 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRESTO: A Multilingual Dataset for Parsing Realistic Task-Oriented Dialogs
Mar 17, 2023



Research interest in task-oriented dialogs has increased as systems such as Google Assistant, Alexa and Siri have become ubiquitous in everyday life. However, the impact of academic research in this area has been limited by the lack of datasets that realistically capture the wide array of user pain points. To enable research on some of the more challenging aspects of parsing realistic conversations, we introduce PRESTO, a public dataset of over 550K contextual multilingual conversations between humans and virtual assistants. PRESTO contains a diverse array of challenges that occur in real-world NLU tasks such as disfluencies, code-switching, and revisions. It is the only large scale human generated conversational parsing dataset that provides structured context such as a user's contacts and lists for each example. Our mT5 model based baselines demonstrate that the conversational phenomenon present in PRESTO are challenging to model, which is further pronounced in a low-resource setup.
Improving Top-K Decoding for Non-Autoregressive Semantic Parsing via Intent Conditioning
Apr 14, 2022
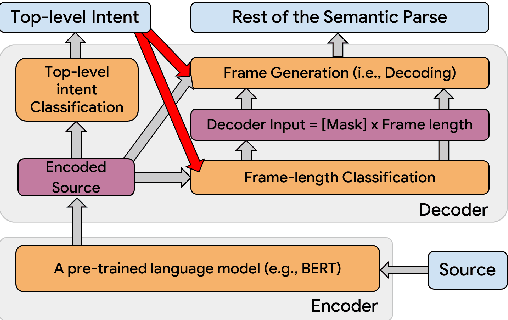

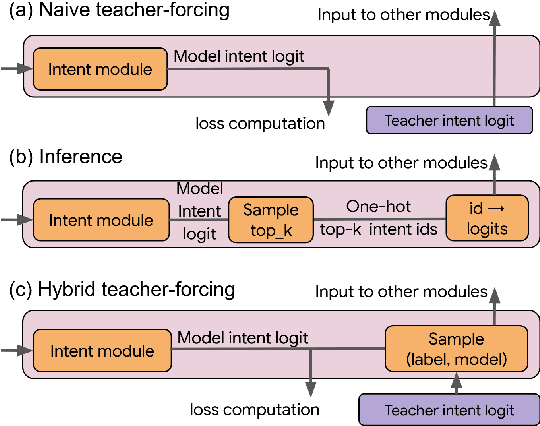
Semantic parsing (SP) is a core component of modern virtual assistants like Google Assistant and Amazon Alexa. While sequence-to-sequence-based auto-regressive (AR) approaches are common for conversational semantic parsing, recent studies employ non-autoregressive (NAR) decoders and reduce inference latency while maintaining competitive parsing quality. However, a major drawback of NAR decoders is the difficulty of generating top-k (i.e., k-best) outputs with approaches such as beam search. To address this challenge, we propose a novel NAR semantic parser that introduces intent conditioning on the decoder. Inspired by the traditional intent and slot tagging parsers, we decouple the top-level intent prediction from the rest of a parse. As the top-level intent largely governs the syntax and semantics of a parse, the intent conditioning allows the model to better control beam search and improves the quality and diversity of top-k outputs. We introduce a hybrid teacher-forcing approach to avoid training and inference mismatch. We evaluate the proposed NAR on conversational SP datasets, TOP & TOPv2. Like the existing NAR models, we maintain the O(1) decoding time complexity while generating more diverse outputs and improving the top-3 exact match (EM) by 2.4 points. In comparison with AR models, our model speeds up beam search inference by 6.7 times on CPU with competitive top-k EM.
Resource Constrained Dialog Policy Learning via Differentiable Inductive Logic Programming
Nov 10, 2020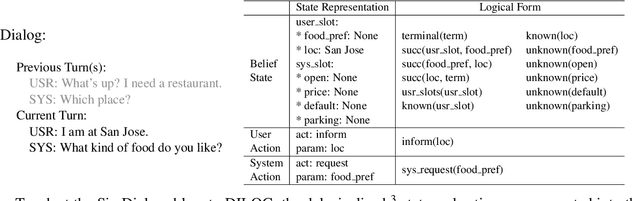
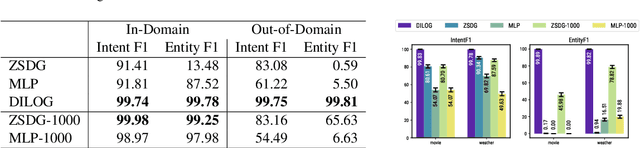

Motivated by the needs of resource constrained dialog policy learning, we introduce dialog policy via differentiable inductive logic (DILOG). We explore the tasks of one-shot learning and zero-shot domain transfer with DILOG on SimDial and MultiWoZ. Using a single representative dialog from the restaurant domain, we train DILOG on the SimDial dataset and obtain 99+% in-domain test accuracy. We also show that the trained DILOG zero-shot transfers to all other domains with 99+% accuracy, proving the suitability of DILOG to slot-filling dialogs. We further extend our study to the MultiWoZ dataset achieving 90+% inform and success metrics. We also observe that these metrics are not capturing some of the shortcomings of DILOG in terms of false positives, prompting us to measure an auxiliary Action F1 score. We show that DILOG is 100x more data efficient than state-of-the-art neural approaches on MultiWoZ while achieving similar performance metrics. We conclude with a discussion on the strengths and weaknesses of DILOG.
User Memory Reasoning for Conversational Recommendation
May 30, 2020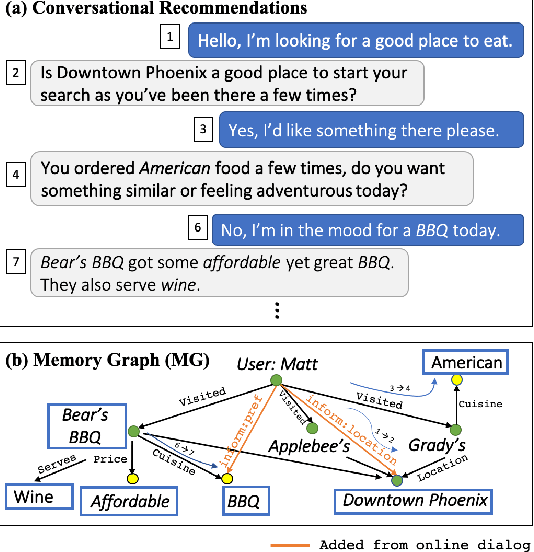
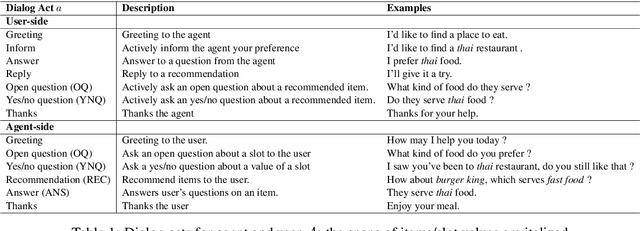

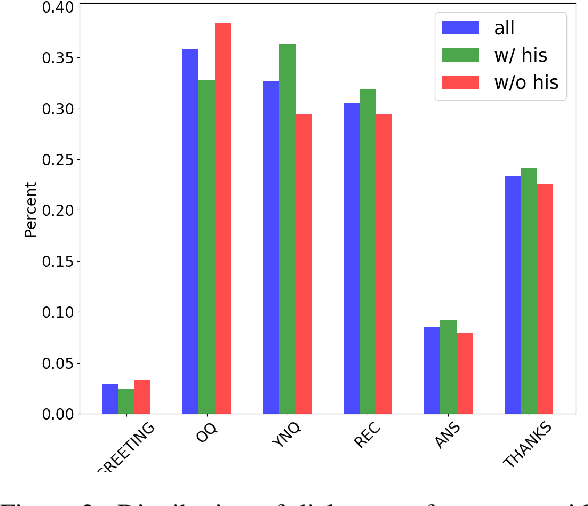
We study a conversational recommendation model which dynamically manages users' past (offline) preferences and current (online) requests through a structured and cumulative user memory knowledge graph, to allow for natural interactions and accurate recommendations. For this study, we create a new Memory Graph (MG) <--> Conversational Recommendation parallel corpus called MGConvRex with 7K+ human-to-human role-playing dialogs, grounded on a large-scale user memory bootstrapped from real-world user scenarios. MGConvRex captures human-level reasoning over user memory and has disjoint training/testing sets of users for zero-shot (cold-start) reasoning for recommendation. We propose a simple yet expandable formulation for constructing and updating the MG, and a reasoning model that predicts optimal dialog policies and recommendation items in unconstrained graph space. The prediction of our proposed model inherits the graph structure, providing a natural way to explain the model's recommendation. Experiments are conducted for both offline metrics and online simulation, showing competitive results.
Recommendation as a Communication Game: Self-Supervised Bot-Play for Goal-oriented Dialogue
Sep 09, 2019
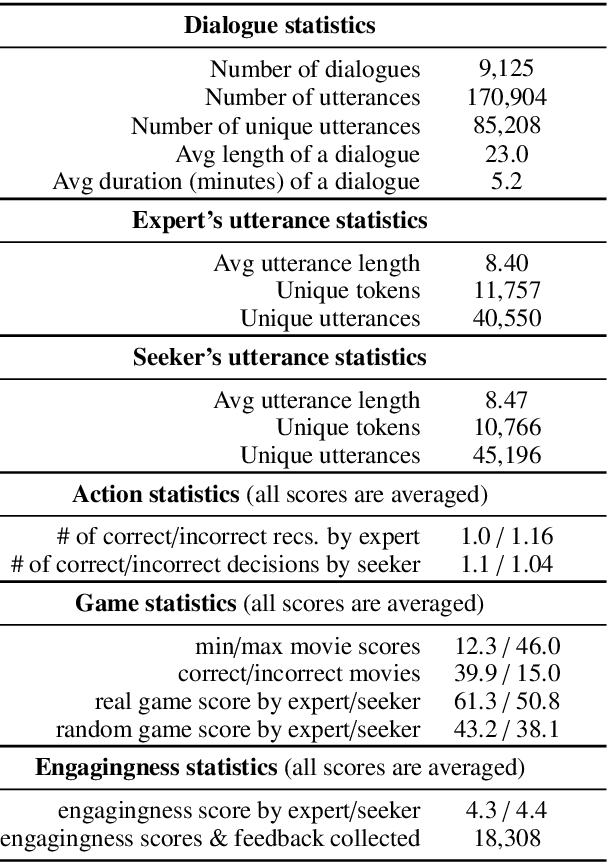
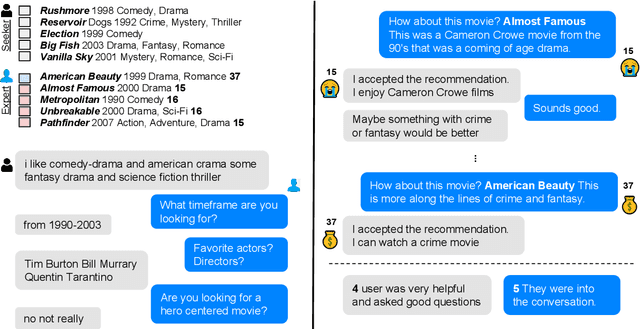
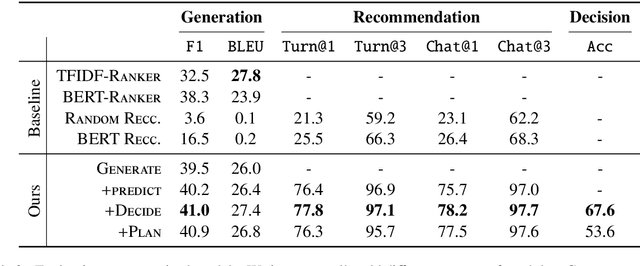
Traditional recommendation systems produce static rather than interactive recommendations invariant to a user's specific requests, clarifications, or current mood, and can suffer from the cold-start problem if their tastes are unknown. These issues can be alleviated by treating recommendation as an interactive dialogue task instead, where an expert recommender can sequentially ask about someone's preferences, react to their requests, and recommend more appropriate items. In this work, we collect a goal-driven recommendation dialogue dataset (GoRecDial), which consists of 9,125 dialogue games and 81,260 conversation turns between pairs of human workers recommending movies to each other. The task is specifically designed as a cooperative game between two players working towards a quantifiable common goal. We leverage the dataset to develop an end-to-end dialogue system that can simultaneously converse and recommend. Models are first trained to imitate the behavior of human players without considering the task goal itself (supervised training). We then finetune our models on simulated bot-bot conversations between two paired pre-trained models (bot-play), in order to achieve the dialogue goal. Our experiments show that models finetuned with bot-play learn improved dialogue strategies, reach the dialogue goal more often when paired with a human, and are rated as more consistent by humans compared to models trained without bot-play. The dataset and code are publicly available through the ParlAI framework.
User Modeling for Task Oriented Dialogues
Nov 11, 2018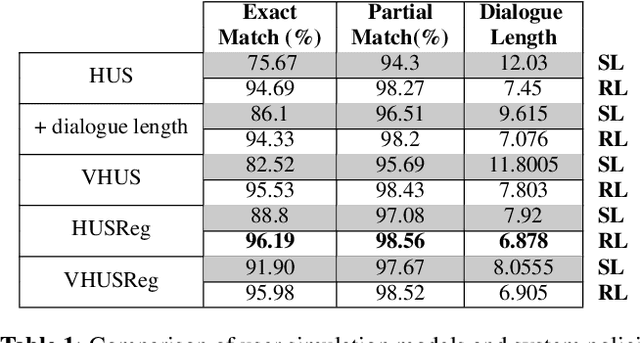
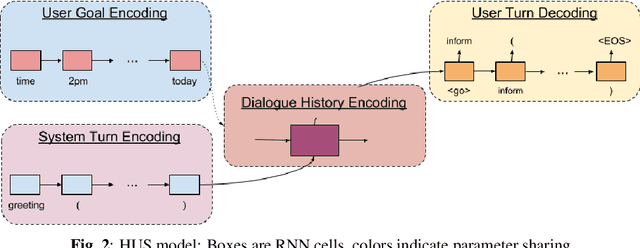
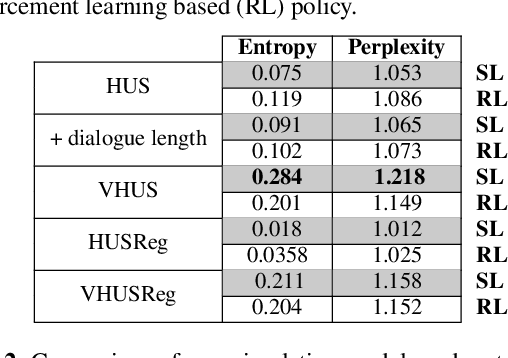
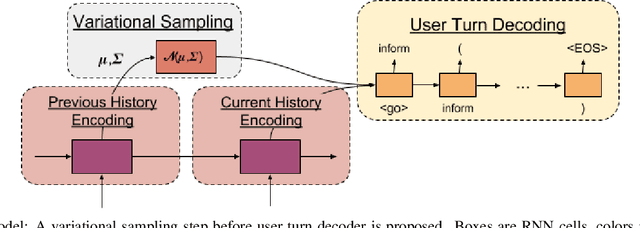
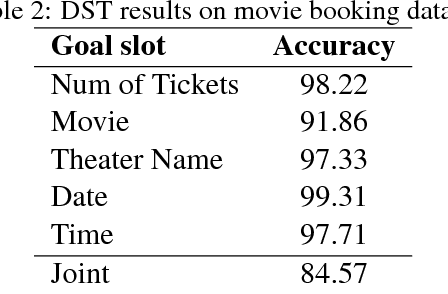
We introduce end-to-end neural network based models for simulating users of task-oriented dialogue systems. User simulation in dialogue systems is crucial from two different perspectives: (i) automatic evaluation of different dialogue models, and (ii) training task-oriented dialogue systems. We design a hierarchical sequence-to-sequence model that first encodes the initial user goal and system turns into fixed length representations using Recurrent Neural Networks (RNN). It then encodes the dialogue history using another RNN layer. At each turn, user responses are decoded from the hidden representations of the dialogue level RNN. This hierarchical user simulator (HUS) approach allows the model to capture undiscovered parts of the user goal without the need of an explicit dialogue state tracking. We further develop several variants by utilizing a latent variable model to inject random variations into user responses to promote diversity in simulated user responses and a novel goal regularization mechanism to penalize divergence of user responses from the initial user goal. We evaluate the proposed models on movie ticket booking domain by systematically interacting each user simulator with various dialogue system policies trained with different objectives and users.
FollowNet: Robot Navigation by Following Natural Language Directions with Deep Reinforcement Learning
May 16, 2018
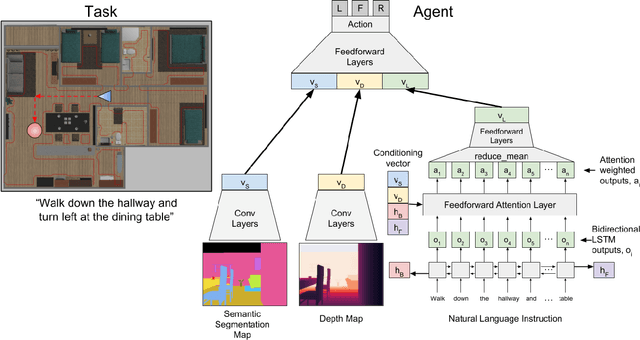
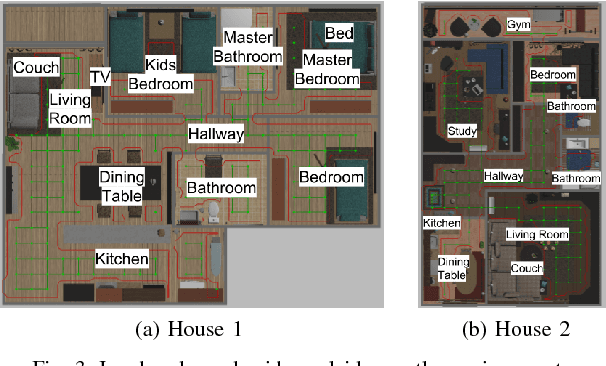
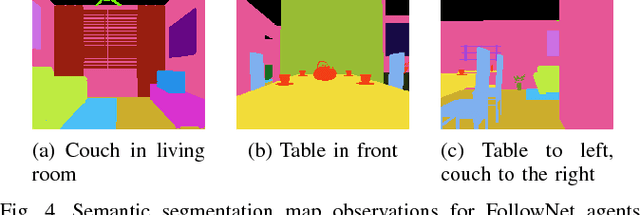
Understanding and following directions provided by humans can enable robots to navigate effectively in unknown situations. We present FollowNet, an end-to-end differentiable neural architecture for learning multi-modal navigation policies. FollowNet maps natural language instructions as well as visual and depth inputs to locomotion primitives. FollowNet processes instructions using an attention mechanism conditioned on its visual and depth input to focus on the relevant parts of the command while performing the navigation task. Deep reinforcement learning (RL) a sparse reward learns simultaneously the state representation, the attention function, and control policies. We evaluate our agent on a dataset of complex natural language directions that guide the agent through a rich and realistic dataset of simulated homes. We show that the FollowNet agent learns to execute previously unseen instructions described with a similar vocabulary, and successfully navigates along paths not encountered during training. The agent shows 30% improvement over a baseline model without the attention mechanism, with 52% success rate at novel instructions.
* 7 pages, 8 figures
Dialogue Learning with Human Teaching and Feedback in End-to-End Trainable Task-Oriented Dialogue Systems
Apr 18, 2018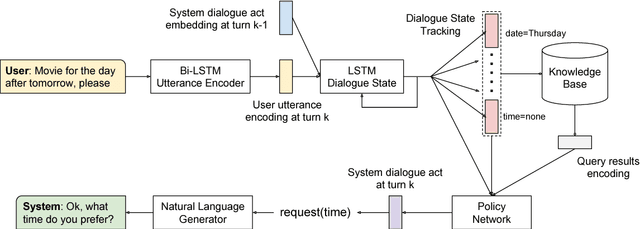
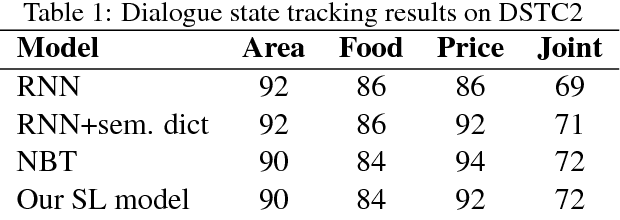
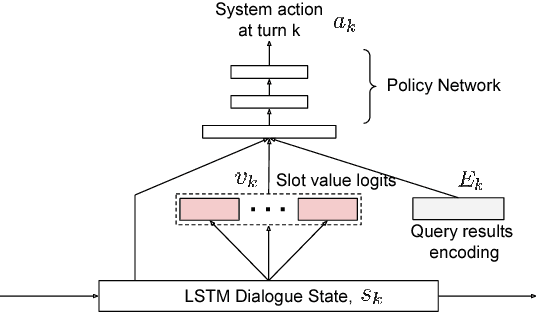
In this work, we present a hybrid learning method for training task-oriented dialogue systems through online user interactions. Popular methods for learning task-oriented dialogues include applying reinforcement learning with user feedback on supervised pre-training models. Efficiency of such learning method may suffer from the mismatch of dialogue state distribution between offline training and online interactive learning stages. To address this challenge, we propose a hybrid imitation and reinforcement learning method, with which a dialogue agent can effectively learn from its interaction with users by learning from human teaching and feedback. We design a neural network based task-oriented dialogue agent that can be optimized end-to-end with the proposed learning method. Experimental results show that our end-to-end dialogue agent can learn effectively from the mistake it makes via imitation learning from user teaching. Applying reinforcement learning with user feedback after the imitation learning stage further improves the agent's capability in successfully completing a task.
Building a Conversational Agent Overnight with Dialogue Self-Play
Jan 15, 2018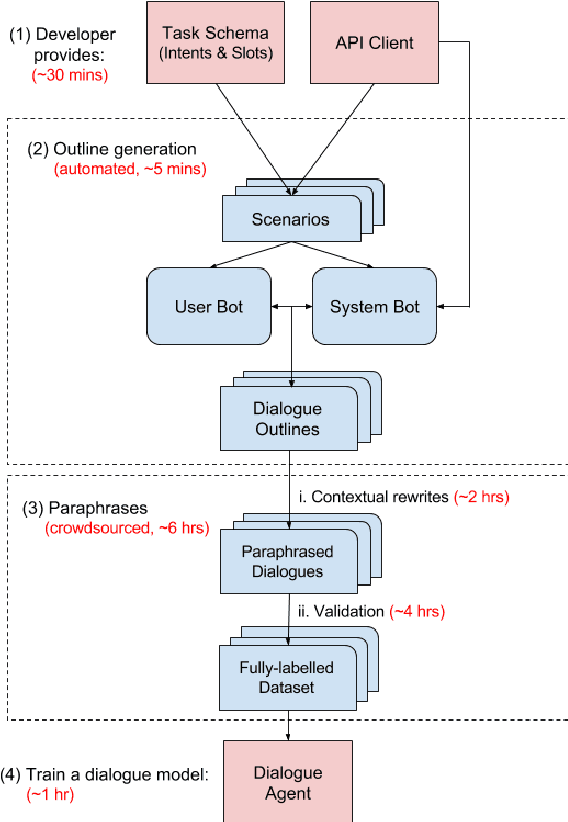
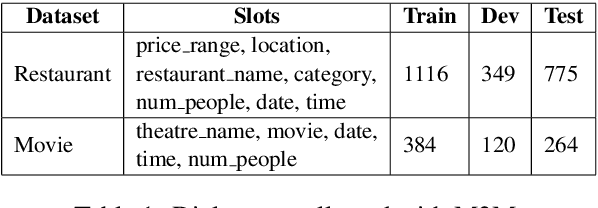
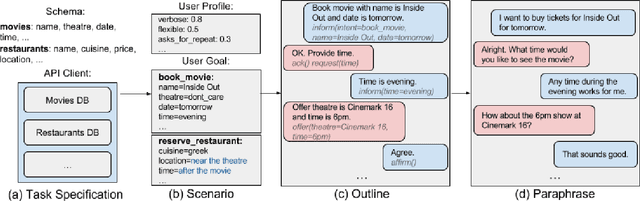
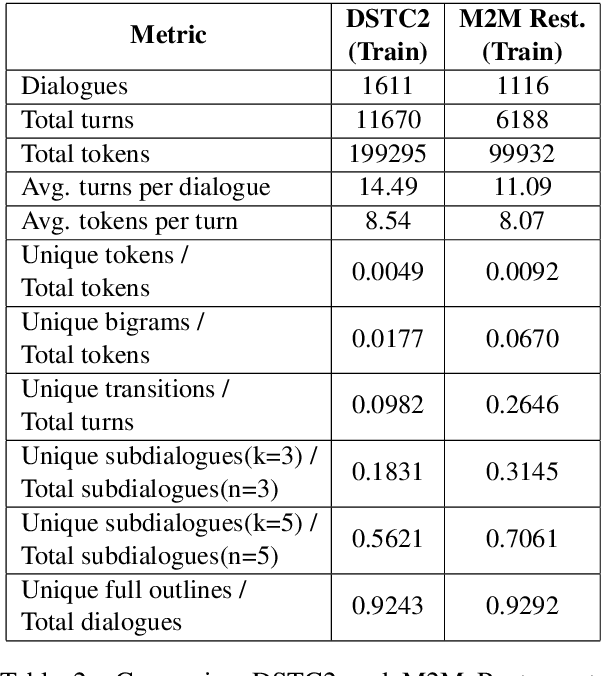
We propose Machines Talking To Machines (M2M), a framework combining automation and crowdsourcing to rapidly bootstrap end-to-end dialogue agents for goal-oriented dialogues in arbitrary domains. M2M scales to new tasks with just a task schema and an API client from the dialogue system developer, but it is also customizable to cater to task-specific interactions. Compared to the Wizard-of-Oz approach for data collection, M2M achieves greater diversity and coverage of salient dialogue flows while maintaining the naturalness of individual utterances. In the first phase, a simulated user bot and a domain-agnostic system bot converse to exhaustively generate dialogue "outlines", i.e. sequences of template utterances and their semantic parses. In the second phase, crowd workers provide contextual rewrites of the dialogues to make the utterances more natural while preserving their meaning. The entire process can finish within a few hours. We propose a new corpus of 3,000 dialogues spanning 2 domains collected with M2M, and present comparisons with popular dialogue datasets on the quality and diversity of the surface forms and dialogue flows.
Federated Control with Hierarchical Multi-Agent Deep Reinforcement Learning
Dec 22, 2017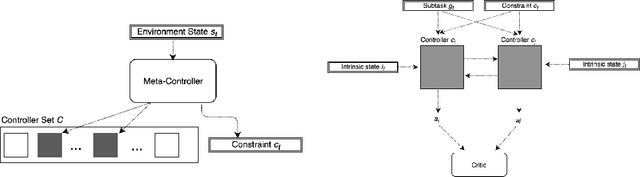
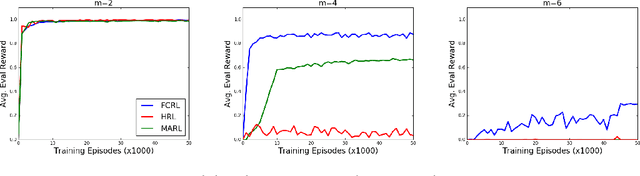
We present a framework combining hierarchical and multi-agent deep reinforcement learning approaches to solve coordination problems among a multitude of agents using a semi-decentralized model. The framework extends the multi-agent learning setup by introducing a meta-controller that guides the communication between agent pairs, enabling agents to focus on communicating with only one other agent at any step. This hierarchical decomposition of the task allows for efficient exploration to learn policies that identify globally optimal solutions even as the number of collaborating agents increases. We show promising initial experimental results on a simulated distributed scheduling problem.