 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSchema Augmentation for Zero-Shot Domain Adaptation in Dialogue State Tracking
Oct 31, 2024



Zero-shot domain adaptation for dialogue state tracking (DST) remains a challenging problem in task-oriented dialogue (TOD) systems, where models must generalize to target domains unseen at training time. Current large language model approaches for zero-shot domain adaptation rely on prompting to introduce knowledge pertaining to the target domains. However, their efficacy strongly depends on prompt engineering, as well as the zero-shot ability of the underlying language model. In this work, we devise a novel data augmentation approach, Schema Augmentation, that improves the zero-shot domain adaptation of language models through fine-tuning. Schema Augmentation is a simple but effective technique that enhances generalization by introducing variations of slot names within the schema provided in the prompt. Experiments on MultiWOZ and SpokenWOZ showed that the proposed approach resulted in a substantial improvement over the baseline, in some experiments achieving over a twofold accuracy gain over unseen domains while maintaining equal or superior performance over all domains.
ASTRA: Aligning Speech and Text Representations for Asr without Sampling
Jun 10, 2024



This paper introduces ASTRA, a novel method for improving Automatic Speech Recognition (ASR) through text injection.Unlike prevailing techniques, ASTRA eliminates the need for sampling to match sequence lengths between speech and text modalities. Instead, it leverages the inherent alignments learned within CTC/RNNT models. This approach offers the following two advantages, namely, avoiding potential misalignment between speech and text features that could arise from upsampling and eliminating the need for models to accurately predict duration of sub-word tokens. This novel formulation of modality (length) matching as a weighted RNNT objective matches the performance of the state-of-the-art duration-based methods on the FLEURS benchmark, while opening up other avenues of research in speech processing.
Audio-AdapterFusion: A Task-ID-free Approach for Efficient and Non-Destructive Multi-task Speech Recognition
Oct 17, 2023Adapters are an efficient, composable alternative to full fine-tuning of pre-trained models and help scale the deployment of large ASR models to many tasks. In practice, a task ID is commonly prepended to the input during inference to route to single-task adapters for the specified task. However, one major limitation of this approach is that the task ID may not be known during inference, rendering it unsuitable for most multi-task settings. To address this, we propose three novel task-ID-free methods to combine single-task adapters in multi-task ASR and investigate two learning algorithms for training. We evaluate our methods on 10 test sets from 4 diverse ASR tasks and show that our methods are non-destructive and parameter-efficient. While only updating 17% of the model parameters, our methods can achieve an 8% mean WER improvement relative to full fine-tuning and are on-par with task-ID adapter routing.
Using Text Injection to Improve Recognition of Personal Identifiers in Speech
Aug 14, 2023



Accurate recognition of specific categories, such as persons' names, dates or other identifiers is critical in many Automatic Speech Recognition (ASR) applications. As these categories represent personal information, ethical use of this data including collection, transcription, training and evaluation demands special care. One way of ensuring the security and privacy of individuals is to redact or eliminate Personally Identifiable Information (PII) from collection altogether. However, this results in ASR models that tend to have lower recognition accuracy of these categories. We use text-injection to improve the recognition of PII categories by including fake textual substitutes of PII categories in the training data using a text injection method. We demonstrate substantial improvement to Recall of Names and Dates in medical notes while improving overall WER. For alphanumeric digit sequences we show improvements to Character Error Rate and Sentence Accuracy.
Universal Automatic Phonetic Transcription into the International Phonetic Alphabet
Aug 07, 2023



This paper presents a state-of-the-art model for transcribing speech in any language into the International Phonetic Alphabet (IPA). Transcription of spoken languages into IPA is an essential yet time-consuming process in language documentation, and even partially automating this process has the potential to drastically speed up the documentation of endangered languages. Like the previous best speech-to-IPA model (Wav2Vec2Phoneme), our model is based on wav2vec 2.0 and is fine-tuned to predict IPA from audio input. We use training data from seven languages from CommonVoice 11.0, transcribed into IPA semi-automatically. Although this training dataset is much smaller than Wav2Vec2Phoneme's, its higher quality lets our model achieve comparable or better results. Furthermore, we show that the quality of our universal speech-to-IPA models is close to that of human annotators.
Google USM: Scaling Automatic Speech Recognition Beyond 100 Languages
Mar 03, 2023
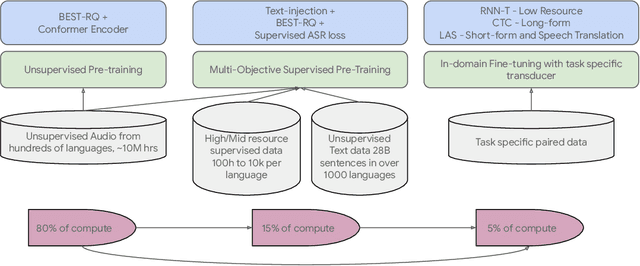
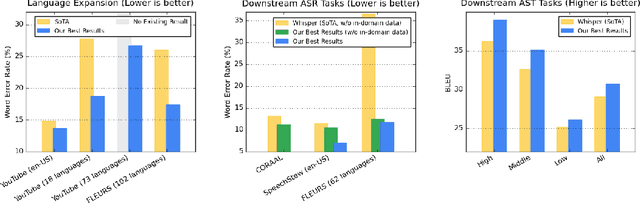

We introduce the Universal Speech Model (USM), a single large model that performs automatic speech recognition (ASR) across 100+ languages. This is achieved by pre-training the encoder of the model on a large unlabeled multilingual dataset of 12 million (M) hours spanning over 300 languages, and fine-tuning on a smaller labeled dataset. We use multilingual pre-training with random-projection quantization and speech-text modality matching to achieve state-of-the-art performance on downstream multilingual ASR and speech-to-text translation tasks. We also demonstrate that despite using a labeled training set 1/7-th the size of that used for the Whisper model, our model exhibits comparable or better performance on both in-domain and out-of-domain speech recognition tasks across many languages.
Accelerating RNN-T Training and Inference Using CTC guidance
Oct 29, 2022We propose a novel method to accelerate training and inference process of recurrent neural network transducer (RNN-T) based on the guidance from a co-trained connectionist temporal classification (CTC) model. We made a key assumption that if an encoder embedding frame is classified as a blank frame by the CTC model, it is likely that this frame will be aligned to blank for all the partial alignments or hypotheses in RNN-T and it can be discarded from the decoder input. We also show that this frame reduction operation can be applied in the middle of the encoder, which result in significant speed up for the training and inference in RNN-T. We further show that the CTC alignment, a by-product of the CTC decoder, can also be used to perform lattice reduction for RNN-T during training. Our method is evaluated on the Librispeech and SpeechStew tasks. We demonstrate that the proposed method is able to accelerate the RNN-T inference by 2.2 times with similar or slightly better word error rates (WER).
Streaming End-to-End Multilingual Speech Recognition with Joint Language Identification
Sep 13, 2022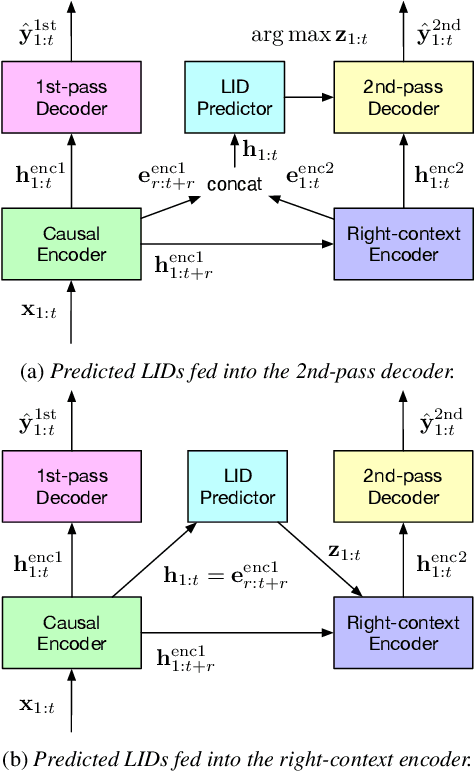


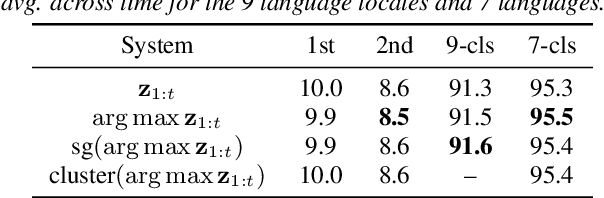
Language identification is critical for many downstream tasks in automatic speech recognition (ASR), and is beneficial to integrate into multilingual end-to-end ASR as an additional task. In this paper, we propose to modify the structure of the cascaded-encoder-based recurrent neural network transducer (RNN-T) model by integrating a per-frame language identifier (LID) predictor. RNN-T with cascaded encoders can achieve streaming ASR with low latency using first-pass decoding with no right-context, and achieve lower word error rates (WERs) using second-pass decoding with longer right-context. By leveraging such differences in the right-contexts and a streaming implementation of statistics pooling, the proposed method can achieve accurate streaming LID prediction with little extra test-time cost. Experimental results on a voice search dataset with 9 language locales shows that the proposed method achieves an average of 96.2% LID prediction accuracy and the same second-pass WER as that obtained by including oracle LID in the input.
A Language Agnostic Multilingual Streaming On-Device ASR System
Aug 29, 2022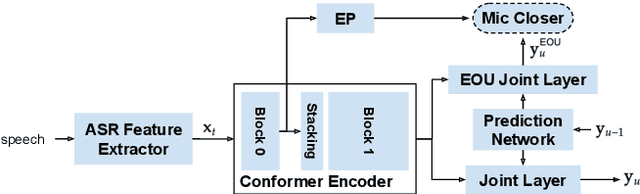
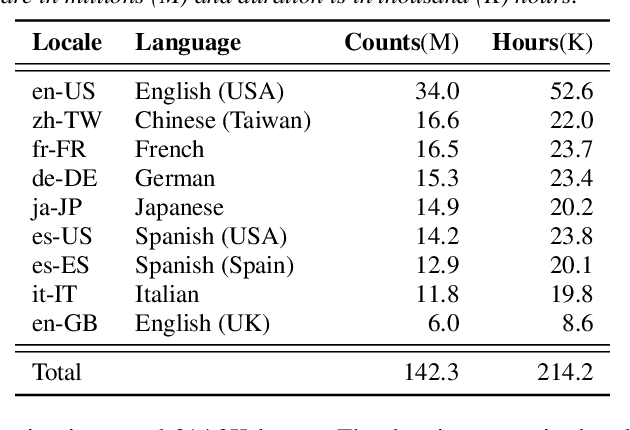
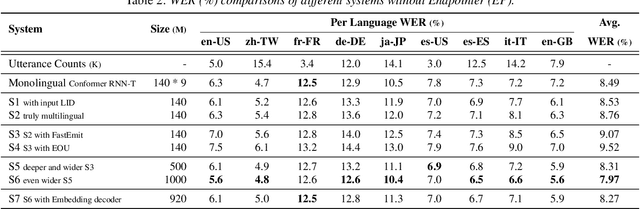
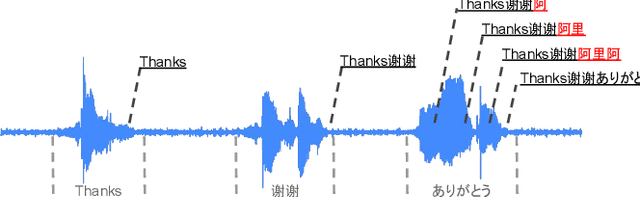
On-device end-to-end (E2E) models have shown improvements over a conventional model on English Voice Search tasks in both quality and latency. E2E models have also shown promising results for multilingual automatic speech recognition (ASR). In this paper, we extend our previous capacity solution to streaming applications and present a streaming multilingual E2E ASR system that runs fully on device with comparable quality and latency to individual monolingual models. To achieve that, we propose an Encoder Endpointer model and an End-of-Utterance (EOU) Joint Layer for a better quality and latency trade-off. Our system is built in a language agnostic manner allowing it to natively support intersentential code switching in real time. To address the feasibility concerns on large models, we conducted on-device profiling and replaced the time consuming LSTM decoder with the recently developed Embedding decoder. With these changes, we managed to run such a system on a mobile device in less than real time.
Unsupervised Data Selection via Discrete Speech Representation for ASR
Apr 05, 2022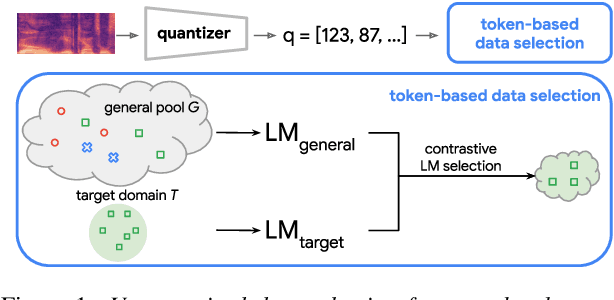


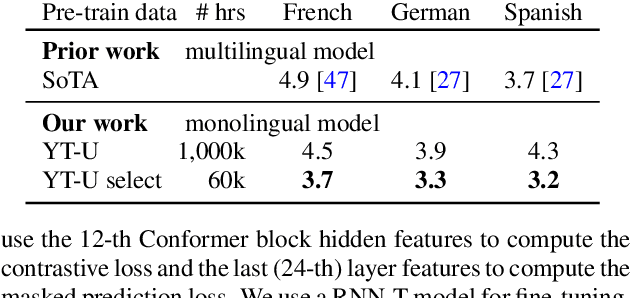
Self-supervised learning of speech representations has achieved impressive results in improving automatic speech recognition (ASR). In this paper, we show that data selection is important for self-supervised learning. We propose a simple and effective unsupervised data selection method which selects acoustically similar speech to a target domain. It takes the discrete speech representation available in common self-supervised learning frameworks as input, and applies a contrastive data selection method on the discrete tokens. Through extensive empirical studies we show that our proposed method reduces the amount of required pre-training data and improves the downstream ASR performance. Pre-training on a selected subset of 6% of the general data pool results in 11.8% relative improvements in LibriSpeech test-other compared to pre-training on the full set. On Multilingual LibriSpeech French, German, and Spanish test sets, selecting 6% data for pre-training reduces word error rate by more than 15% relatively compared to the full set, and achieves competitive results compared to current state-of-the-art performances.