 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOGENT: A Curriculum-oriented Framework for Generating Grade-appropriate Educational Content
Jun 11, 2025While Generative AI has demonstrated strong potential and versatility in content generation, its application to educational contexts presents several challenges. Models often fail to align with curriculum standards and maintain grade-appropriate reading levels consistently. Furthermore, STEM education poses additional challenges in balancing scientific explanations with everyday language when introducing complex and abstract ideas and phenomena to younger students. In this work, we propose COGENT, a curriculum-oriented framework for generating grade-appropriate educational content. We incorporate three curriculum components (science concepts, core ideas, and learning objectives), control readability through length, vocabulary, and sentence complexity, and adopt a ``wonder-based'' approach to increase student engagement and interest. We conduct a multi-dimensional evaluation via both LLM-as-a-judge and human expert analysis. Experimental results show that COGENT consistently produces grade-appropriate passages that are comparable or superior to human references. Our work establishes a viable approach for scaling adaptive and high-quality learning resources.
Beyond Classification: Towards Speech Emotion Reasoning with Multitask AudioLLMs
Jun 07, 2025Audio Large Language Models (AudioLLMs) have achieved strong results in semantic tasks like speech recognition and translation, but remain limited in modeling paralinguistic cues such as emotion. Existing approaches often treat emotion understanding as a classification problem, offering little insight into the underlying rationale behind predictions. In this work, we explore emotion reasoning, a strategy that leverages the generative capabilities of AudioLLMs to enhance emotion recognition by producing semantically aligned, evidence-grounded explanations. To support this in multitask AudioLLMs, we introduce a unified framework combining reasoning-augmented data supervision, dual-encoder architecture, and task-alternating training. This approach enables AudioLLMs to effectively learn different tasks while incorporating emotional reasoning. Experiments on IEMOCAP and MELD show that our approach not only improves emotion prediction accuracy but also enhances the coherence and evidential grounding of the generated responses.
What Makes a Good Natural Language Prompt?
Jun 07, 2025



As large language models (LLMs) have progressed towards more human-like and human--AI communications have become prevalent, prompting has emerged as a decisive component. However, there is limited conceptual consensus on what exactly quantifies natural language prompts. We attempt to address this question by conducting a meta-analysis surveying more than 150 prompting-related papers from leading NLP and AI conferences from 2022 to 2025 and blogs. We propose a property- and human-centric framework for evaluating prompt quality, encompassing 21 properties categorized into six dimensions. We then examine how existing studies assess their impact on LLMs, revealing their imbalanced support across models and tasks, and substantial research gaps. Further, we analyze correlations among properties in high-quality natural language prompts, deriving prompting recommendations. We then empirically explore multi-property prompt enhancements in reasoning tasks, observing that single-property enhancements often have the greatest impact. Finally, we discover that instruction-tuning on property-enhanced prompts can result in better reasoning models. Our findings establish a foundation for property-centric prompt evaluation and optimization, bridging the gaps between human--AI communication and opening new prompting research directions.
Towards Spoken Mathematical Reasoning: Benchmarking Speech-based Models over Multi-faceted Math Problems
May 21, 2025Recent advances in large language models (LLMs) and multimodal LLMs (MLLMs) have led to strong reasoning ability across a wide range of tasks. However, their ability to perform mathematical reasoning from spoken input remains underexplored. Prior studies on speech modality have mostly focused on factual speech understanding or simple audio reasoning tasks, providing limited insight into logical step-by-step reasoning, such as that required for mathematical problem solving. To address this gap, we introduce Spoken Math Question Answering (Spoken-MQA), a new benchmark designed to evaluate the mathematical reasoning capabilities of speech-based models, including both cascade models (ASR + LLMs) and end-to-end speech LLMs. Spoken-MQA covers a diverse set of math problems, including pure arithmetic, single-step and multi-step contextual reasoning, and knowledge-oriented reasoning problems, all presented in unambiguous natural spoken language. Through extensive experiments, we find that: (1) while some speech LLMs perform competitively on contextual reasoning tasks involving basic arithmetic, they still struggle with direct arithmetic problems; (2) current LLMs exhibit a strong bias toward symbolic mathematical expressions written in LaTex and have difficulty interpreting verbalized mathematical expressions; and (3) mathematical knowledge reasoning abilities are significantly degraded in current speech LLMs.
Distilling a speech and music encoder with task arithmetic
May 19, 2025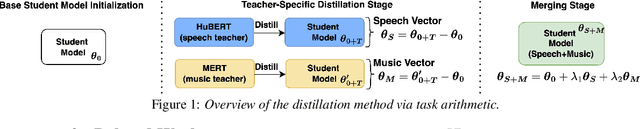
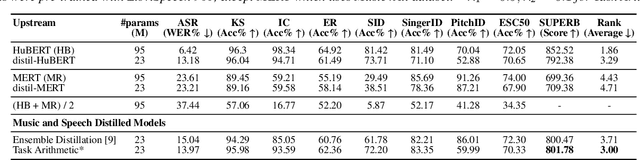
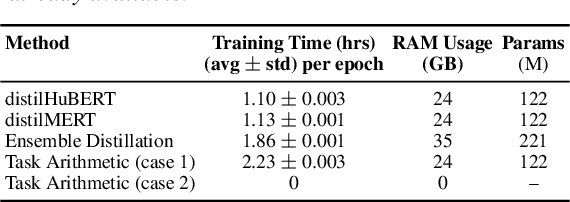
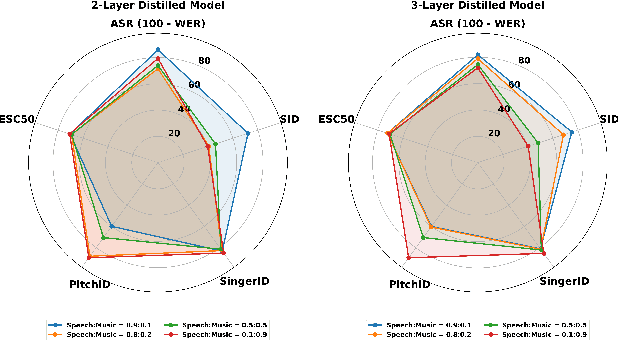
Despite the progress in self-supervised learning (SSL) for speech and music, existing models treat these domains separately, limiting their capacity for unified audio understanding. A unified model is desirable for applications that require general representations, e.g. audio large language models. Nonetheless, directly training a general model for speech and music is computationally expensive. Knowledge Distillation of teacher ensembles may be a natural solution, but we posit that decoupling the distillation of the speech and music SSL models allows for more flexibility. Thus, we propose to learn distilled task vectors and then linearly interpolate them to form a unified speech+music model. This strategy enables flexible domain emphasis through adjustable weights and is also simpler to train. Experiments on speech and music benchmarks demonstrate that our method yields superior overall performance compared to ensemble distillation.
Integrating Video and Text: A Balanced Approach to Multimodal Summary Generation and Evaluation
May 10, 2025Vision-Language Models (VLMs) often struggle to balance visual and textual information when summarizing complex multimodal inputs, such as entire TV show episodes. In this paper, we propose a zero-shot video-to-text summarization approach that builds its own screenplay representation of an episode, effectively integrating key video moments, dialogue, and character information into a unified document. Unlike previous approaches, we simultaneously generate screenplays and name the characters in zero-shot, using only the audio, video, and transcripts as input. Additionally, we highlight that existing summarization metrics can fail to assess the multimodal content in summaries. To address this, we introduce MFactSum, a multimodal metric that evaluates summaries with respect to both vision and text modalities. Using MFactSum, we evaluate our screenplay summaries on the SummScreen3D dataset, demonstrating superiority against state-of-the-art VLMs such as Gemini 1.5 by generating summaries containing 20% more relevant visual information while requiring 75% less of the video as input.
Reinforcing Compositional Retrieval: Retrieving Step-by-Step for Composing Informative Contexts
Apr 15, 2025



Large Language Models (LLMs) have demonstrated remarkable capabilities across numerous tasks, yet they often rely on external context to handle complex tasks. While retrieval-augmented frameworks traditionally focus on selecting top-ranked documents in a single pass, many real-world scenarios demand compositional retrieval, where multiple sources must be combined in a coordinated manner. In this work, we propose a tri-encoder sequential retriever that models this process as a Markov Decision Process (MDP), decomposing the probability of retrieving a set of elements into a sequence of conditional probabilities and allowing each retrieval step to be conditioned on previously selected examples. We train the retriever in two stages: first, we efficiently construct supervised sequential data for initial policy training; we then refine the policy to align with the LLM's preferences using a reward grounded in the structural correspondence of generated programs. Experimental results show that our method consistently and significantly outperforms baselines, underscoring the importance of explicitly modeling inter-example dependencies. These findings highlight the potential of compositional retrieval for tasks requiring multiple pieces of evidence or examples.
Advancing Singlish Understanding: Bridging the Gap with Datasets and Multimodal Models
Jan 02, 2025



Singlish, a Creole language rooted in English, is a key focus in linguistic research within multilingual and multicultural contexts. However, its spoken form remains underexplored, limiting insights into its linguistic structure and applications. To address this gap, we standardize and annotate the largest spoken Singlish corpus, introducing the Multitask National Speech Corpus (MNSC). These datasets support diverse tasks, including Automatic Speech Recognition (ASR), Spoken Question Answering (SQA), Spoken Dialogue Summarization (SDS), and Paralinguistic Question Answering (PQA). We release standardized splits and a human-verified test set to facilitate further research. Additionally, we propose SingAudioLLM, a multi-task multimodal model leveraging multimodal large language models to handle these tasks concurrently. Experiments reveal our models adaptability to Singlish context, achieving state-of-the-art performance and outperforming prior models by 10-30% in comparison with other AudioLLMs and cascaded solutions.
MERaLiON-SpeechEncoder: Towards a Speech Foundation Model for Singapore and Beyond
Dec 20, 2024



This technical report describes the MERaLiON-SpeechEncoder, a foundation model designed to support a wide range of downstream speech applications. Developed as part of Singapore's National Multimodal Large Language Model Programme, the MERaLiON-SpeechEncoder is tailored to address the speech processing needs in Singapore and the surrounding Southeast Asian region. The model currently supports mainly English, including the variety spoken in Singapore. We are actively expanding our datasets to gradually cover other languages in subsequent releases. The MERaLiON-SpeechEncoder was pre-trained from scratch on 200,000 hours of unlabelled speech data using a self-supervised learning approach based on masked language modelling. We describe our training procedure and hyperparameter tuning experiments in detail below. Our evaluation demonstrates improvements to spontaneous and Singapore speech benchmarks for speech recognition, while remaining competitive to other state-of-the-art speech encoders across ten other speech tasks. We commit to releasing our model, supporting broader research endeavours, both in Singapore and beyond.
MERaLiON-AudioLLM: Bridging Audio and Language with Large Language Models
Dec 18, 2024

We introduce MERaLiON-AudioLLM (Multimodal Empathetic Reasoning and Learning in One Network), the first speech-text model tailored for Singapore's multilingual and multicultural landscape. Developed under the National Large Language Models Funding Initiative, Singapore, MERaLiON-AudioLLM integrates advanced speech and text processing to address the diverse linguistic nuances of local accents and dialects, enhancing accessibility and usability in complex, multilingual environments. Our results demonstrate improvements in both speech recognition and task-specific understanding, positioning MERaLiON-AudioLLM as a pioneering solution for region specific AI applications. We envision this release to set a precedent for future models designed to address localised linguistic and cultural contexts in a global framework.