 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning GFlowNets from partial episodes for improved convergence and stability
Sep 30, 2022

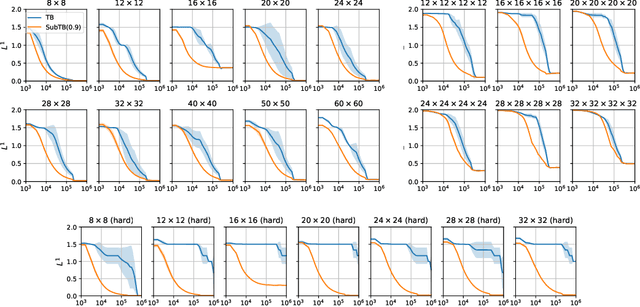
Generative flow networks (GFlowNets) are a family of algorithms for training a sequential sampler of discrete objects under an unnormalized target density and have been successfully used for various probabilistic modeling tasks. Existing training objectives for GFlowNets are either local to states or transitions, or propagate a reward signal over an entire sampling trajectory. We argue that these alternatives represent opposite ends of a gradient bias-variance tradeoff and propose a way to exploit this tradeoff to mitigate its harmful effects. Inspired by the TD($\lambda$) algorithm in reinforcement learning, we introduce subtrajectory balance or SubTB($\lambda$), a GFlowNet training objective that can learn from partial action subsequences of varying lengths. We show that SubTB($\lambda$) accelerates sampler convergence in previously studied and new environments and enables training GFlowNets in environments with longer action sequences and sparser reward landscapes than what was possible before. We also perform a comparative analysis of stochastic gradient dynamics, shedding light on the bias-variance tradeoff in GFlowNet training and the advantages of subtrajectory balance.
Do sequence-to-sequence VAEs learn global features of sentences?
Apr 16, 2020
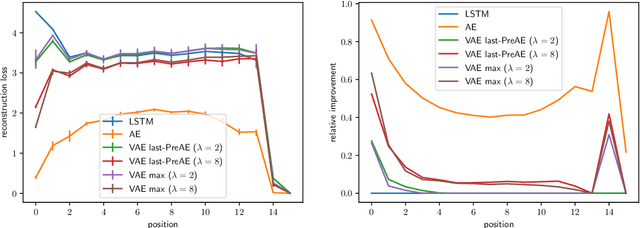
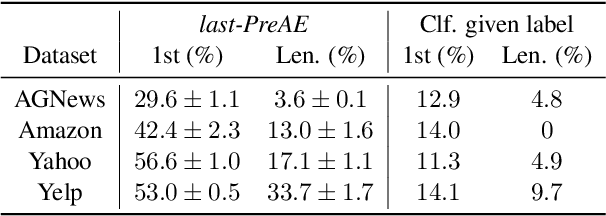
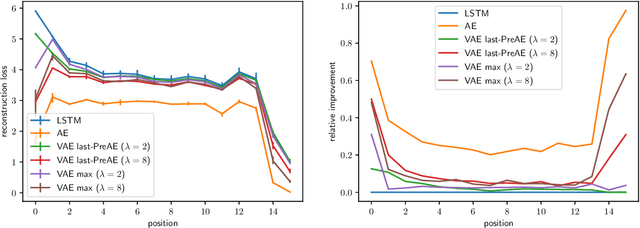
A longstanding goal in NLP is to compute global sentence representations. Such representations would be useful for sample-efficient semi-supervised learning and controllable text generation. To learn to represent global and local information separately, Bowman & al. (2016) proposed to train a sequence-to-sequence model with the variational auto-encoder (VAE) objective. What precisely is encoded in these latent variables expected to capture global features? We measure which words benefit most from the latent information by decomposing the reconstruction loss per position in the sentence. Using this method, we see that VAEs are prone to memorizing the first words and the sentence length, drastically limiting their usefulness. To alleviate this, we propose variants based on bag-of-words assumptions and language model pretraining. These variants learn latents that are more global: they are more predictive of topic or sentiment labels, and their reconstructions are more faithful to the labels of the original documents.
Learning to Compute Word Embeddings On the Fly
Mar 07, 2018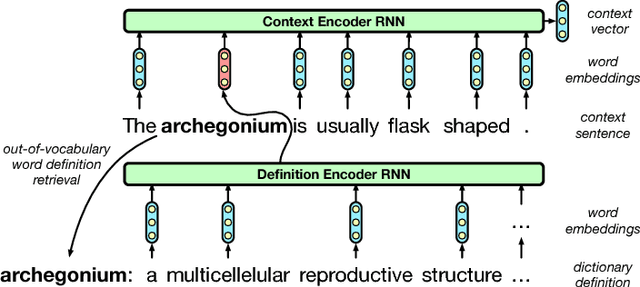
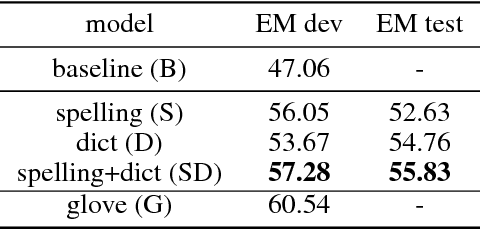
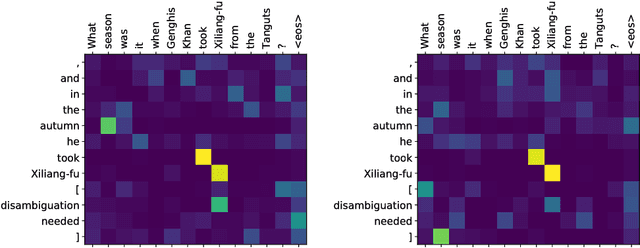
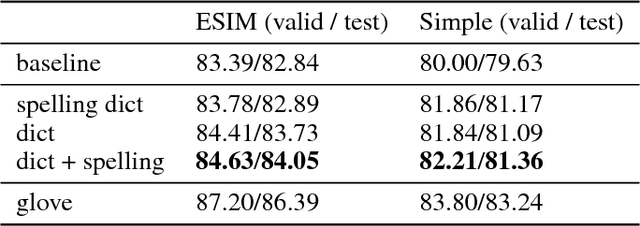
Words in natural language follow a Zipfian distribution whereby some words are frequent but most are rare. Learning representations for words in the "long tail" of this distribution requires enormous amounts of data. Representations of rare words trained directly on end tasks are usually poor, requiring us to pre-train embeddings on external data, or treat all rare words as out-of-vocabulary words with a unique representation. We provide a method for predicting embeddings of rare words on the fly from small amounts of auxiliary data with a network trained end-to-end for the downstream task. We show that this improves results against baselines where embeddings are trained on the end task for reading comprehension, recognizing textual entailment and language modeling.
Learning to Learn Neural Networks
Oct 19, 2016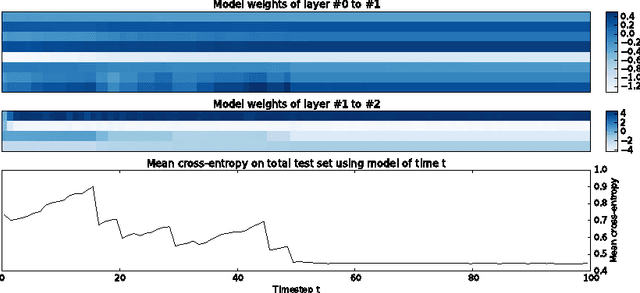
Meta-learning consists in learning learning algorithms. We use a Long Short Term Memory (LSTM) based network to learn to compute on-line updates of the parameters of another neural network. These parameters are stored in the cell state of the LSTM. Our framework allows to compare learned algorithms to hand-made algorithms within the traditional train and test methodology. In an experiment, we learn a learning algorithm for a one-hidden layer Multi-Layer Perceptron (MLP) on non-linearly separable datasets. The learned algorithm is able to update parameters of both layers and generalise well on similar datasets.