 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient Semi-Automated Scheme for Infrastructure LiDAR Annotation
Jan 25, 2023



Most existing perception systems rely on sensory data acquired from cameras, which perform poorly in low light and adverse weather conditions. To resolve this limitation, we have witnessed advanced LiDAR sensors become popular in perception tasks in autonomous driving applications. Nevertheless, their usage in traffic monitoring systems is less ubiquitous. We identify two significant obstacles in cost-effectively and efficiently developing such a LiDAR-based traffic monitoring system: (i) public LiDAR datasets are insufficient for supporting perception tasks in infrastructure systems, and (ii) 3D annotations on LiDAR point clouds are time-consuming and expensive. To fill this gap, we present an efficient semi-automated annotation tool that automatically annotates LiDAR sequences with tracking algorithms while offering a fully annotated infrastructure LiDAR dataset -- FLORIDA (Florida LiDAR-based Object Recognition and Intelligent Data Annotation) -- which will be made publicly available. Our advanced annotation tool seamlessly integrates multi-object tracking (MOT), single-object tracking (SOT), and suitable trajectory post-processing techniques. Specifically, we introduce a human-in-the-loop schema in which annotators recursively fix and refine annotations imperfectly predicted by our tool and incrementally add them to the training dataset to obtain better SOT and MOT models. By repeating the process, we significantly increase the overall annotation speed by three to four times and obtain better qualitative annotations than a state-of-the-art annotation tool. The human annotation experiments verify the effectiveness of our annotation tool. In addition, we provide detailed statistics and object detection evaluation results for our dataset in serving as a benchmark for perception tasks at traffic intersections.
Expressing linear equality constraints in feedforward neural networks
Nov 08, 2022


We seek to impose linear, equality constraints in feedforward neural networks. As top layer predictors are usually nonlinear, this is a difficult task if we seek to deploy standard convex optimization methods and strong duality. To overcome this, we introduce a new saddle-point Lagrangian with auxiliary predictor variables on which constraints are imposed. Elimination of the auxiliary variables leads to a dual minimization problem on the Lagrange multipliers introduced to satisfy the linear constraints. This minimization problem is combined with the standard learning problem on the weight matrices. From this theoretical line of development, we obtain the surprising interpretation of Lagrange parameters as additional, penultimate layer hidden units with fixed weights stemming from the constraints. Consequently, standard minimization approaches can be used despite the inclusion of Lagrange parameters -- a very satisfying, albeit unexpected, discovery. Examples ranging from multi-label classification to constrained autoencoders are envisaged in the future.
Learning Canonical Embeddings for Unsupervised Shape Correspondence with Locally Linear Transformations
Sep 07, 2022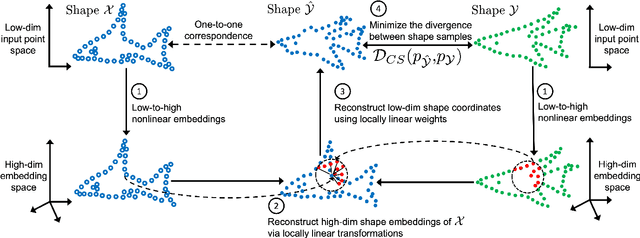
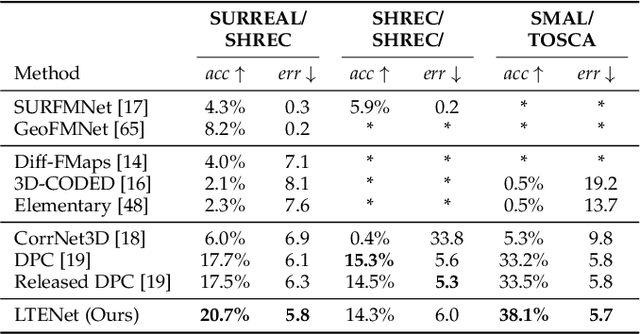
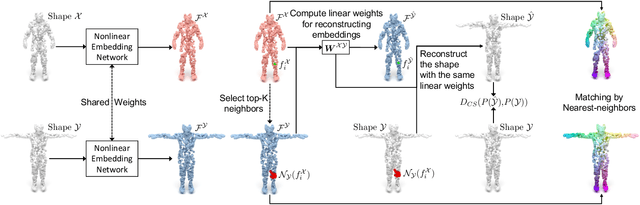

We present a new approach to unsupervised shape correspondence learning between pairs of point clouds. We make the first attempt to adapt the classical locally linear embedding algorithm (LLE) -- originally designed for nonlinear dimensionality reduction -- for shape correspondence. The key idea is to find dense correspondences between shapes by first obtaining high-dimensional neighborhood-preserving embeddings of low-dimensional point clouds and subsequently aligning the source and target embeddings using locally linear transformations. We demonstrate that learning the embedding using a new LLE-inspired point cloud reconstruction objective results in accurate shape correspondences. More specifically, the approach comprises an end-to-end learnable framework of extracting high-dimensional neighborhood-preserving embeddings, estimating locally linear transformations in the embedding space, and reconstructing shapes via divergence measure-based alignment of probabilistic density functions built over reconstructed and target shapes. Our approach enforces embeddings of shapes in correspondence to lie in the same universal/canonical embedding space, which eventually helps regularize the learning process and leads to a simple nearest neighbors approach between shape embeddings for finding reliable correspondences. Comprehensive experiments show that the new method makes noticeable improvements over state-of-the-art approaches on standard shape correspondence benchmark datasets covering both human and nonhuman shapes.
Slot Order Matters for Compositional Scene Understanding
Jun 03, 2022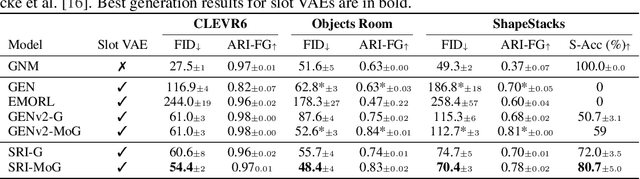
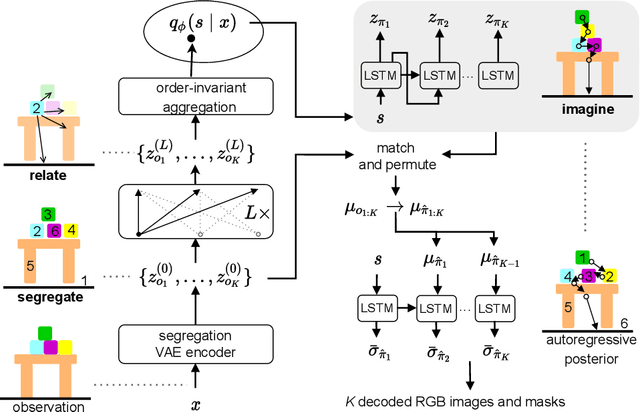


Empowering agents with a compositional understanding of their environment is a promising next step toward solving long-horizon planning problems. On the one hand, we have seen encouraging progress on variational inference algorithms for obtaining sets of object-centric latent representations ("slots") from unstructured scene observations. On the other hand, generating scenes from slots has received less attention, in part because it is complicated by the lack of a canonical object order. A canonical object order is useful for learning the object correlations necessary to generate physically plausible scenes similar to how raster scan order facilitates learning pixel correlations for pixel-level autoregressive image generation. In this work, we address this lack by learning a fixed object order for a hierarchical variational autoencoder with a single level of autoregressive slots and a global scene prior. We cast autoregressive slot inference as a set-to-sequence modeling problem. We introduce an auxiliary loss to train the slot prior to generate objects in a fixed order. During inference, we align a set of inferred slots to the object order obtained from a slot prior rollout. To ensure the rolled out objects are meaningful for the given scene, we condition the prior on an inferred global summary of the input. Experiments on compositional environments and ablations demonstrate that our model with global prior, inference with aligned slot order, and auxiliary loss achieves state-of-the-art sample quality.
Self-Supervised Robust Scene Flow Estimation via the Alignment of Probability Density Functions
Mar 23, 2022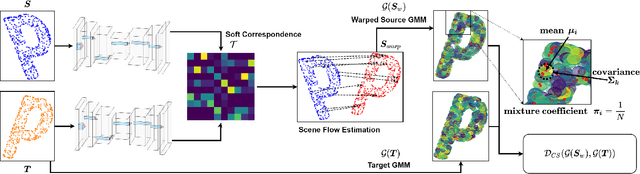
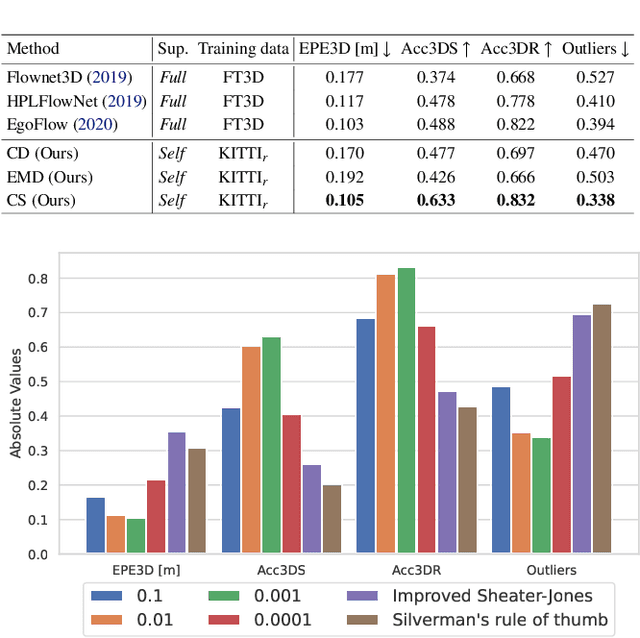
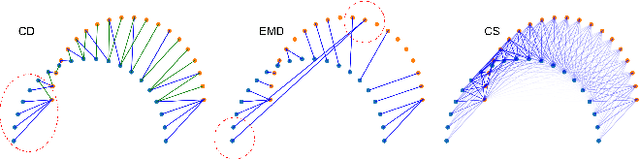
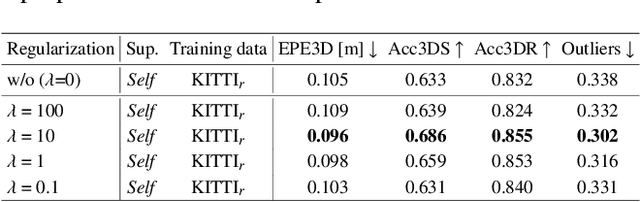
In this paper, we present a new self-supervised scene flow estimation approach for a pair of consecutive point clouds. The key idea of our approach is to represent discrete point clouds as continuous probability density functions using Gaussian mixture models. Scene flow estimation is therefore converted into the problem of recovering motion from the alignment of probability density functions, which we achieve using a closed-form expression of the classic Cauchy-Schwarz divergence. Unlike existing nearest-neighbor-based approaches that use hard pairwise correspondences, our proposed approach establishes soft and implicit point correspondences between point clouds and generates more robust and accurate scene flow in the presence of missing correspondences and outliers. Comprehensive experiments show that our method makes noticeable gains over the Chamfer Distance and the Earth Mover's Distance in real-world environments and achieves state-of-the-art performance among self-supervised learning methods on FlyingThings3D and KITTI, even outperforming some supervised methods with ground truth annotations.
Protum: A New Method For Prompt Tuning Based on ""
Jan 28, 2022Recently, prompt tuning \cite{lester2021power} has gradually become a new paradigm for NLP, which only depends on the representation of the words by freezing the parameters of pre-trained language models (PLMs) to obtain remarkable performance on downstream tasks. It maintains the consistency of Masked Language Model (MLM) \cite{devlin2018bert} task in the process of pre-training, and avoids some issues that may happened during fine-tuning. Naturally, we consider that the "[MASK]" tokens carry more useful information than other tokens because the model combines with context to predict the masked tokens. Among the current prompt tuning methods, there will be a serious problem of random composition of the answer tokens in prediction when they predict multiple words so that they have to map tokens to labels with the help verbalizer. In response to the above issue, we propose a new \textbf{Pro}mpt \textbf{Tu}ning based on "[\textbf{M}ASK]" (\textbf{Protum}) method in this paper, which constructs a classification task through the information carried by the hidden layer of "[MASK]" tokens and then predicts the labels directly rather than the answer tokens. At the same time, we explore how different hidden layers under "[MASK]" impact on our classification model on many different data sets. Finally, we find that our \textbf{Protum} can achieve much better performance than fine-tuning after continuous pre-training with less time consumption. Our model facilitates the practical application of large models in NLP.
Learning Scene Dynamics from Point Cloud Sequences
Nov 16, 2021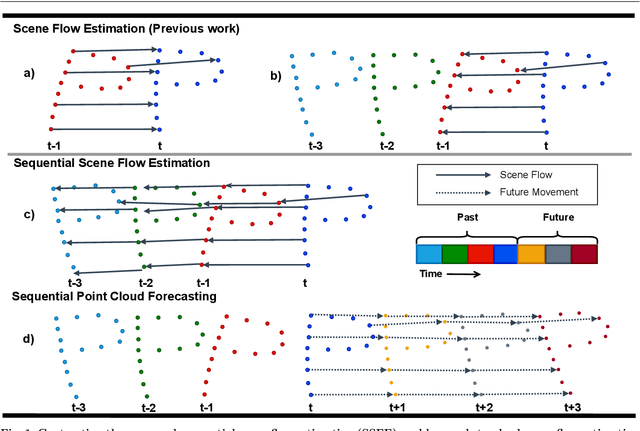

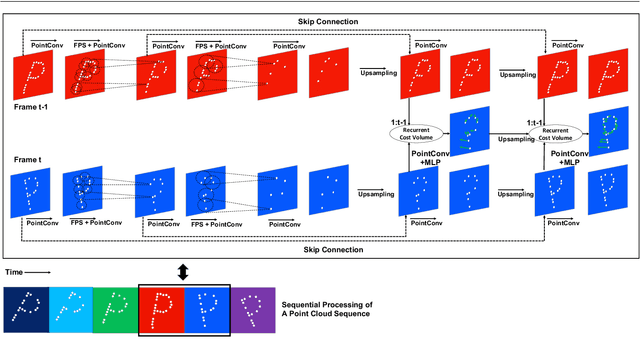
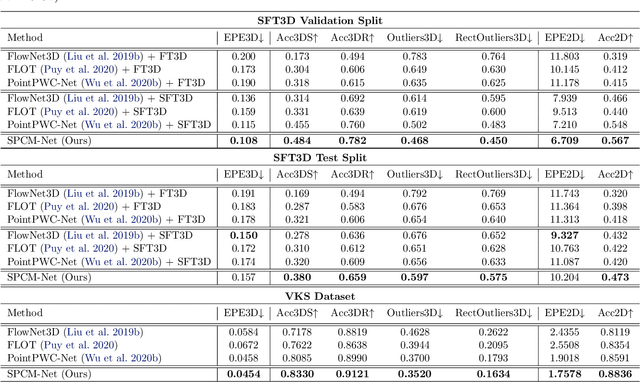
Understanding 3D scenes is a critical prerequisite for autonomous agents. Recently, LiDAR and other sensors have made large amounts of data available in the form of temporal sequences of point cloud frames. In this work, we propose a novel problem -- sequential scene flow estimation (SSFE) -- that aims to predict 3D scene flow for all pairs of point clouds in a given sequence. This is unlike the previously studied problem of scene flow estimation which focuses on two frames. We introduce the SPCM-Net architecture, which solves this problem by computing multi-scale spatiotemporal correlations between neighboring point clouds and then aggregating the correlation across time with an order-invariant recurrent unit. Our experimental evaluation confirms that recurrent processing of point cloud sequences results in significantly better SSFE compared to using only two frames. Additionally, we demonstrate that this approach can be effectively modified for sequential point cloud forecasting (SPF), a related problem that demands forecasting future point cloud frames. Our experimental results are evaluated using a new benchmark for both SSFE and SPF consisting of synthetic and real datasets. Previously, datasets for scene flow estimation have been limited to two frames. We provide non-trivial extensions to these datasets for multi-frame estimation and prediction. Due to the difficulty of obtaining ground truth motion for real-world datasets, we use self-supervised training and evaluation metrics. We believe that this benchmark will be pivotal to future research in this area. All code for benchmark and models will be made accessible.
Efficient Iterative Amortized Inference for Learning Symmetric and Disentangled Multi-Object Representations
Jun 07, 2021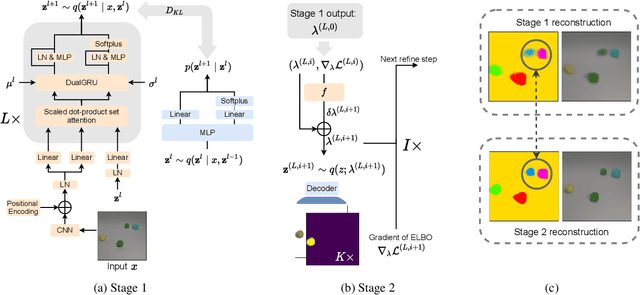
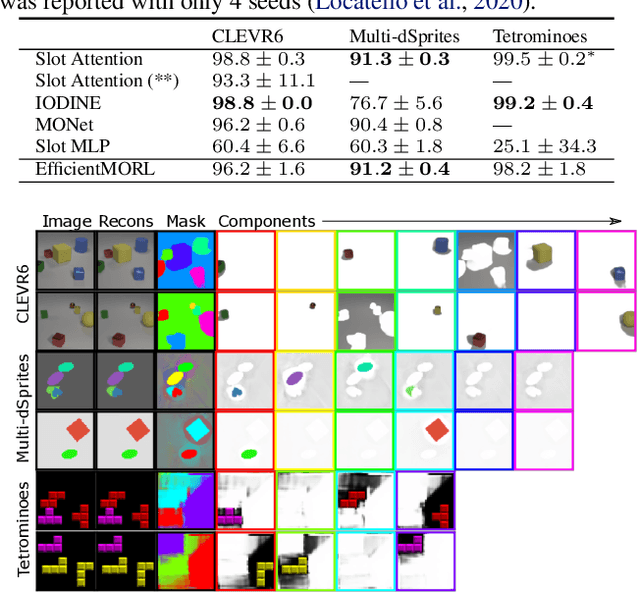
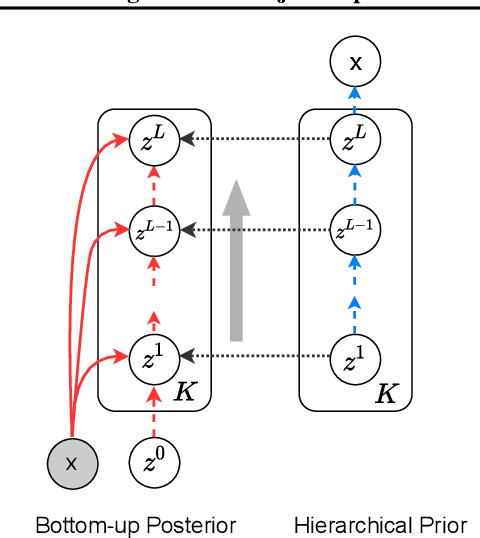
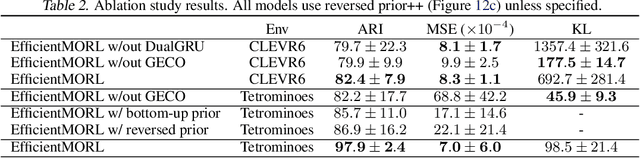
Unsupervised multi-object representation learning depends on inductive biases to guide the discovery of object-centric representations that generalize. However, we observe that methods for learning these representations are either impractical due to long training times and large memory consumption or forego key inductive biases. In this work, we introduce EfficientMORL, an efficient framework for the unsupervised learning of object-centric representations. We show that optimization challenges caused by requiring both symmetry and disentanglement can in fact be addressed by high-cost iterative amortized inference by designing the framework to minimize its dependence on it. We take a two-stage approach to inference: first, a hierarchical variational autoencoder extracts symmetric and disentangled representations through bottom-up inference, and second, a lightweight network refines the representations with top-down feedback. The number of refinement steps taken during training is reduced following a curriculum, so that at test time with zero steps the model achieves 99.1% of the refined decomposition performance. We demonstrate strong object decomposition and disentanglement on the standard multi-object benchmark while achieving nearly an order of magnitude faster training and test time inference over the previous state-of-the-art model.
SparsePipe: Parallel Deep Learning for 3D Point Clouds
Dec 27, 2020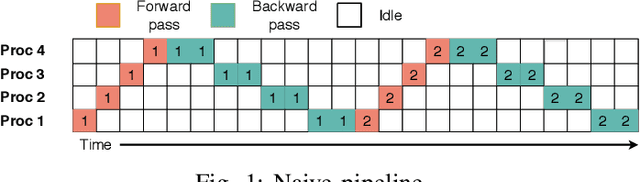
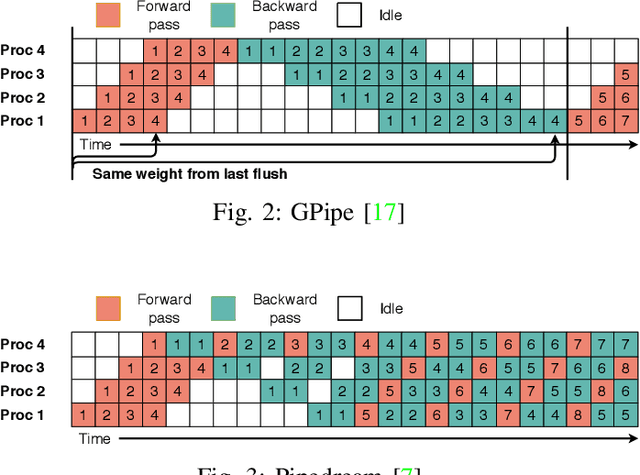
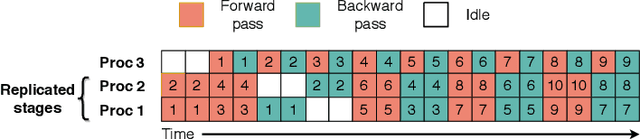
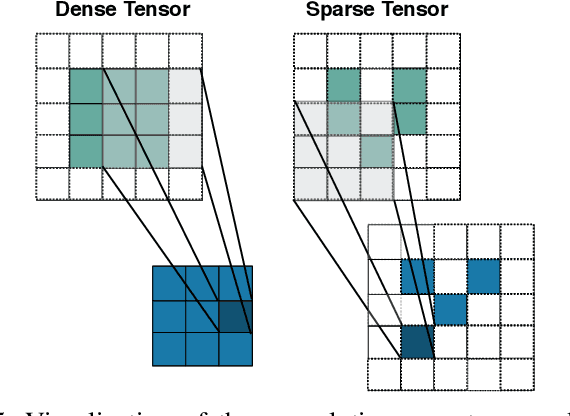
We propose SparsePipe, an efficient and asynchronous parallelism approach for handling 3D point clouds with multi-GPU training. SparsePipe is built to support 3D sparse data such as point clouds. It achieves this by adopting generalized convolutions with sparse tensor representation to build expressive high-dimensional convolutional neural networks. Compared to dense solutions, the new models can efficiently process irregular point clouds without densely sliding over the entire space, significantly reducing the memory requirements and allowing higher resolutions of the underlying 3D volumes for better performance. SparsePipe exploits intra-batch parallelism that partitions input data into multiple processors and further improves the training throughput with inter-batch pipelining to overlap communication and computing. Besides, it suitably partitions the model when the GPUs are heterogeneous such that the computing is load-balanced with reduced communication overhead. Using experimental results on an eight-GPU platform, we show that SparsePipe can parallelize effectively and obtain better performance on current point cloud benchmarks for both training and inference, compared to its dense solutions.
Intelligent Intersection: Two-Stream Convolutional Networks for Real-time Near Accident Detection in Traffic Video
Jan 04, 2019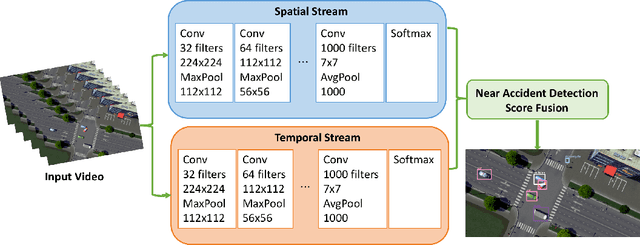
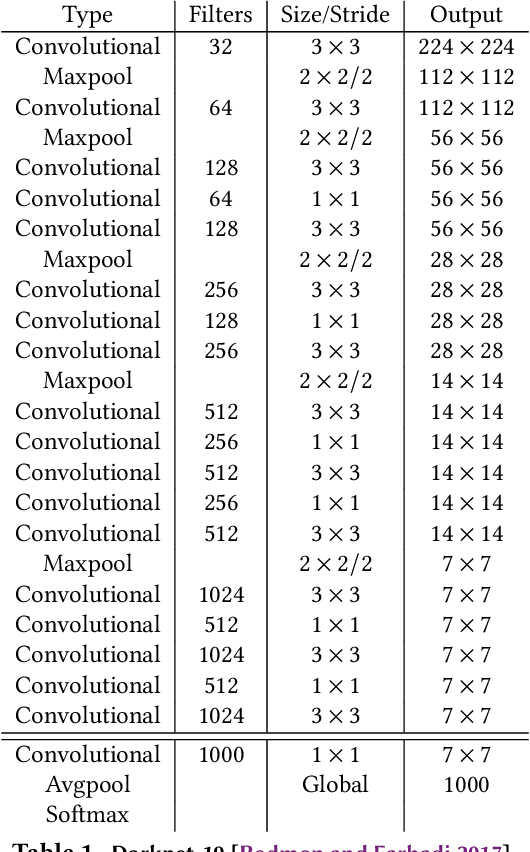
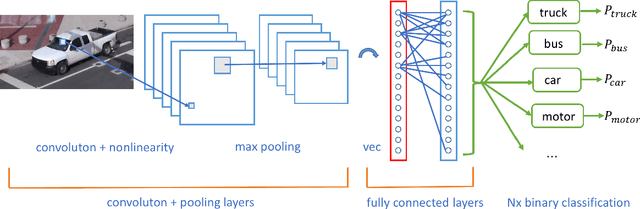
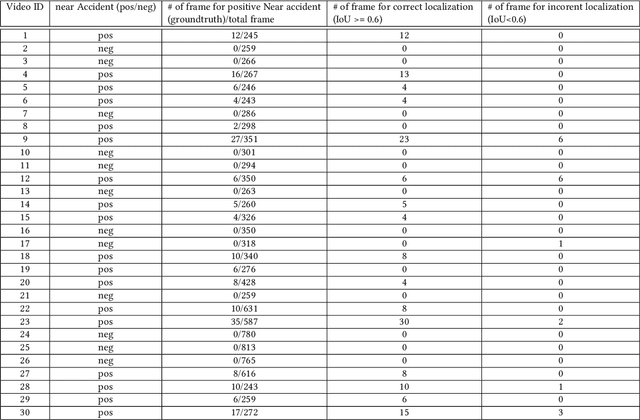
In Intelligent Transportation System, real-time systems that monitor and analyze road users become increasingly critical as we march toward the smart city era. Vision-based frameworks for Object Detection, Multiple Object Tracking, and Traffic Near Accident Detection are important applications of Intelligent Transportation System, particularly in video surveillance and etc. Although deep neural networks have recently achieved great success in many computer vision tasks, a uniformed framework for all the three tasks is still challenging where the challenges multiply from demand for real-time performance, complex urban setting, highly dynamic traffic event, and many traffic movements. In this paper, we propose a two-stream Convolutional Network architecture that performs real-time detection, tracking, and near accident detection of road users in traffic video data. The two-stream model consists of a spatial stream network for Object Detection and a temporal stream network to leverage motion features for Multiple Object Tracking. We detect near accidents by incorporating appearance features and motion features from two-stream networks. Using aerial videos, we propose a Traffic Near Accident Dataset (TNAD) covering various types of traffic interactions that is suitable for vision-based traffic analysis tasks. Our experiments demonstrate the advantage of our framework with an overall competitive qualitative and quantitative performance at high frame rates on the TNAD dataset.