 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Classification: Towards Speech Emotion Reasoning with Multitask AudioLLMs
Jun 07, 2025Audio Large Language Models (AudioLLMs) have achieved strong results in semantic tasks like speech recognition and translation, but remain limited in modeling paralinguistic cues such as emotion. Existing approaches often treat emotion understanding as a classification problem, offering little insight into the underlying rationale behind predictions. In this work, we explore emotion reasoning, a strategy that leverages the generative capabilities of AudioLLMs to enhance emotion recognition by producing semantically aligned, evidence-grounded explanations. To support this in multitask AudioLLMs, we introduce a unified framework combining reasoning-augmented data supervision, dual-encoder architecture, and task-alternating training. This approach enables AudioLLMs to effectively learn different tasks while incorporating emotional reasoning. Experiments on IEMOCAP and MELD show that our approach not only improves emotion prediction accuracy but also enhances the coherence and evidential grounding of the generated responses.
MERaLiON-SpeechEncoder: Towards a Speech Foundation Model for Singapore and Beyond
Dec 20, 2024



This technical report describes the MERaLiON-SpeechEncoder, a foundation model designed to support a wide range of downstream speech applications. Developed as part of Singapore's National Multimodal Large Language Model Programme, the MERaLiON-SpeechEncoder is tailored to address the speech processing needs in Singapore and the surrounding Southeast Asian region. The model currently supports mainly English, including the variety spoken in Singapore. We are actively expanding our datasets to gradually cover other languages in subsequent releases. The MERaLiON-SpeechEncoder was pre-trained from scratch on 200,000 hours of unlabelled speech data using a self-supervised learning approach based on masked language modelling. We describe our training procedure and hyperparameter tuning experiments in detail below. Our evaluation demonstrates improvements to spontaneous and Singapore speech benchmarks for speech recognition, while remaining competitive to other state-of-the-art speech encoders across ten other speech tasks. We commit to releasing our model, supporting broader research endeavours, both in Singapore and beyond.
Semi-supervised Learning For Robust Speech Evaluation
Sep 23, 2024


Speech evaluation measures a learners oral proficiency using automatic models. Corpora for training such models often pose sparsity challenges given that there often is limited scored data from teachers, in addition to the score distribution across proficiency levels being often imbalanced among student cohorts. Automatic scoring is thus not robust when faced with under-represented samples or out-of-distribution samples, which inevitably exist in real-world deployment scenarios. This paper proposes to address such challenges by exploiting semi-supervised pre-training and objective regularization to approximate subjective evaluation criteria. In particular, normalized mutual information is used to quantify the speech characteristics from the learner and the reference. An anchor model is trained using pseudo labels to predict the correctness of pronunciation. An interpolated loss function is proposed to minimize not only the prediction error with respect to ground-truth scores but also the divergence between two probability distributions estimated by the speech evaluation model and the anchor model. Compared to other state-of-the-art methods on a public data-set, this approach not only achieves high performance while evaluating the entire test-set as a whole, but also brings the most evenly distributed prediction error across distinct proficiency levels. Furthermore, empirical results show the model accuracy on out-of-distribution data also compares favorably with competitive baselines.
MoWE-Audio: Multitask AudioLLMs with Mixture of Weak Encoders
Sep 10, 2024



The rapid advancements in large language models (LLMs) have significantly enhanced natural language processing capabilities, facilitating the development of AudioLLMs that process and understand speech and audio inputs alongside text. Existing AudioLLMs typically combine a pre-trained audio encoder with a pre-trained LLM, which are subsequently finetuned on specific audio tasks. However, the pre-trained audio encoder has constrained capacity to capture features for new tasks and datasets. To address this, we propose to incorporate mixtures of `weak' encoders (MoWE) into the AudioLLM framework. MoWE supplements a base encoder with a pool of relatively light weight encoders, selectively activated based on the audio input to enhance feature extraction without significantly increasing model size. Our empirical results demonstrate that MoWE effectively improves multi-task performance, broadening the applicability of AudioLLMs to more diverse audio tasks.
AudioBench: A Universal Benchmark for Audio Large Language Models
Jun 25, 2024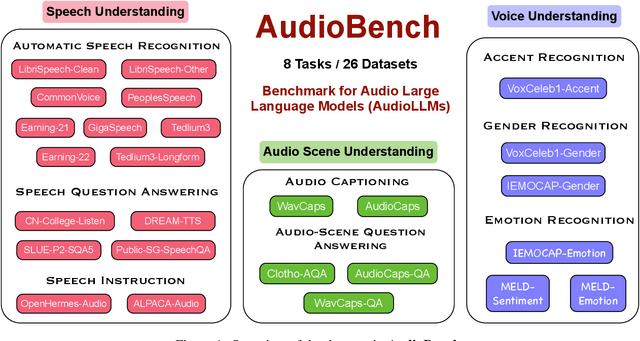

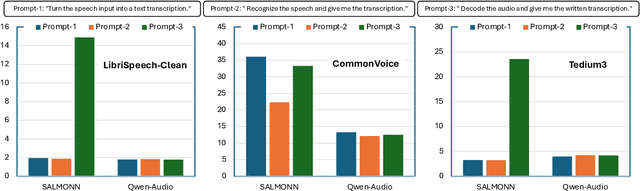

We introduce AudioBench, a new benchmark designed to evaluate audio large language models (AudioLLMs). AudioBench encompasses 8 distinct tasks and 26 carefully selected or newly curated datasets, focusing on speech understanding, voice interpretation, and audio scene understanding. Despite the rapid advancement of large language models, including multimodal versions, a significant gap exists in comprehensive benchmarks for thoroughly evaluating their capabilities. AudioBench addresses this gap by providing relevant datasets and evaluation metrics. In our study, we evaluated the capabilities of four models across various aspects and found that no single model excels consistently across all tasks. We outline the research outlook for AudioLLMs and anticipate that our open-source code, data, and leaderboard will offer a robust testbed for future model developments.
CRAFT: Extracting and Tuning Cultural Instructions from the Wild
May 06, 2024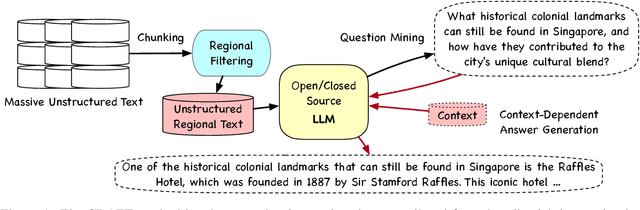


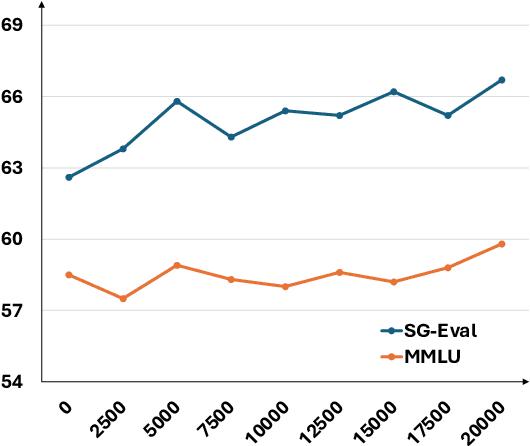
Large language models (LLMs) have rapidly evolved as the foundation of various natural language processing (NLP) applications. Despite their wide use cases, their understanding of culturally-related concepts and reasoning remains limited. Meantime, there is a significant need to enhance these models' cultural reasoning capabilities, especially concerning underrepresented regions. This paper introduces a novel pipeline for extracting high-quality, culturally-related instruction tuning datasets from vast unstructured corpora. We utilize a self-instruction generation pipeline to identify cultural concepts and trigger instruction. By integrating with a general-purpose instruction tuning dataset, our model demonstrates enhanced capabilities in recognizing and understanding regional cultural nuances, thereby enhancing its reasoning capabilities. We conduct experiments across three regions: Singapore, the Philippines, and the United States, achieving performance improvement of up to 6%. Our research opens new avenues for extracting cultural instruction tuning sets directly from unstructured data, setting a precedent for future innovations in the field.
CrossIn: An Efficient Instruction Tuning Approach for Cross-Lingual Knowledge Alignment
Apr 18, 2024



Multilingual proficiency presents a significant challenge for large language models (LLMs). English-centric models are usually suboptimal in other languages, particularly those that are linguistically distant from English. This performance discrepancy mainly stems from the imbalanced distribution of training data across languages during pre-training and instruction tuning stages. To address this problem, we propose a novel approach called CrossIn, which utilizes a mixed composition of cross-lingual instruction tuning data. Our method leverages the compressed representation shared by various languages to efficiently enhance the model's task-solving capabilities and multilingual proficiency within a single process. In addition, we introduce a multi-task and multi-faceted benchmark to evaluate the effectiveness of CrossIn. Experimental results demonstrate that our method substantially improves performance across tasks and languages, and we provide extensive insights into the impact of cross-lingual data volume and the integration of translation data on enhancing multilingual consistency and accuracy.
Resilience of Large Language Models for Noisy Instructions
Apr 15, 2024



As the rapidly advancing domain of natural language processing (NLP), large language models (LLMs) have emerged as powerful tools for interpreting human commands and generating text across various tasks. Nonetheless, the resilience of LLMs to handle text containing inherent errors, stemming from human interactions and collaborative systems, has not been thoroughly explored. Our study investigates the resilience of LLMs against five common types of disruptions including 1) ASR (Automatic Speech Recognition) errors, 2) OCR (Optical Character Recognition) errors, 3) grammatical mistakes, 4) typographical errors, and 5) distractive content. We aim to investigate how these models react by deliberately embedding these errors into instructions. Our findings reveal that while some LLMs show a degree of resistance to certain types of noise, their overall performance significantly suffers. This emphasizes the importance of further investigation into enhancing model resilience. In response to the observed decline in performance, our study also evaluates a "re-pass" strategy, designed to purify the instructions of noise before the LLMs process them. Our analysis indicates that correcting noisy instructions, particularly for open-source LLMs, presents significant challenges.
Personality-aware Student Simulation for Conversational Intelligent Tutoring Systems
Apr 10, 2024



Intelligent Tutoring Systems (ITSs) can provide personalized and self-paced learning experience. The emergence of large language models (LLMs) further enables better human-machine interaction, and facilitates the development of conversational ITSs in various disciplines such as math and language learning. In dialogic teaching, recognizing and adapting to individual characteristics can significantly enhance student engagement and learning efficiency. However, characterizing and simulating student's persona remain challenging in training and evaluating conversational ITSs. In this work, we propose a framework to construct profiles of different student groups by refining and integrating both cognitive and noncognitive aspects, and leverage LLMs for personality-aware student simulation in a language learning scenario. We further enhance the framework with multi-aspect validation, and conduct extensive analysis from both teacher and student perspectives. Our experimental results show that state-of-the-art LLMs can produce diverse student responses according to the given language ability and personality traits, and trigger teacher's adaptive scaffolding strategies.