 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Complexity Dynamics of Grokking
Dec 13, 2024We investigate the phenomenon of generalization through the lens of compression. In particular, we study the complexity dynamics of neural networks to explain grokking, where networks suddenly transition from memorizing to generalizing solutions long after over-fitting the training data. To this end we introduce a new measure of intrinsic complexity for neural networks based on the theory of Kolmogorov complexity. Tracking this metric throughout network training, we find a consistent pattern in training dynamics, consisting of a rise and fall in complexity. We demonstrate that this corresponds to memorization followed by generalization. Based on insights from rate--distortion theory and the minimum description length principle, we lay out a principled approach to lossy compression of neural networks, and connect our complexity measure to explicit generalization bounds. Based on a careful analysis of information capacity in neural networks, we propose a new regularization method which encourages networks towards low-rank representations by penalizing their spectral entropy, and find that our regularizer outperforms baselines in total compression of the dataset.
No Regrets: Investigating and Improving Regret Approximations for Curriculum Discovery
Aug 27, 2024



What data or environments to use for training to improve downstream performance is a longstanding and very topical question in reinforcement learning. In particular, Unsupervised Environment Design (UED) methods have gained recent attention as their adaptive curricula enable agents to be robust to in- and out-of-distribution tasks. We ask to what extent these methods are themselves robust when applied to a novel setting, closely inspired by a real-world robotics problem. Surprisingly, we find that the state-of-the-art UED methods either do not improve upon the na\"{i}ve baseline of Domain Randomisation (DR), or require substantial hyperparameter tuning to do so. Our analysis shows that this is due to their underlying scoring functions failing to predict intuitive measures of ``learnability'', i.e., in finding the settings that the agent sometimes solves, but not always. Based on this, we instead directly train on levels with high learnability and find that this simple and intuitive approach outperforms UED methods and DR in several binary-outcome environments, including on our domain and the standard UED domain of Minigrid. We further introduce a new adversarial evaluation procedure for directly measuring robustness, closely mirroring the conditional value at risk (CVaR). We open-source all our code and present visualisations of final policies here: https://github.com/amacrutherford/sampling-for-learnability.
A Transparency Paradox? Investigating the Impact of Explanation Specificity and Autonomous Vehicle Perceptual Inaccuracies on Passengers
Aug 16, 2024Transparency in automated systems could be afforded through the provision of intelligible explanations. While transparency is desirable, might it lead to catastrophic outcomes (such as anxiety), that could outweigh its benefits? It's quite unclear how the specificity of explanations (level of transparency) influences recipients, especially in autonomous driving (AD). In this work, we examined the effects of transparency mediated through varying levels of explanation specificity in AD. We first extended a data-driven explainer model by adding a rule-based option for explanation generation in AD, and then conducted a within-subject lab study with 39 participants in an immersive driving simulator to study the effect of the resulting explanations. Specifically, our investigation focused on: (1) how different types of explanations (specific vs. abstract) affect passengers' perceived safety, anxiety, and willingness to take control of the vehicle when the vehicle perception system makes erroneous predictions; and (2) the relationship between passengers' behavioural cues and their feelings during the autonomous drives. Our findings showed that passengers felt safer with specific explanations when the vehicle's perception system had minimal errors, while abstract explanations that hid perception errors led to lower feelings of safety. Anxiety levels increased when specific explanations revealed perception system errors (high transparency). We found no significant link between passengers' visual patterns and their anxiety levels. Our study suggests that passengers prefer clear and specific explanations (high transparency) when they originate from autonomous vehicles (AVs) with optimal perceptual accuracy.
AutoInspect: Towards Long-Term Autonomous Industrial Inspection
Apr 19, 2024We give an overview of AutoInspect, a ROS-based software system for robust and extensible mission-level autonomy. Over the past three years AutoInspect has been deployed in a variety of environments, including at a mine, a chemical plant, a mock oil rig, decommissioned nuclear power plants, and a fusion reactor for durations ranging from hours to weeks. The system combines robust mapping and localisation with graph-based autonomous navigation, mission execution, and scheduling to achieve a complete autonomous inspection system. The time from arrival at a new site to autonomous mission execution can be under an hour. It is deployed on a Boston Dynamics Spot robot using a custom sensing and compute payload called Frontier. In this work we go into detail of the system's performance in two long-term deployments of 49 days at a robotics test facility, and 35 days at the Joint European Torus (JET) fusion reactor in Oxfordshire, UK.
Watching Grass Grow: Long-term Visual Navigation and Mission Planning for Autonomous Biodiversity Monitoring
Apr 16, 2024



We describe a challenging robotics deployment in a complex ecosystem to monitor a rich plant community. The study site is dominated by dynamic grassland vegetation and is thus visually ambiguous and liable to drastic appearance change over the course of a day and especially through the growing season. This dynamism and complexity in appearance seriously impact the stability of the robotics platform, as localisation is a foundational part of that control loop, and so routes must be carefully taught and retaught until autonomy is robust and repeatable. Our system is demonstrated over a 6-week period monitoring the response of grass species to experimental climate change manipulations. We also discuss the applicability of our pipeline to monitor biodiversity in other complex natural settings.
Monte Carlo Tree Search with Boltzmann Exploration
Apr 11, 2024Monte-Carlo Tree Search (MCTS) methods, such as Upper Confidence Bound applied to Trees (UCT), are instrumental to automated planning techniques. However, UCT can be slow to explore an optimal action when it initially appears inferior to other actions. Maximum ENtropy Tree-Search (MENTS) incorporates the maximum entropy principle into an MCTS approach, utilising Boltzmann policies to sample actions, naturally encouraging more exploration. In this paper, we highlight a major limitation of MENTS: optimal actions for the maximum entropy objective do not necessarily correspond to optimal actions for the original objective. We introduce two algorithms, Boltzmann Tree Search (BTS) and Decaying ENtropy Tree-Search (DENTS), that address these limitations and preserve the benefits of Boltzmann policies, such as allowing actions to be sampled faster by using the Alias method. Our empirical analysis shows that our algorithms show consistent high performance across several benchmark domains, including the game of Go.
* Camera ready version of NeurIPS2023 paper
Planning for Robust Open-loop Pushing: Exploiting Quasi-static Belief Dynamics and Contact-informed Optimization
Apr 03, 2024Non-prehensile manipulation such as pushing is typically subject to uncertain, non-smooth dynamics. However, modeling the uncertainty of the dynamics typically results in intractable belief dynamics, making data-efficient planning under uncertainty difficult. This article focuses on the problem of efficiently generating robust open-loop pushing plans. First, we investigate how the belief over object configurations propagates through quasi-static contact dynamics. We exploit the simplified dynamics to predict the variance of the object configuration without sampling from a perturbation distribution. In a sampling-based trajectory optimization algorithm, the gain of the variance is constrained in order to enforce robustness of the plan. Second, we propose an informed trajectory sampling mechanism for drawing robot trajectories that are likely to make contact with the object. This sampling mechanism is shown to significantly improve chances of finding robust solutions, especially when making-and-breaking contacts is required. We demonstrate that the proposed approach is able to synthesize bi-manual pushing trajectories, resulting in successful long-horizon pushing maneuvers without exteroceptive feedback such as vision or tactile feedback.
CC-VPSTO: Chance-Constrained Via-Point-based Stochastic Trajectory Optimisation for Safe and Efficient Online Robot Motion Planning
Feb 06, 2024Safety in the face of uncertainty is a key challenge in robotics. We introduce a real-time capable framework to generate safe and task-efficient robot motions for stochastic control problems. We frame this as a chance-constrained optimisation problem constraining the probability of the controlled system to violate a safety constraint to be below a set threshold. To estimate this probability we propose a Monte--Carlo approximation. We suggest several ways to construct the problem given a fixed number of uncertainty samples, such that it is a reliable over-approximation of the original problem, i.e. any solution to the sample-based problem adheres to the original chance-constraint with high confidence. To solve the resulting problem, we integrate it into our motion planner VP-STO and name the enhanced framework Chance-Constrained (CC)-VPSTO. The strengths of our approach lie in i) its generality, without assumptions on the underlying uncertainty distribution, system dynamics, cost function, or the form of inequality constraints; and ii) its applicability to MPC-settings. We demonstrate the validity and efficiency of our approach on both simulation and real-world robot experiments.
JaxMARL: Multi-Agent RL Environments in JAX
Nov 20, 2023



Benchmarks play an important role in the development of machine learning algorithms. For example, research in reinforcement learning (RL) has been heavily influenced by available environments and benchmarks. However, RL environments are traditionally run on the CPU, limiting their scalability with typical academic compute. Recent advancements in JAX have enabled the wider use of hardware acceleration to overcome these computational hurdles, enabling massively parallel RL training pipelines and environments. This is particularly useful for multi-agent reinforcement learning (MARL) research. First of all, multiple agents must be considered at each environment step, adding computational burden, and secondly, the sample complexity is increased due to non-stationarity, decentralised partial observability, or other MARL challenges. In this paper, we present JaxMARL, the first open-source code base that combines ease-of-use with GPU enabled efficiency, and supports a large number of commonly used MARL environments as well as popular baseline algorithms. When considering wall clock time, our experiments show that per-run our JAX-based training pipeline is up to 12500x faster than existing approaches. This enables efficient and thorough evaluations, with the potential to alleviate the evaluation crisis of the field. We also introduce and benchmark SMAX, a vectorised, simplified version of the popular StarCraft Multi-Agent Challenge, which removes the need to run the StarCraft II game engine. This not only enables GPU acceleration, but also provides a more flexible MARL environment, unlocking the potential for self-play, meta-learning, and other future applications in MARL. We provide code at https://github.com/flairox/jaxmarl.
Effects of Explanation Specificity on Passengers in Autonomous Driving
Jul 02, 2023
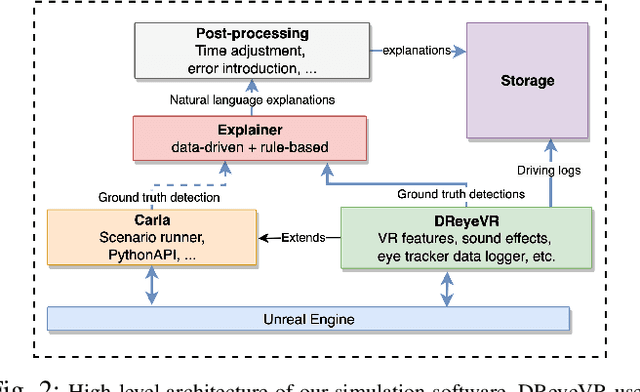
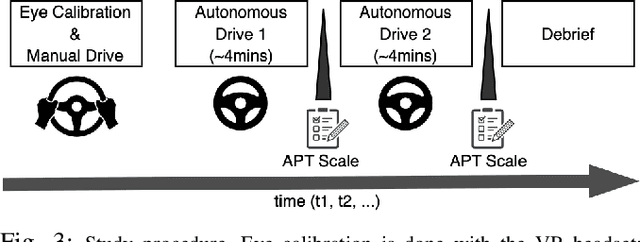
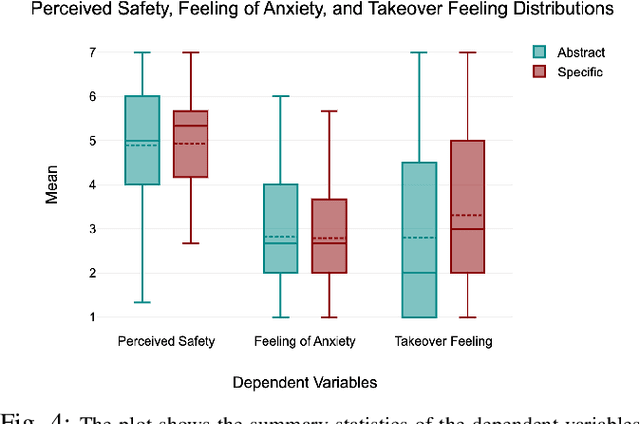
The nature of explanations provided by an explainable AI algorithm has been a topic of interest in the explainable AI and human-computer interaction community. In this paper, we investigate the effects of natural language explanations' specificity on passengers in autonomous driving. We extended an existing data-driven tree-based explainer algorithm by adding a rule-based option for explanation generation. We generated auditory natural language explanations with different levels of specificity (abstract and specific) and tested these explanations in a within-subject user study (N=39) using an immersive physical driving simulation setup. Our results showed that both abstract and specific explanations had similar positive effects on passengers' perceived safety and the feeling of anxiety. However, the specific explanations influenced the desire of passengers to takeover driving control from the autonomous vehicle (AV), while the abstract explanations did not. We conclude that natural language auditory explanations are useful for passengers in autonomous driving, and their specificity levels could influence how much in-vehicle participants would wish to be in control of the driving activity.