into the mathematical programming literature, we counter some common misconceptions about the difficulties of saddle point optimization and propose to extend techniques designed for variational inequalities to the training of GANs. We apply averaging, extrapolation and a novel computationally cheaper variant that we call extrapolation from the past to the stochastic gradient method (SGD) and Adam.