 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelational inductive biases, deep learning, and graph networks
Oct 17, 2018
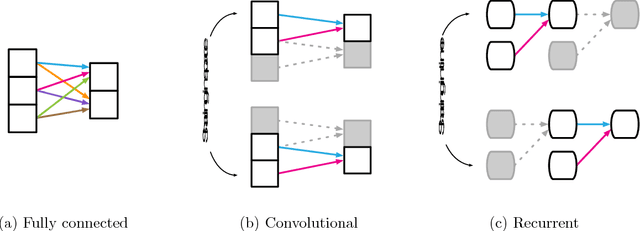
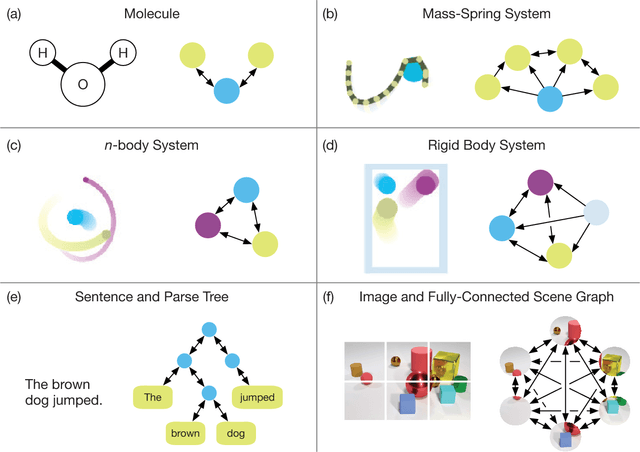
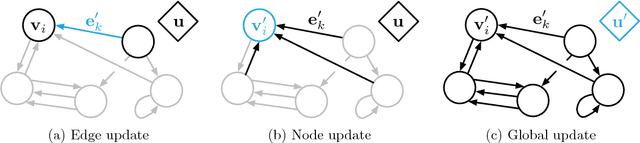
Artificial intelligence (AI) has undergone a renaissance recently, making major progress in key domains such as vision, language, control, and decision-making. This has been due, in part, to cheap data and cheap compute resources, which have fit the natural strengths of deep learning. However, many defining characteristics of human intelligence, which developed under much different pressures, remain out of reach for current approaches. In particular, generalizing beyond one's experiences--a hallmark of human intelligence from infancy--remains a formidable challenge for modern AI. The following is part position paper, part review, and part unification. We argue that combinatorial generalization must be a top priority for AI to achieve human-like abilities, and that structured representations and computations are key to realizing this objective. Just as biology uses nature and nurture cooperatively, we reject the false choice between "hand-engineering" and "end-to-end" learning, and instead advocate for an approach which benefits from their complementary strengths. We explore how using relational inductive biases within deep learning architectures can facilitate learning about entities, relations, and rules for composing them. We present a new building block for the AI toolkit with a strong relational inductive bias--the graph network--which generalizes and extends various approaches for neural networks that operate on graphs, and provides a straightforward interface for manipulating structured knowledge and producing structured behaviors. We discuss how graph networks can support relational reasoning and combinatorial generalization, laying the foundation for more sophisticated, interpretable, and flexible patterns of reasoning. As a companion to this paper, we have released an open-source software library for building graph networks, with demonstrations of how to use them in practice.
Meta-Learning with Latent Embedding Optimization
Sep 28, 2018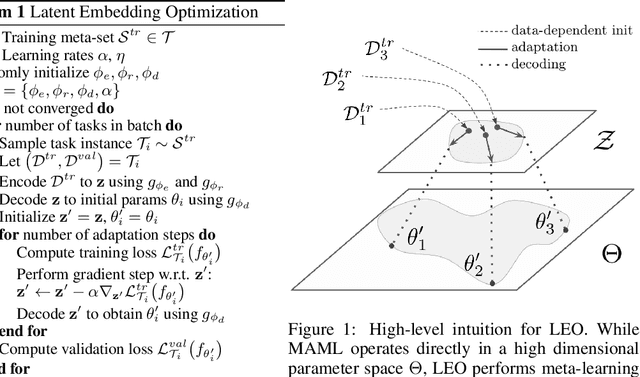
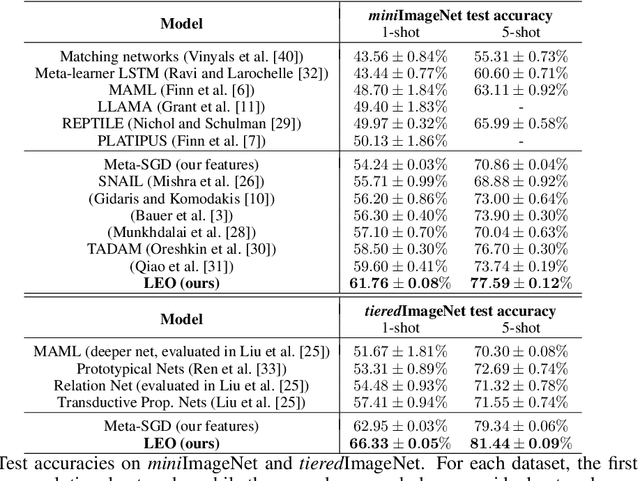
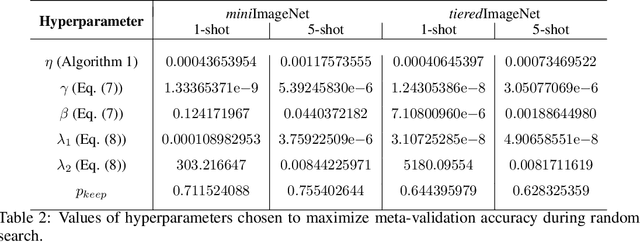
Gradient-based meta-learning techniques are both widely applicable and proficient at solving challenging few-shot learning and fast adaptation problems. However, they have practical difficulties when operating on high-dimensional parameter spaces in extreme low-data regimes. We show that it is possible to bypass these limitations by learning a data-dependent latent generative representation of model parameters, and performing gradient-based meta-learning in this low-dimensional latent space. The resulting approach, latent embedding optimization (LEO), decouples the gradient-based adaptation procedure from the underlying high-dimensional space of model parameters. Our evaluation shows that LEO can achieve state-of-the-art performance on the competitive miniImageNet and tieredImageNet few-shot classification tasks. Further analysis indicates LEO is able to capture uncertainty in the data, and can perform adaptation more effectively by optimizing in latent space.
Sample Efficient Adaptive Text-to-Speech
Sep 27, 2018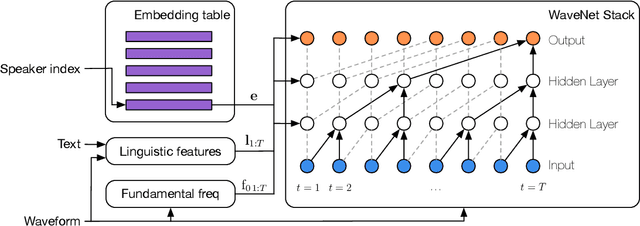
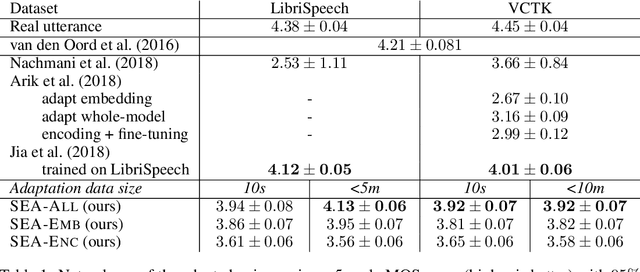
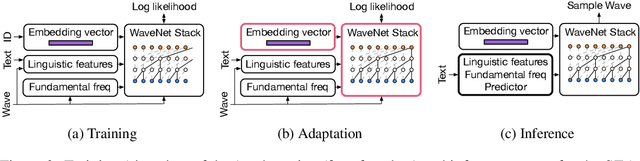
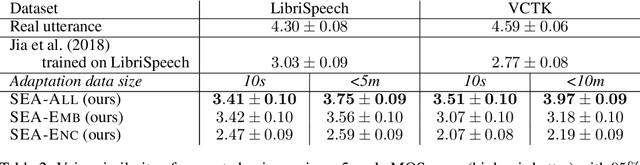
We present a meta-learning approach for adaptive text-to-speech (TTS) with few data. During training, we learn a multi-speaker model using a shared conditional WaveNet core and independent learned embeddings for each speaker. The aim of training is not to produce a neural network with fixed weights, which is then deployed as a TTS system. Instead, the aim is to produce a network that requires few data at deployment time to rapidly adapt to new speakers. We introduce and benchmark three strategies: (i) learning the speaker embedding while keeping the WaveNet core fixed, (ii) fine-tuning the entire architecture with stochastic gradient descent, and (iii) predicting the speaker embedding with a trained neural network encoder. The experiments show that these approaches are successful at adapting the multi-speaker neural network to new speakers, obtaining state-of-the-art results in both sample naturalness and voice similarity with merely a few minutes of audio data from new speakers.
Deep Audio-Visual Speech Recognition
Sep 06, 2018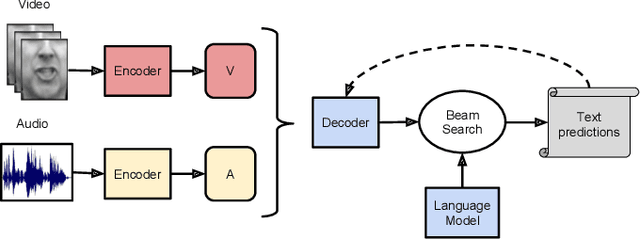
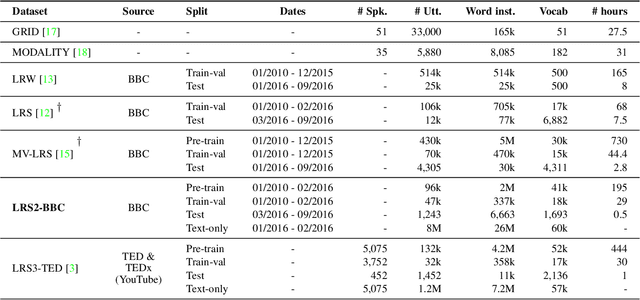
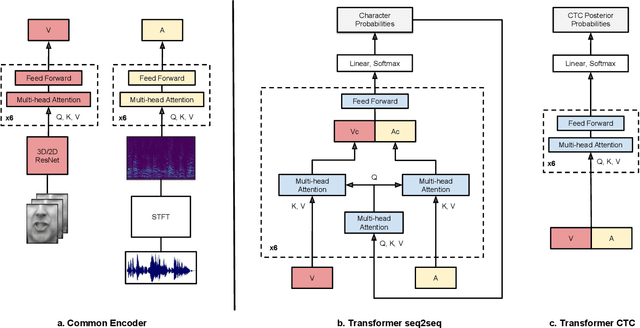
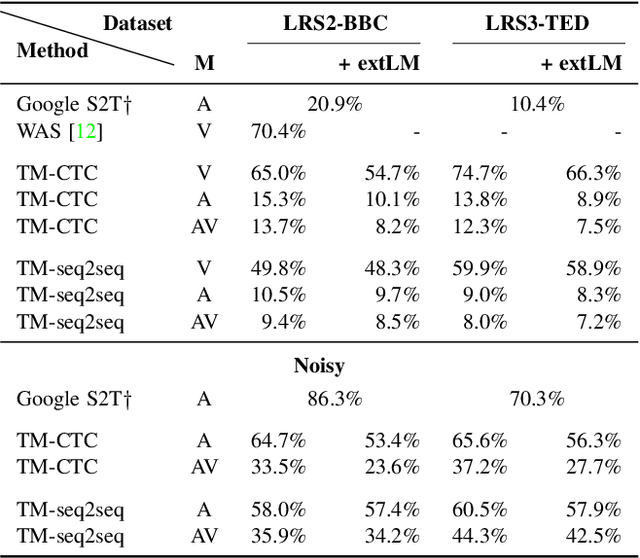
The goal of this work is to recognise phrases and sentences being spoken by a talking face, with or without the audio. Unlike previous works that have focussed on recognising a limited number of words or phrases, we tackle lip reading as an open-world problem - unconstrained natural language sentences, and in the wild videos. Our key contributions are: (1) we compare two models for lip reading, one using a CTC loss, and the other using a sequence-to-sequence loss. Both models are built on top of the transformer self-attention architecture; (2) we investigate to what extent lip reading is complementary to audio speech recognition, especially when the audio signal is noisy; (3) we introduce and publicly release a new dataset for audio-visual speech recognition, LRS2-BBC, consisting of thousands of natural sentences from British television. The models that we train surpass the performance of all previous work on a lip reading benchmark dataset by a significant margin.
Learning to Search with MCTSnets
Jul 17, 2018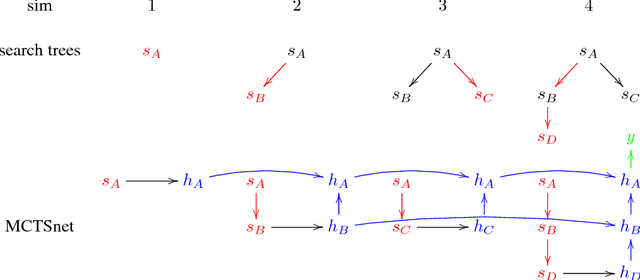
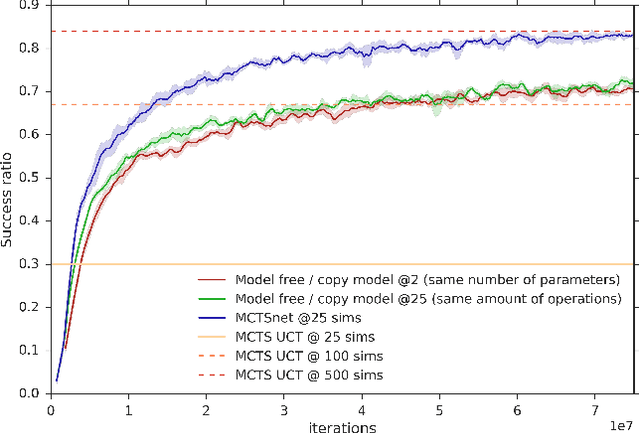
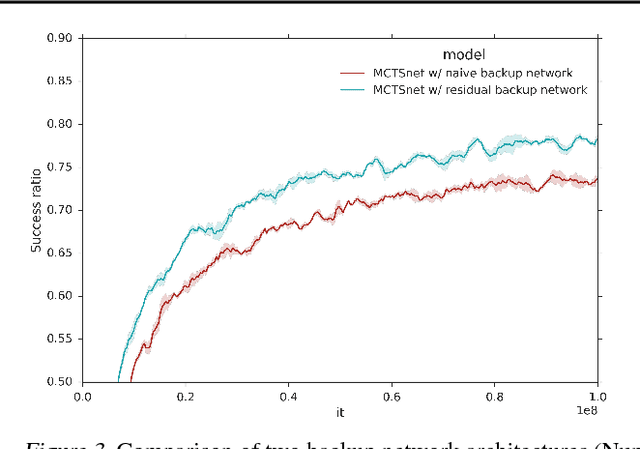
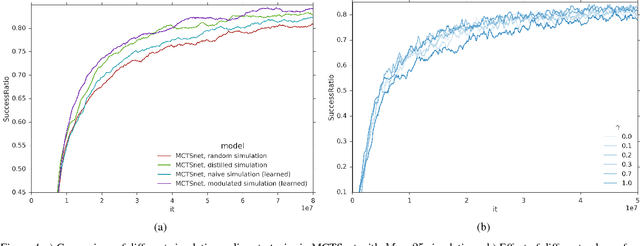
Planning problems are among the most important and well-studied problems in artificial intelligence. They are most typically solved by tree search algorithms that simulate ahead into the future, evaluate future states, and back-up those evaluations to the root of a search tree. Among these algorithms, Monte-Carlo tree search (MCTS) is one of the most general, powerful and widely used. A typical implementation of MCTS uses cleverly designed rules, optimized to the particular characteristics of the domain. These rules control where the simulation traverses, what to evaluate in the states that are reached, and how to back-up those evaluations. In this paper we instead learn where, what and how to search. Our architecture, which we call an MCTSnet, incorporates simulation-based search inside a neural network, by expanding, evaluating and backing-up a vector embedding. The parameters of the network are trained end-to-end using gradient-based optimisation. When applied to small searches in the well known planning problem Sokoban, the learned search algorithm significantly outperformed MCTS baselines.
Universal Transformers
Jul 10, 2018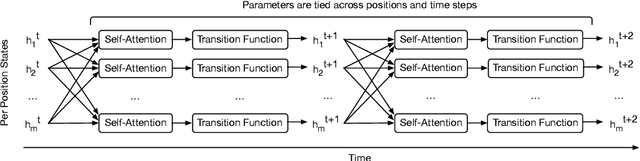
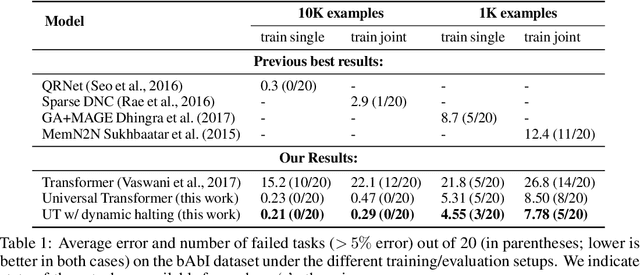
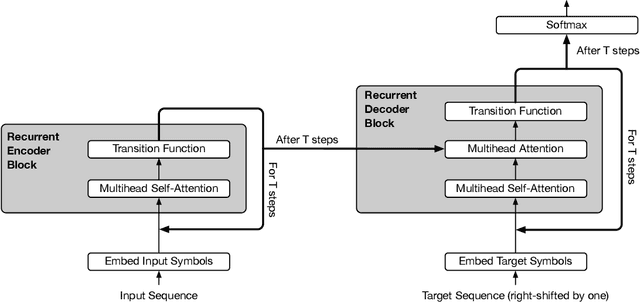
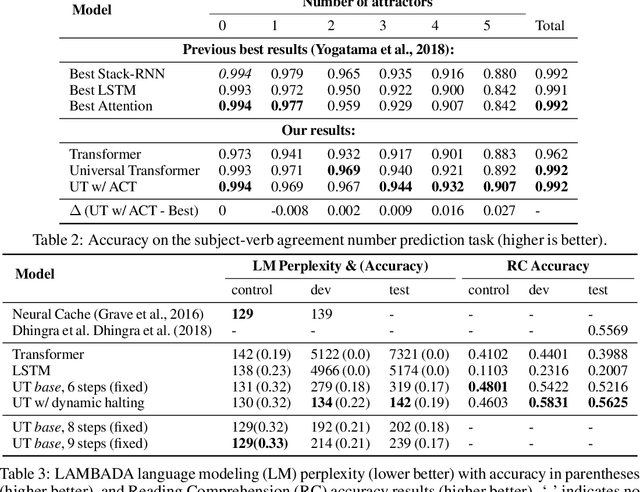
Self-attentive feed-forward sequence models have been shown to achieve impressive results on sequence modeling tasks, thereby presenting a compelling alternative to recurrent neural networks (RNNs) which has remained the de-facto standard architecture for many sequence modeling problems to date. Despite these successes, however, feed-forward sequence models like the Transformer fail to generalize in many tasks that recurrent models handle with ease (e.g. copying when the string lengths exceed those observed at training time). Moreover, and in contrast to RNNs, the Transformer model is not computationally universal, limiting its theoretical expressivity. In this paper we propose the Universal Transformer which addresses these practical and theoretical shortcomings and we show that it leads to improved performance on several tasks. Instead of recurring over the individual symbols of sequences like RNNs, the Universal Transformer repeatedly revises its representations of all symbols in the sequence with each recurrent step. In order to combine information from different parts of a sequence, it employs a self-attention mechanism in every recurrent step. Assuming sufficient memory, its recurrence makes the Universal Transformer computationally universal. We further employ an adaptive computation time (ACT) mechanism to allow the model to dynamically adjust the number of times the representation of each position in a sequence is revised. Beyond saving computation, we show that ACT can improve the accuracy of the model. Our experiments show that on various algorithmic tasks and a diverse set of large-scale language understanding tasks the Universal Transformer generalizes significantly better and outperforms both a vanilla Transformer and an LSTM in machine translation, and achieves a new state of the art on the bAbI linguistic reasoning task and the challenging LAMBADA language modeling task.
Representation Learning with Contrastive Predictive Coding
Jul 10, 2018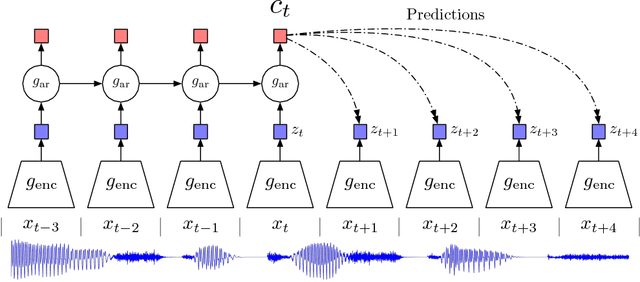
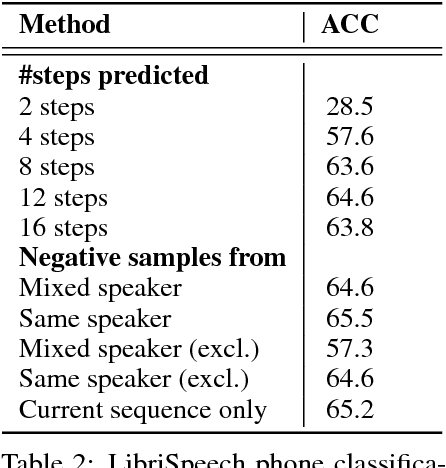
While supervised learning has enabled great progress in many applications, unsupervised learning has not seen such widespread adoption, and remains an important and challenging endeavor for artificial intelligence. In this work, we propose a universal unsupervised learning approach to extract useful representations from high-dimensional data, which we call Contrastive Predictive Coding. The key insight of our model is to learn such representations by predicting the future in latent space by using powerful autoregressive models. We use a probabilistic contrastive loss which induces the latent space to capture information that is maximally useful to predict future samples. It also makes the model tractable by using negative sampling. While most prior work has focused on evaluating representations for a particular modality, we demonstrate that our approach is able to learn useful representations achieving strong performance on four distinct domains: speech, images, text and reinforcement learning in 3D environments.
Relational recurrent neural networks
Jun 28, 2018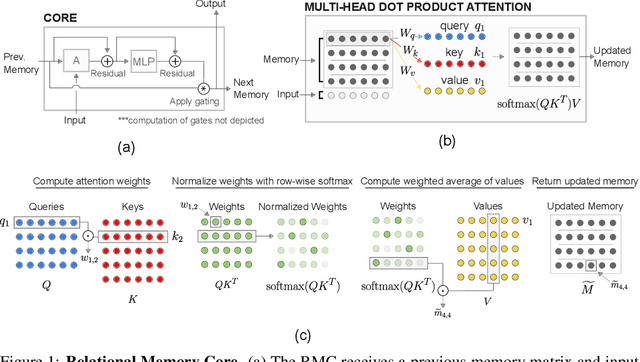
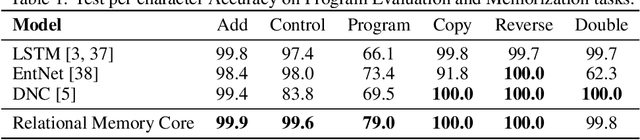
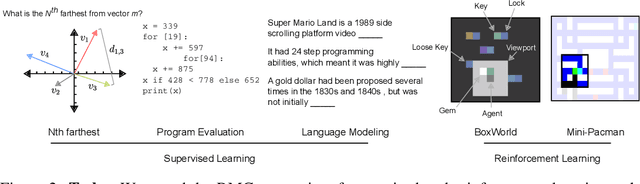
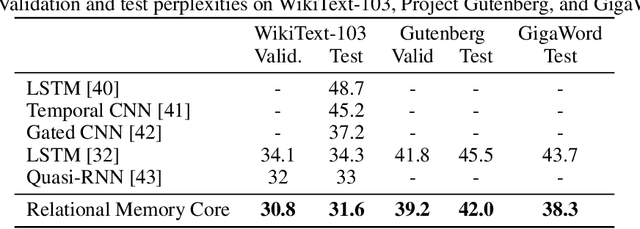
Memory-based neural networks model temporal data by leveraging an ability to remember information for long periods. It is unclear, however, whether they also have an ability to perform complex relational reasoning with the information they remember. Here, we first confirm our intuitions that standard memory architectures may struggle at tasks that heavily involve an understanding of the ways in which entities are connected -- i.e., tasks involving relational reasoning. We then improve upon these deficits by using a new memory module -- a \textit{Relational Memory Core} (RMC) -- which employs multi-head dot product attention to allow memories to interact. Finally, we test the RMC on a suite of tasks that may profit from more capable relational reasoning across sequential information, and show large gains in RL domains (e.g. Mini PacMan), program evaluation, and language modeling, achieving state-of-the-art results on the WikiText-103, Project Gutenberg, and GigaWord datasets.
Relational Deep Reinforcement Learning
Jun 28, 2018
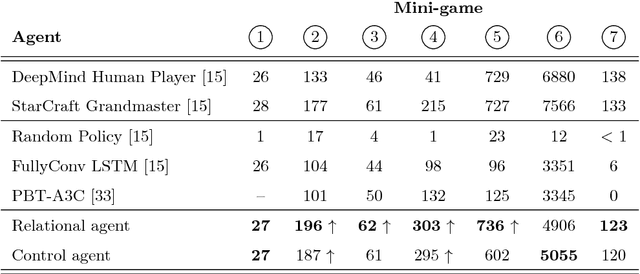
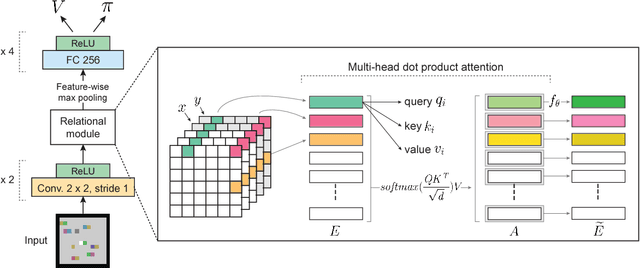
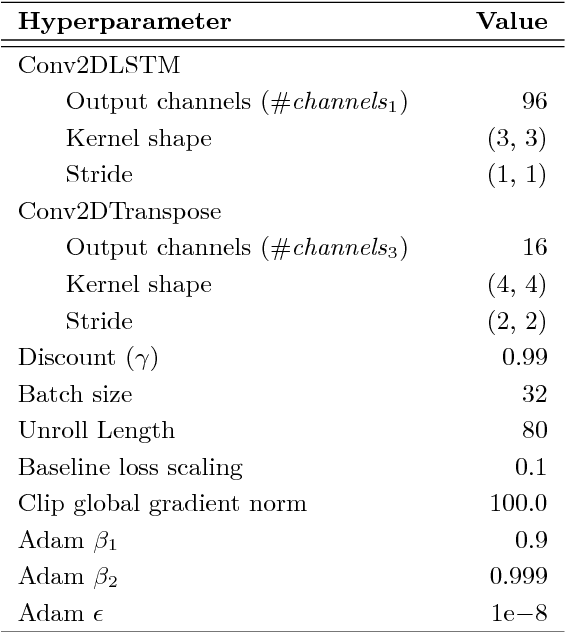
We introduce an approach for deep reinforcement learning (RL) that improves upon the efficiency, generalization capacity, and interpretability of conventional approaches through structured perception and relational reasoning. It uses self-attention to iteratively reason about the relations between entities in a scene and to guide a model-free policy. Our results show that in a novel navigation and planning task called Box-World, our agent finds interpretable solutions that improve upon baselines in terms of sample complexity, ability to generalize to more complex scenes than experienced during training, and overall performance. In the StarCraft II Learning Environment, our agent achieves state-of-the-art performance on six mini-games -- surpassing human grandmaster performance on four. By considering architectural inductive biases, our work opens new directions for overcoming important, but stubborn, challenges in deep RL.
Learning Implicit Generative Models with the Method of Learned Moments
Jun 28, 2018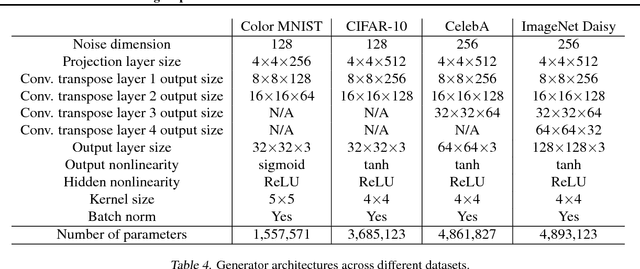
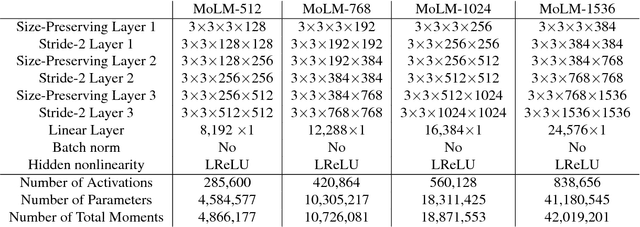

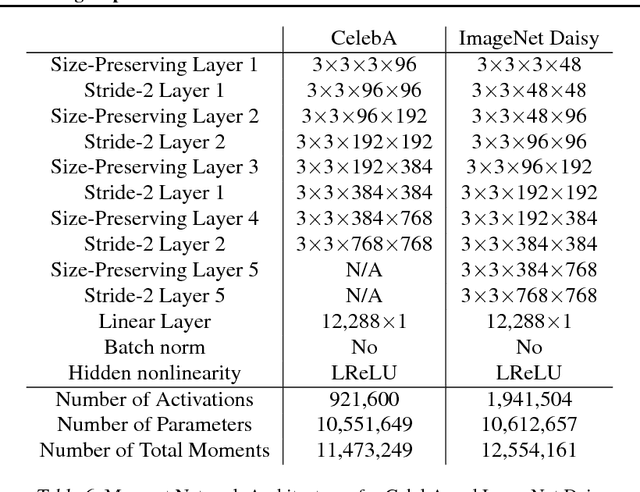
We propose a method of moments (MoM) algorithm for training large-scale implicit generative models. Moment estimation in this setting encounters two problems: it is often difficult to define the millions of moments needed to learn the model parameters, and it is hard to determine which properties are useful when specifying moments. To address the first issue, we introduce a moment network, and define the moments as the network's hidden units and the gradient of the network's output with the respect to its parameters. To tackle the second problem, we use asymptotic theory to highlight desiderata for moments -- namely they should minimize the asymptotic variance of estimated model parameters -- and introduce an objective to learn better moments. The sequence of objectives created by this Method of Learned Moments (MoLM) can train high-quality neural image samplers. On CIFAR-10, we demonstrate that MoLM-trained generators achieve significantly higher Inception Scores and lower Frechet Inception Distances than those trained with gradient penalty-regularized and spectrally-normalized adversarial objectives. These generators also achieve nearly perfect Multi-Scale Structural Similarity Scores on CelebA, and can create high-quality samples of 128x128 images.