 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoInspect: Towards Long-Term Autonomous Industrial Inspection
Apr 19, 2024We give an overview of AutoInspect, a ROS-based software system for robust and extensible mission-level autonomy. Over the past three years AutoInspect has been deployed in a variety of environments, including at a mine, a chemical plant, a mock oil rig, decommissioned nuclear power plants, and a fusion reactor for durations ranging from hours to weeks. The system combines robust mapping and localisation with graph-based autonomous navigation, mission execution, and scheduling to achieve a complete autonomous inspection system. The time from arrival at a new site to autonomous mission execution can be under an hour. It is deployed on a Boston Dynamics Spot robot using a custom sensing and compute payload called Frontier. In this work we go into detail of the system's performance in two long-term deployments of 49 days at a robotics test facility, and 35 days at the Joint European Torus (JET) fusion reactor in Oxfordshire, UK.
Sim-to-Real Deep Reinforcement Learning with Manipulators for Pick-and-place
Sep 17, 2023When transferring a Deep Reinforcement Learning model from simulation to the real world, the performance could be unsatisfactory since the simulation cannot imitate the real world well in many circumstances. This results in a long period of fine-tuning in the real world. This paper proposes a self-supervised vision-based DRL method that allows robots to pick and place objects effectively and efficiently when directly transferring a training model from simulation to the real world. A height-sensitive action policy is specially designed for the proposed method to deal with crowded and stacked objects in challenging environments. The training model with the proposed approach can be applied directly to a real suction task without any fine-tuning from the real world while maintaining a high suction success rate. It is also validated that our model can be deployed to suction novel objects in a real experiment with a suction success rate of 90\% without any real-world fine-tuning. The experimental video is available at: https://youtu.be/jSTC-EGsoFA.
Sim-and-Real Reinforcement Learning for Manipulation: A Consensus-based Approach
Feb 26, 2023Sim-and-real training is a promising alternative to sim-to-real training for robot manipulations. However, the current sim-and-real training is neither efficient, i.e., slow convergence to the optimal policy, nor effective, i.e., sizeable real-world robot data. Given limited time and hardware budgets, the performance of sim-and-real training is not satisfactory. In this paper, we propose a Consensus-based Sim-And-Real deep reinforcement learning algorithm (CSAR) for manipulator pick-and-place tasks, which shows comparable performance in both sim-and-real worlds. In this algorithm, we train the agents in simulators and the real world to get the optimal policies for both sim-and-real worlds. We found two interesting phenomenons: (1) Best policy in simulation is not the best for sim-and-real training. (2) The more simulation agents, the better sim-and-real training. The experimental video is available at: https://youtu.be/mcHJtNIsTEQ.
Design, Integration and Sea Trials of 3D Printed Unmanned Aerial Vehicle and Unmanned Surface Vehicle for Cooperative Missions
Feb 23, 2021
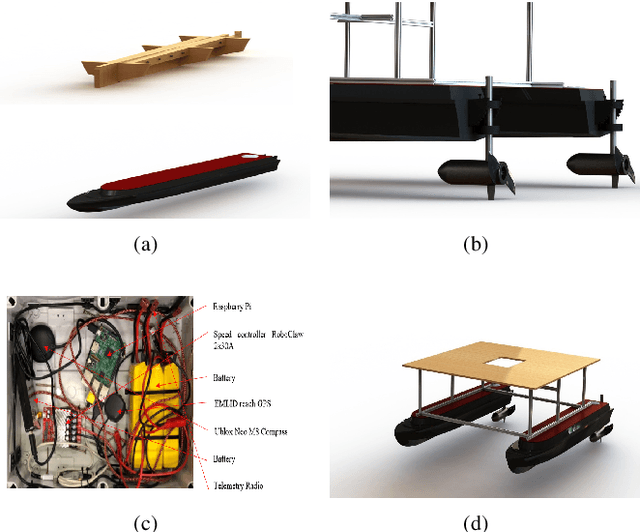
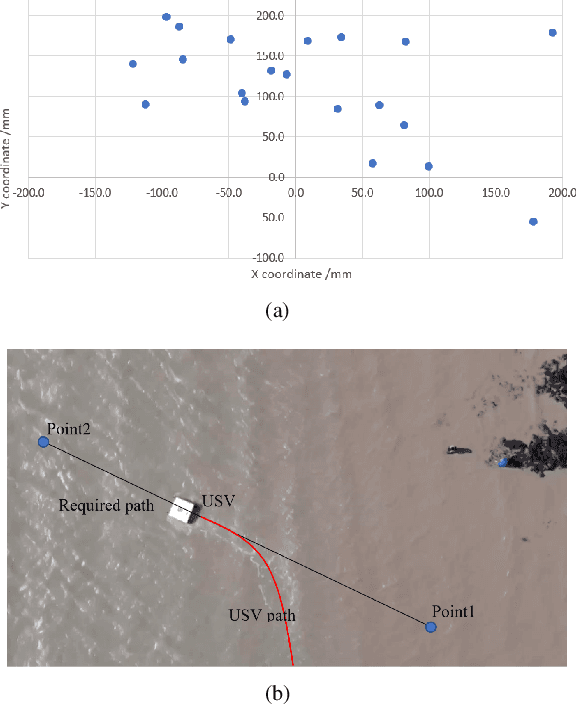
In recent years, Unmanned Surface Vehicles (USV) have been extensively deployed for maritime applications. However, USV has a limited detection range with sensor installed at the same elevation with the targets. In this research, we propose a cooperative Unmanned Aerial Vehicle - Unmanned Surface Vehicle (UAV-USV) platform to improve the detection range of USV. A floatable and waterproof UAV is designed and 3D printed, which allows it to land on the sea. A catamaran USV and landing platform are also developed. To land UAV on the USV precisely in various lighting conditions, IR beacon detector and IR beacon are implemented on the UAV and USV, respectively. Finally, a two-phase UAV precise landing method, USV control algorithm and USV path following algorithm are proposed and tested.
3D Vision-guided Pick-and-Place Using Kuka LBR iiwa Robot
Feb 23, 2021

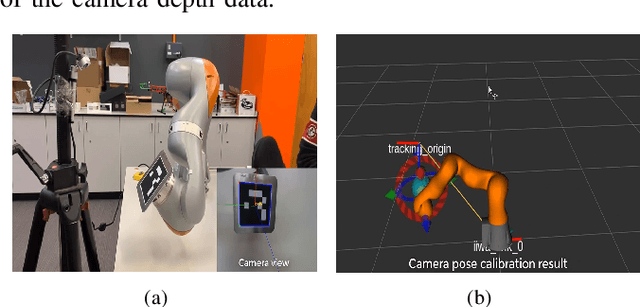
This paper presents the development of a control system for vision-guided pick-and-place tasks using a robot arm equipped with a 3D camera. The main steps include camera intrinsic and extrinsic calibration, hand-eye calibration, initial object pose registration, objects pose alignment algorithm, and pick-and-place execution. The proposed system allows the robot be able to to pick and place object with limited times of registering a new object and the developed software can be applied for new object scenario quickly. The integrated system was tested using the hardware combination of kuka iiwa, Robotiq grippers (two finger gripper and three finger gripper) and 3D cameras (Intel realsense D415 camera, Intel realsense D435 camera, Microsoft Kinect V2). The whole system can also be modified for the combination of other robotic arm, gripper and 3D camera.
Accelerated Sim-to-Real Deep Reinforcement Learning: Learning Collision Avoidance from Human Player
Feb 23, 2021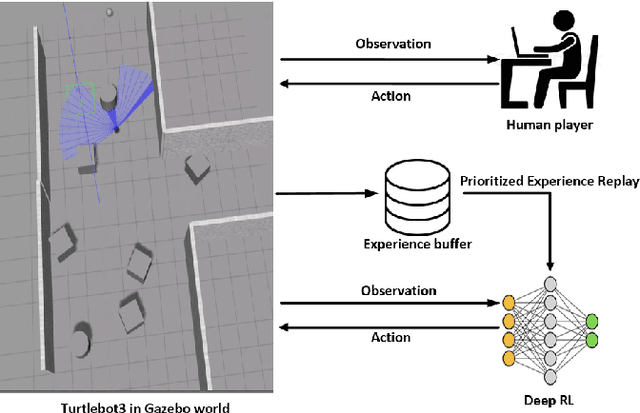
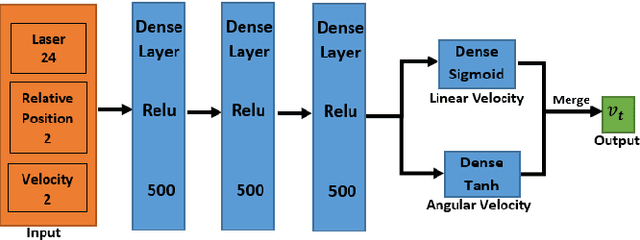
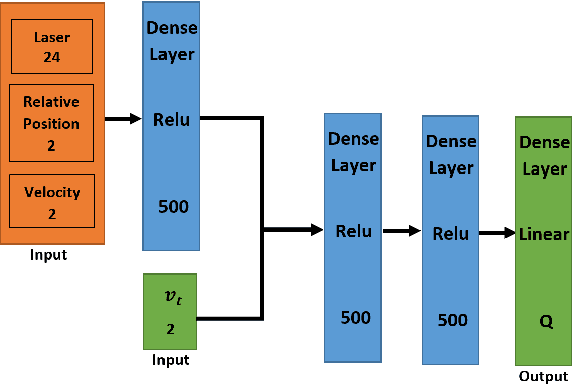
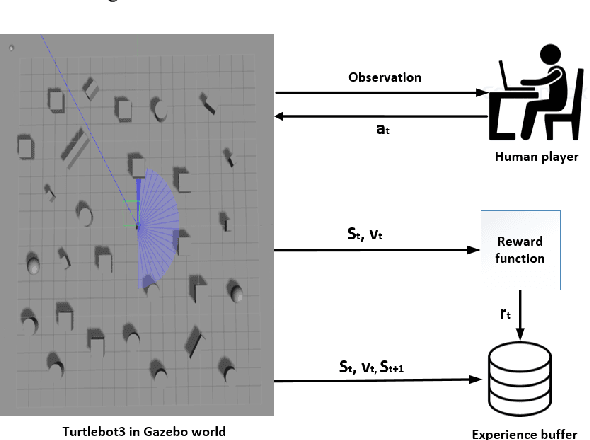
This paper presents a sensor-level mapless collision avoidance algorithm for use in mobile robots that map raw sensor data to linear and angular velocities and navigate in an unknown environment without a map. An efficient training strategy is proposed to allow a robot to learn from both human experience data and self-exploratory data. A game format simulation framework is designed to allow the human player to tele-operate the mobile robot to a goal and human action is also scored using the reward function. Both human player data and self-playing data are sampled using prioritized experience replay algorithm. The proposed algorithm and training strategy have been evaluated in two different experimental configurations: \textit{Environment 1}, a simulated cluttered environment, and \textit{Environment 2}, a simulated corridor environment, to investigate the performance. It was demonstrated that the proposed method achieved the same level of reward using only 16\% of the training steps required by the standard Deep Deterministic Policy Gradient (DDPG) method in Environment 1 and 20\% of that in Environment 2. In the evaluation of 20 random missions, the proposed method achieved no collision in less than 2~h and 2.5~h of training time in the two Gazebo environments respectively. The method also generated smoother trajectories than DDPG. The proposed method has also been implemented on a real robot in the real-world environment for performance evaluation. We can confirm that the trained model with the simulation software can be directly applied into the real-world scenario without further fine-tuning, further demonstrating its higher robustness than DDPG. The video and code are available: https://youtu.be/BmwxevgsdGc https://github.com/hanlinniu/turtlebot3_ddpg_collision_avoidance