 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Jun 30, 2020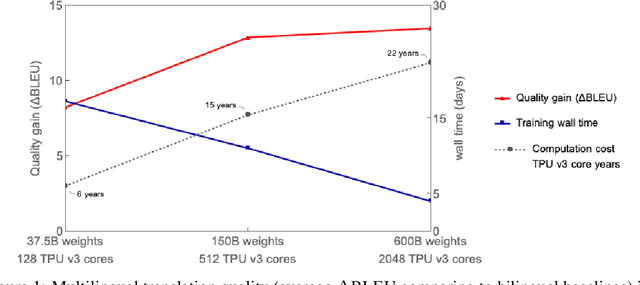
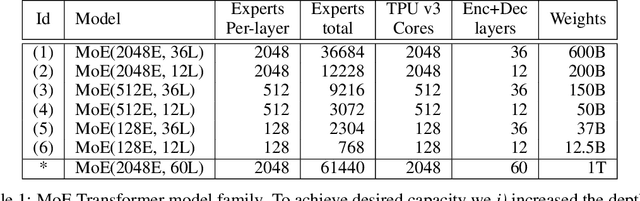
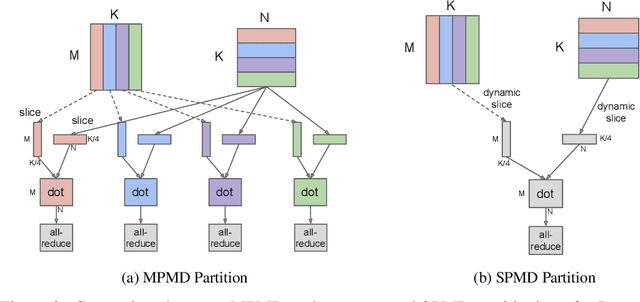
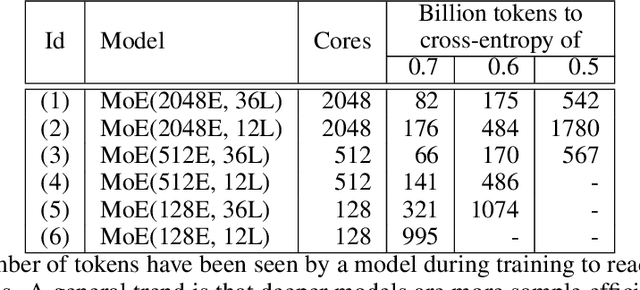
Neural network scaling has been critical for improving the model quality in many real-world machine learning applications with vast amounts of training data and compute. Although this trend of scaling is affirmed to be a sure-fire approach for better model quality, there are challenges on the path such as the computation cost, ease of programming, and efficient implementation on parallel devices. GShard is a module composed of a set of lightweight annotation APIs and an extension to the XLA compiler. It provides an elegant way to express a wide range of parallel computation patterns with minimal changes to the existing model code. GShard enabled us to scale up multilingual neural machine translation Transformer model with Sparsely-Gated Mixture-of-Experts beyond 600 billion parameters using automatic sharding. We demonstrate that such a giant model can efficiently be trained on 2048 TPU v3 accelerators in 4 days to achieve far superior quality for translation from 100 languages to English compared to the prior art.
Leveraging Monolingual Data with Self-Supervision for Multilingual Neural Machine Translation
May 11, 2020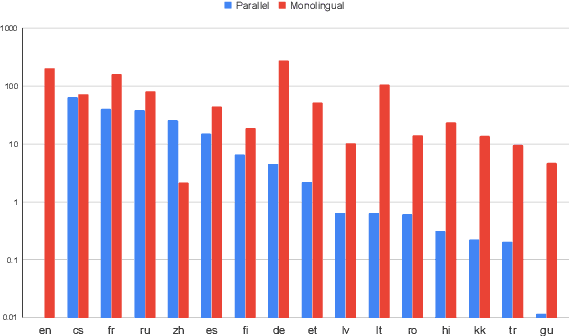

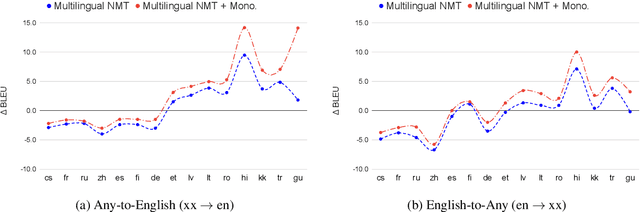
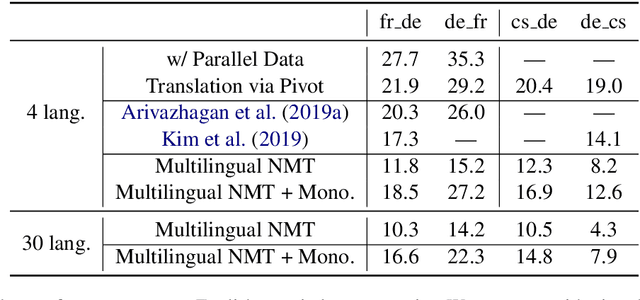
Over the last few years two promising research directions in low-resource neural machine translation (NMT) have emerged. The first focuses on utilizing high-resource languages to improve the quality of low-resource languages via multilingual NMT. The second direction employs monolingual data with self-supervision to pre-train translation models, followed by fine-tuning on small amounts of supervised data. In this work, we join these two lines of research and demonstrate the efficacy of monolingual data with self-supervision in multilingual NMT. We offer three major results: (i) Using monolingual data significantly boosts the translation quality of low-resource languages in multilingual models. (ii) Self-supervision improves zero-shot translation quality in multilingual models. (iii) Leveraging monolingual data with self-supervision provides a viable path towards adding new languages to multilingual models, getting up to 33 BLEU on ro-en translation without any parallel data or back-translation.
XTREME: A Massively Multilingual Multi-task Benchmark for Evaluating Cross-lingual Generalization
Apr 10, 2020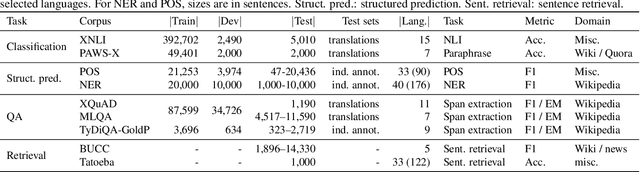
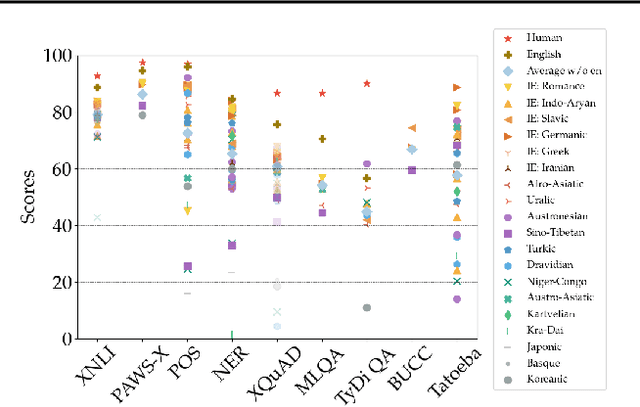
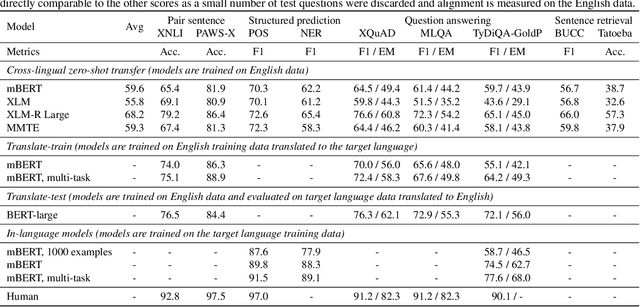
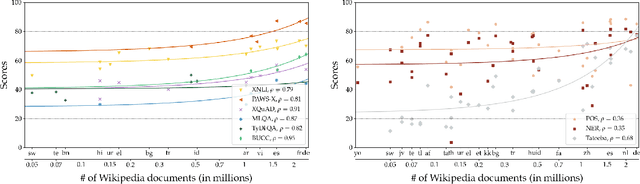
Much recent progress in applications of machine learning models to NLP has been driven by benchmarks that evaluate models across a wide variety of tasks. However, these broad-coverage benchmarks have been mostly limited to English, and despite an increasing interest in multilingual models, a benchmark that enables the comprehensive evaluation of such methods on a diverse range of languages and tasks is still missing. To this end, we introduce the Cross-lingual TRansfer Evaluation of Multilingual Encoders XTREME benchmark, a multi-task benchmark for evaluating the cross-lingual generalization capabilities of multilingual representations across 40 languages and 9 tasks. We demonstrate that while models tested on English reach human performance on many tasks, there is still a sizable gap in the performance of cross-lingually transferred models, particularly on syntactic and sentence retrieval tasks. There is also a wide spread of results across languages. We release the benchmark to encourage research on cross-lingual learning methods that transfer linguistic knowledge across a diverse and representative set of languages and tasks.
On the Discrepancy between Density Estimation and Sequence Generation
Feb 17, 2020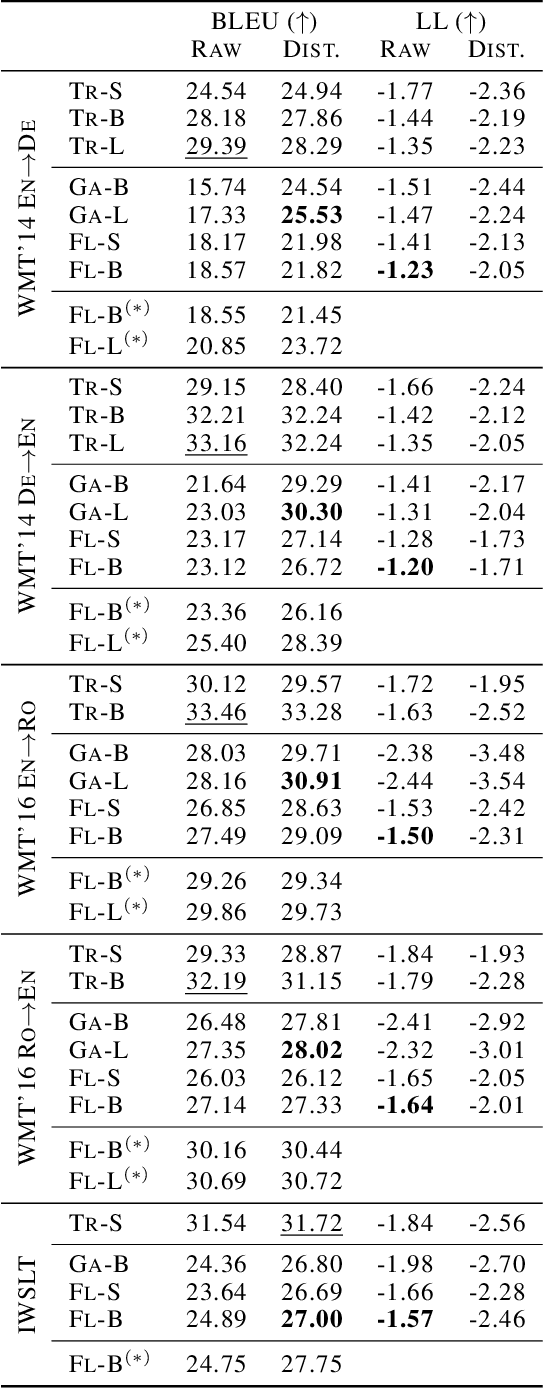
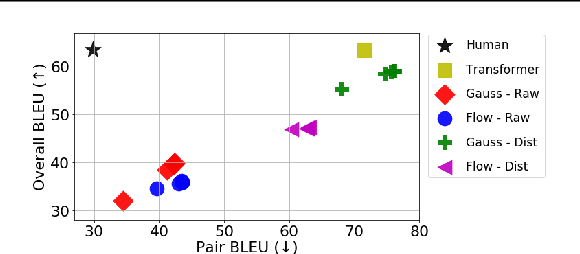

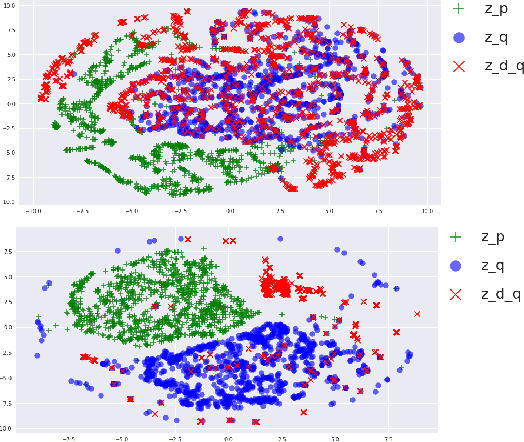
Many sequence-to-sequence generation tasks, including machine translation and text-to-speech, can be posed as estimating the density of the output y given the input x: p(y|x). Given this interpretation, it is natural to evaluate sequence-to-sequence models using conditional log-likelihood on a test set. However, the goal of sequence-to-sequence generation (or structured prediction) is to find the best output y^ given an input x, and each task has its own downstream metric R that scores a model output by comparing against a set of references y*: R(y^, y* | x). While we hope that a model that excels in density estimation also performs well on the downstream metric, the exact correlation has not been studied for sequence generation tasks. In this paper, by comparing several density estimators on five machine translation tasks, we find that the correlation between rankings of models based on log-likelihood and BLEU varies significantly depending on the range of the model families being compared. First, log-likelihood is highly correlated with BLEU when we consider models within the same family (e.g. autoregressive models, or latent variable models with the same parameterization of the prior). However, we observe no correlation between rankings of models across different families: (1) among non-autoregressive latent variable models, a flexible prior distribution is better at density estimation but gives worse generation quality than a simple prior, and (2) autoregressive models offer the best translation performance overall, while latent variable models with a normalizing flow prior give the highest held-out log-likelihood across all datasets. Therefore, we recommend using a simple prior for the latent variable non-autoregressive model when fast generation speed is desired.
Controlling Computation versus Quality for Neural Sequence Models
Feb 17, 2020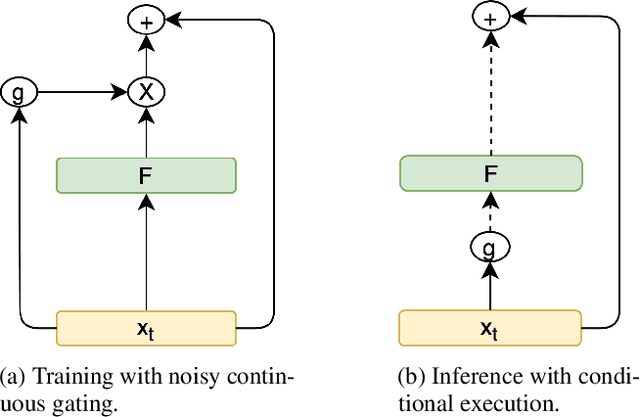
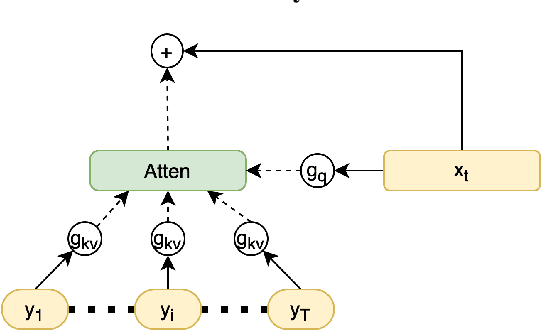
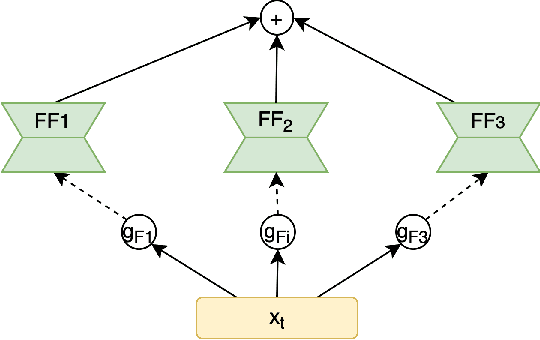
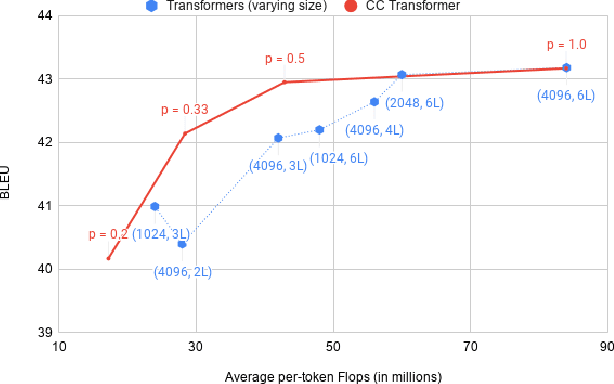
Most neural networks utilize the same amount of compute for every example independent of the inherent complexity of the input. Further, methods that adapt the amount of computation to the example focus on finding a fixed inference-time computational graph per example, ignoring any external computational budgets or varying inference time limitations. In this work, we utilize conditional computation to make neural sequence models (Transformer) more efficient and computation-aware during inference. We first modify the Transformer architecture, making each set of operations conditionally executable depending on the output of a learned control network. We then train this model in a multi-task setting, where each task corresponds to a particular computation budget. This allows us to train a single model that can be controlled to operate on different points of the computation-quality trade-off curve, depending on the available computation budget at inference time. We evaluate our approach on two tasks: (i) WMT English-French Translation and (ii) Unsupervised representation learning (BERT). Our experiments demonstrate that the proposed Conditional Computation Transformer (CCT) is competitive with vanilla Transformers when allowed to utilize its full computational budget, while improving significantly over computationally equivalent baselines when operating on smaller computational budgets.
Fill in the Blanks: Imputing Missing Sentences for Larger-Context Neural Machine Translation
Oct 30, 2019
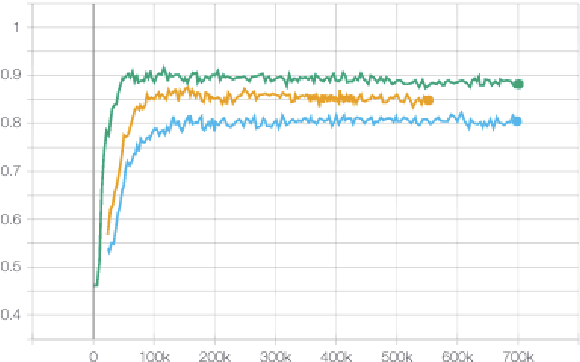
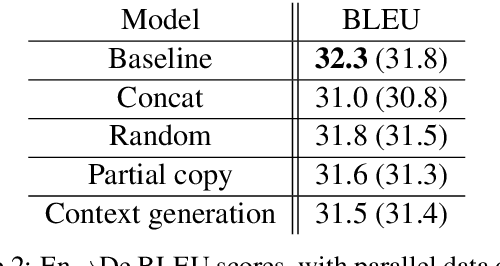
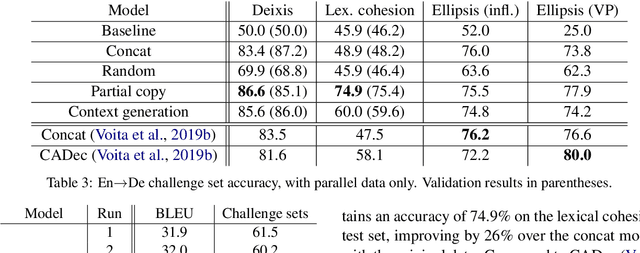
Most neural machine translation systems still translate sentences in isolation. To make further progress, a promising line of research additionally considers the surrounding context in order to provide the model potentially missing source-side information, as well as to maintain a coherent output. One difficulty in training such larger-context (i.e. document-level) machine translation systems is that context may be missing from many parallel examples. To circumvent this issue, two-stage approaches, in which sentence-level translations are post-edited in context, have recently been proposed. In this paper, we instead consider the viability of filling in the missing context. In particular, we consider three distinct approaches to generate the missing context: using random contexts, applying a copy heuristic or generating it with a language model. In particular, the copy heuristic significantly helps with lexical coherence, while using completely random contexts hurts performance on many long-distance linguistic phenomena. We also validate the usefulness of tagged back-translation. In addition to improving BLEU scores as expected, using back-translated data helps larger-context machine translation systems to better capture long-range phenomena.
On the Importance of Word Boundaries in Character-level Neural Machine Translation
Oct 21, 2019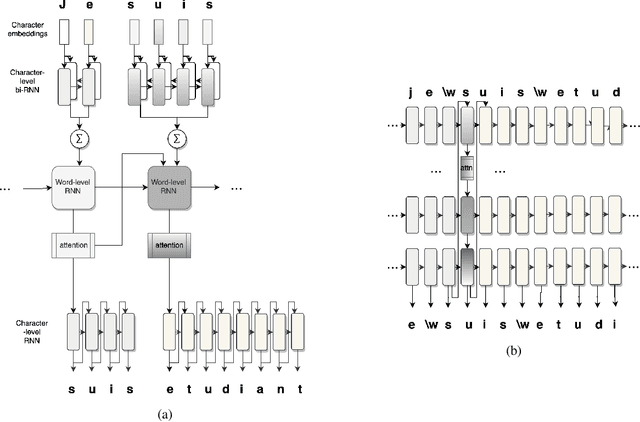
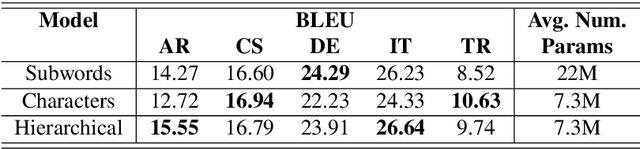
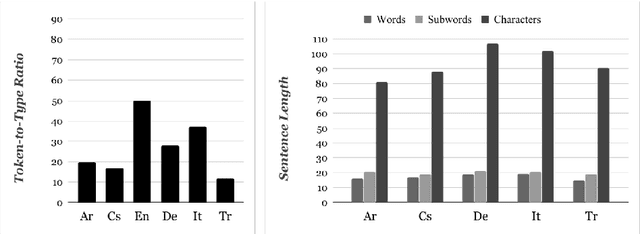
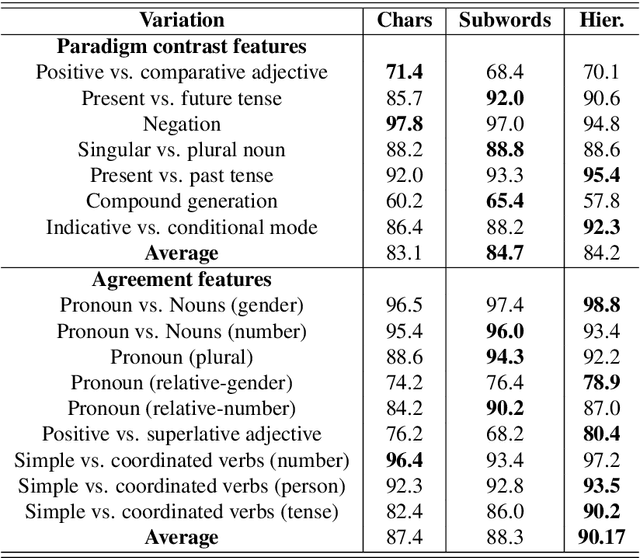
Neural Machine Translation (NMT) models generally perform translation using a fixed-size lexical vocabulary, which is an important bottleneck on their generalization capability and overall translation quality. The standard approach to overcome this limitation is to segment words into subword units, typically using some external tools with arbitrary heuristics, resulting in vocabulary units not optimized for the translation task. Recent studies have shown that the same approach can be extended to perform NMT directly at the level of characters, which can deliver translation accuracy on-par with subword-based models, on the other hand, this requires relatively deeper networks. In this paper, we propose a more computationally-efficient solution for character-level NMT which implements a hierarchical decoding architecture where translations are subsequently generated at the level of words and characters. We evaluate different methods for open-vocabulary NMT in the machine translation task from English into five languages with distinct morphological typology, and show that the hierarchical decoding model can reach higher translation accuracy than the subword-level NMT model using significantly fewer parameters, while demonstrating better capacity in learning longer-distance contextual and grammatical dependencies than the standard character-level NMT model.
Simple, Scalable Adaptation for Neural Machine Translation
Sep 18, 2019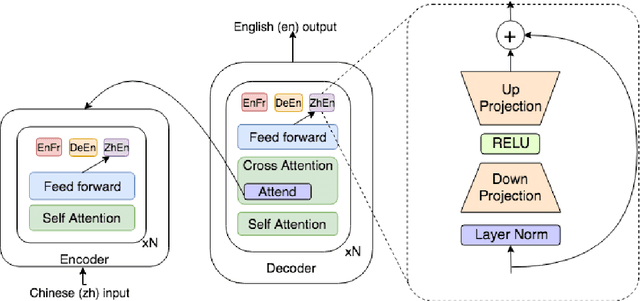
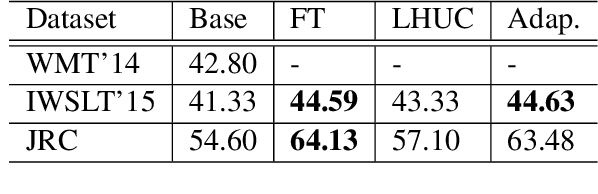
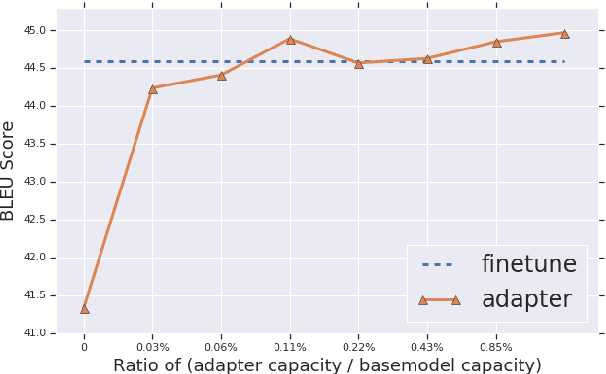
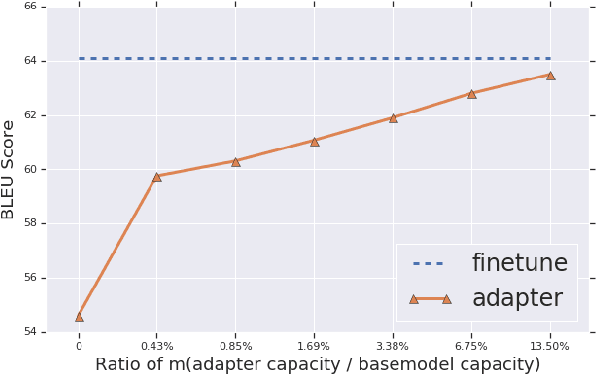
Fine-tuning pre-trained Neural Machine Translation (NMT) models is the dominant approach for adapting to new languages and domains. However, fine-tuning requires adapting and maintaining a separate model for each target task. We propose a simple yet efficient approach for adaptation in NMT. Our proposed approach consists of injecting tiny task specific adapter layers into a pre-trained model. These lightweight adapters, with just a small fraction of the original model size, adapt the model to multiple individual tasks simultaneously. We evaluate our approach on two tasks: (i) Domain Adaptation and (ii) Massively Multilingual NMT. Experiments on domain adaptation demonstrate that our proposed approach is on par with full fine-tuning on various domains, dataset sizes and model capacities. On a massively multilingual dataset of 103 languages, our adaptation approach bridges the gap between individual bilingual models and one massively multilingual model for most language pairs, paving the way towards universal machine translation.
Adaptive Scheduling for Multi-Task Learning
Sep 13, 2019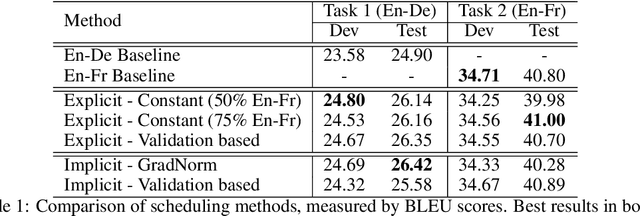
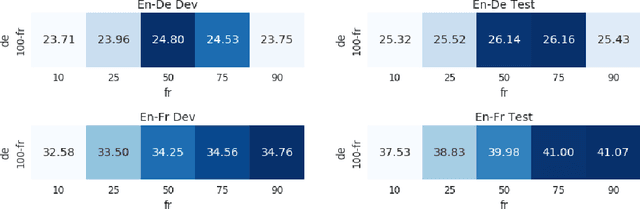
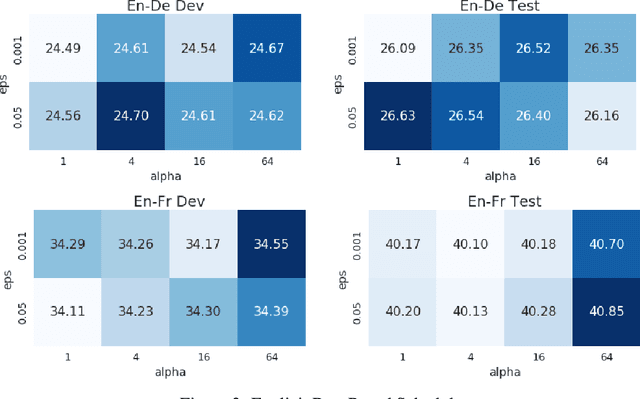
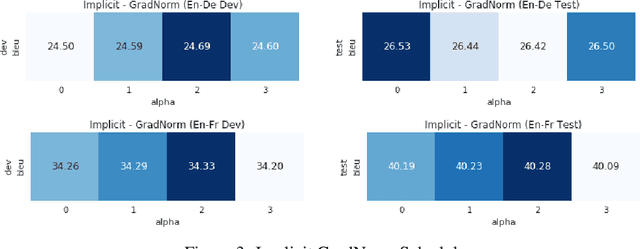
To train neural machine translation models simultaneously on multiple tasks (languages), it is common to sample each task uniformly or in proportion to dataset sizes. As these methods offer little control over performance trade-offs, we explore different task scheduling approaches. We first consider existing non-adaptive techniques, then move on to adaptive schedules that over-sample tasks with poorer results compared to their respective baseline. As explicit schedules can be inefficient, especially if one task is highly over-sampled, we also consider implicit schedules, learning to scale learning rates or gradients of individual tasks instead. These techniques allow training multilingual models that perform better for low-resource language pairs (tasks with small amount of data), while minimizing negative effects on high-resource tasks.
Investigating Multilingual NMT Representations at Scale
Sep 11, 2019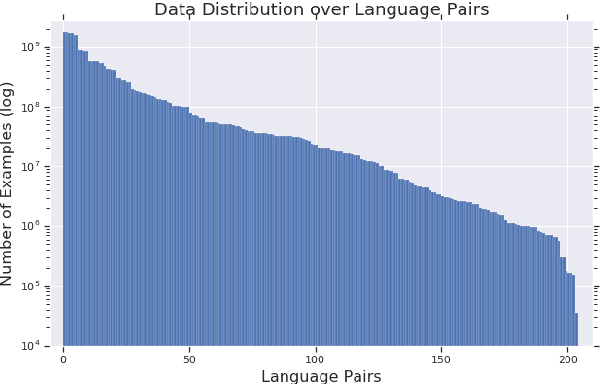
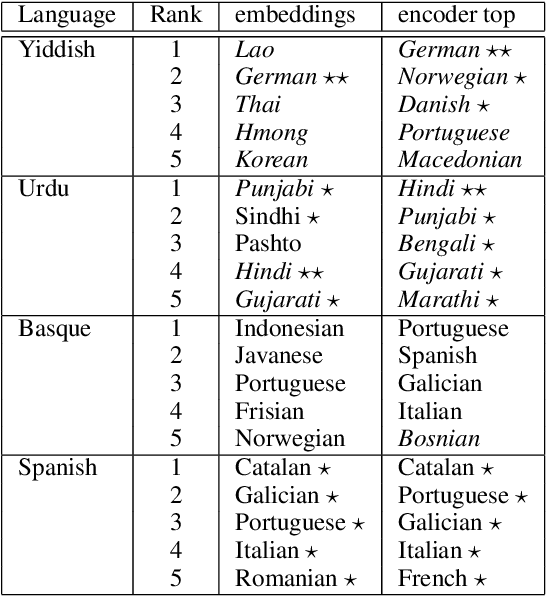
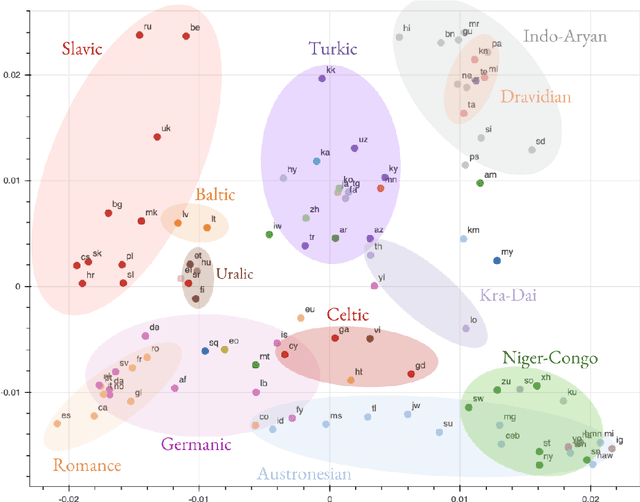

Multilingual Neural Machine Translation (NMT) models have yielded large empirical success in transfer learning settings. However, these black-box representations are poorly understood, and their mode of transfer remains elusive. In this work, we attempt to understand massively multilingual NMT representations (with 103 languages) using Singular Value Canonical Correlation Analysis (SVCCA), a representation similarity framework that allows us to compare representations across different languages, layers and models. Our analysis validates several empirical results and long-standing intuitions, and unveils new observations regarding how representations evolve in a multilingual translation model. We draw three major conclusions from our analysis, with implications on cross-lingual transfer learning: (i) Encoder representations of different languages cluster based on linguistic similarity, (ii) Representations of a source language learned by the encoder are dependent on the target language, and vice-versa, and (iii) Representations of high resource and/or linguistically similar languages are more robust when fine-tuning on an arbitrary language pair, which is critical to determining how much cross-lingual transfer can be expected in a zero or few-shot setting. We further connect our findings with existing empirical observations in multilingual NMT and transfer learning.