 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArchitectural Implications of Neural Network Inference for High Data-Rate, Low-Latency Scientific Applications
Mar 13, 2024


With more scientific fields relying on neural networks (NNs) to process data incoming at extreme throughputs and latencies, it is crucial to develop NNs with all their parameters stored on-chip. In many of these applications, there is not enough time to go off-chip and retrieve weights. Even more so, off-chip memory such as DRAM does not have the bandwidth required to process these NNs as fast as the data is being produced (e.g., every 25 ns). As such, these extreme latency and bandwidth requirements have architectural implications for the hardware intended to run these NNs: 1) all NN parameters must fit on-chip, and 2) codesigning custom/reconfigurable logic is often required to meet these latency and bandwidth constraints. In our work, we show that many scientific NN applications must run fully on chip, in the extreme case requiring a custom chip to meet such stringent constraints.
Robust Anomaly Detection for Particle Physics Using Multi-Background Representation Learning
Jan 16, 2024Anomaly, or out-of-distribution, detection is a promising tool for aiding discoveries of new particles or processes in particle physics. In this work, we identify and address two overlooked opportunities to improve anomaly detection for high-energy physics. First, rather than train a generative model on the single most dominant background process, we build detection algorithms using representation learning from multiple background types, thus taking advantage of more information to improve estimation of what is relevant for detection. Second, we generalize decorrelation to the multi-background setting, thus directly enforcing a more complete definition of robustness for anomaly detection. We demonstrate the benefit of the proposed robust multi-background anomaly detection algorithms on a high-dimensional dataset of particle decays at the Large Hadron Collider.
Beyond PID Controllers: PPO with Neuralized PID Policy for Proton Beam Intensity Control in Mu2e
Dec 28, 2023



We introduce a novel Proximal Policy Optimization (PPO) algorithm aimed at addressing the challenge of maintaining a uniform proton beam intensity delivery in the Muon to Electron Conversion Experiment (Mu2e) at Fermi National Accelerator Laboratory (Fermilab). Our primary objective is to regulate the spill process to ensure a consistent intensity profile, with the ultimate goal of creating an automated controller capable of providing real-time feedback and calibration of the Spill Regulation System (SRS) parameters on a millisecond timescale. We treat the Mu2e accelerator system as a Markov Decision Process suitable for Reinforcement Learning (RL), utilizing PPO to reduce bias and enhance training stability. A key innovation in our approach is the integration of a neuralized Proportional-Integral-Derivative (PID) controller into the policy function, resulting in a significant improvement in the Spill Duty Factor (SDF) by 13.6%, surpassing the performance of the current PID controller baseline by an additional 1.6%. This paper presents the preliminary offline results based on a differentiable simulator of the Mu2e accelerator. It paves the groundwork for real-time implementations and applications, representing a crucial step towards automated proton beam intensity control for the Mu2e experiment.
Neural Architecture Codesign for Fast Bragg Peak Analysis
Dec 12, 2023



We develop an automated pipeline to streamline neural architecture codesign for fast, real-time Bragg peak analysis in high-energy diffraction microscopy. Traditional approaches, notably pseudo-Voigt fitting, demand significant computational resources, prompting interest in deep learning models for more efficient solutions. Our method employs neural architecture search and AutoML to enhance these models, including hardware costs, leading to the discovery of more hardware-efficient neural architectures. Our results match the performance, while achieving a 13$\times$ reduction in bit operations compared to the previous state-of-the-art. We show further speedup through model compression techniques such as quantization-aware-training and neural network pruning. Additionally, our hierarchical search space provides greater flexibility in optimization, which can easily extend to other tasks and domains.
Low latency optical-based mode tracking with machine learning deployed on FPGAs on a tokamak
Nov 30, 2023



Active feedback control in magnetic confinement fusion devices is desirable to mitigate plasma instabilities and enable robust operation. Optical high-speed cameras provide a powerful, non-invasive diagnostic and can be suitable for these applications. In this study, we process fast camera data, at rates exceeding 100kfps, on $\textit{in situ}$ Field Programmable Gate Array (FPGA) hardware to track magnetohydrodynamic (MHD) mode evolution and generate control signals in real-time. Our system utilizes a convolutional neural network (CNN) model which predicts the $n$=1 MHD mode amplitude and phase using camera images with better accuracy than other tested non-deep-learning-based methods. By implementing this model directly within the standard FPGA readout hardware of the high-speed camera diagnostic, our mode tracking system achieves a total trigger-to-output latency of 17.6$\mu$s and a throughput of up to 120kfps. This study at the High Beta Tokamak-Extended Pulse (HBT-EP) experiment demonstrates an FPGA-based high-speed camera data acquisition and processing system, enabling application in real-time machine-learning-based tokamak diagnostic and control as well as potential applications in other scientific domains.
On-Sensor Data Filtering using Neuromorphic Computing for High Energy Physics Experiments
Jul 20, 2023



This work describes the investigation of neuromorphic computing-based spiking neural network (SNN) models used to filter data from sensor electronics in high energy physics experiments conducted at the High Luminosity Large Hadron Collider. We present our approach for developing a compact neuromorphic model that filters out the sensor data based on the particle's transverse momentum with the goal of reducing the amount of data being sent to the downstream electronics. The incoming charge waveforms are converted to streams of binary-valued events, which are then processed by the SNN. We present our insights on the various system design choices - from data encoding to optimal hyperparameters of the training algorithm - for an accurate and compact SNN optimized for hardware deployment. Our results show that an SNN trained with an evolutionary algorithm and an optimized set of hyperparameters obtains a signal efficiency of about 91% with nearly half as many parameters as a deep neural network.
Differentiable Earth Mover's Distance for Data Compression at the High-Luminosity LHC
Jun 07, 2023The Earth mover's distance (EMD) is a useful metric for image recognition and classification, but its usual implementations are not differentiable or too slow to be used as a loss function for training other algorithms via gradient descent. In this paper, we train a convolutional neural network (CNN) to learn a differentiable, fast approximation of the EMD and demonstrate that it can be used as a substitute for computing-intensive EMD implementations. We apply this differentiable approximation in the training of an autoencoder-inspired neural network (encoder NN) for data compression at the high-luminosity LHC at CERN. The goal of this encoder NN is to compress the data while preserving the information related to the distribution of energy deposits in particle detectors. We demonstrate that the performance of our encoder NN trained using the differentiable EMD CNN surpasses that of training with loss functions based on mean squared error.
Structural Re-weighting Improves Graph Domain Adaptation
Jun 05, 2023In many real-world applications, graph-structured data used for training and testing have differences in distribution, such as in high energy physics (HEP) where simulation data used for training may not match real experiments. Graph domain adaptation (GDA) is a method used to address these differences. However, current GDA primarily works by aligning the distributions of node representations output by a single graph neural network encoder shared across the training and testing domains, which may often yield sub-optimal solutions. This work examines different impacts of distribution shifts caused by either graph structure or node attributes and identifies a new type of shift, named conditional structure shift (CSS), which current GDA approaches are provably sub-optimal to deal with. A novel approach, called structural reweighting (StruRW), is proposed to address this issue and is tested on synthetic graphs, four benchmark datasets, and a new application in HEP. StruRW has shown significant performance improvement over the baselines in the settings with large graph structure shifts, and reasonable performance improvement when node attribute shift dominates.
End-to-end codesign of Hessian-aware quantized neural networks for FPGAs and ASICs
Apr 13, 2023We develop an end-to-end workflow for the training and implementation of co-designed neural networks (NNs) for efficient field-programmable gate array (FPGA) and application-specific integrated circuit (ASIC) hardware. Our approach leverages Hessian-aware quantization (HAWQ) of NNs, the Quantized Open Neural Network Exchange (QONNX) intermediate representation, and the hls4ml tool flow for transpiling NNs into FPGA and ASIC firmware. This makes efficient NN implementations in hardware accessible to nonexperts, in a single open-sourced workflow that can be deployed for real-time machine learning applications in a wide range of scientific and industrial settings. We demonstrate the workflow in a particle physics application involving trigger decisions that must operate at the 40 MHz collision rate of the CERN Large Hadron Collider (LHC). Given the high collision rate, all data processing must be implemented on custom ASIC and FPGA hardware within a strict area and latency. Based on these constraints, we implement an optimized mixed-precision NN classifier for high-momentum particle jets in simulated LHC proton-proton collisions.
Neural network accelerator for quantum control
Aug 04, 2022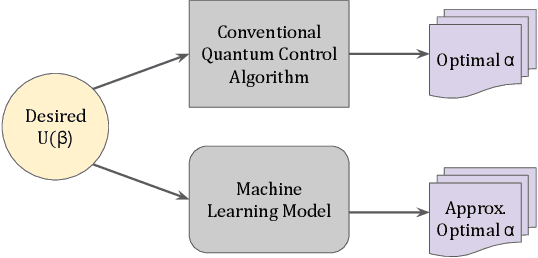
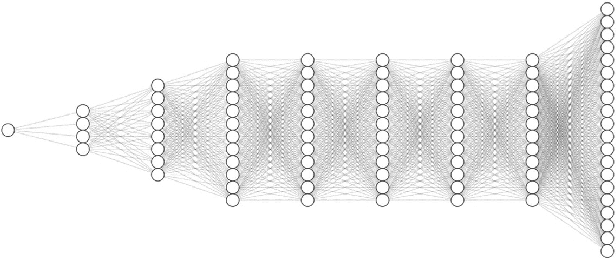
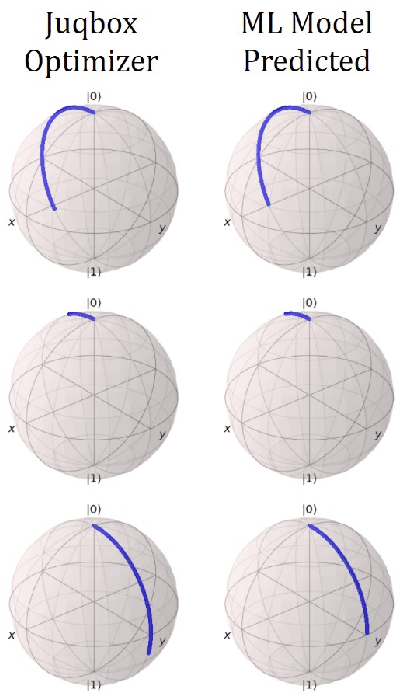
Efficient quantum control is necessary for practical quantum computing implementations with current technologies. Conventional algorithms for determining optimal control parameters are computationally expensive, largely excluding them from use outside of the simulation. Existing hardware solutions structured as lookup tables are imprecise and costly. By designing a machine learning model to approximate the results of traditional tools, a more efficient method can be produced. Such a model can then be synthesized into a hardware accelerator for use in quantum systems. In this study, we demonstrate a machine learning algorithm for predicting optimal pulse parameters. This algorithm is lightweight enough to fit on a low-resource FPGA and perform inference with a latency of 175 ns and pipeline interval of 5 ns with $~>~$0.99 gate fidelity. In the long term, such an accelerator could be used near quantum computing hardware where traditional computers cannot operate, enabling quantum control at a reasonable cost at low latencies without incurring large data bandwidths outside of the cryogenic environment.