 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiAiTutor: Child-Friendly Educational Multilingual Speech Generation Tutor with LLMs
Aug 12, 2025Generative speech models have demonstrated significant potential in personalizing teacher-student interactions, offering valuable real-world applications for language learning in children's education. However, achieving high-quality, child-friendly speech generation remains challenging, particularly for low-resource languages across diverse languages and cultural contexts. In this paper, we propose MultiAiTutor, an educational multilingual generative AI tutor with child-friendly designs, leveraging LLM architecture for speech generation tailored for educational purposes. We propose to integrate age-appropriate multilingual speech generation using LLM architectures, facilitating young children's language learning through culturally relevant image-description tasks in three low-resource languages: Singaporean-accent Mandarin, Malay, and Tamil. Experimental results from both objective metrics and subjective evaluations demonstrate the superior performance of the proposed MultiAiTutor compared to baseline methods.
Semi-supervised Learning For Robust Speech Evaluation
Sep 23, 2024


Speech evaluation measures a learners oral proficiency using automatic models. Corpora for training such models often pose sparsity challenges given that there often is limited scored data from teachers, in addition to the score distribution across proficiency levels being often imbalanced among student cohorts. Automatic scoring is thus not robust when faced with under-represented samples or out-of-distribution samples, which inevitably exist in real-world deployment scenarios. This paper proposes to address such challenges by exploiting semi-supervised pre-training and objective regularization to approximate subjective evaluation criteria. In particular, normalized mutual information is used to quantify the speech characteristics from the learner and the reference. An anchor model is trained using pseudo labels to predict the correctness of pronunciation. An interpolated loss function is proposed to minimize not only the prediction error with respect to ground-truth scores but also the divergence between two probability distributions estimated by the speech evaluation model and the anchor model. Compared to other state-of-the-art methods on a public data-set, this approach not only achieves high performance while evaluating the entire test-set as a whole, but also brings the most evenly distributed prediction error across distinct proficiency levels. Furthermore, empirical results show the model accuracy on out-of-distribution data also compares favorably with competitive baselines.
Emo-DPO: Controllable Emotional Speech Synthesis through Direct Preference Optimization
Sep 16, 2024



Current emotional text-to-speech (TTS) models predominantly conduct supervised training to learn the conversion from text and desired emotion to its emotional speech, focusing on a single emotion per text-speech pair. These models only learn the correct emotional outputs without fully comprehending other emotion characteristics, which limits their capabilities of capturing the nuances between different emotions. We propose a controllable Emo-DPO approach, which employs direct preference optimization to differentiate subtle emotional nuances between emotions through optimizing towards preferred emotions over less preferred emotional ones. Instead of relying on traditional neural architectures used in existing emotional TTS models, we propose utilizing the emotion-aware LLM-TTS neural architecture to leverage LLMs' in-context learning and instruction-following capabilities. Comprehensive experiments confirm that our proposed method outperforms the existing baselines.
PRESENT: Zero-Shot Text-to-Prosody Control
Aug 13, 2024Current strategies for achieving fine-grained prosody control in speech synthesis entail extracting additional style embeddings or adopting more complex architectures. To enable zero-shot application of pretrained text-to-speech (TTS) models, we present PRESENT (PRosody Editing without Style Embeddings or New Training), which exploits explicit prosody prediction in FastSpeech2-based models by modifying the inference process directly. We apply our text-to-prosody framework to zero-shot language transfer using a JETS model exclusively trained on English LJSpeech data. We obtain character error rates (CER) of 12.8%, 18.7% and 5.9% for German, Hungarian and Spanish respectively, beating the previous state-of-the-art CER by over 2x for all three languages. Furthermore, we allow subphoneme-level control, a first in this field. To evaluate its effectiveness, we show that PRESENT can improve the prosody of questions, and use it to generate Mandarin, a tonal language where vowel pitch varies at subphoneme level. We attain 25.3% hanzi CER and 13.0% pinyin CER with the JETS model. All our code and audio samples are available online.
Multiple output samples for each input in a single-output Gaussian process
Jun 05, 2023
The standard Gaussian Process (GP) only considers a single output sample per input in the training set. Datasets for subjective tasks, such as spoken language assessment, may be annotated with output labels from multiple human raters per input. This paper proposes to generalise the GP to allow for these multiple output samples in the training set, and thus make use of available output uncertainty information. This differs from a multi-output GP, as all output samples are from the same task here. The output density function is formulated to be the joint likelihood of observing all output samples, and latent variables are not repeated to reduce computation cost. The test set predictions are inferred similarly to a standard GP, with a difference being in the optimised hyper-parameters. This is evaluated on speechocean762, showing that it allows the GP to compute a test set output distribution that is more similar to the collection of reference outputs from the multiple human raters.
SNIPER Training: Variable Sparsity Rate Training For Text-To-Speech
Nov 14, 2022



Text-to-speech (TTS) models have achieved remarkable naturalness in recent years, yet like most deep neural models, they have more parameters than necessary. Sparse TTS models can improve on dense models via pruning and extra retraining, or converge faster than dense models with some performance loss. Inspired by these results, we propose training TTS models using a decaying sparsity rate, i.e. a high initial sparsity to accelerate training first, followed by a progressive rate reduction to obtain better eventual performance. This decremental approach differs from current methods of incrementing sparsity to a desired target, which costs significantly more time than dense training. We call our method SNIPER training: Single-shot Initialization Pruning Evolving-Rate training. Our experiments on FastSpeech2 show that although we were only able to obtain better losses in the first few epochs before being overtaken by the baseline, the final SNIPER-trained models beat constant-sparsity models and pip dense models in performance.
EPIC TTS Models: Empirical Pruning Investigations Characterizing Text-To-Speech Models
Sep 22, 2022
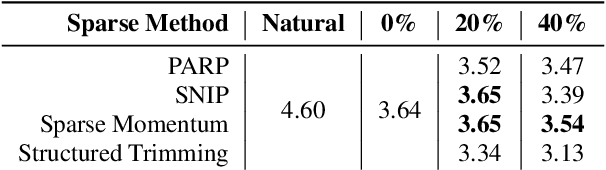
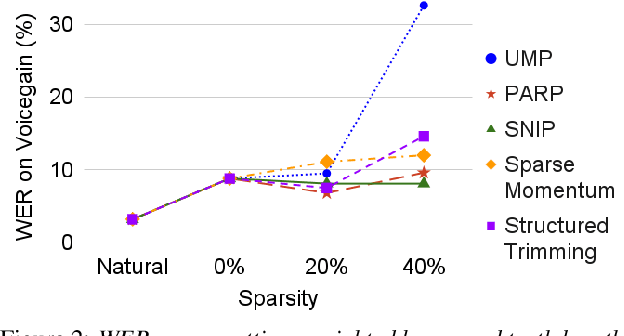
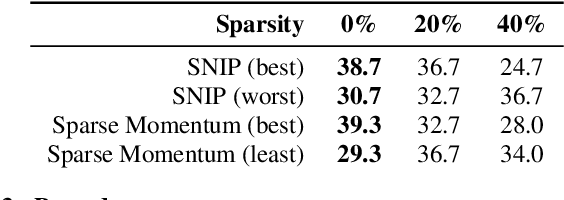
Neural models are known to be over-parameterized, and recent work has shown that sparse text-to-speech (TTS) models can outperform dense models. Although a plethora of sparse methods has been proposed for other domains, such methods have rarely been applied in TTS. In this work, we seek to answer the question: what are the characteristics of selected sparse techniques on the performance and model complexity? We compare a Tacotron2 baseline and the results of applying five techniques. We then evaluate the performance via the factors of naturalness, intelligibility and prosody, while reporting model size and training time. Complementary to prior research, we find that pruning before or during training can achieve similar performance to pruning after training and can be trained much faster, while removing entire neurons degrades performance much more than removing parameters. To our best knowledge, this is the first work that compares sparsity paradigms in text-to-speech synthesis.
Multilingual Speech Evaluation: Case Studies on English, Malay and Tamil
Jul 08, 2021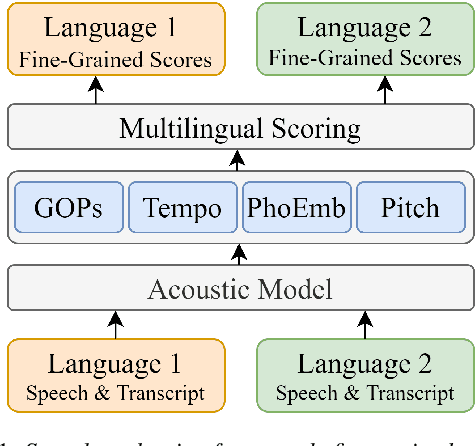
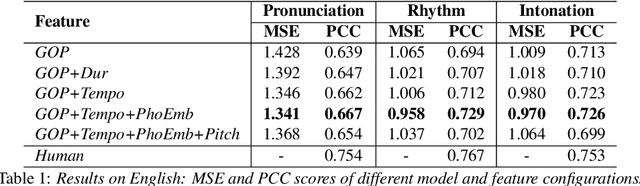
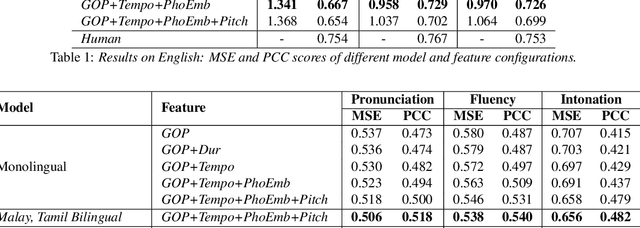
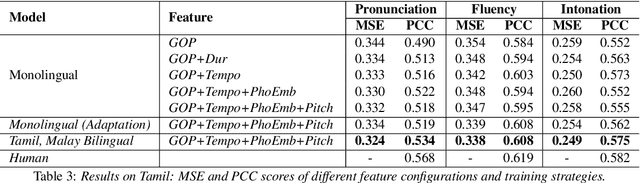
Speech evaluation is an essential component in computer-assisted language learning (CALL). While speech evaluation on English has been popular, automatic speech scoring on low resource languages remains challenging. Work in this area has focused on monolingual specific designs and handcrafted features stemming from resource-rich languages like English. Such approaches are often difficult to generalize to other languages, especially if we also want to consider suprasegmental qualities such as rhythm. In this work, we examine three different languages that possess distinct rhythm patterns: English (stress-timed), Malay (syllable-timed), and Tamil (mora-timed). We exploit robust feature representations inspired by music processing and vector representation learning. Empirical validations show consistent gains for all three languages when predicting pronunciation, rhythm and intonation performance.