 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointCaM: Cut-and-Mix for Open-Set Point Cloud Analysis
Dec 05, 2022Point cloud analysis is receiving increasing attention, however, most existing point cloud models lack the practical ability to deal with the unavoidable presence of unknown objects. This paper mainly discusses point cloud analysis under open-set settings, where we train the model without data from unknown classes and identify them in the inference stage. Basically, we propose to solve open-set point cloud analysis using a novel Point Cut-and-Mix mechanism consisting of Unknown-Point Simulator and Unknown-Point Estimator modules. Specifically, we use the Unknown-Point Simulator to simulate unknown data in the training stage by manipulating the geometric context of partial known data. Based on this, the Unknown-Point Estimator module learns to exploit the point cloud's feature context for discriminating the known and unknown data. Extensive experiments show the plausibility of open-set point cloud analysis and the effectiveness of our proposed solutions. Our code is available at \url{https://github.com/ShiQiu0419/pointcam}.
Energy-Based Residual Latent Transport for Unsupervised Point Cloud Completion
Nov 13, 2022Unsupervised point cloud completion aims to infer the whole geometry of a partial object observation without requiring partial-complete correspondence. Differing from existing deterministic approaches, we advocate generative modeling based unsupervised point cloud completion to explore the missing correspondence. Specifically, we propose a novel framework that performs completion by transforming a partial shape encoding into a complete one using a latent transport module, and it is designed as a latent-space energy-based model (EBM) in an encoder-decoder architecture, aiming to learn a probability distribution conditioned on the partial shape encoding. To train the latent code transport module and the encoder-decoder network jointly, we introduce a residual sampling strategy, where the residual captures the domain gap between partial and complete shape latent spaces. As a generative model-based framework, our method can produce uncertainty maps consistent with human perception, leading to explainable unsupervised point cloud completion. We experimentally show that the proposed method produces high-fidelity completion results, outperforming state-of-the-art models by a significant margin.
The Devil in Linear Transformer
Oct 19, 2022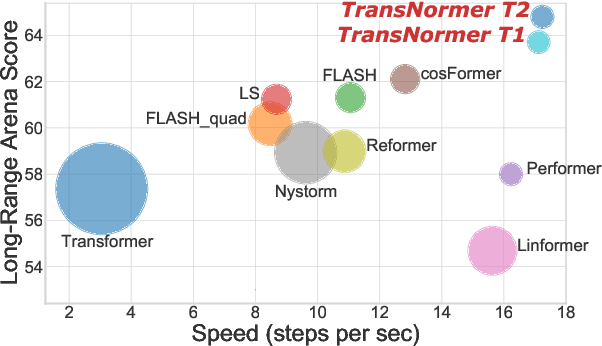



Linear transformers aim to reduce the quadratic space-time complexity of vanilla transformers. However, they usually suffer from degraded performances on various tasks and corpus. In this paper, we examine existing kernel-based linear transformers and identify two key issues that lead to such performance gaps: 1) unbounded gradients in the attention computation adversely impact the convergence of linear transformer models; 2) attention dilution which trivially distributes attention scores over long sequences while neglecting neighbouring structures. To address these issues, we first identify that the scaling of attention matrices is the devil in unbounded gradients, which turns out unnecessary in linear attention as we show theoretically and empirically. To this end, we propose a new linear attention that replaces the scaling operation with a normalization to stabilize gradients. For the issue of attention dilution, we leverage a diagonal attention to confine attention to only neighbouring tokens in early layers. Benefiting from the stable gradients and improved attention, our new linear transformer model, transNormer, demonstrates superior performance on text classification and language modeling tasks, as well as on the challenging Long-Range Arena benchmark, surpassing vanilla transformer and existing linear variants by a clear margin while being significantly more space-time efficient. The code is available at https://github.com/OpenNLPLab/Transnormer .
Efficient Gaussian Process Model on Class-Imbalanced Datasets for Generalized Zero-Shot Learning
Oct 11, 2022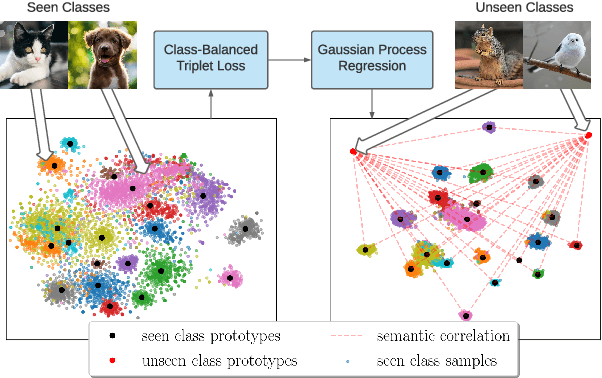
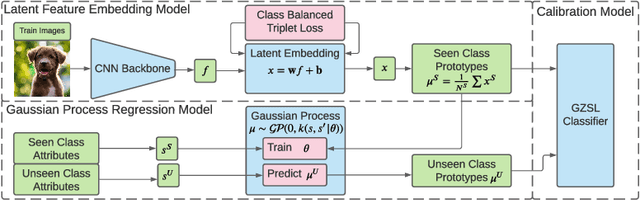
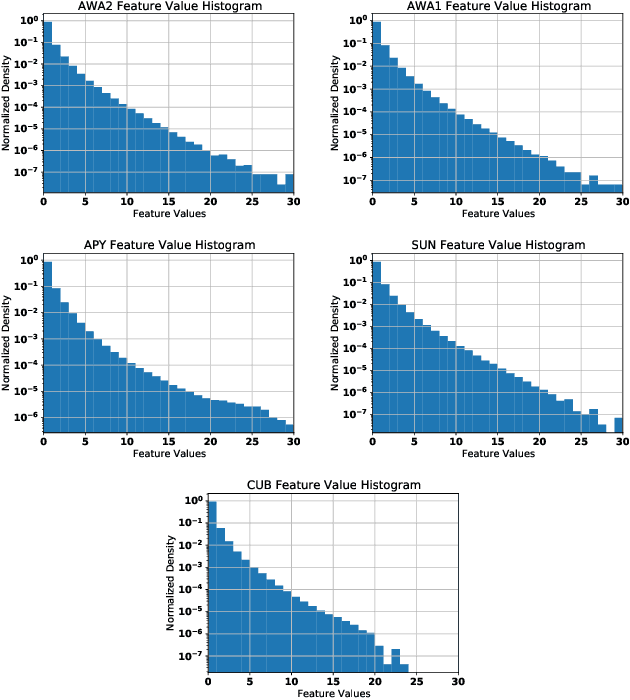
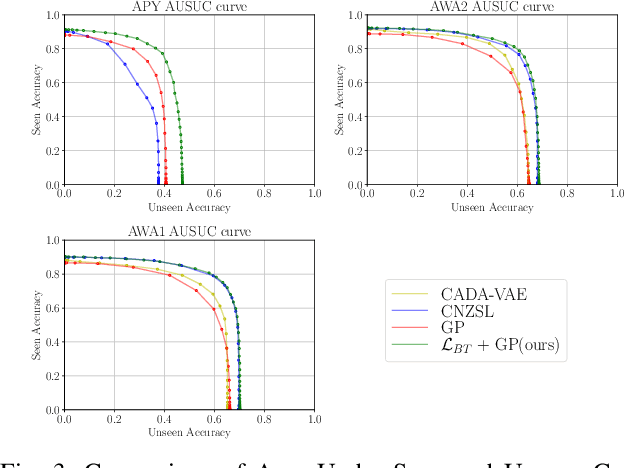
Zero-Shot Learning (ZSL) models aim to classify object classes that are not seen during the training process. However, the problem of class imbalance is rarely discussed, despite its presence in several ZSL datasets. In this paper, we propose a Neural Network model that learns a latent feature embedding and a Gaussian Process (GP) regression model that predicts latent feature prototypes of unseen classes. A calibrated classifier is then constructed for ZSL and Generalized ZSL tasks. Our Neural Network model is trained efficiently with a simple training strategy that mitigates the impact of class-imbalanced training data. The model has an average training time of 5 minutes and can achieve state-of-the-art (SOTA) performance on imbalanced ZSL benchmark datasets like AWA2, AWA1 and APY, while having relatively good performance on the SUN and CUB datasets.
Generalised Co-Salient Object Detection
Aug 20, 2022
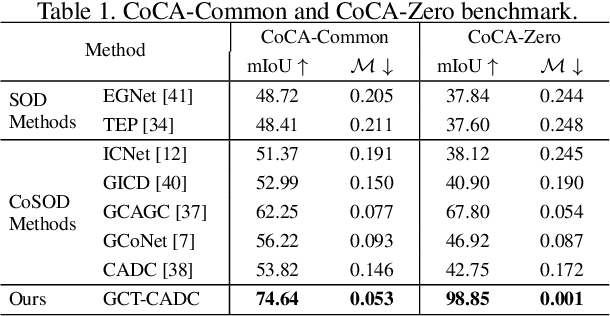

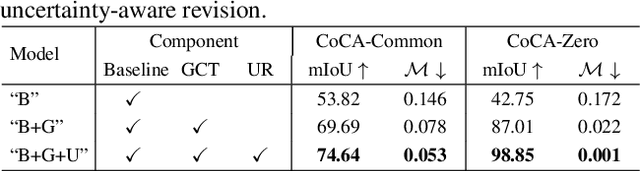
Conventional co-salient object detection (CoSOD) has a strong assumption that \enquote{a common salient object exists in every image of the same group}. However, the biased assumption contradicts real scenarios where co-salient objects could be partially or completely absent in a group of images. We propose a random sampling based Generalised CoSOD Training (GCT) strategy to distill the awareness of inter-image absence of co-salient object(s) into CoSOD models. In addition, the random sampling process inherent in GCT enables the generation of a high-quality uncertainty map, with which we can further remediate less confident model predictions that are prone to localising non-common salient objects. To evaluate the generalisation ability of CoSOD models, we propose two new testing datasets, namely CoCA-Common and CoCA-Zero, where a common salient object is partially present in the former and completely absent in the latter. Extensive experiments demonstrate that our proposed method significantly improves the generalisation ability of CoSOD models on the two new datasets, while not negatively impacting its performance under the conventional CoSOD setting. Codes are available at https://github.com/Carlisle-Liu/GCoSOD.
Vicinity Vision Transformer
Jun 21, 2022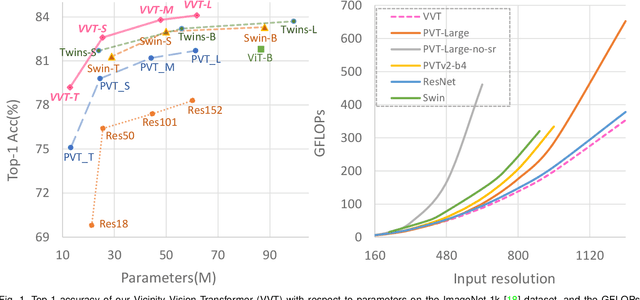
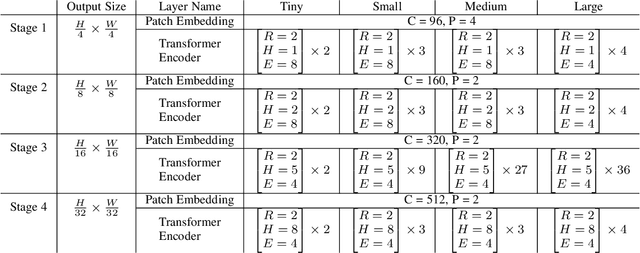
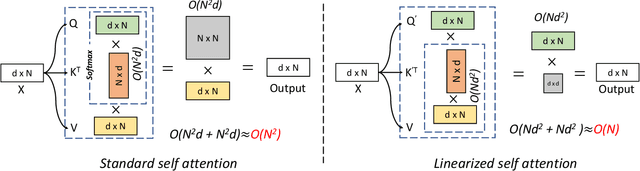
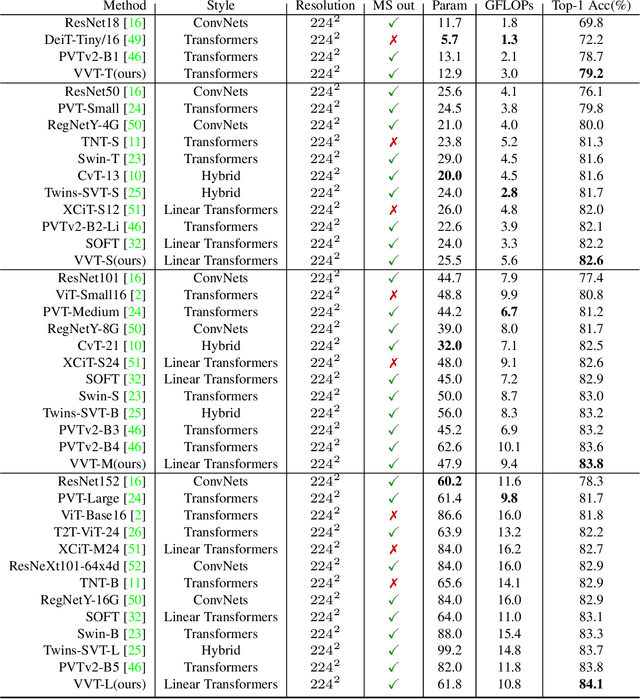
Vision transformers have shown great success on numerous computer vision tasks. However, its central component, softmax attention, prohibits vision transformers from scaling up to high-resolution images, due to both the computational complexity and memory footprint being quadratic. Although linear attention was introduced in natural language processing (NLP) tasks to mitigate a similar issue, directly applying existing linear attention to vision transformers may not lead to satisfactory results. We investigate this problem and find that computer vision tasks focus more on local information compared with NLP tasks. Based on this observation, we present a Vicinity Attention that introduces a locality bias to vision transformers with linear complexity. Specifically, for each image patch, we adjust its attention weight based on its 2D Manhattan distance measured by its neighbouring patches. In this case, the neighbouring patches will receive stronger attention than far-away patches. Moreover, since our Vicinity Attention requires the token length to be much larger than the feature dimension to show its efficiency advantages, we further propose a new Vicinity Vision Transformer (VVT) structure to reduce the feature dimension without degenerating the accuracy. We perform extensive experiments on the CIFAR100, ImageNet1K, and ADE20K datasets to validate the effectiveness of our method. Our method has a slower growth rate of GFlops than previous transformer-based and convolution-based networks when the input resolution increases. In particular, our approach achieves state-of-the-art image classification accuracy with 50% fewer parameters than previous methods.
Towards Deeper Understanding of Camouflaged Object Detection
May 23, 2022
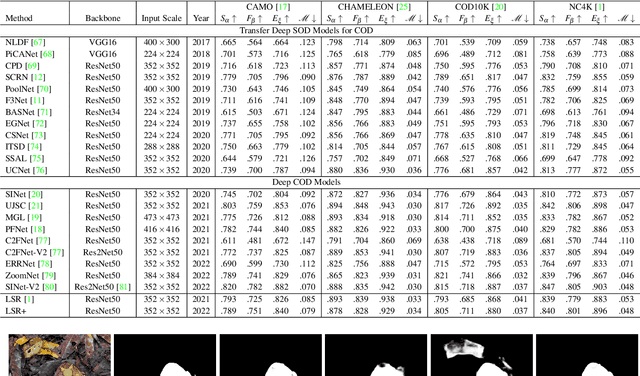
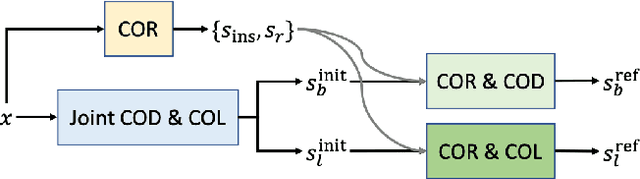
Preys in the wild evolve to be camouflaged to avoid being recognized by predators. In this way, camouflage acts as a key defence mechanism across species that is critical to survival. To detect and segment the whole scope of a camouflaged object, camouflaged object detection (COD) is introduced as a binary segmentation task, with the binary ground truth camouflage map indicating the exact regions of the camouflaged objects. In this paper, we revisit this task and argue that the binary segmentation setting fails to fully understand the concept of camouflage. We find that explicitly modeling the conspicuousness of camouflaged objects against their particular backgrounds can not only lead to a better understanding about camouflage, but also provide guidance to designing more sophisticated camouflage techniques. Furthermore, we observe that it is some specific parts of camouflaged objects that make them detectable by predators. With the above understanding about camouflaged objects, we present the first triple-task learning framework to simultaneously localize, segment and rank camouflaged objects, indicating the conspicuousness level of camouflage. As no corresponding datasets exist for either the localization model or the ranking model, we generate localization maps with an eye tracker, which are then processed according to the instance level labels to generate our ranking-based training and testing dataset. We also contribute the largest COD testing set to comprehensively analyse performance of the camouflaged object detection models. Experimental results show that our triple-task learning framework achieves new state-of-the-art, leading to a more explainable camouflaged object detection network. Our code, data and results are available at: https://github.com/JingZhang617/COD-Rank-Localize-and-Segment.
An Energy-Based Prior for Generative Saliency
Apr 19, 2022
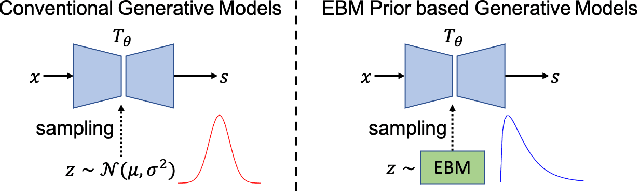
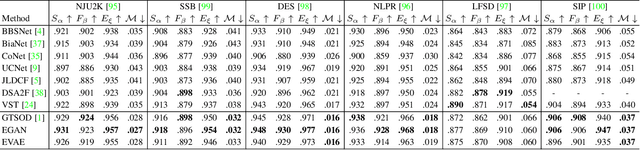

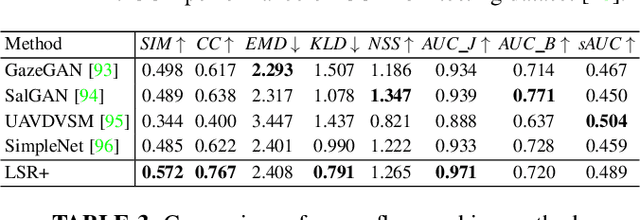
We propose a novel energy-based prior for generative saliency prediction, where the latent variables follow an informative energy-based prior. Both the saliency generator and the energy-based prior are jointly trained via Markov chain Monte Carlo-based maximum likelihood estimation, in which the sampling from the intractable posterior and prior distributions of the latent variables are performed by Langevin dynamics. With the generative saliency model, we can obtain a pixel-wise uncertainty map from an image, indicating model confidence in the saliency prediction. Different from existing generative models, which define the prior distribution of the latent variable as a simple isotropic Gaussian distribution, our model uses an energy-based informative prior which can be more expressive in capturing the latent space of the data. With the informative energy-based prior, we extend the Gaussian distribution assumption of generative models to achieve a more representative distribution of the latent space, leading to more reliable uncertainty estimation. We apply the proposed frameworks to both RGB and RGB-D salient object detection tasks with both transformer and convolutional neural network backbones. Experimental results show that our generative saliency model with an energy-based prior can achieve not only accurate saliency predictions but also reliable uncertainty maps that are consistent with human perception.
Towards Open-Set Object Detection and Discovery
Apr 12, 2022



With the human pursuit of knowledge, open-set object detection (OSOD) has been designed to identify unknown objects in a dynamic world. However, an issue with the current setting is that all the predicted unknown objects share the same category as "unknown", which require incremental learning via a human-in-the-loop approach to label novel classes. In order to address this problem, we present a new task, namely Open-Set Object Detection and Discovery (OSODD). This new task aims to extend the ability of open-set object detectors to further discover the categories of unknown objects based on their visual appearance without human effort. We propose a two-stage method that first uses an open-set object detector to predict both known and unknown objects. Then, we study the representation of predicted objects in an unsupervised manner and discover new categories from the set of unknown objects. With this method, a detector is able to detect objects belonging to known classes and define novel categories for objects of unknown classes with minimal supervision. We show the performance of our model on the MS-COCO dataset under a thorough evaluation protocol. We hope that our work will promote further research towards a more robust real-world detection system.
Semi-supervised Salient Object Detection with Effective Confidence Estimation
Dec 28, 2021
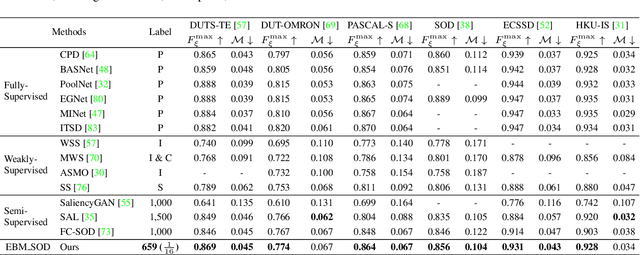
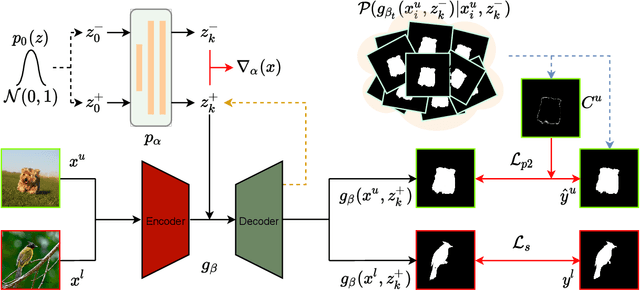

The success of existing salient object detection models relies on a large pixel-wise labeled training dataset. How-ever, collecting such a dataset is not only time-consuming but also very expensive. To reduce the labeling burden, we study semi-supervised salient object detection, and formulate it as an unlabeled dataset pixel-level confidence estimation problem by identifying pixels with less confident predictions. Specifically, we introduce a new latent variable model with an energy-based prior for effective latent space exploration, leading to more reliable confidence maps. With the proposed strategy, the unlabelled images can effectively participate in model training. Experimental results show that the proposed solution, using only 1/16 of the annotations from the original training dataset, achieves competitive performance compared with state-of-the-art fully supervised models.