 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiomedJourney: Counterfactual Biomedical Image Generation by Instruction-Learning from Multimodal Patient Journeys
Oct 21, 2023



Rapid progress has been made in instruction-learning for image editing with natural-language instruction, as exemplified by InstructPix2Pix. In biomedicine, such methods can be applied to counterfactual image generation, which helps differentiate causal structure from spurious correlation and facilitate robust image interpretation for disease progression modeling. However, generic image-editing models are ill-suited for the biomedical domain, and counterfactual biomedical image generation is largely underexplored. In this paper, we present BiomedJourney, a novel method for counterfactual biomedical image generation by instruction-learning from multimodal patient journeys. Given a patient with two biomedical images taken at different time points, we use GPT-4 to process the corresponding imaging reports and generate a natural language description of disease progression. The resulting triples (prior image, progression description, new image) are then used to train a latent diffusion model for counterfactual biomedical image generation. Given the relative scarcity of image time series data, we introduce a two-stage curriculum that first pretrains the denoising network using the much more abundant single image-report pairs (with dummy prior image), and then continues training using the counterfactual triples. Experiments using the standard MIMIC-CXR dataset demonstrate the promise of our method. In a comprehensive battery of tests on counterfactual medical image generation, BiomedJourney substantially outperforms prior state-of-the-art methods in instruction image editing and medical image generation such as InstructPix2Pix and RoentGen. To facilitate future study in counterfactual medical generation, we plan to release our instruction-learning code and pretrained models.
Scaling Clinical Trial Matching Using Large Language Models: A Case Study in Oncology
Aug 18, 2023Clinical trial matching is a key process in health delivery and discovery. In practice, it is plagued by overwhelming unstructured data and unscalable manual processing. In this paper, we conduct a systematic study on scaling clinical trial matching using large language models (LLMs), with oncology as the focus area. Our study is grounded in a clinical trial matching system currently in test deployment at a large U.S. health network. Initial findings are promising: out of box, cutting-edge LLMs, such as GPT-4, can already structure elaborate eligibility criteria of clinical trials and extract complex matching logic (e.g., nested AND/OR/NOT). While still far from perfect, LLMs substantially outperform prior strong baselines and may serve as a preliminary solution to help triage patient-trial candidates with humans in the loop. Our study also reveals a few significant growth areas for applying LLMs to end-to-end clinical trial matching, such as context limitation and accuracy, especially in structuring patient information from longitudinal medical records.
Distilling Large Language Models for Biomedical Knowledge Extraction: A Case Study on Adverse Drug Events
Jul 12, 2023



Large language models (LLMs), such as GPT-4, have demonstrated remarkable capabilities across a wide range of tasks, including health applications. In this paper, we study how LLMs can be used to scale biomedical knowledge curation. We find that while LLMs already possess decent competency in structuring biomedical text, by distillation into a task-specific student model through self-supervised learning, substantial gains can be attained over out-of-box LLMs, with additional advantages such as cost, efficiency, and white-box model access. We conduct a case study on adverse drug event (ADE) extraction, which is an important area for improving care. On standard ADE extraction evaluation, a GPT-3.5 distilled PubMedBERT model attained comparable accuracy as supervised state-of-the-art models without using any labeled data. Despite being over 1,000 times smaller, the distilled model outperformed its teacher GPT-3.5 by over 6 absolute points in F1 and GPT-4 by over 5 absolute points. Ablation studies on distillation model choice (e.g., PubMedBERT vs BioGPT) and ADE extraction architecture shed light on best practice for biomedical knowledge extraction. Similar gains were attained by distillation for other standard biomedical knowledge extraction tasks such as gene-disease associations and protected health information, further illustrating the promise of this approach.
LLaVA-Med: Training a Large Language-and-Vision Assistant for Biomedicine in One Day
Jun 01, 2023Conversational generative AI has demonstrated remarkable promise for empowering biomedical practitioners, but current investigations focus on unimodal text. Multimodal conversational AI has seen rapid progress by leveraging billions of image-text pairs from the public web, but such general-domain vision-language models still lack sophistication in understanding and conversing about biomedical images. In this paper, we propose a cost-efficient approach for training a vision-language conversational assistant that can answer open-ended research questions of biomedical images. The key idea is to leverage a large-scale, broad-coverage biomedical figure-caption dataset extracted from PubMed Central, use GPT-4 to self-instruct open-ended instruction-following data from the captions, and then fine-tune a large general-domain vision-language model using a novel curriculum learning method. Specifically, the model first learns to align biomedical vocabulary using the figure-caption pairs as is, then learns to master open-ended conversational semantics using GPT-4 generated instruction-following data, broadly mimicking how a layperson gradually acquires biomedical knowledge. This enables us to train a Large Language and Vision Assistant for BioMedicine (LLaVA-Med) in less than 15 hours (with eight A100s). LLaVA-Med exhibits excellent multimodal conversational capability and can follow open-ended instruction to assist with inquiries about a biomedical image. On three standard biomedical visual question answering datasets, LLaVA-Med outperforms previous supervised state-of-the-art on certain metrics. To facilitate biomedical multimodal research, we will release our instruction-following data and the LLaVA-Med model.
Compositional Zero-Shot Domain Transfer with Text-to-Text Models
Mar 23, 2023Label scarcity is a bottleneck for improving task performance in specialised domains. We propose a novel compositional transfer learning framework (DoT5 - domain compositional zero-shot T5) for zero-shot domain transfer. Without access to in-domain labels, DoT5 jointly learns domain knowledge (from MLM of unlabelled in-domain free text) and task knowledge (from task training on more readily available general-domain data) in a multi-task manner. To improve the transferability of task training, we design a strategy named NLGU: we simultaneously train NLG for in-domain label-to-data generation which enables data augmentation for self-finetuning and NLU for label prediction. We evaluate DoT5 on the biomedical domain and the resource-lean subdomain of radiology, focusing on NLI, text summarisation and embedding learning. DoT5 demonstrates the effectiveness of compositional transfer learning through multi-task learning. In particular, DoT5 outperforms the current SOTA in zero-shot transfer by over 7 absolute points in accuracy on RadNLI. We validate DoT5 with ablations and a case study demonstrating its ability to solve challenging NLI examples requiring in-domain expertise.
Large-Scale Domain-Specific Pretraining for Biomedical Vision-Language Processing
Mar 02, 2023Contrastive pretraining on parallel image-text data has attained great success in vision-language processing (VLP), as exemplified by CLIP and related methods. However, prior explorations tend to focus on general domains in the web. Biomedical images and text are rather different, but publicly available datasets are small and skew toward chest X-ray, thus severely limiting progress. In this paper, we conducted by far the largest study on biomedical VLP, using 15 million figure-caption pairs extracted from biomedical research articles in PubMed Central. Our dataset (PMC-15M) is two orders of magnitude larger than existing biomedical image-text datasets such as MIMIC-CXR, and spans a diverse range of biomedical images. The standard CLIP method is suboptimal for the biomedical domain. We propose BiomedCLIP with domain-specific adaptations tailored to biomedical VLP. We conducted extensive experiments and ablation studies on standard biomedical imaging tasks from retrieval to classification to visual question-answering (VQA). BiomedCLIP established new state of the art in a wide range of standard datasets, substantially outperformed prior VLP approaches. Surprisingly, BiomedCLIP even outperformed radiology-specific state-of-the-art models such as BioViL on radiology-specific tasks such as RSNA pneumonia detection, thus highlighting the utility in large-scale pretraining across all biomedical image types. We will release our models at https://aka.ms/biomedclip to facilitate future research in biomedical VLP.
Making the Most of Text Semantics to Improve Biomedical Vision--Language Processing
Apr 21, 2022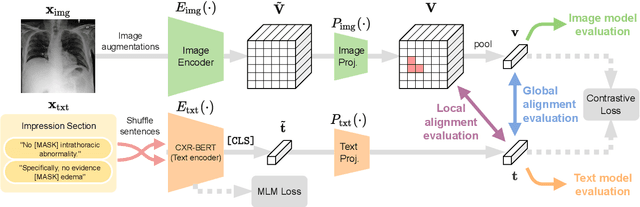

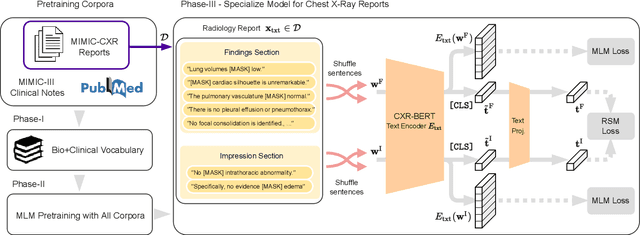

Multi-modal data abounds in biomedicine, such as radiology images and reports. Interpreting this data at scale is essential for improving clinical care and accelerating clinical research. Biomedical text with its complex semantics poses additional challenges in vision-language modelling compared to the general domain, and previous work has used insufficiently adapted models that lack domain-specific language understanding. In this paper, we show that principled textual semantic modelling can substantially improve contrastive learning in self-supervised vision--language processing. We release a language model that achieves state-of-the-art results in radiology natural language inference through its improved vocabulary and novel language pretraining objective leveraging semantics and discourse characteristics in radiology reports. Further, we propose a self-supervised joint vision--language approach with a focus on better text modelling. It establishes new state of the art results on a wide range of publicly available benchmarks, in part by leveraging our new domain-specific language model. We release a new dataset with locally-aligned phrase grounding annotations by radiologists to facilitate the study of complex semantic modelling in biomedical vision--language processing. A broad evaluation, including on this new dataset, shows that our contrastive learning approach, aided by textual-semantic modelling, outperforms prior methods in segmentation tasks, despite only using a global-alignment objective.
Towards Structuring Real-World Data at Scale: Deep Learning for Extracting Key Oncology Information from Clinical Text with Patient-Level Supervision
Mar 20, 2022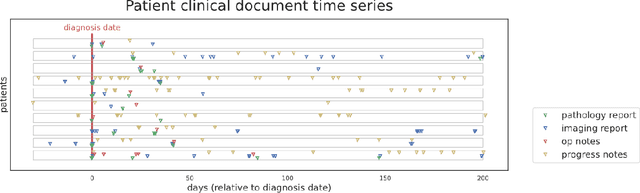
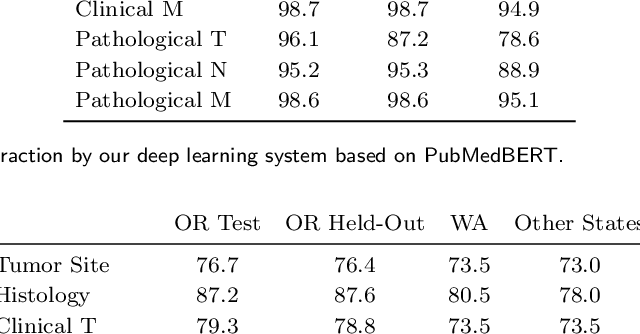
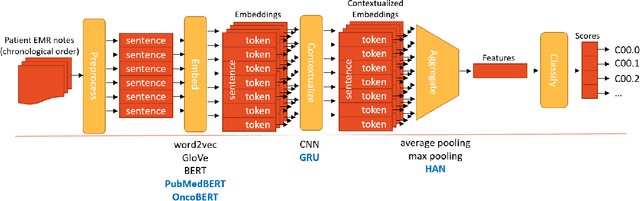
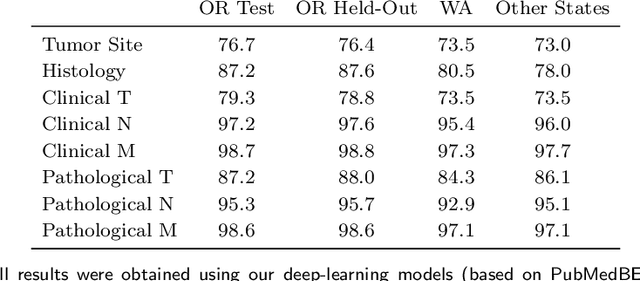
Objective: The majority of detailed patient information in real-world data (RWD) is only consistently available in free-text clinical documents. Manual curation is expensive and time-consuming. Developing natural language processing (NLP) methods for structuring RWD is thus essential for scaling real-world evidence generation. Materials and Methods: Traditional rule-based systems are vulnerable to the prevalent linguistic variations and ambiguities in clinical text, and prior applications of machine-learning methods typically require sentence-level or report-level labeled examples that are hard to produce at scale. We propose leveraging patient-level supervision from medical registries, which are often readily available and capture key patient information, for general RWD applications. To combat the lack of sentence-level or report-level annotations, we explore advanced deep-learning methods by combining domain-specific pretraining, recurrent neural networks, and hierarchical attention. Results: We conduct an extensive study on 135,107 patients from the cancer registry of a large integrated delivery network (IDN) comprising healthcare systems in five western US states. Our deep learning methods attain test AUROC of 94-99% for key tumor attributes and comparable performance on held-out data from separate health systems and states. Discussion and Conclusion: Ablation results demonstrate clear superiority of these advanced deep-learning methods over prior approaches. Error analysis shows that our NLP system sometimes even corrects errors in registrar labels. We also conduct a preliminary investigation in accelerating registry curation and general RWD structuring via assisted curation for over 1.2 million cancer patients in this healthcare network.
Fine-Tuning Large Neural Language Models for Biomedical Natural Language Processing
Dec 15, 2021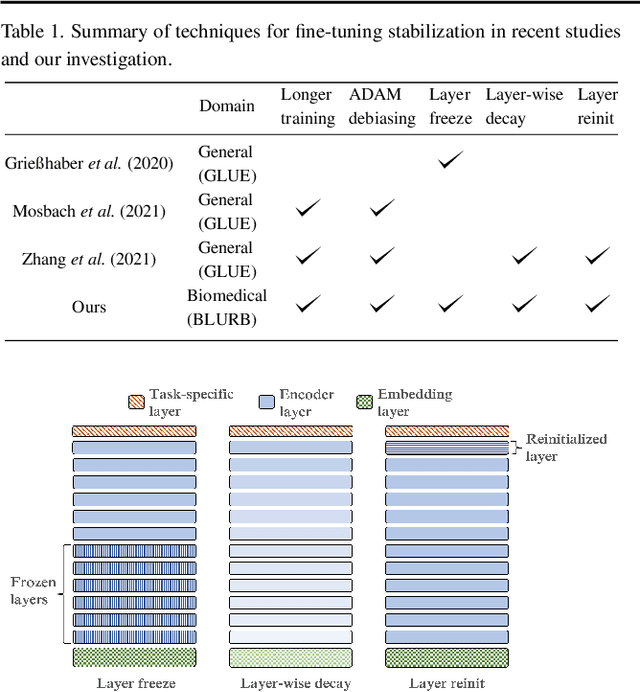
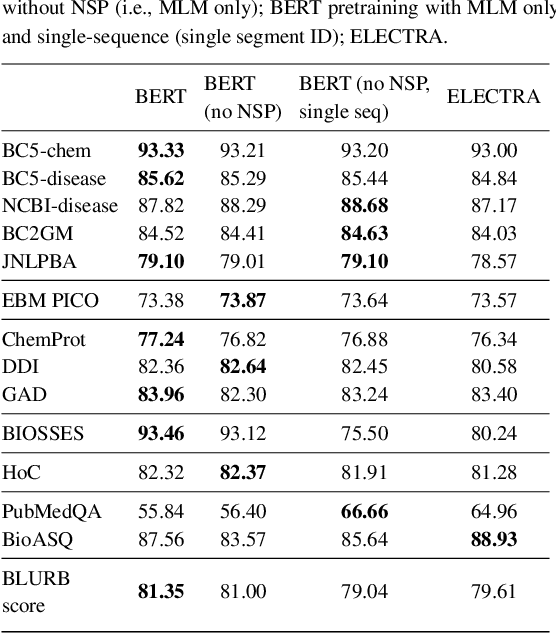
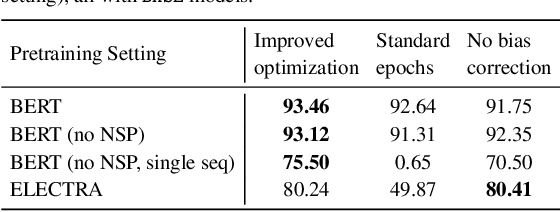
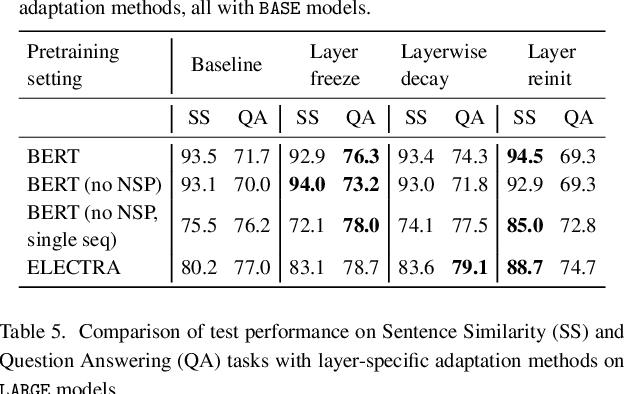
Motivation: A perennial challenge for biomedical researchers and clinical practitioners is to stay abreast with the rapid growth of publications and medical notes. Natural language processing (NLP) has emerged as a promising direction for taming information overload. In particular, large neural language models facilitate transfer learning by pretraining on unlabeled text, as exemplified by the successes of BERT models in various NLP applications. However, fine-tuning such models for an end task remains challenging, especially with small labeled datasets, which are common in biomedical NLP. Results: We conduct a systematic study on fine-tuning stability in biomedical NLP. We show that finetuning performance may be sensitive to pretraining settings, especially in low-resource domains. Large models have potential to attain better performance, but increasing model size also exacerbates finetuning instability. We thus conduct a comprehensive exploration of techniques for addressing fine-tuning instability. We show that these techniques can substantially improve fine-tuning performance for lowresource biomedical NLP applications. Specifically, freezing lower layers is helpful for standard BERT-BASE models, while layerwise decay is more effective for BERT-LARGE and ELECTRA models. For low-resource text similarity tasks such as BIOSSES, reinitializing the top layer is the optimal strategy. Overall, domainspecific vocabulary and pretraining facilitate more robust models for fine-tuning. Based on these findings, we establish new state of the art on a wide range of biomedical NLP applications. Availability and implementation: To facilitate progress in biomedical NLP, we release our state-of-the-art pretrained and fine-tuned models: https://aka.ms/BLURB.
Modular Self-Supervision for Document-Level Relation Extraction
Sep 11, 2021
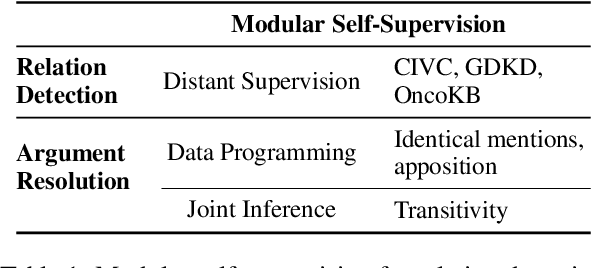
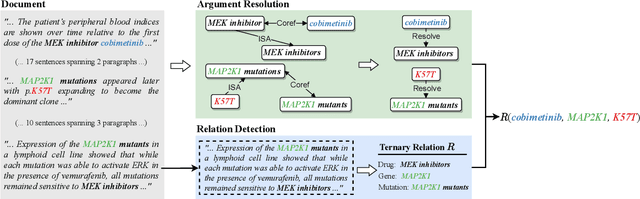
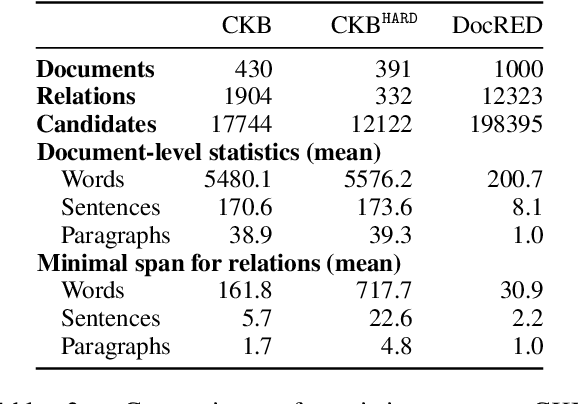
Extracting relations across large text spans has been relatively underexplored in NLP, but it is particularly important for high-value domains such as biomedicine, where obtaining high recall of the latest findings is crucial for practical applications. Compared to conventional information extraction confined to short text spans, document-level relation extraction faces additional challenges in both inference and learning. Given longer text spans, state-of-the-art neural architectures are less effective and task-specific self-supervision such as distant supervision becomes very noisy. In this paper, we propose decomposing document-level relation extraction into relation detection and argument resolution, taking inspiration from Davidsonian semantics. This enables us to incorporate explicit discourse modeling and leverage modular self-supervision for each sub-problem, which is less noise-prone and can be further refined end-to-end via variational EM. We conduct a thorough evaluation in biomedical machine reading for precision oncology, where cross-paragraph relation mentions are prevalent. Our method outperforms prior state of the art, such as multi-scale learning and graph neural networks, by over 20 absolute F1 points. The gain is particularly pronounced among the most challenging relation instances whose arguments never co-occur in a paragraph.