 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimum Word Error Rate Training with Language Model Fusion for End-to-End Speech Recognition
Jun 04, 2021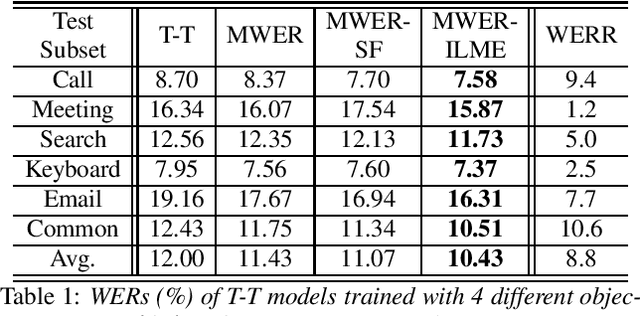
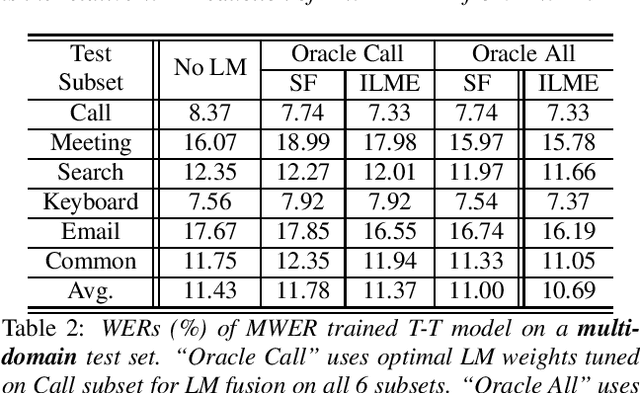
Integrating external language models (LMs) into end-to-end (E2E) models remains a challenging task for domain-adaptive speech recognition. Recently, internal language model estimation (ILME)-based LM fusion has shown significant word error rate (WER) reduction from Shallow Fusion by subtracting a weighted internal LM score from an interpolation of E2E model and external LM scores during beam search. However, on different test sets, the optimal LM interpolation weights vary over a wide range and have to be tuned extensively on well-matched validation sets. In this work, we perform LM fusion in the minimum WER (MWER) training of an E2E model to obviate the need for LM weights tuning during inference. Besides MWER training with Shallow Fusion (MWER-SF), we propose a novel MWER training with ILME (MWER-ILME) where the ILME-based fusion is conducted to generate N-best hypotheses and their posteriors. Additional gradient is induced when internal LM is engaged in MWER-ILME loss computation. During inference, LM weights pre-determined in MWER training enable robust LM integrations on test sets from different domains. Experimented with 30K-hour trained transformer transducers, MWER-ILME achieves on average 8.8% and 5.8% relative WER reductions from MWER and MWER-SF training, respectively, on 6 different test sets
* 5 pages, Interspeech 2021
Large-Scale Pre-Training of End-to-End Multi-Talker ASR for Meeting Transcription with Single Distant Microphone
Apr 12, 2021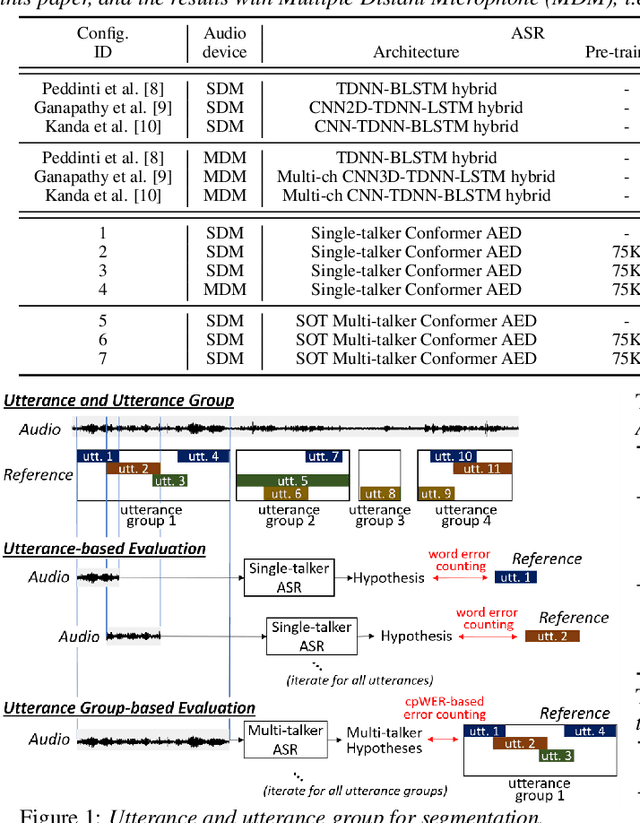


Transcribing meetings containing overlapped speech with only a single distant microphone (SDM) has been one of the most challenging problems for automatic speech recognition (ASR). While various approaches have been proposed, all previous studies on the monaural overlapped speech recognition problem were based on either simulation data or small-scale real data. In this paper, we extensively investigate a two-step approach where we first pre-train a serialized output training (SOT)-based multi-talker ASR by using large-scale simulation data and then fine-tune the model with a small amount of real meeting data. Experiments are conducted by utilizing 75 thousand (K) hours of our internal single-talker recording to simulate a total of 900K hours of multi-talker audio segments for supervised pre-training. With fine-tuning on the 70 hours of the AMI-SDM training data, our SOT ASR model achieves a word error rate (WER) of 21.2% for the AMI-SDM evaluation set while automatically counting speakers in each test segment. This result is not only significantly better than the previous state-of-the-art WER of 36.4% with oracle utterance boundary information but also better than a result by a similarly fine-tuned single-talker ASR model applied to beamformed audio.
End-to-End Speaker-Attributed ASR with Transformer
Apr 05, 2021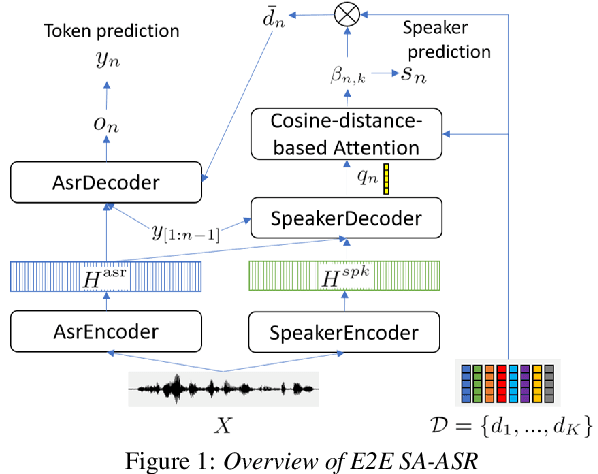
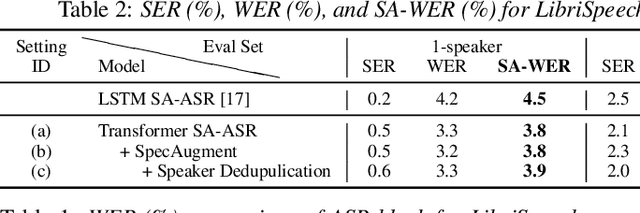
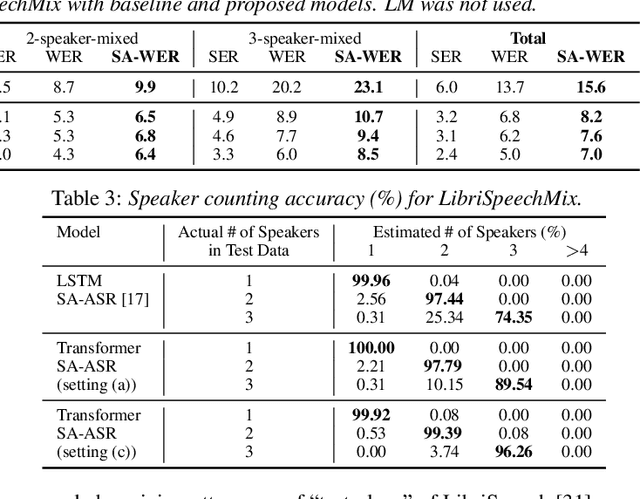
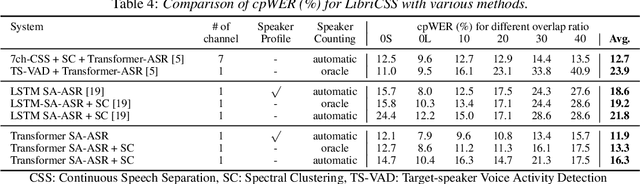
This paper presents our recent effort on end-to-end speaker-attributed automatic speech recognition, which jointly performs speaker counting, speech recognition and speaker identification for monaural multi-talker audio. Firstly, we thoroughly update the model architecture that was previously designed based on a long short-term memory (LSTM)-based attention encoder decoder by applying transformer architectures. Secondly, we propose a speaker deduplication mechanism to reduce speaker identification errors in highly overlapped regions. Experimental results on the LibriSpeechMix dataset shows that the transformer-based architecture is especially good at counting the speakers and that the proposed model reduces the speaker-attributed word error rate by 47% over the LSTM-based baseline. Furthermore, for the LibriCSS dataset, which consists of real recordings of overlapped speech, the proposed model achieves concatenated minimum-permutation word error rates of 11.9% and 16.3% with and without target speaker profiles, respectively, both of which are the state-of-the-art results for LibriCSS with the monaural setting.
Streaming Multi-talker Speech Recognition with Joint Speaker Identification
Apr 05, 2021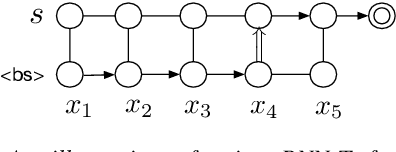
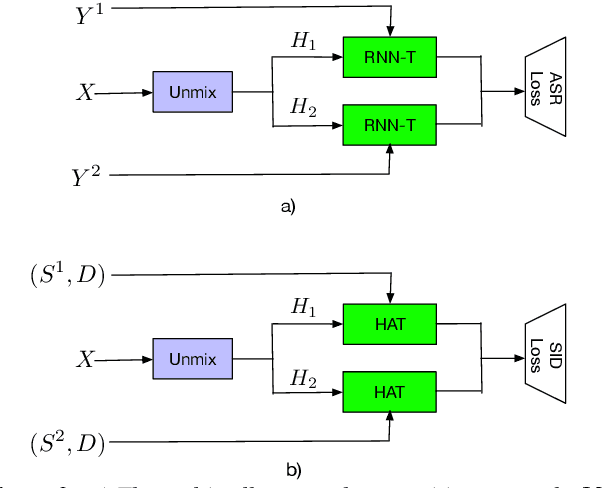
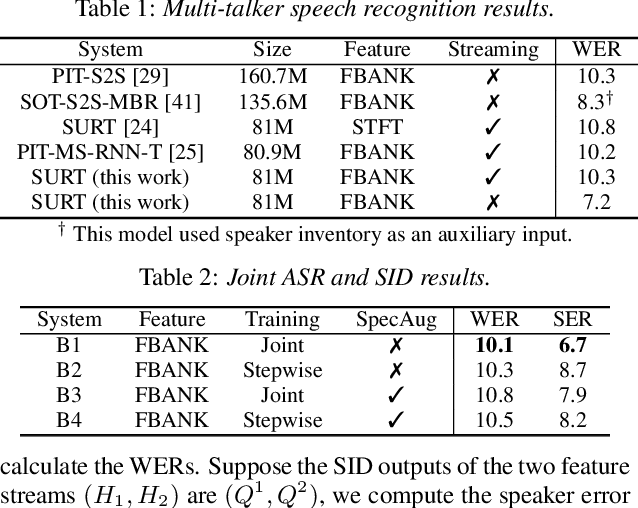
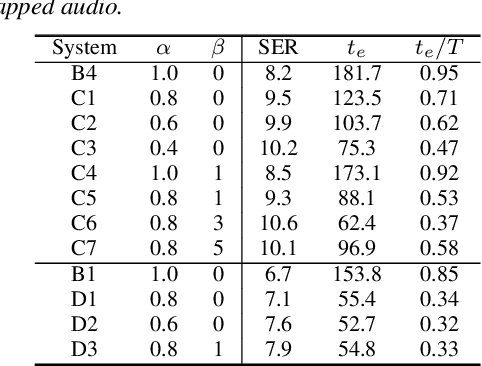
In multi-talker scenarios such as meetings and conversations, speech processing systems are usually required to transcribe the audio as well as identify the speakers for downstream applications. Since overlapped speech is common in this case, conventional approaches usually address this problem in a cascaded fashion that involves speech separation, speech recognition and speaker identification that are trained independently. In this paper, we propose Streaming Unmixing, Recognition and Identification Transducer (SURIT) -- a new framework that deals with this problem in an end-to-end streaming fashion. SURIT employs the recurrent neural network transducer (RNN-T) as the backbone for both speech recognition and speaker identification. We validate our idea on the LibrispeechMix dataset -- a multi-talker dataset derived from Librispeech, and present encouraging results.
Speech-language Pre-training for End-to-end Spoken Language Understanding
Feb 11, 2021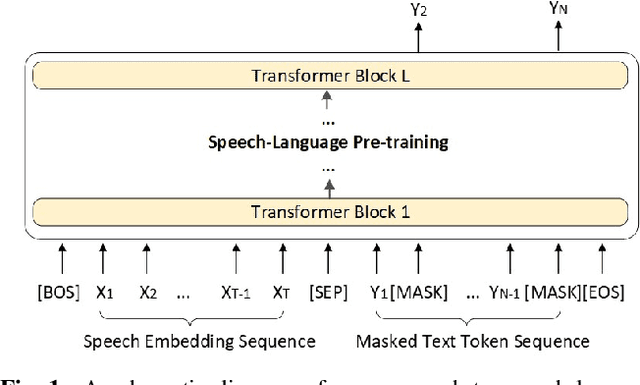
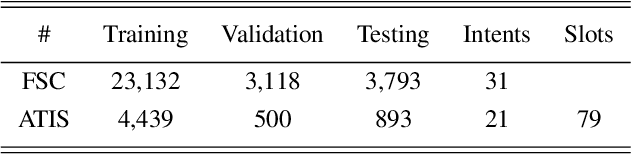
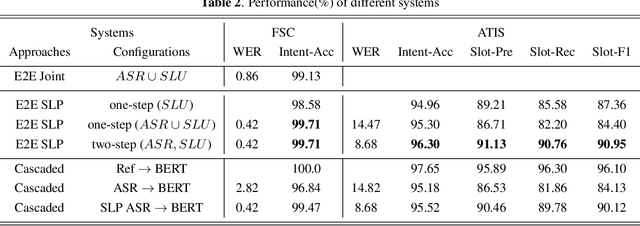
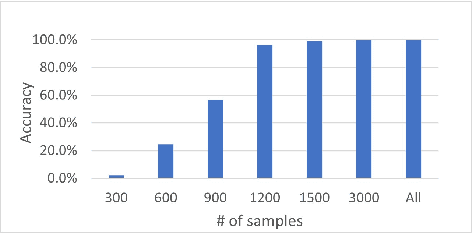
End-to-end (E2E) spoken language understanding (SLU) can infer semantics directly from speech signal without cascading an automatic speech recognizer (ASR) with a natural language understanding (NLU) module. However, paired utterance recordings and corresponding semantics may not always be available or sufficient to train an E2E SLU model in a real production environment. In this paper, we propose to unify a well-optimized E2E ASR encoder (speech) and a pre-trained language model encoder (language) into a transformer decoder. The unified speech-language pre-trained model (SLP) is continually enhanced on limited labeled data from a target domain by using a conditional masked language model (MLM) objective, and thus can effectively generate a sequence of intent, slot type, and slot value for given input speech in the inference. The experimental results on two public corpora show that our approach to E2E SLU is superior to the conventional cascaded method. It also outperforms the present state-of-the-art approaches to E2E SLU with much less paired data.
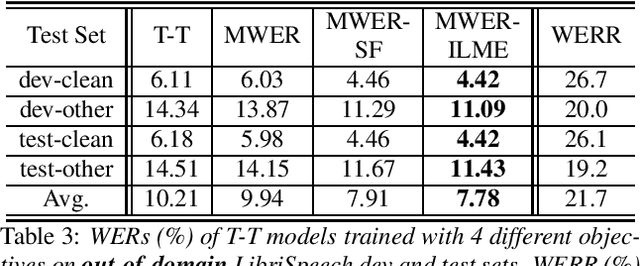
Internal Language Model Training for Domain-Adaptive End-to-End Speech Recognition
Feb 02, 2021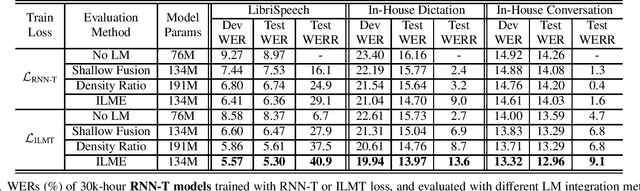
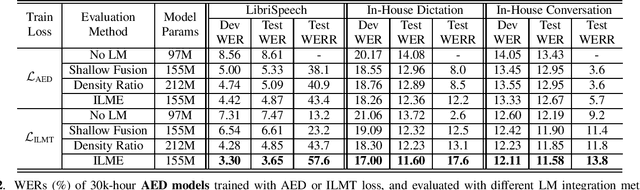
The efficacy of external language model (LM) integration with existing end-to-end (E2E) automatic speech recognition (ASR) systems can be improved significantly using the internal language model estimation (ILME) method. In this method, the internal LM score is subtracted from the score obtained by interpolating the E2E score with the external LM score, during inference. To improve the ILME-based inference, we propose an internal LM training (ILMT) method to minimize an additional internal LM loss by updating only the E2E model components that affect the internal LM estimation. ILMT encourages the E2E model to form a standalone LM inside its existing components, without sacrificing ASR accuracy. After ILMT, the more modular E2E model with matched training and inference criteria enables a more thorough elimination of the source-domain internal LM, and therefore leads to a more effective integration of the target-domain external LM. Experimented with 30K-hour trained recurrent neural network transducer and attention-based encoder-decoder models, ILMT with ILME-based inference achieves up to 31.5% and 11.4% relative word error rate reductions from standard E2E training with Shallow Fusion on out-of-domain LibriSpeech and in-domain Microsoft production test sets, respectively.
* 5 pages, ICASSP 2021
A Review of Speaker Diarization: Recent Advances with Deep Learning
Jan 24, 2021
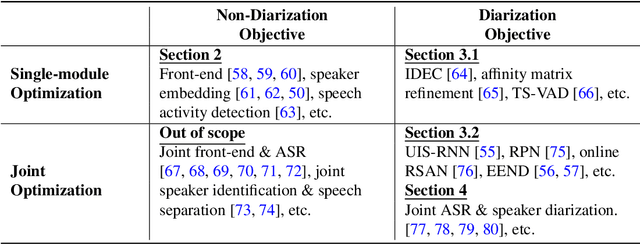
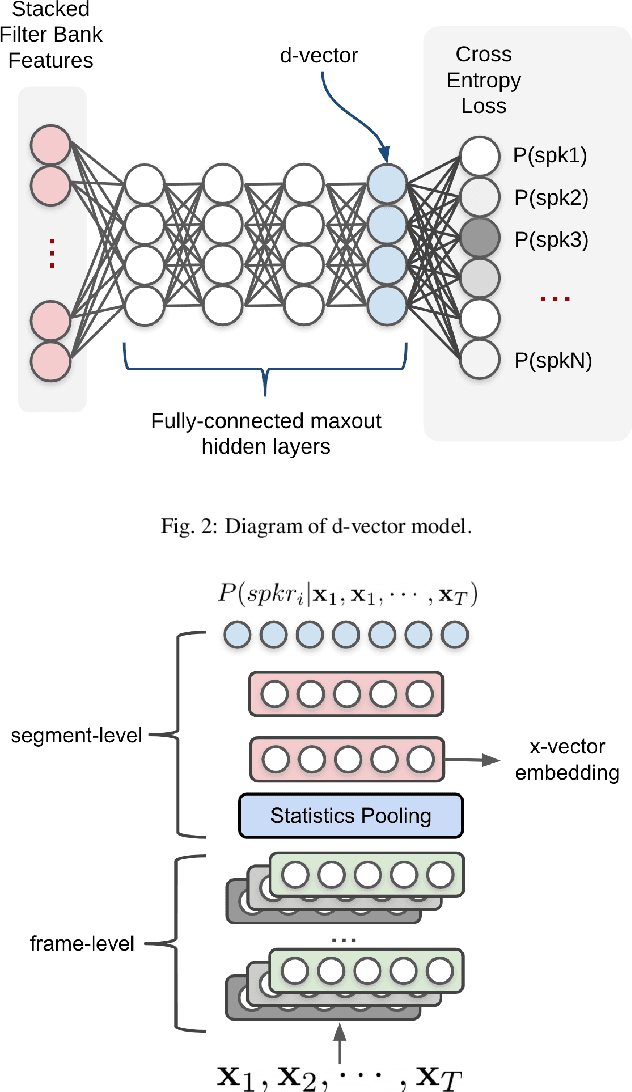
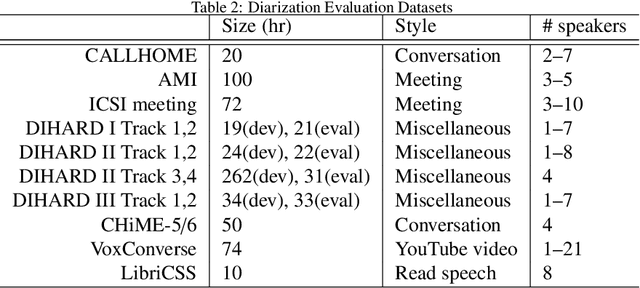
Speaker diarization is a task to label audio or video recordings with classes corresponding to speaker identity, or in short, a task to identify "who spoke when". In the early years, speaker diarization algorithms were developed for speech recognition on multi-speaker audio recordings to enable speaker adaptive processing, but also gained its own value as a stand-alone application over time to provide speaker-specific meta information for downstream tasks such as audio retrieval. More recently, with the rise of deep learning technology that has been a driving force to revolutionary changes in research and practices across speech application domains in the past decade, more rapid advancements have been made for speaker diarization. In this paper, we review not only the historical development of speaker diarization technology but also the recent advancements in neural speaker diarization approaches. We also discuss how speaker diarization systems have been integrated with speech recognition applications and how the recent surge of deep learning is leading the way of jointly modeling these two components to be complementary to each other. By considering such exciting technical trends, we believe that it is a valuable contribution to the community to provide a survey work by consolidating the recent developments with neural methods and thus facilitating further progress towards a more efficient speaker diarization.
Hypothesis Stitcher for End-to-End Speaker-attributed ASR on Long-form Multi-talker Recordings
Jan 06, 2021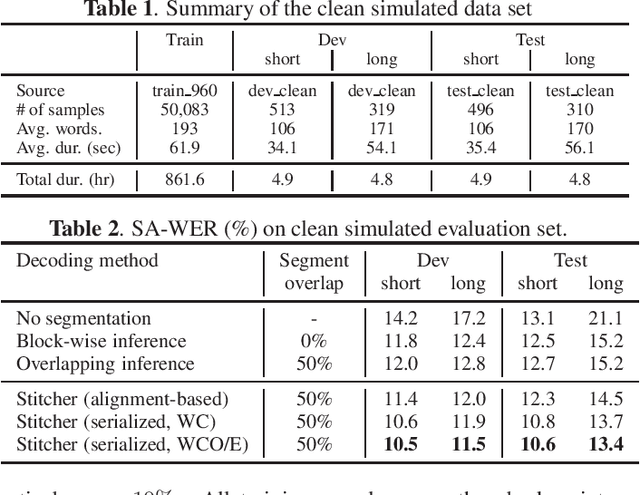
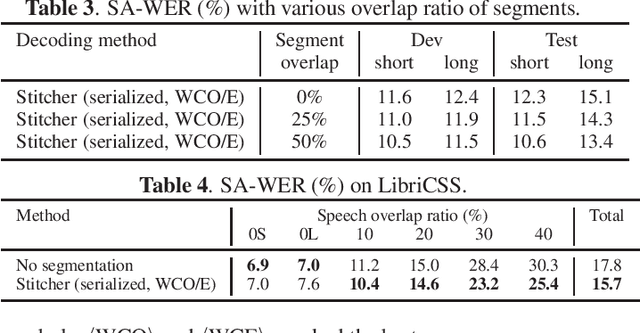
An end-to-end (E2E) speaker-attributed automatic speech recognition (SA-ASR) model was proposed recently to jointly perform speaker counting, speech recognition and speaker identification. The model achieved a low speaker-attributed word error rate (SA-WER) for monaural overlapped speech comprising an unknown number of speakers. However, the E2E modeling approach is susceptible to the mismatch between the training and testing conditions. It has yet to be investigated whether the E2E SA-ASR model works well for recordings that are much longer than samples seen during training. In this work, we first apply a known decoding technique that was developed to perform single-speaker ASR for long-form audio to our E2E SA-ASR task. Then, we propose a novel method using a sequence-to-sequence model, called hypothesis stitcher. The model takes multiple hypotheses obtained from short audio segments that are extracted from the original long-form input, and it then outputs a fused single hypothesis. We propose several architectural variations of the hypothesis stitcher model and compare them with the conventional decoding methods. Experiments using LibriSpeech and LibriCSS corpora show that the proposed method significantly improves SA-WER especially for long-form multi-talker recordings.
Streaming end-to-end multi-talker speech recognition
Nov 26, 2020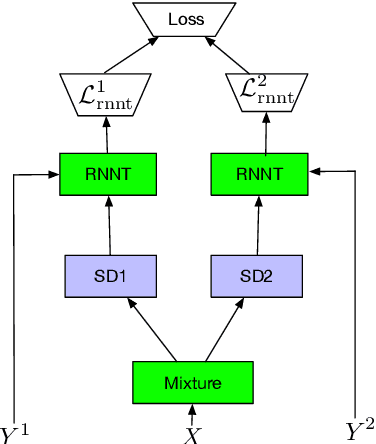


End-to-end multi-talker speech recognition is an emerging research trend in the speech community due to its vast potential in applications such as conversation and meeting transcriptions. To the best of our knowledge, all existing research works are constrained in the offline scenario. In this work, we propose the Streaming Unmixing and Recognition Transducer (SURT) for end-to-end multi-talker speech recognition. Our model employs the Recurrent Neural Network Transducer as the backbone that can meet various latency constraints. We study two different model architectures that are based on a speaker-differentiator encoder and a mask encoder respectively. To train this model, we investigate the widely used Permutation Invariant Training (PIT) approach and the recently introduced Heuristic Error Assignment Training (HEAT) approach. Based on experiments on the publicly available LibriSpeechMix dataset, we show that HEAT can achieve better accuracy compared with PIT, and the SURT model with 120 milliseconds algorithmic latency constraint compares favorably with the offline sequence-to-sequence based baseline model in terms of accuracy.
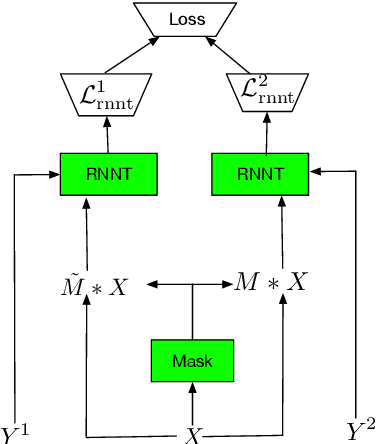
Minimum Bayes Risk Training for End-to-End Speaker-Attributed ASR
Nov 03, 2020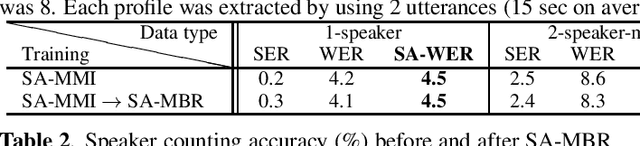
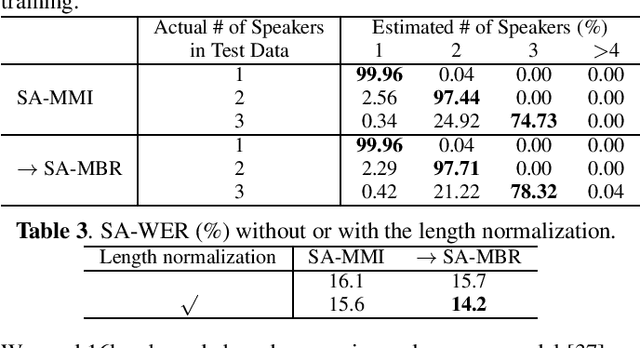
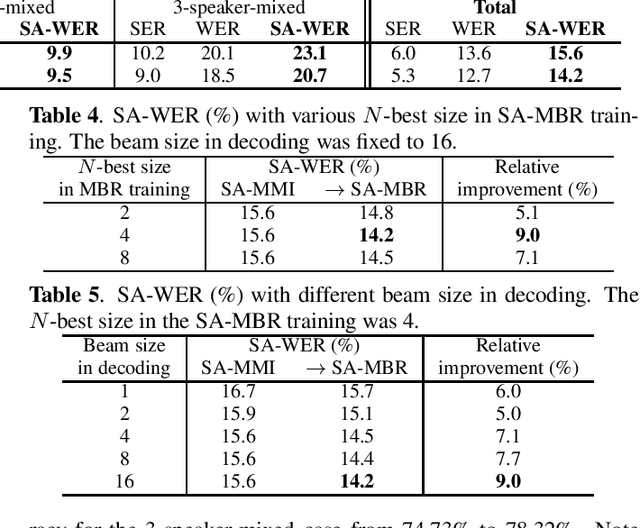
Recently, an end-to-end speaker-attributed automatic speech recognition (E2E SA-ASR) model was proposed as a joint model of speaker counting, speech recognition and speaker identification for monaural overlapped speech. In the previous study, the model parameters were trained based on the speaker-attributed maximum mutual information (SA-MMI) criterion, with which the joint posterior probability for multi-talker transcription and speaker identification are maximized over training data. Although SA-MMI training showed promising results for overlapped speech consisting of various numbers of speakers, the training criterion was not directly linked to the final evaluation metric, i.e., speaker-attributed word error rate (SA-WER). In this paper, we propose a speaker-attributed minimum Bayes risk (SA-MBR) training method where the parameters are trained to directly minimize the expected SA-WER over the training data. Experiments using the LibriSpeech corpus show that the proposed SA-MBR training reduces the SA-WER by 9.0 % relative compared with the SA-MMI-trained model.