 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRSV: Robotic Sonography for Thyroid Volumetry
Dec 13, 2021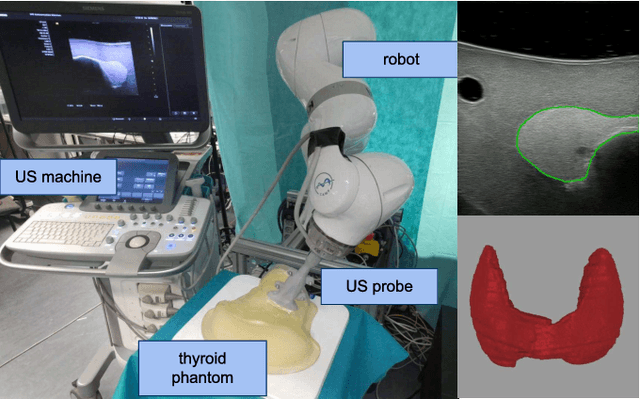
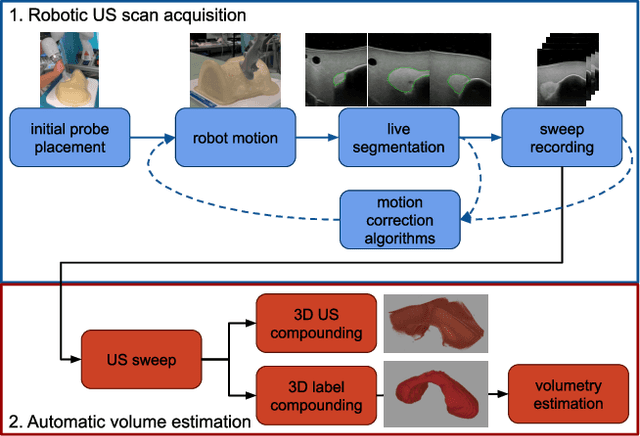
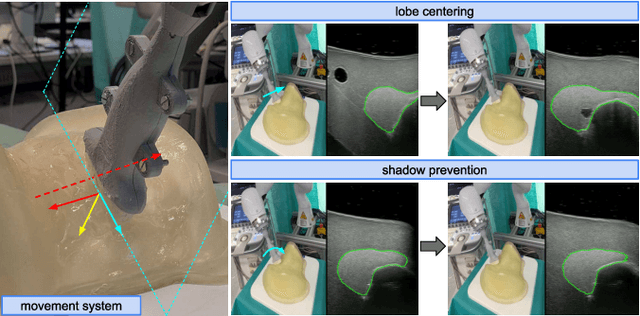
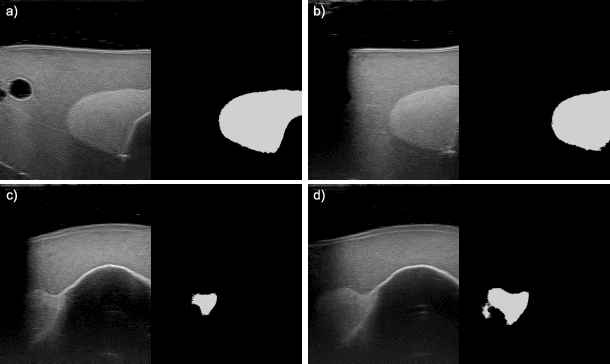
In nuclear medicine, radioiodine therapy is prescribed to treat diseases like hyperthyroidism. The calculation of the prescribed dose depends, amongst other factors, on the thyroid volume. This is currently estimated using conventional 2D ultrasound imaging. However, this modality is inherently user-dependant, resulting in high variability in volume estimations. To increase reproducibility and consistency, we uniquely combine a neural network-based segmentation with an automatic robotic ultrasound scanning for thyroid volumetry. The robotic acquisition is achieved by using a 6 DOF robotic arm with an attached ultrasound probe. Its movement is based on an online segmentation of each thyroid lobe and the appearance of the US image. During post-processing, the US images are segmented to obtain a volume estimation. In an ablation study, we demonstrated the superiority of the motion guidance algorithms for the robot arm movement compared to a naive linear motion, executed by the robot in terms of volumetric accuracy. In a user study on a phantom, we compared conventional 2D ultrasound measurements with our robotic system. The mean volume measurement error of ultrasound expert users could be significantly decreased from 20.85+/-16.10% to only 8.23+/-3.10% compared to the ground truth. This tendency was observed even more in non-expert users where the mean error improvement with the robotic system was measured to be as high as $85\%$ which clearly shows the advantages of the robotic support.
3D-VField: Learning to Adversarially Deform Point Clouds for Robust 3D Object Detection
Dec 09, 2021
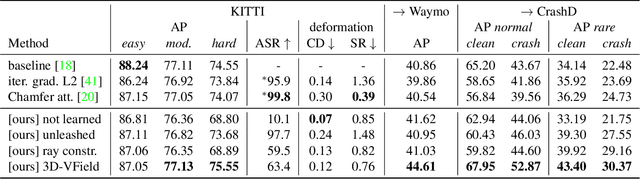
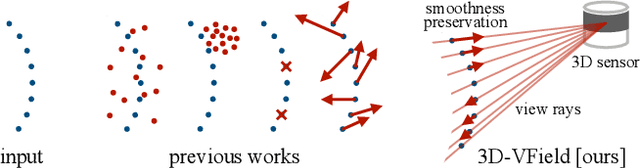

As 3D object detection on point clouds relies on the geometrical relationships between the points, non-standard object shapes can hinder a method's detection capability. However, in safety-critical settings, robustness on out-of-distribution and long-tail samples is fundamental to circumvent dangerous issues, such as the misdetection of damaged or rare cars. In this work, we substantially improve the generalization of 3D object detectors to out-of-domain data by taking into account deformed point clouds during training. We achieve this with 3D-VField: a novel method that plausibly deforms objects via vectors learned in an adversarial fashion. Our approach constrains 3D points to slide along their sensor view rays while neither adding nor removing any of them. The obtained vectors are transferrable, sample-independent and preserve shape smoothness and occlusions. By augmenting normal samples with the deformations produced by these vector fields during training, we significantly improve robustness against differently shaped objects, such as damaged/deformed cars, even while training only on KITTI. Towards this end, we propose and share open source CrashD: a synthetic dataset of realistic damaged and rare cars, with a variety of crash scenarios. Extensive experiments on KITTI, Waymo, our CrashD and SUN RGB-D show the high generalizability of our techniques to out-of-domain data, different models and sensors, namely LiDAR and ToF cameras, for both indoor and outdoor scenes. Our CrashD dataset is available at https://crashd-cars.github.io.
Polarimetric Pose Prediction
Dec 07, 2021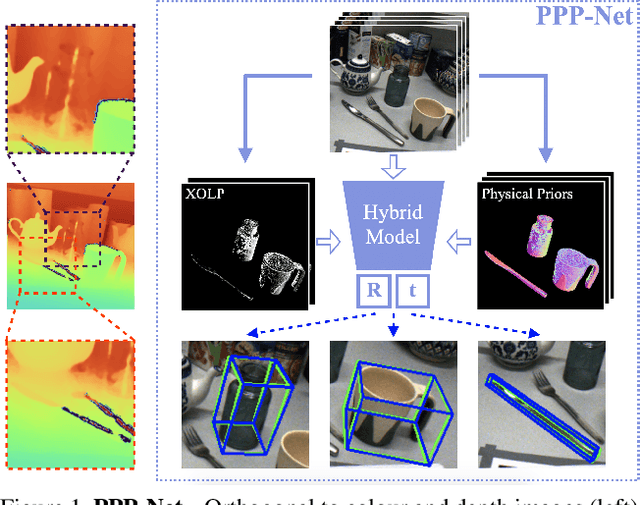
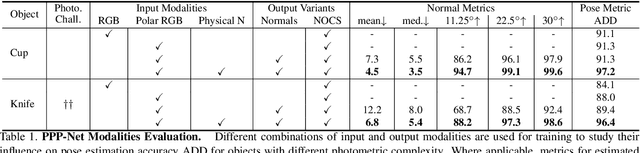
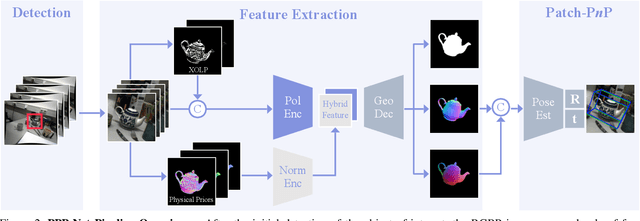
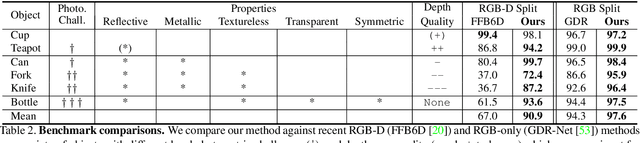
Light has many properties that can be passively measured by vision sensors. Colour-band separated wavelength and intensity are arguably the most commonly used ones for monocular 6D object pose estimation. This paper explores how complementary polarisation information, i.e. the orientation of light wave oscillations, can influence the accuracy of pose predictions. A hybrid model that leverages physical priors jointly with a data-driven learning strategy is designed and carefully tested on objects with different amount of photometric complexity. Our design not only significantly improves the pose accuracy in relation to photometric state-of-the-art approaches, but also enables object pose estimation for highly reflective and transparent objects.
Wild ToFu: Improving Range and Quality of Indirect Time-of-Flight Depth with RGB Fusion in Challenging Environments
Dec 07, 2021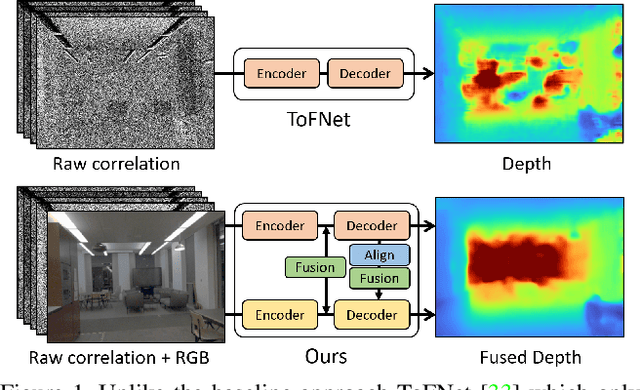

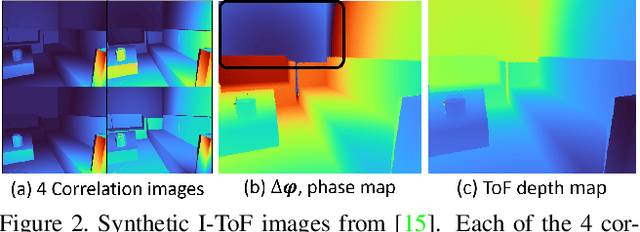
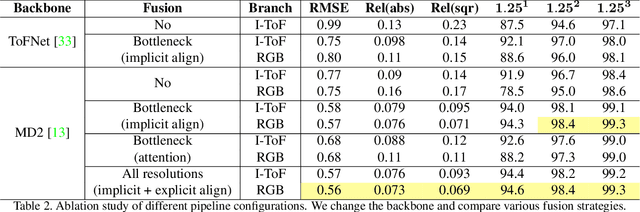
Indirect Time-of-Flight (I-ToF) imaging is a widespread way of depth estimation for mobile devices due to its small size and affordable price. Previous works have mainly focused on quality improvement for I-ToF imaging especially curing the effect of Multi Path Interference (MPI). These investigations are typically done in specifically constrained scenarios at close distance, indoors and under little ambient light. Surprisingly little work has investigated I-ToF quality improvement in real-life scenarios where strong ambient light and far distances pose difficulties due to an extreme amount of induced shot noise and signal sparsity, caused by the attenuation with limited sensor power and light scattering. In this work, we propose a new learning based end-to-end depth prediction network which takes noisy raw I-ToF signals as well as an RGB image and fuses their latent representation based on a multi step approach involving both implicit and explicit alignment to predict a high quality long range depth map aligned to the RGB viewpoint. We test our approach on challenging real-world scenes and show more than 40% RMSE improvement on the final depth map compared to the baseline approach.
DemoGrasp: Few-Shot Learning for Robotic Grasping with Human Demonstration
Dec 06, 2021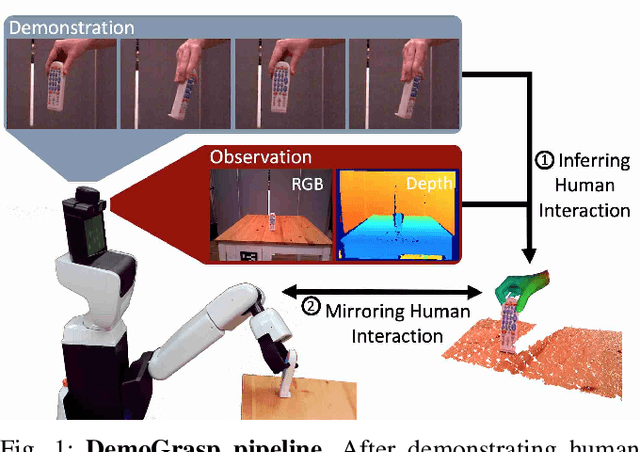
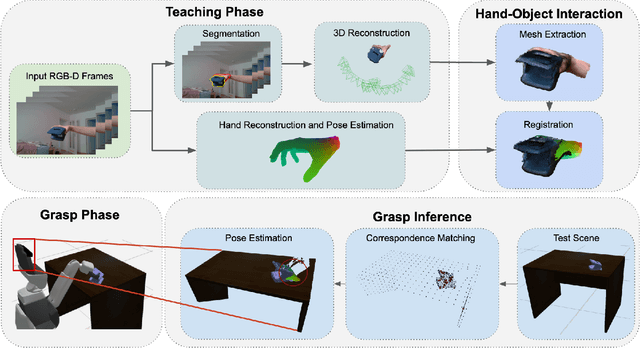


The ability to successfully grasp objects is crucial in robotics, as it enables several interactive downstream applications. To this end, most approaches either compute the full 6D pose for the object of interest or learn to predict a set of grasping points. While the former approaches do not scale well to multiple object instances or classes yet, the latter require large annotated datasets and are hampered by their poor generalization capabilities to new geometries. To overcome these shortcomings, we propose to teach a robot how to grasp an object with a simple and short human demonstration. Hence, our approach neither requires many annotated images nor is it restricted to a specific geometry. We first present a small sequence of RGB-D images displaying a human-object interaction. This sequence is then leveraged to build associated hand and object meshes that represent the depicted interaction. Subsequently, we complete missing parts of the reconstructed object shape and estimate the relative transformation between the reconstruction and the visible object in the scene. Finally, we transfer the a-priori knowledge from the relative pose between object and human hand with the estimate of the current object pose in the scene into necessary grasping instructions for the robot. Exhaustive evaluations with Toyota's Human Support Robot (HSR) in real and synthetic environments demonstrate the applicability of our proposed methodology and its advantage in comparison to previous approaches.
Object-aware Monocular Depth Prediction with Instance Convolutions
Dec 02, 2021


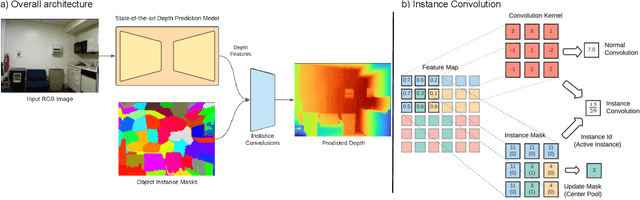
With the advent of deep learning, estimating depth from a single RGB image has recently received a lot of attention, being capable of empowering many different applications ranging from path planning for robotics to computational cinematography. Nevertheless, while the depth maps are in their entirety fairly reliable, the estimates around object discontinuities are still far from satisfactory. This can be contributed to the fact that the convolutional operator naturally aggregates features across object discontinuities, resulting in smooth transitions rather than clear boundaries. Therefore, in order to circumvent this issue, we propose a novel convolutional operator which is explicitly tailored to avoid feature aggregation of different object parts. In particular, our method is based on estimating per-part depth values by means of superpixels. The proposed convolutional operator, which we dub "Instance Convolution", then only considers each object part individually on the basis of the estimated superpixels. Our evaluation with respect to the NYUv2 as well as the iBims dataset clearly demonstrates the superiority of Instance Convolutions over the classical convolution at estimating depth around occlusion boundaries, while producing comparable results elsewhere. Code will be made publicly available upon acceptance.
ColibriDoc: An Eye-in-Hand Autonomous Trocar Docking System
Nov 30, 2021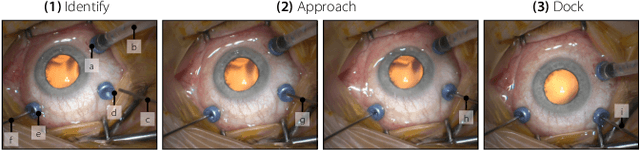

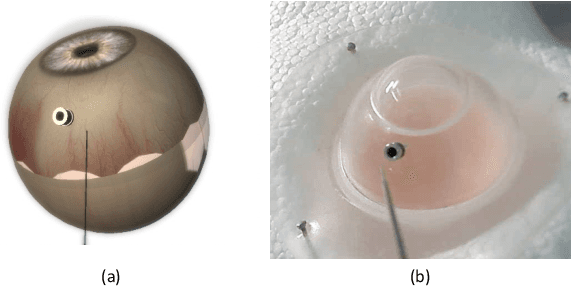
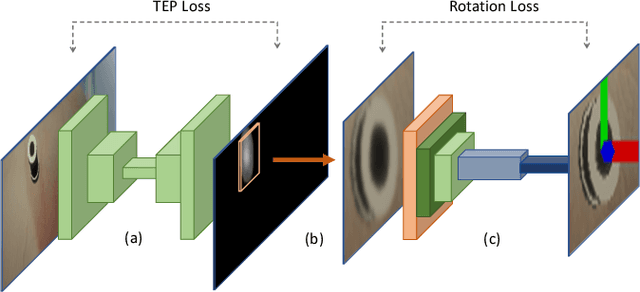
Retinal surgery is a complex medical procedure that requires exceptional expertise and dexterity. For this purpose, several robotic platforms are currently being developed to enable or improve the outcome of microsurgical tasks. Since the control of such robots is often designed for navigation inside the eye in proximity to the retina, successful trocar docking and inserting the instrument into the eye represents an additional cognitive effort, and is, therefore, one of the open challenges in robotic retinal surgery. For this purpose, we present a platform for autonomous trocar docking that combines computer vision and a robotic setup. Inspired by the Cuban Colibri (hummingbird) aligning its beak to a flower using only vision, we mount a camera onto the endeffector of a robotic system. By estimating the position and pose of the trocar, the robot is able to autonomously align and navigate the instrument towards the Trocar's Entry Point (TEP) and finally perform the insertion. Our experiments show that the proposed method is able to accurately estimate the position and pose of the trocar and achieve repeatable autonomous docking. The aim of this work is to reduce the complexity of robotic setup preparation prior to the surgical task and therefore, increase the intuitiveness of the system integration into the clinical workflow.
MIGS: Meta Image Generation from Scene Graphs
Oct 22, 2021
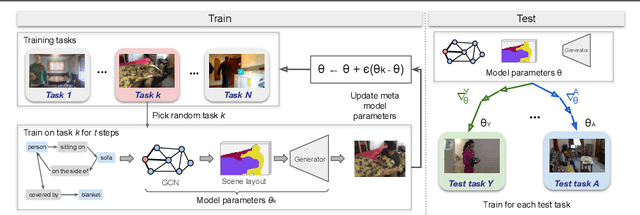
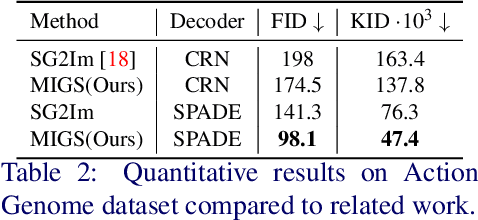

Generation of images from scene graphs is a promising direction towards explicit scene generation and manipulation. However, the images generated from the scene graphs lack quality, which in part comes due to high difficulty and diversity in the data. We propose MIGS (Meta Image Generation from Scene Graphs), a meta-learning based approach for few-shot image generation from graphs that enables adapting the model to different scenes and increases the image quality by training on diverse sets of tasks. By sampling the data in a task-driven fashion, we train the generator using meta-learning on different sets of tasks that are categorized based on the scene attributes. Our results show that using this meta-learning approach for the generation of images from scene graphs achieves state-of-the-art performance in terms of image quality and capturing the semantic relationships in the scene. Project Website: https://migs2021.github.io/
Attention meets Geometry: Geometry Guided Spatial-Temporal Attention for Consistent Self-Supervised Monocular Depth Estimation
Oct 15, 2021
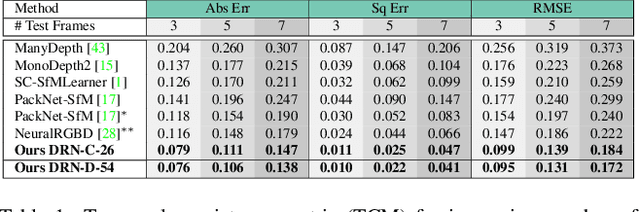

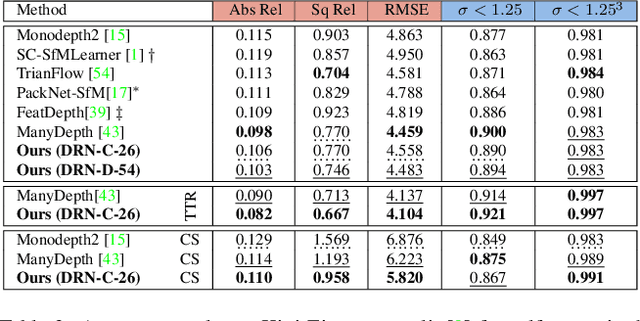
Inferring geometrically consistent dense 3D scenes across a tuple of temporally consecutive images remains challenging for self-supervised monocular depth prediction pipelines. This paper explores how the increasingly popular transformer architecture, together with novel regularized loss formulations, can improve depth consistency while preserving accuracy. We propose a spatial attention module that correlates coarse depth predictions to aggregate local geometric information. A novel temporal attention mechanism further processes the local geometric information in a global context across consecutive images. Additionally, we introduce geometric constraints between frames regularized by photometric cycle consistency. By combining our proposed regularization and the novel spatial-temporal-attention module we fully leverage both the geometric and appearance-based consistency across monocular frames. This yields geometrically meaningful attention and improves temporal depth stability and accuracy compared to previous methods.
Semantic Image Alignment for Vehicle Localization
Oct 08, 2021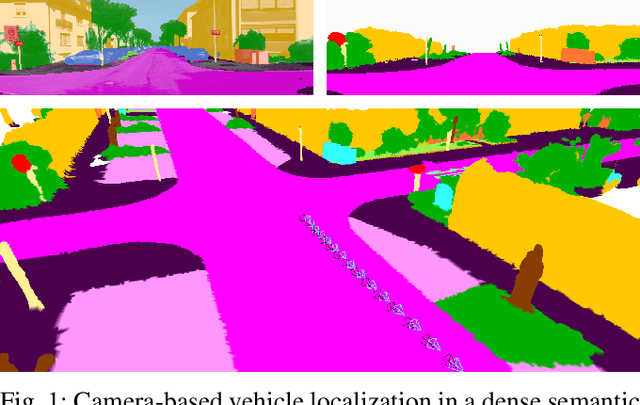
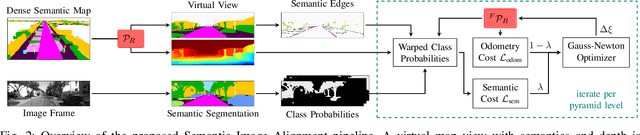
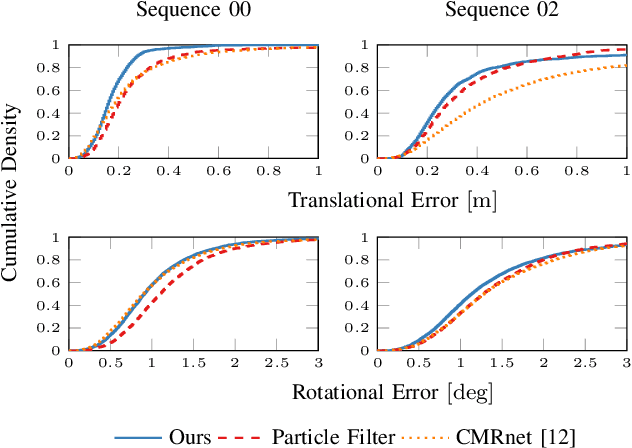
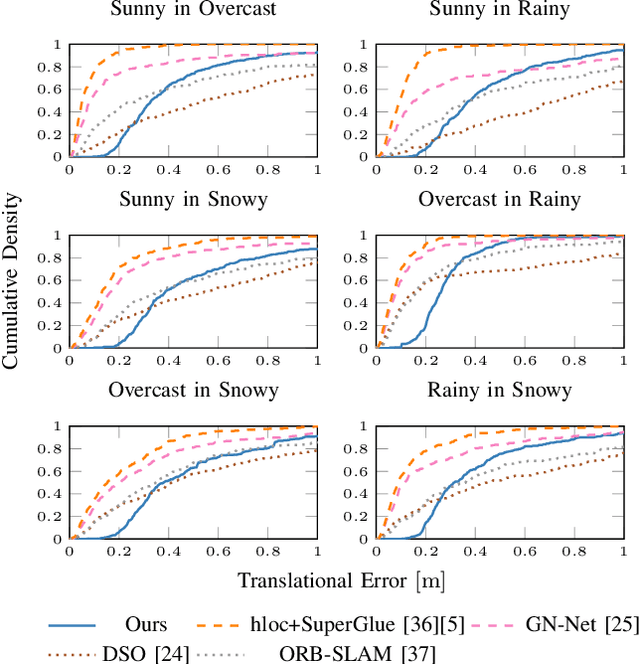
Accurate and reliable localization is a fundamental requirement for autonomous vehicles to use map information in higher-level tasks such as navigation or planning. In this paper, we present a novel approach to vehicle localization in dense semantic maps, including vectorized high-definition maps or 3D meshes, using semantic segmentation from a monocular camera. We formulate the localization task as a direct image alignment problem on semantic images, which allows our approach to robustly track the vehicle pose in semantically labeled maps by aligning virtual camera views rendered from the map to sequences of semantically segmented camera images. In contrast to existing visual localization approaches, the system does not require additional keypoint features, handcrafted localization landmark extractors or expensive LiDAR sensors. We demonstrate the wide applicability of our method on a diverse set of semantic mesh maps generated from stereo or LiDAR as well as manually annotated HD maps and show that it achieves reliable and accurate localization in real-time.