 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining and Tuning Generative Neural Radiance Fields for Attribute-Conditional 3D-Aware Face Generation
Aug 26, 2022

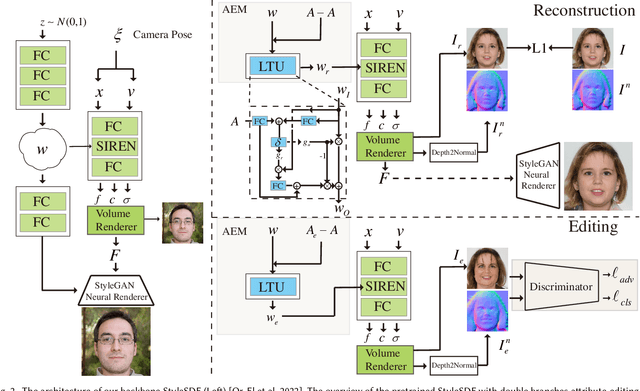
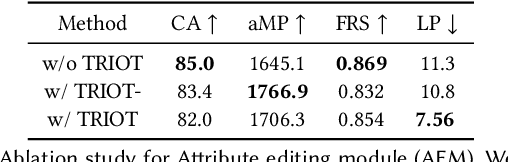
3D-aware GANs based on generative neural radiance fields (GNeRF) have achieved impressive high-quality image generation, while preserving strong 3D consistency. The most notable achievements are made in the face generation domain. However, most of these models focus on improving view consistency but neglect a disentanglement aspect, thus these models cannot provide high-quality semantic/attribute control over generation. To this end, we introduce a conditional GNeRF model that uses specific attribute labels as input in order to improve the controllabilities and disentangling abilities of 3D-aware generative models. We utilize the pre-trained 3D-aware model as the basis and integrate a dual-branches attribute-editing module (DAEM), that utilize attribute labels to provide control over generation. Moreover, we propose a TRIOT (TRaining as Init, and Optimizing for Tuning) method to optimize the latent vector to improve the precision of the attribute-editing further. Extensive experiments on the widely used FFHQ show that our model yields high-quality editing with better view consistency while preserving the non-target regions. The code is available at https://github.com/zhangqianhui/TT-GNeRF.
Uncertainty-guided Source-free Domain Adaptation
Aug 16, 2022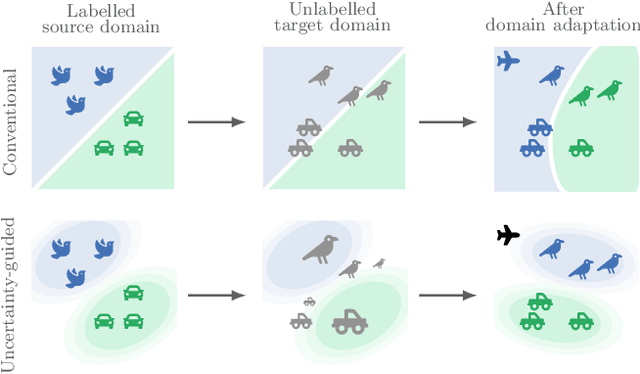

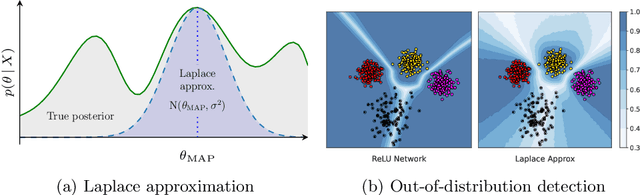
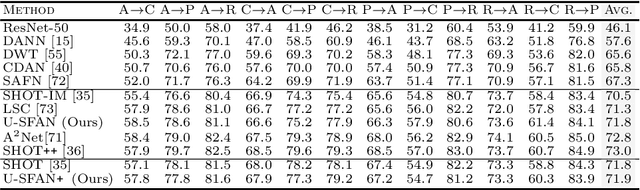
Source-free domain adaptation (SFDA) aims to adapt a classifier to an unlabelled target data set by only using a pre-trained source model. However, the absence of the source data and the domain shift makes the predictions on the target data unreliable. We propose quantifying the uncertainty in the source model predictions and utilizing it to guide the target adaptation. For this, we construct a probabilistic source model by incorporating priors on the network parameters inducing a distribution over the model predictions. Uncertainties are estimated by employing a Laplace approximation and incorporated to identify target data points that do not lie in the source manifold and to down-weight them when maximizing the mutual information on the target data. Unlike recent works, our probabilistic treatment is computationally lightweight, decouples source training and target adaptation, and requires no specialized source training or changes of the model architecture. We show the advantages of uncertainty-guided SFDA over traditional SFDA in the closed-set and open-set settings and provide empirical evidence that our approach is more robust to strong domain shifts even without tuning.
Unsupervised Domain Adaptation for Video Transformers in Action Recognition
Jul 26, 2022
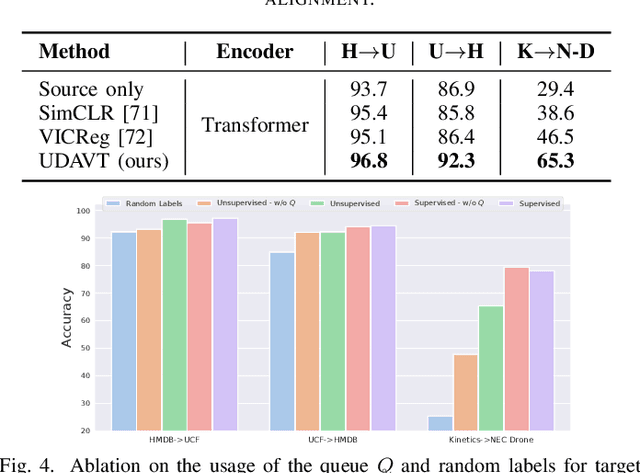
Over the last few years, Unsupervised Domain Adaptation (UDA) techniques have acquired remarkable importance and popularity in computer vision. However, when compared to the extensive literature available for images, the field of videos is still relatively unexplored. On the other hand, the performance of a model in action recognition is heavily affected by domain shift. In this paper, we propose a simple and novel UDA approach for video action recognition. Our approach leverages recent advances on spatio-temporal transformers to build a robust source model that better generalises to the target domain. Furthermore, our architecture learns domain invariant features thanks to the introduction of a novel alignment loss term derived from the Information Bottleneck principle. We report results on two video action recognition benchmarks for UDA, showing state-of-the-art performance on HMDB$\leftrightarrow$UCF, as well as on Kinetics$\rightarrow$NEC-Drone, which is more challenging. This demonstrates the effectiveness of our method in handling different levels of domain shift. The source code is available at https://github.com/vturrisi/UDAVT.
CoSMix: Compositional Semantic Mix for Domain Adaptation in 3D LiDAR Segmentation
Jul 20, 20223D LiDAR semantic segmentation is fundamental for autonomous driving. Several Unsupervised Domain Adaptation (UDA) methods for point cloud data have been recently proposed to improve model generalization for different sensors and environments. Researchers working on UDA problems in the image domain have shown that sample mixing can mitigate domain shift. We propose a new approach of sample mixing for point cloud UDA, namely Compositional Semantic Mix (CoSMix), the first UDA approach for point cloud segmentation based on sample mixing. CoSMix consists of a two-branch symmetric network that can process labelled synthetic data (source) and real-world unlabelled point clouds (target) concurrently. Each branch operates on one domain by mixing selected pieces of data from the other one, and by using the semantic information derived from source labels and target pseudo-labels. We evaluate CoSMix on two large-scale datasets, showing that it outperforms state-of-the-art methods by a large margin. Our code is available at https://github.com/saltoricristiano/cosmix-uda.
GIPSO: Geometrically Informed Propagation for Online Adaptation in 3D LiDAR Segmentation
Jul 20, 2022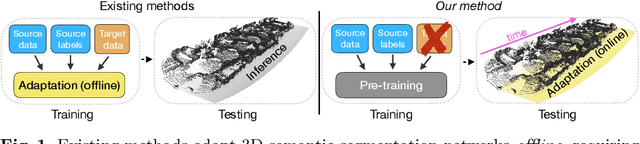
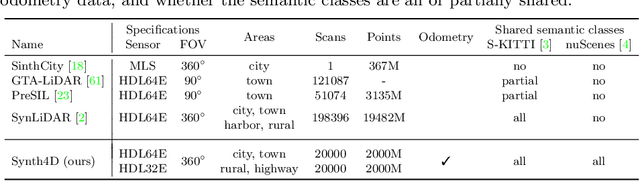
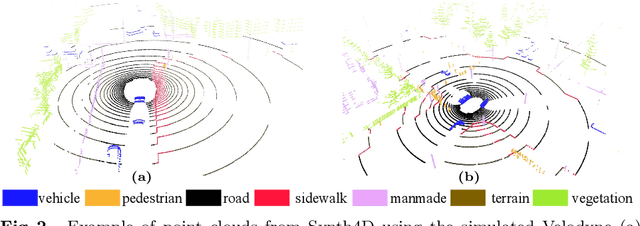
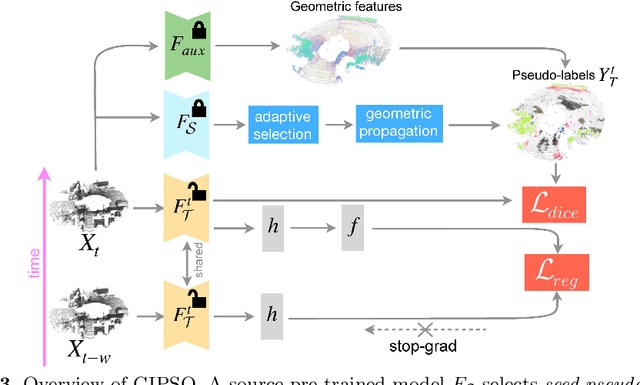
3D point cloud semantic segmentation is fundamental for autonomous driving. Most approaches in the literature neglect an important aspect, i.e., how to deal with domain shift when handling dynamic scenes. This can significantly hinder the navigation capabilities of self-driving vehicles. This paper advances the state of the art in this research field. Our first contribution consists in analysing a new unexplored scenario in point cloud segmentation, namely Source-Free Online Unsupervised Domain Adaptation (SF-OUDA). We experimentally show that state-of-the-art methods have a rather limited ability to adapt pre-trained deep network models to unseen domains in an online manner. Our second contribution is an approach that relies on adaptive self-training and geometric-feature propagation to adapt a pre-trained source model online without requiring either source data or target labels. Our third contribution is to study SF-OUDA in a challenging setup where source data is synthetic and target data is point clouds captured in the real world. We use the recent SynLiDAR dataset as a synthetic source and introduce two new synthetic (source) datasets, which can stimulate future synthetic-to-real autonomous driving research. Our experiments show the effectiveness of our segmentation approach on thousands of real-world point clouds. Code and synthetic datasets are available at https://github.com/saltoricristiano/gipso-sfouda.
Class-incremental Novel Class Discovery
Jul 18, 2022
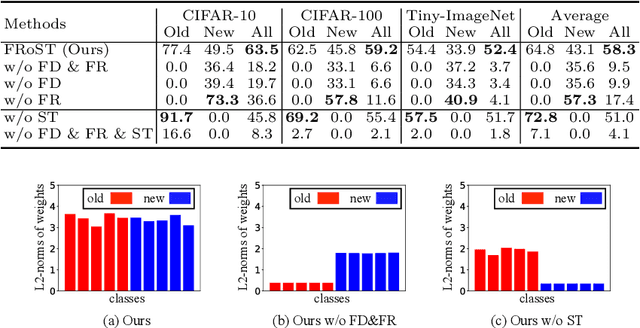
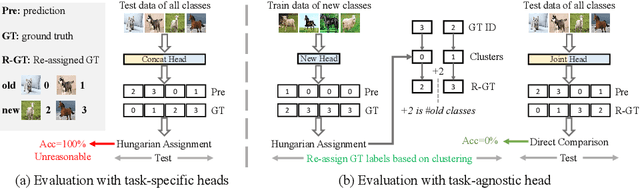

We study the new task of class-incremental Novel Class Discovery (class-iNCD), which refers to the problem of discovering novel categories in an unlabelled data set by leveraging a pre-trained model that has been trained on a labelled data set containing disjoint yet related categories. Apart from discovering novel classes, we also aim at preserving the ability of the model to recognize previously seen base categories. Inspired by rehearsal-based incremental learning methods, in this paper we propose a novel approach for class-iNCD which prevents forgetting of past information about the base classes by jointly exploiting base class feature prototypes and feature-level knowledge distillation. We also propose a self-training clustering strategy that simultaneously clusters novel categories and trains a joint classifier for both the base and novel classes. This makes our method able to operate in a class-incremental setting. Our experiments, conducted on three common benchmarks, demonstrate that our method significantly outperforms state-of-the-art approaches. Code is available at https://github.com/OatmealLiu/class-iNCD
Adversarial Style Augmentation for Domain Generalized Urban-Scene Segmentation
Jul 11, 2022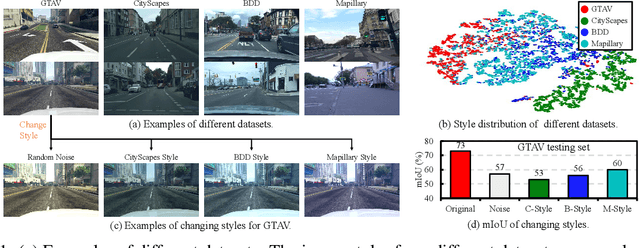
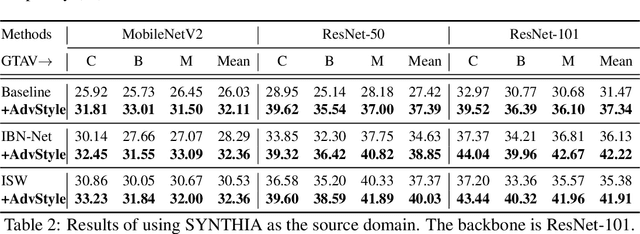

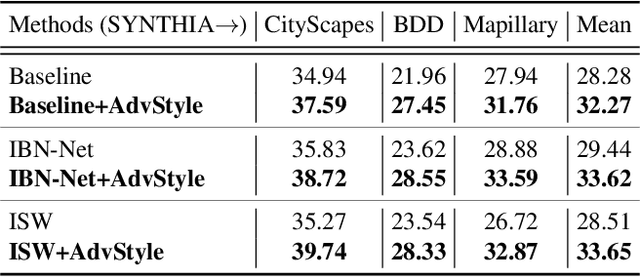
In this paper, we consider the problem of domain generalization in semantic segmentation, which aims to learn a robust model using only labeled synthetic (source) data. The model is expected to perform well on unseen real (target) domains. Our study finds that the image style variation can largely influence the model's performance and the style features can be well represented by the channel-wise mean and standard deviation of images. Inspired by this, we propose a novel adversarial style augmentation (AdvStyle) approach, which can dynamically generate hard stylized images during training and thus can effectively prevent the model from overfitting on the source domain. Specifically, AdvStyle regards the style feature as a learnable parameter and updates it by adversarial training. The learned adversarial style feature is used to construct an adversarial image for robust model training. AdvStyle is easy to implement and can be readily applied to different models. Experiments on two synthetic-to-real semantic segmentation benchmarks demonstrate that AdvStyle can significantly improve the model performance on unseen real domains and show that we can achieve the state of the art. Moreover, AdvStyle can be employed to domain generalized image classification and produces a clear improvement on the considered datasets.
PI-Trans: Parallel-ConvMLP and Implicit-Transformation Based GAN for Cross-View Image Translation
Jul 09, 2022
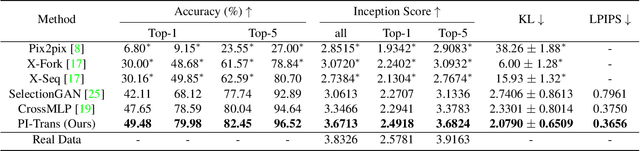
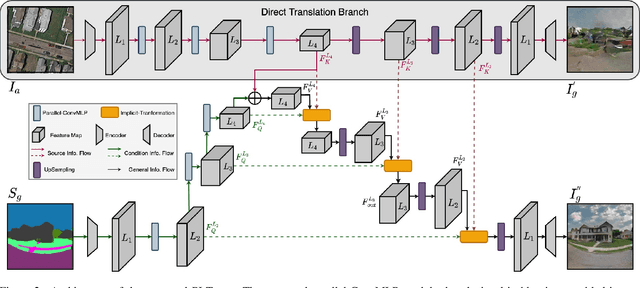
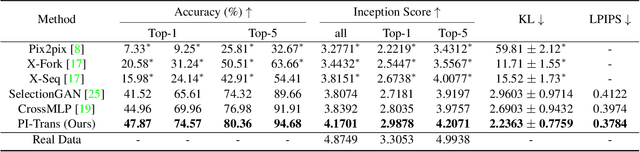
For semantic-guided cross-view image translation, it is crucial to learn where to sample pixels from the source view image and where to reallocate them guided by the target view semantic map, especially when there is little overlap or drastic view difference between the source and target images. Hence, one not only needs to encode the long-range dependencies among pixels in both the source view image and target view the semantic map but also needs to translate these learned dependencies. To this end, we propose a novel generative adversarial network, PI-Trans, which mainly consists of a novel Parallel-ConvMLP module and an Implicit Transformation module at multiple semantic levels. Extensive experimental results show that the proposed PI-Trans achieves the best qualitative and quantitative performance by a large margin compared to the state-of-the-art methods on two challenging datasets. The code will be made available at https://github.com/Amazingren/PI-Trans.
Batch-efficient EigenDecomposition for Small and Medium Matrices
Jul 09, 2022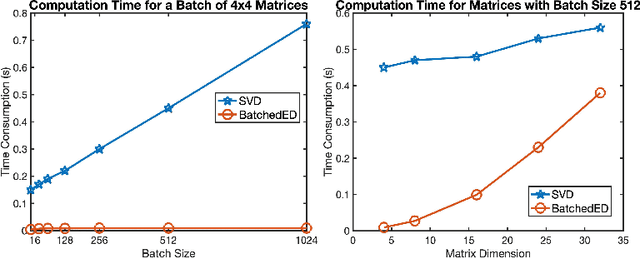

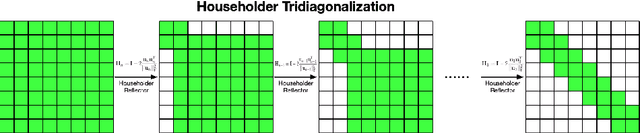
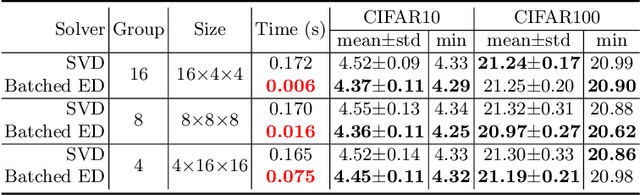
EigenDecomposition (ED) is at the heart of many computer vision algorithms and applications. One crucial bottleneck limiting its usage is the expensive computation cost, particularly for a mini-batch of matrices in the deep neural networks. In this paper, we propose a QR-based ED method dedicated to the application scenarios of computer vision. Our proposed method performs the ED entirely by batched matrix/vector multiplication, which processes all the matrices simultaneously and thus fully utilizes the power of GPUs. Our technique is based on the explicit QR iterations by Givens rotation with double Wilkinson shifts. With several acceleration techniques, the time complexity of QR iterations is reduced from $O{(}n^5{)}$ to $O{(}n^3{)}$. The numerical test shows that for small and medium batched matrices (\emph{e.g.,} $dim{<}32$) our method can be much faster than the Pytorch SVD function. Experimental results on visual recognition and image generation demonstrate that our methods also achieve competitive performances.
Improving Covariance Conditioning of the SVD Meta-layer by Orthogonality
Jul 05, 2022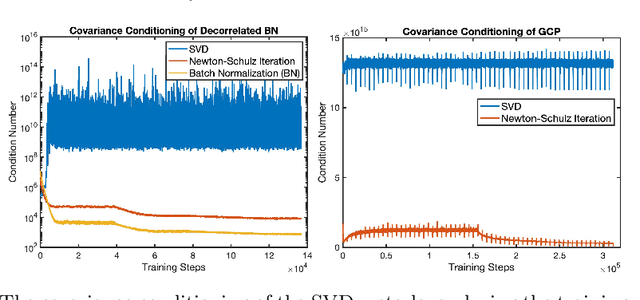
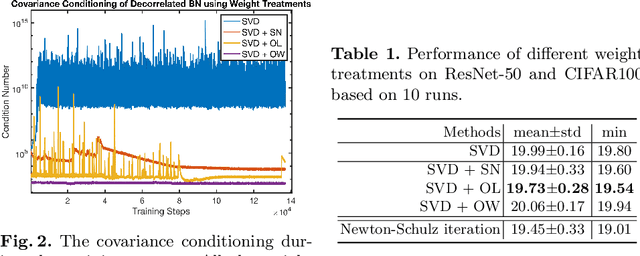
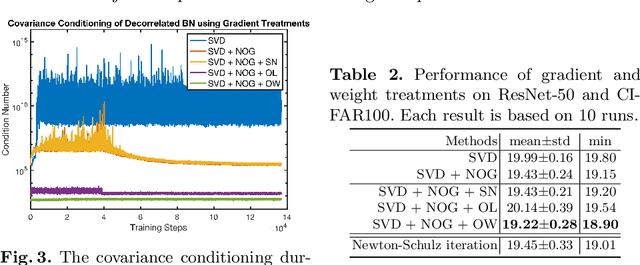
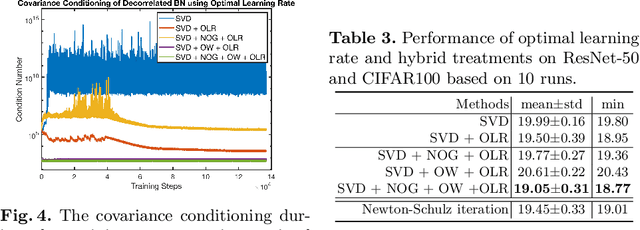
Inserting an SVD meta-layer into neural networks is prone to make the covariance ill-conditioned, which could harm the model in the training stability and generalization abilities. In this paper, we systematically study how to improve the covariance conditioning by enforcing orthogonality to the Pre-SVD layer. Existing orthogonal treatments on the weights are first investigated. However, these techniques can improve the conditioning but would hurt the performance. To avoid such a side effect, we propose the Nearest Orthogonal Gradient (NOG) and Optimal Learning Rate (OLR). The effectiveness of our methods is validated in two applications: decorrelated Batch Normalization (BN) and Global Covariance Pooling (GCP). Extensive experiments on visual recognition demonstrate that our methods can simultaneously improve the covariance conditioning and generalization. Moreover, the combinations with orthogonal weight can further boost the performances.