 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSilverTorch: A Unified Model-based System to Democratize Large-Scale Recommendation on GPUs
Nov 18, 2025Serving deep learning based recommendation models (DLRM) at scale is challenging. Existing systems rely on CPU-based ANN indexing and filtering services, suffering from non-negligible costs and forgoing joint optimization opportunities. Such inefficiency makes them difficult to support more complex model architectures, such as learned similarities and multi-task retrieval. In this paper, we propose SilverTorch, a model-based system for serving recommendation models on GPUs. SilverTorch unifies model serving by replacing standalone indexing and filtering services with layers of served models. We propose a Bloom index algorithm on GPUs for feature filtering and a tensor-native fused Int8 ANN kernel on GPUs for nearest neighbor search. We further co-design the ANN search index and filtering index to reduce GPU memory utilization and eliminate unnecessary computation. Benefit from SilverTorch's serving paradigm, we introduce a OverArch scoring layer and a Value Model to aggregate results across multi-tasks. These advancements improve the accuracy for retrieval and enable future studies for serving more complex models. For ranking, SilverTorch's design accelerates item embedding calculation by caching the pre-calculated embeddings inside the serving model. Our evaluation on the industry-scale datasets show that SilverTorch achieves up to 5.6x lower latency and 23.7x higher throughput compared to the state-of-the-art approaches. We also demonstrate that SilverTorch's solution is 13.35x more cost-efficient than CPU-based solution while improving accuracy via serving more complex models. SilverTorch serves over hundreds of models online across major products and recommends contents for billions of daily active users.
A Method for Enhancing the Safety of Large Model Generation Based on Multi-dimensional Attack and Defense
Dec 31, 2024



Currently, large models are prone to generating harmful content when faced with complex attack instructions, significantly reducing their defensive capabilities. To address this issue, this paper proposes a method based on constructing data aligned with multi-dimensional attack defense to enhance the generative security of large models. The core of our method lies in improving the effectiveness of safe alignment learning for large models by innova-tively increasing the diversity of attack instruction dimensions and the accuracy of generat-ing safe responses. To validate the effectiveness of our method, beyond existing security evaluation benchmarks, we additionally designed new security evaluation benchmarks and conducted comparative experiments using Llama3.2 as the baseline model. The final ex-perimental results demonstrate that our method can significantly improve the generative security of large models under complex instructional attacks, while also maintaining and enhancing the models' general capabilities.
A Post-Training Enhanced Optimization Approach for Small Language Models
Nov 05, 2024



This paper delves into the continuous post-training optimization methods for small language models, and proposes a continuous post-training alignment data construction method for small language models. The core of this method is based on the data guidance of large models, optimizing the diversity and accuracy of alignment data. In addition, to verify the effectiveness of the methods in this paper, we used Qwen2-0.5B-Instruct model as the baseline model for small language models, using the alignment dataset constructed by our proposed method, we trained and compared several groups of experiments, including SFT (Supervised Fine Tuning) post-training experiment and KTO (Kahneman Tversky optimization) post-training experiment, as well as SFT-KTO two-stage post-training experiment and model weight fusion experiment. Finally, we evaluated and analyzed the performance of post-training models, and confirmed that the continuous post-training optimization method proposed by us can significantly improve the performance of small language models.
SparsePipe: Parallel Deep Learning for 3D Point Clouds
Dec 27, 2020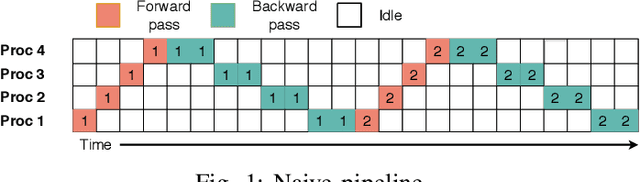
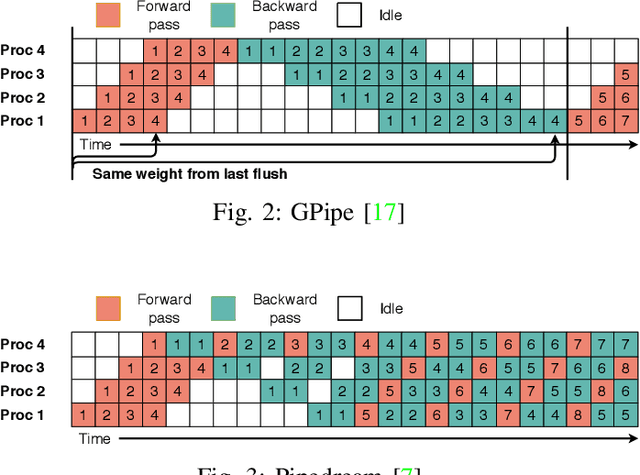
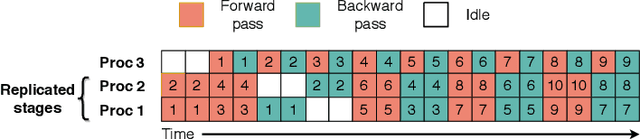
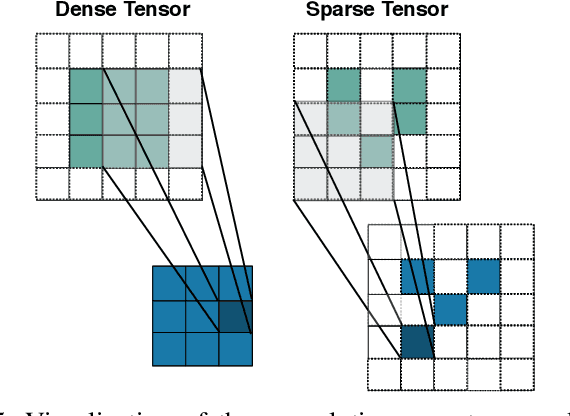
We propose SparsePipe, an efficient and asynchronous parallelism approach for handling 3D point clouds with multi-GPU training. SparsePipe is built to support 3D sparse data such as point clouds. It achieves this by adopting generalized convolutions with sparse tensor representation to build expressive high-dimensional convolutional neural networks. Compared to dense solutions, the new models can efficiently process irregular point clouds without densely sliding over the entire space, significantly reducing the memory requirements and allowing higher resolutions of the underlying 3D volumes for better performance. SparsePipe exploits intra-batch parallelism that partitions input data into multiple processors and further improves the training throughput with inter-batch pipelining to overlap communication and computing. Besides, it suitably partitions the model when the GPUs are heterogeneous such that the computing is load-balanced with reduced communication overhead. Using experimental results on an eight-GPU platform, we show that SparsePipe can parallelize effectively and obtain better performance on current point cloud benchmarks for both training and inference, compared to its dense solutions.