 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlack-Box Behavioral Distillation Breaks Safety Alignment in Medical LLMs
Dec 10, 2025As medical large language models (LLMs) become increasingly integrated into clinical workflows, concerns around alignment robustness, and safety are escalating. Prior work on model extraction has focused on classification models or memorization leakage, leaving the vulnerability of safety-aligned generative medical LLMs underexplored. We present a black-box distillation attack that replicates the domain-specific reasoning of safety-aligned medical LLMs using only output-level access. By issuing 48,000 instruction queries to Meditron-7B and collecting 25,000 benign instruction response pairs, we fine-tune a LLaMA3 8B surrogate via parameter efficient LoRA under a zero-alignment supervision setting, requiring no access to model weights, safety filters, or training data. With a cost of $12, the surrogate achieves strong fidelity on benign inputs while producing unsafe completions for 86% of adversarial prompts, far exceeding both Meditron-7B (66%) and the untuned base model (46%). This reveals a pronounced functional-ethical gap, task utility transfers, while alignment collapses. To analyze this collapse, we develop a dynamic adversarial evaluation framework combining Generative Query (GQ)-based harmful prompt generation, verifier filtering, category-wise failure analysis, and adaptive Random Search (RS) jailbreak attacks. We also propose a layered defense system, as a prototype detector for real-time alignment drift in black-box deployments. Our findings show that benign-only black-box distillation exposes a practical and under-recognized threat: adversaries can cheaply replicate medical LLM capabilities while stripping safety mechanisms, underscoring the need for extraction-aware safety monitoring.
Computer Users Have Unique Yet Temporally Inconsistent Computer Usage Profiles
May 20, 2021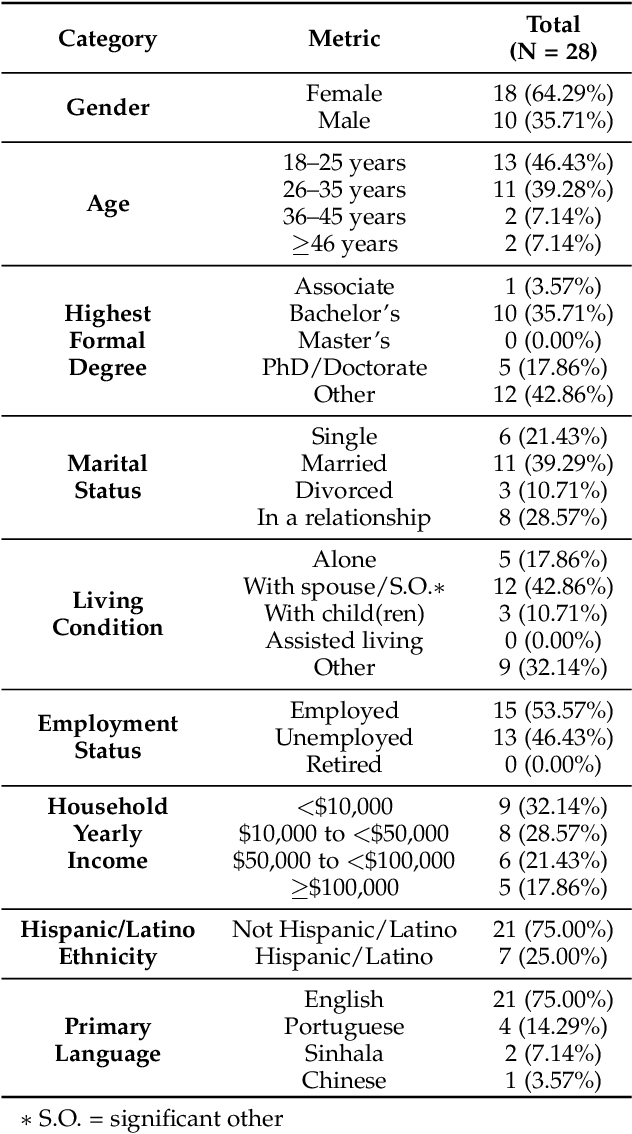
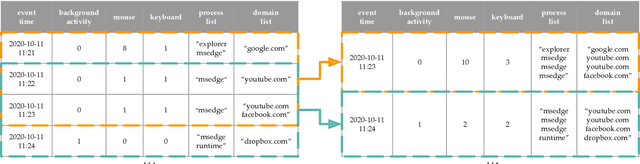
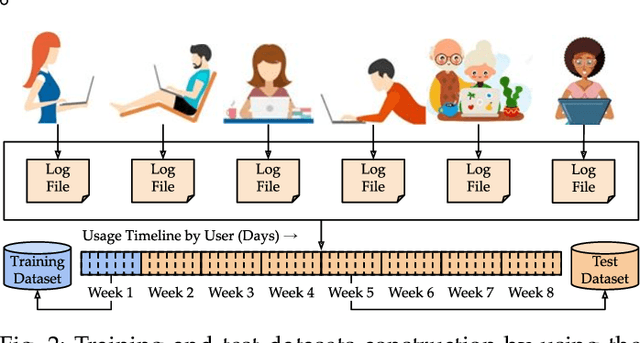
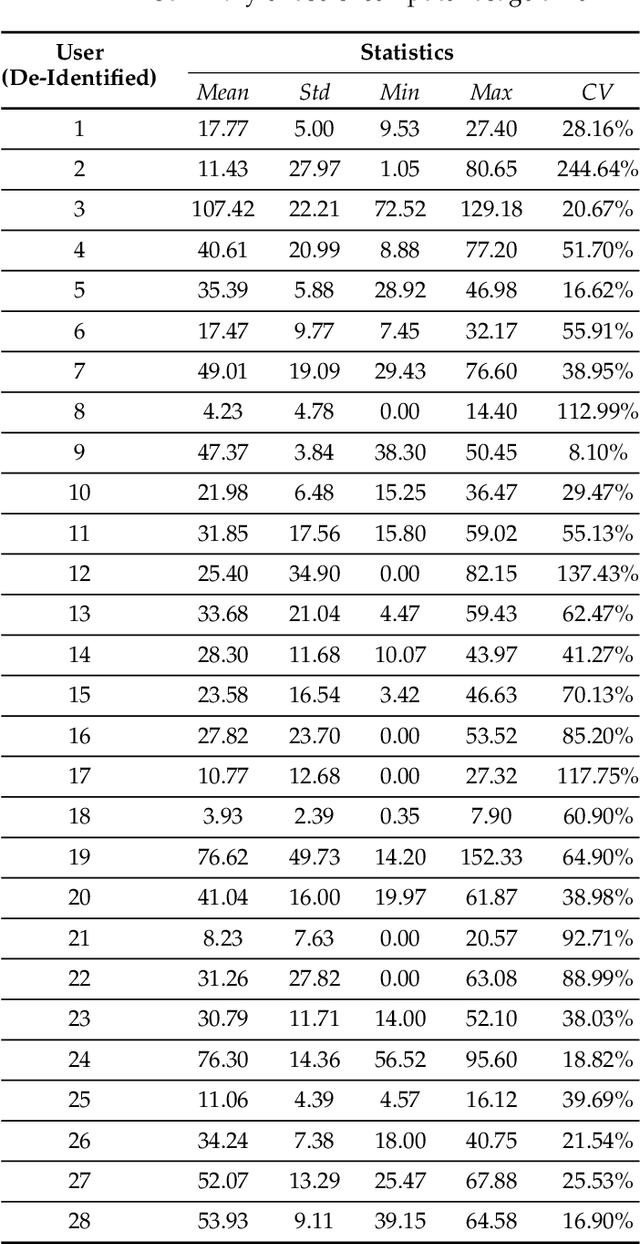
This paper investigates whether computer usage profiles comprised of process-, network-, mouse- and keystroke-related events are unique and temporally consistent in a naturalistic setting, discussing challenges and opportunities of using such profiles in applications of continuous authentication. We collected ecologically-valid computer usage profiles from 28 MS Windows 10 computer users over 8 weeks and submitted this data to comprehensive machine learning analysis involving a diverse set of online and offline classifiers. We found that (i) computer usage profiles have the potential to uniquely characterize computer users (with a maximum F-score of 99.94%); (ii) network-related events were the most useful features to properly recognize profiles (95.14% of the top features distinguishing users being network-related); (iii) user profiles were mostly inconsistent over the 8-week data collection period, with 92.86% of users exhibiting drifts in terms of time and usage habits; and (iv) online models are better suited to handle computer usage profiles compared to offline models (maximum F-score for each approach was 95.99% and 99.94%, respectively).
ShadowNet: A Secure and Efficient System for On-device Model Inference
Nov 11, 2020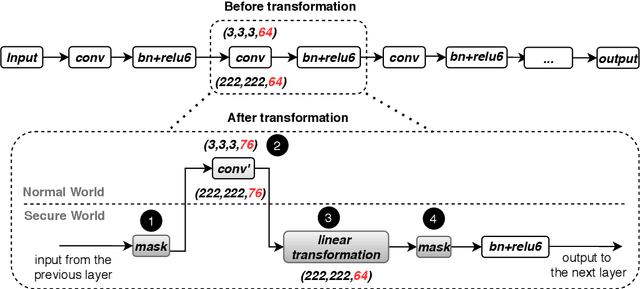
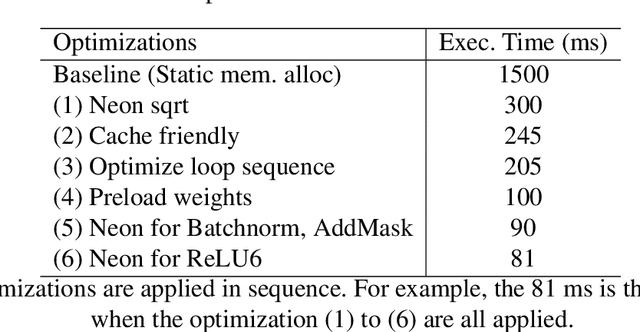
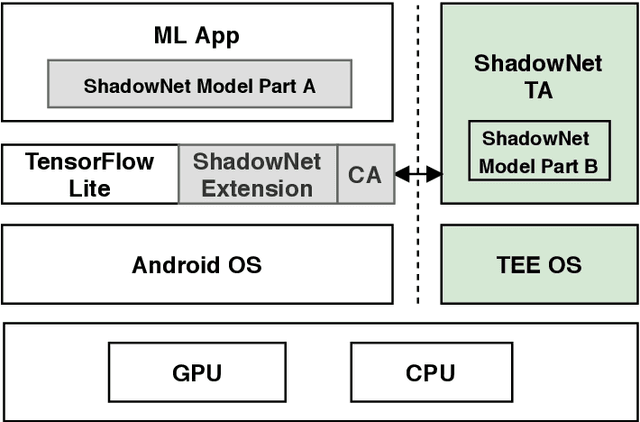
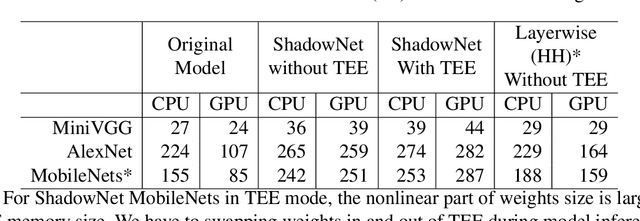
On-device machine learning (ML) is getting more and more popular as fast evolving AI accelerators emerge on mobile and edge devices. Consequently, thousands of proprietary ML models are being deployed on billions of untrusted devices, raising a serious security concern about the model privacy. However, how to protect the model privacy without losing access to the AI accelerators is a challenging problem. This paper presents a novel on-device model inference system called ShadowNet, which protects the model privacy with TEE while securely outsourcing the heavy linear layers of the model onto the hardware accelerators without trusting them. ShadowNet achieves it by transforming the weights of the linear layers before outsourcing them and restoring the results inside the TEE. The nonlinear layers are also kept secure inside the TEE. The transformation of the weights and the restoration of the results are designed in a way that can be implemented efficiently. We have built a ShadowNet prototype based on TensorFlow Lite and applied it on three popular CNNs including AlexNet, MiniVGG and MobileNets. Our evaluation shows that the ShadowNet transformed models have comparable performance with the original models, offering a promising solution for secure on-device model inference.
Mind Your Weight: A Large-scale Study on Insufficient Machine Learning Model Protection in Mobile Apps
Feb 18, 2020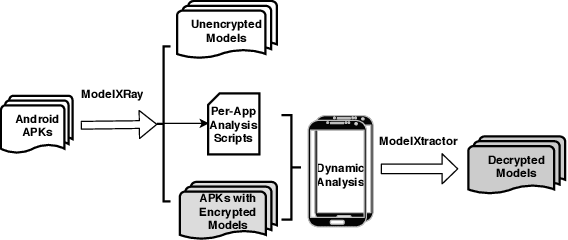
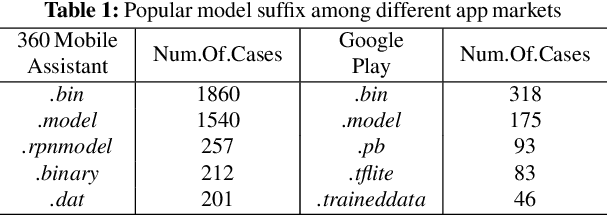
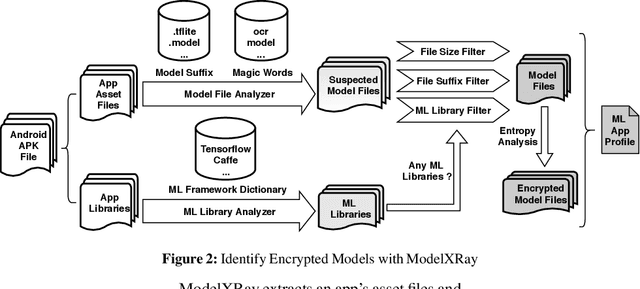
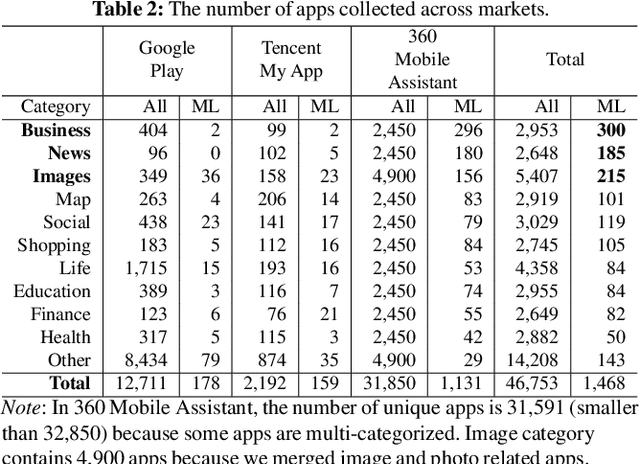
On-device machine learning (ML) is quickly gaining popularity among mobile apps. It allows offline model inference while preserving user privacy. However, ML models, considered as core intellectual properties of model owners, are now stored on billions of untrusted devices and subject to potential thefts. Leaked models can cause both severe financial loss and security consequences. This paper presents the first empirical study of ML model protection on mobile devices. Our study aims to answer three open questions with quantitative evidence: How widely is model protection used in apps? How robust are existing model protection techniques? How much can (stolen) models cost? To that end, we built a simple app analysis pipeline and analyzed 46,753 popular apps collected from the US and Chinese app markets. We identified 1,468 ML apps spanning all popular app categories. We found that, alarmingly, 41% of ML apps do not protect their models at all, which can be trivially stolen from app packages. Even for those apps that use model protection or encryption, we were able to extract the models from 66% of them via unsophisticated dynamic analysis techniques. The extracted models are mostly commercial products and used for face recognition, liveness detection, ID/bank card recognition, and malware detection. We quantitatively estimated the potential financial impact of a leaked model, which can amount to millions of dollars for different stakeholders. Our study reveals that on-device models are currently at high risk of being leaked; attackers are highly motivated to steal such models. Drawn from our large-scale study, we report our insights into this emerging security problem and discuss the technical challenges, hoping to inspire future research on robust and practical model protection for mobile devices.
Learning Fast and Slow: PROPEDEUTICA for Real-time Malware Detection
Dec 04, 2017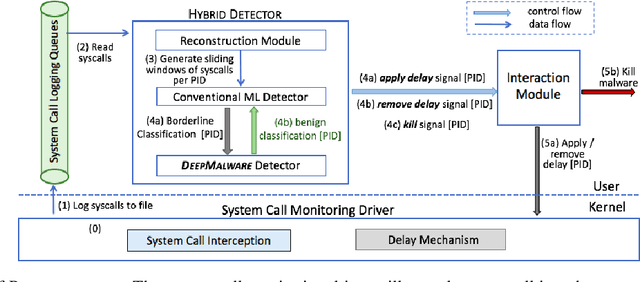
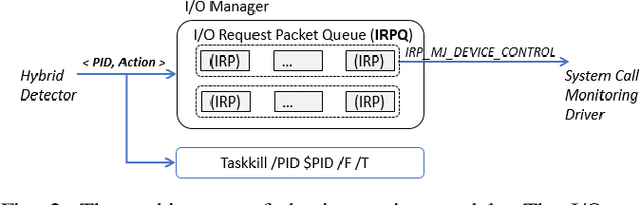
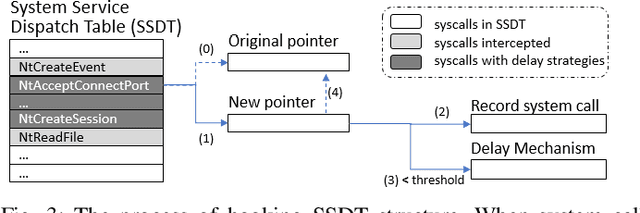
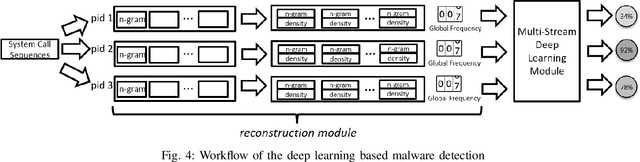
In this paper, we introduce and evaluate PROPEDEUTICA, a novel methodology and framework for efficient and effective real-time malware detection, leveraging the best of conventional machine learning (ML) and deep learning (DL) algorithms. In PROPEDEUTICA, all software processes in the system start execution subjected to a conventional ML detector for fast classification. If a piece of software receives a borderline classification, it is subjected to further analysis via more performance expensive and more accurate DL methods, via our newly proposed DL algorithm DEEPMALWARE. Further, we introduce delays to the execution of software subjected to deep learning analysis as a way to "buy time" for DL analysis and to rate-limit the impact of possible malware in the system. We evaluated PROPEDEUTICA with a set of 9,115 malware samples and 877 commonly used benign software samples from various categories for the Windows OS. Our results show that the false positive rate for conventional ML methods can reach 20%, and for modern DL methods it is usually below 6%. However, the classification time for DL can be 100X longer than conventional ML methods. PROPEDEUTICA improved the detection F1-score from 77.54% (conventional ML method) to 90.25%, and reduced the detection time by 54.86%. Further, the percentage of software subjected to DL analysis was approximately 40% on average. Further, the application of delays in software subjected to ML reduced the detection time by approximately 10%. Finally, we found and discussed a discrepancy between the detection accuracy offline (analysis after all traces are collected) and on-the-fly (analysis in tandem with trace collection). Our insights show that conventional ML and modern DL-based malware detectors in isolation cannot meet the needs of efficient and effective malware detection: high accuracy, low false positive rate, and short classification time.